Java 基础学习(十四)Map集合与Set集合
1 Map集合
1.1 Map接口
1.1.1 Map接口概述
Map接口是一种双列集合。Map的每个元素都包含一个键对象Key和一个值对象Value ,键对象和值对象之间存在对应关系,这种关系称为映射(Mapping)。
Map接口中的元素,可以通过 key 找到 value,因此:
- 一个键只能映射一个值,但允许多个不同的键映射到同一个值上
- 键对象Key必须是唯一的,不允许重复
- 值对象Value允许重复
如下图所示:

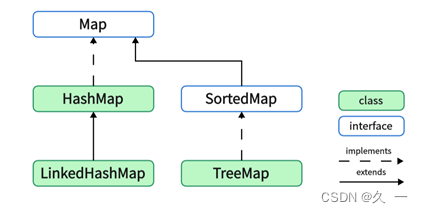
?1.1.2 Map接口的实现类
Map接口常用的实现类包括HashMap、TreeMap和LinkedHashMap:
?1.1.3 Map接口的常用方法
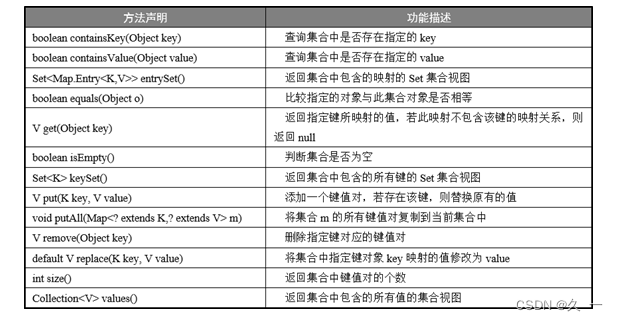
Map是实现映射集合的根接口。Map接口定义了关于映射集合的相关的操作方法,常用方法如下所示:
?1.1.4 【案例】Map常用方法示例
编写代码,测试Map的常用方法。代码示意如下:
import java.util.*;
public class MapDemo1 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
// 存放元素,以键值对形式
map.put(1, "Tom");
map.put(3, "Jerry");
map.put(5, "Lucy");
// 获取元素,通过key获取value
String value = map.get(1);
System.out.println("value: " + value); // Tom
String value2 = map.get(2); // 尝试通过不存在的key获取value
System.out.println("value2: " + value2); // 返回null
// 存放已存在的key,则替换value,并返回被替换的value
String oldValue = map.put(1, "Tony");
System.out.println("oldValue: "+oldValue); // Tom
System.out.println("value: " + map.get(1)); // Tony
// 支持基于key删除键值对,返回被删除的value
map.remove(1);
System.out.println("value: " + map.get(1)); // null
// 查询map中是否包含了某个key 或 value
boolean flag1 = map.containsKey(3);
System.out.println("containsKey 3: "+flag1);
boolean flag2 = map.containsValue("Tom");
System.out.println("containsValue Tom: "+flag2);
// 返回包含了所有key的集合
Set<Integer> keys = map.keySet();
System.out.println("keys: " + keys); // [3, 5]
// 返回包含了所有value的集合
Collection<String> values = map.values();
System.out.println("values: " + values); // [Jerry, Lucy]
}
}1.2 哈希表
1.2.1 初识哈希表
哈希表(Hash Table),也称为散列表,是一种常见的数据结构,用于存储和检索键值对(key-value pairs)。它基于哈希函数将关键字(key)映射到数组索引(下标),以便快速访问和操作数据。
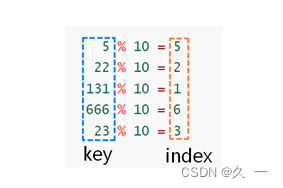
我们通过一个对比案例来介绍哈希表的作用及原理。在这个案例中,我们需要按顺序添加5个键值对,分别是(5, Lucy), (22, Tom), (131, Jerry), (666, Bob), (23, Alice)。
首先,我们来看一下不使用哈希表的情况,默认按照元素的添加顺序将键值对的键存放到数组中,如下图所示。

?
这种方式的缺点在于使用key查询数据时,最差的情况下需要遍历整个数组。
接下来,我们来看一下使用哈希表的情况。想使用哈希表,我们需要先定义一个哈希函数。简单的说,哈希函数是计算一个key对应的数组索引的函数。
在本例中,我们使用的哈希函数如下:

此时计算得到的key与数组下标的关系如下:
?按照这一规则,元素在数组中的存放位置如下:
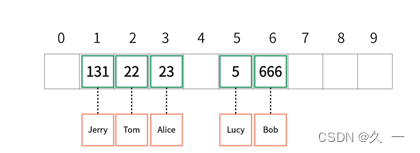
?采用这样的方式,使用key查询数据时,可以使用相同的规则计算索引,直接通过计算的结果获取数组该位置元素,查询效率高。
在许多情况下,哈希表比搜索树或任何其他表查找结构平均更有效。 因此,哈希表被广泛用于多种计算机软件,特别是关联数组、数据库索引、缓存和集合。
1.2.2 哈希算法
哈希函数(也称Hash算法)有多种实现方法,比如“除留取余法”,以及“直接定址法”、“数字分析法”、“分段叠加法”、“平均取中法”、“伪随机数法”等。
除留取余法如下图所示:

1.2.3 哈希冲突
两个不同的输入值,根据同一哈希函数计算出的索引相同的现象称为哈希冲突,也称为哈希碰撞。
例如,假设数组的长度为10,使用除留取余法,元素18和元素28对应的数组索引均为8,即发生了哈希冲突。
衡量一个Hash算法的重要指标就是发生冲突的概率,以及发生冲突的解决方案。任何Hash函数基本都无法彻底避免冲突,常见的解决冲突的方法有以下几种:
1、开放地址法:一旦发生了冲突,就去寻找下一个空的哈希地址,只要哈希表足够大,总能找到空的哈希地址,并将元素存入。
2、再Hash法:当Hash地址发生冲突时使用其他函数计算另一个Hash函数地址,直到不再产生冲突为止。
3、建立公共溢出区:将Hash表分为基本表和溢出表两部分,发生冲突的元素都放入溢出表。
4、链地址法:将Hash表的每个单元作为链表的头节点,所有Hash地址为i的元素构成一个同义词链表,即发生冲突时就把该元素链接在该单元为头节点的链表的尾部。

1.3 HashMap
1.3.1 HashMap概述
HashMap类是Map接口最常用的实现类之一,内部基于哈希表存储键值对数据,以提供高效的插入、删除和查找操作。HashMap在实际开发中广泛应用于缓存、索引、数据存储和快速查找等场景。
HashMap的内部使用了一个Node类来表示存储在哈希桶(数组)中的键值对。Node类是HashMap的内部私有静态类。
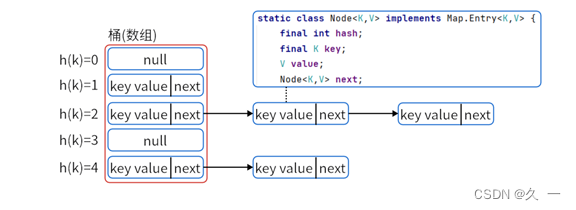
?Node类包含了以下几个主要的字段:
- final int hash:存储键的哈希码,用于确定键值对在桶数组中的位置。
- final K key:存储键的值。
- V value:存储与键相关联的值。
- Node<K,V> next:用于处理哈希冲突,存储下一个Node节点的引用,形成链表或红黑树结构。
1.3.2 【案例】HashMap遍历示例
编写代码,测试HashMap的遍历。代码示意如下:
import java.util.*;
public class HashMapDemo1 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
// 存放元素,以键值对形式
map.put(5, "Tom");
map.put(3, "Jerry");
map.put(9, "Lucy");
// 通过keySet()方法遍历
Set<Integer> keySet = map.keySet();
for(Integer key : keySet) {
// 基于key查询value,多了一步查询
System.out.println("key: " + key+" value: " + map.get(key));
}
// 通过entrySet方法遍历(推荐),一次查询出全部键值对
Set<Map.Entry<Integer,String >> entrySet = map.entrySet();
for(Map.Entry<Integer,String> entry:entrySet){
System.out.println("key: " + entry.getKey()+" value: " + entry.getValue());
}
}
}1.3.3 hashCode方法
在前面的案例中,我们使用的key是整型,可以直接参与取余运算。如果我们想要使用字符串或者自定义类型(例如Student)作为key,是否还能使用哈希表呢?答案是肯定的。
Java在Object类中设计了hashCode方法,用于返回当前对象的哈希值。通过下面的源码可以看到,该方法返回的是一个int类型的值。

?通过这样的设计,任意一个Java对象均可以作为哈希表的key。

?1.3.4 put方法的执行流程
当使用HashMap对象的put方法存储一个键值对时,一般会经过以下几步:
1、计算Key的哈希值。
- 如果Key为null,则哈希值为0
- 如果Key不为null,调用Key的hashCode方法,计算Key的哈希值
2、如果内部数组没有被初始化,会先初始化内部数组。
3、通过Key的哈希值计算Key在桶(数组)中的位置。
4、如果桶中目标位置没有元素,则创建Node对象,存储键值对数据,并将Node对象保存到桶中目标位置。
5、如果桶中目标位置有元素(注意可能有多个),则将key与这些元素的key进行比较。
- 如果Key与某个元素的Key相等(== 或 equals),则使用新存入的Value覆盖旧的Value
- 如果Key与桶中该位置的所有元素都不相等,则创建新的Node对象,存储键值对数据,并追加到链表中
1.3.5 【案例】put方法示例
编写代码,测试HashMap的遍历。代码示意如下:
import java.util.HashMap;
import java.util.Map;
public class HashMapDemo2 {
public static void main(String[] args) {
// 使用包裹类作为Key
Map<Integer, String> map1 = new HashMap<>();
map1.put(1, "Tom");
map1.put(1, "Jerry");
System.out.println(map1.get(1)); // Jerry
// 使用自定义类作为Key
Map<Student, String> map2 = new HashMap<>();
Student s1 = new Student("Tom", 18);
Student s2 = new Student("Tom", 18);
map2.put(s1, "Tom");
map2.put(s2, "Jerry");
System.out.println(map2.get(s1)); // Tom
System.out.println(map2.get(s2)); // Jerry
// hashCode不同导致不会调用equals方法
System.out.println("s1.hashCode:"+s1.hashCode()); // 990368553
System.out.println("s1.hashCode:"+s2.hashCode()); // 1096979270
}
}
class Student{
String name;
Integer age;
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object obj) { // 案例中的equals并没有被调用
System.out.println("equals方法被调用了:" + obj);
return super.equals(obj);
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}1.3.6 重写hashCode方法
结合put方法的执行流程及上面案例的执行效果我们可以发现:使用hashCode方法的默认实现逻辑,可能导致HashMap无法正确识别两个逻辑相等的Key。
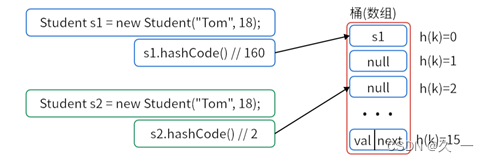
因此,在使用自定义类型作为HashMap中的Key时,需要重写该类的hashCode方法,以满足以下要求。
1、多次调用同一个对象的hashCode方法,应返回相同的哈希码。
2、如果两个对象被equals()方法判断为相等,那么它们的hashCode()方法应该返回相同的哈希码。
3、如果两个对象被equals()方法判断为不相等,不强制要求它们的hashCode()方法返回不同的哈希码,但是开发者应该了解,返回不同的哈希码有利于提高哈希表的性能。
集成式开发环境如IDEA和Eclipse均提供了重写hashCode和equals方法的支持,开发者可直接使用,提高开发效率。
1.3.7 【案例】HashMap应用示例
请基于HashMap重构前一天的ArrayList应用示例,对比HashMap和ArrayList在使用上的差别。
1、将前一天的Subject、Exam和ArrayListDemo2三个类拷贝到今天的package中。
2、将ArrayListDemo2更名为HashMapDemo3。
3、分析并重构HashMapDemo3中的代码,在适合使用HashMap的地方将ArrayList替换为HashMap。
import java.io.BufferedReader;
import java.io.FileReader;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.*;
public class HashMapDemo3 {
public static void main(String[] args) {
String subjectPath = "d:/data/subject.csv";
String examPath = "d:/data/exam.csv";
HashMap<Integer, Subject> subjects = readSubjects(subjectPath);
System.out.println(subjects); // 打印科目信息
HashMap<Integer, Exam> exams = readExams(examPath, subjects);
System.out.println(exams); // 打印考试信息
// 筛选出考试时间在10点之后的考试信息
DateTimeFormatter formatter =
DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss");
for (Exam exam : exams.values()) {
LocalDateTime ldt = LocalDateTime
.parse(exam.getStartTime(),formatter);
if (ldt.getHour()>9){
System.out.println(exam);
}
}
}
/**
* 读取文件中的数据,每行生成一个考试对象,存储到集合中
* @param path
* @param subjects
* @return
*/
public static HashMap<Integer, Exam> readExams(String path
, Map<Integer, Subject> subjects) {
List<String> lines = readLines(path);
HashMap<Integer, Exam> exams = new HashMap<>();
for (String line : lines) {
String[] arr = line.split(",");
Exam exam = new Exam();
exam.setId(Integer.parseInt(arr[0]));
exam.setName(arr[1]);
exam.setStartTime(arr[2]);
exam.setDuration(Integer.parseInt(arr[3]));
// 从map中查询科目对象
exam.setSubject(subjects.get(Integer.parseInt(arr[4])));
exams.put(exam.getId(), exam);
}
return exams;
}
/**
* 读取文件中的数据,每行生成一个科目对象,存储到集合中
* @param path
* @return
*/
public static HashMap<Integer, Subject> readSubjects(String path){
List<String> lines = readLines(path);
HashMap<Integer, Subject> subjects = new HashMap<>();
for(String line : lines){
String[] arr = line.split(",");
Subject subject = new Subject();
subject.setId(Integer.parseInt(arr[0]));
subject.setName(arr[1]);
subjects.put(subject.getId(), subject);
}
return subjects;
}
/**
* 读取文件中的数据,每行生成一个字符串,存储到集合中
* @param path
* @return
*/
public static ArrayList<String> readLines(String path){
ArrayList<String> lines = new ArrayList<>();
try(
FileReader fr = new FileReader(path);
BufferedReader br = new BufferedReader(fr);
){
String line = br.readLine();
line = br.readLine(); // 跳过第一行
while(line != null){
lines.add(line);
line = br.readLine();
}
}catch (Exception e){
e.printStackTrace();
}
return lines;
}
}1.4 HashMap原理
1.4.1 HashMap的容量
HashMap中使用数组作为存储元素的桶,对应的内部属性为table,如下图所示。HashMap的内部数组不是在创建HashMap对象时初始化,而是在首次存入元素时进行初始化,以减少对内存的占用。

?
从源码注释中我们可以发现,官方规定table的长度总是2的幂,即2的N次方。这样设计的原因是为了保证HashMap的速度足够快。这是一个需要特别注意的面试高频考点。
我们知道,不论存操作还是取操作,HashMap都使用除留取余法通过key的哈希值计算key在桶中的索引。如果能优化这一计算的速度,将会大幅优化HashMap存取操作的速度。
在数学中有这样一条公式:X % 2^n = X & (2^n - 1) 。简单的说,当X对Y取余时,如果Y是2的幂,则可以将取余运算转换为位运算,以提高计算速度。
综上,HashMap的容量始终是2的幂,以保证内部高效的哈希运算。
1.4.2 HashMap的初始容量
与ArrayList相似,HashMap的初始容量分为默认容量和手动指定两种情况。
当使用无参构造器创建HashMap对象时,table的初始化长度为16,由如下的静态常量指定。

?因此,默认情况下,HashMap的默认容量为16。
HashMap支持使用带参构造器HashMap(int initialCapacity)来创建HashMap对象,并指定内部数组的初始化长度。
此处需要注意,HashMap并不会直接使用开发者指定的长度作为内部数组的长度,而是会通过一个内部方法,计算大于开发者指定长度的最小的2的幂作为内部数组的长度。

?因此,当开发者指定初始长度时,HashMap的容量为大于该长度的最小的2的幂。
1.4.3 HashMap的扩容
HashMap中提供了桶的自动扩容机制,在满足特定的条件时自动将桶的长度扩容到原来的两倍。
想要理解桶的扩容条件,需要先分清楚4个概念:
- 1、容量(capacity):HashSet内部数组的长度,默认长度为16
- 2、大小(size):HashSet中实际存储的元素的个数,默认为0
- 3、负载因子(loadFactor):用来衡量HashSet“满”的程度,默认值为0.75f
- 4、临界值(threshold):当size超过临界值时,HashSet将会扩容,threshold = capacity * loadFactor
对于一个默认的HashSet来说,临界值=16 * 0.75 = 12,即当存储了超过12个元素时,HashSet会自动扩容,将容量扩大到原来的2倍,即32。
扩容后,还会对所有的元素进行一次rehash操作,相当于对所有的元素重新做一遍Hash运算,是一项比较耗时的操作。
由于存在上述的设计,因此开发者手动指定HashMap的初始容量时,需要计算合适的容量,而不是直接传入要存储元素的个数。具体可参考《阿里巴巴 Java开发手册》中的建议。

?1.4.4 树化与退化
HashMap中使用链地址法处理Hash冲突,当桶中某个位置的链表过长时,会响查询效率的情况。

自Java 8开始,HashMap在解决哈希冲突时引入了红黑树的应用,以提高查找操作的效率。当链表长度大于等于阈值(默认为8),同时HashMap容量已达到64时,链表会转换为红黑树,从而减少查找操作的时间复杂度,这个过程称为树化(Treeify)。
树化的2个阈值由HashMap内部的静态常量指定。

红黑树是一种自平衡的二叉搜索树,它具有良好的平衡性能和较快的查找、插入和删除操作的时间复杂度。相比于链表,红黑树在大型哈希桶中可以提供更快的查找速度。

?同时,当红黑树中的节点数量减少到一定程度(默认为6)时,HashMap会将红黑树转换回链表。这个过程称为退化(Untreeify)。退化的阈值同样由HashMap内部的静态常量指定:

1.5 LinkedHashMap
1.5.1 LinkedHashMap概述
HashMap虽然提供了高效的添加和查询功能,但是无法保存元素的添加顺序。在一些特定的应用场景中,可能需要保存键值对的添加顺序,此时可以使用LinkedHashMap来实现。
例如:项目既需要提供按用户名快速查询用户信息的功能,也需要提供按用户签到顺序显示用户信息列表的功能。此时需要能够记载元素的添加顺序。
LinkedHashMap是在HashMap的基础上维护了一个Entry的双向链表,以此记录元素之间的先后顺序。
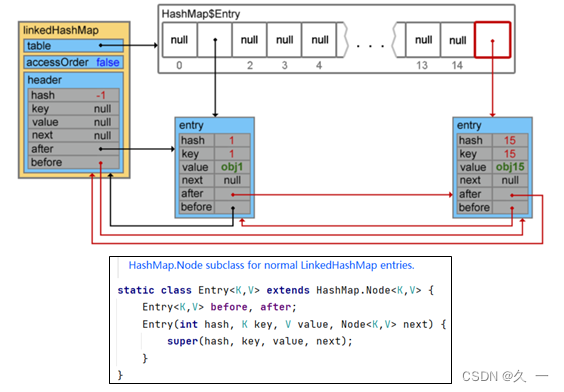
?
1.5.2 【案例】LinkedHashMap示例
编写代码,测试LinkedHashMap的遍历。代码示意如下:
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Set;
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<Integer,String> map = new LinkedHashMap<>();
// 存放元素,以键值对形式
map.put(5, "Tom");
map.put(3, "Jerry");
map.put(9, "Lucy");
// 通过entrySet方法遍历
Set<Map.Entry<Integer,String >> entrySet = map.entrySet();
for(Map.Entry<Integer,String> entry:entrySet){
System.out.println("key: " + entry.getKey()+" value: " + entry.getValue());
}
}
}2 Set集合
2.1 Set接口
2.1.1 Set接口概述
Set接口继承自Collection接口,所以与Collection接口中的方法基本一致,并没有对Collection接口进行功能上的扩充,只是比Collection接口更加严格。
Set集合的特点是无序且不可重复:
- 无序:不能保证按照添加元素的顺序来存放元素
- 不可重复:集合中不能存储两个用equals方法判断为相等的元素
可以利用Set集合不可重复的特点实现去重操作。
2.1.2 【案例】Set集合示例
编写代码,测试Set集合的使用。代码示意如下:
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class SetDemo1 {
public static void main(String[] args) {
List<Integer> list = Arrays.asList(7, 3, 1, 3, 5, 3, 1);
// 创建Set集合对象,并将list集合中的元素添加到Set中
Set<Integer> set = new HashSet<>(list);
System.out.println(set); // 1, 3, 5, 7
// 尝试添加重复元素
boolean flag = set.add(1);
System.out.println("flag: " + flag); // false
System.out.println(set); // 1, 3, 5, 7
}
}2.1.3 集合运算
Set接口能利用相关方法实现数学上的集合运算,如并、交、差等:
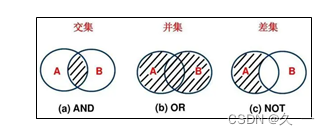
?常用的集合运算方法如下所示:

?2.1.4 【案例】集合运算示例
编写代码,测试集合运算。代码示意如下:
import java.util.*;
public class SetDemo2 {
public static void main(String[] args) {
List<Integer> list1 = Arrays.asList(1, 2, 3, 4);
List<Integer> list2 = Arrays.asList(3, 4, 5, 6);
Set<Integer> set1 = new HashSet<>(list1);
Set<Integer> set2 = new HashSet<>(list2);
System.out.println("set1: " + set1);
System.out.println("set2: " + set2);
// 求交集
set1.retainAll(set2);
System.out.println("set1 和 set2 交集:"+set1);
// 重置set1
set1= new HashSet<>(list1);
// 求并集
set1.addAll(set2);
System.out.println("set1 和 set2 并集:"+set1);
// 重置set1
set1= new HashSet<>(list1);
// 求补集
set1.removeAll(set2);
System.out.println("set1 和 set2 补集:"+set1);
}
}2.2 HashSet
2.2.1 HashSet概述
HashSet是Java中实现了Set接口的集合类,它使用哈希表作为底层数据结构,用于存储唯一的元素。HashSet不保证元素的顺序,且不允许重复元素。
HashSet底层实际上是使用HashMap对象来存储数据,如下图所示。

以下是HashSet的一些特点:
1、HashSet基于哈希表,使用哈希函数将元素映射到对应的存储位置。
2、HashSet存储的元素是无序的,即元素的插入顺序与遍历顺序不一致。
3、HashSet不允许重复元素,每个元素只能出现一次。当尝试将重复元素添加到HashSet时,操作将被忽略。
4、HashSet的元素可以是任何对象,但需要正确实现hashCode()和equals()方法,以确保元素的唯一性。
5、HashSet允许使用null作为元素,但只能有一个null元素。
6、HashSet的插入、删除和查找操作具有常数时间复杂度(平均情况下为O(1)),提供了高效的性能。
2.2.2 【案例】HashSet示例
编写代码,测试HashSet的使用。代码示意如下:
import java.util.HashSet;
import java.util.Objects;
import java.util.Set;
public class HashSetDemo1 {
public static void main(String[] args) {
Set<Student1> set1 = new HashSet<>();
set1.add(new Student1("Tom",18));
set1.add(new Student1("Tom",18));
System.out.println(set1);
Set<Student2> set2 = new HashSet<>();
set2.add(new Student2("Tom",18));
set2.add(new Student2("Tom",18));
System.out.println(set2);
}
}
class Student1{
String name;
int age;
public Student1(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student1{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
class Student2{
String name;
int age;
public Student2(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student2 student2 = (Student2) o;
return age == student2.age && Objects.equals(name, student2.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
@Override
public String toString() {
return "Student1{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!