Python 架构模式:第十章到结语
第十章:命令和命令处理程序
原文:10: Commands and Command Handler
译者:飞龙
在上一章中,我们谈到使用事件作为表示系统输入的一种方式,并将我们的应用程序转变为一个消息处理机器。
为了实现这一点,我们将所有的用例函数转换为事件处理程序。当 API 接收到一个创建新批次的 POST 请求时,它构建一个新的BatchCreated事件,并将其处理为内部事件。这可能感觉反直觉。毕竟,批次还没有被创建;这就是我们调用 API 的原因。我们将通过引入命令并展示它们如何通过相同的消息总线处理,但规则略有不同来解决这个概念上的问题。
提示
本章的代码在 GitHub 的 chapter_10_commands 分支中oreil.ly/U_VGa:
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_10_commands
# or to code along, checkout the previous chapter:
git checkout chapter_09_all_messagebus
命令和事件
与事件一样,命令是一种消息类型——由系统的一部分发送给另一部分的指令。我们通常用愚蠢的数据结构表示命令,并且可以以与事件相同的方式处理它们。
然而,命令和事件之间的差异是重要的。
命令由一个参与者发送给另一个特定的参与者,并期望作为结果发生特定的事情。当我们向 API 处理程序发布表单时,我们正在发送一个命令。我们用祈使句动词短语命名命令,比如“分配库存”或“延迟发货”。
命令捕获意图。它们表达了我们希望系统执行某些操作的愿望。因此,当它们失败时,发送者需要接收错误信息。
事件由一个参与者广播给所有感兴趣的监听器。当我们发布BatchQuantityChanged时,我们不知道谁会接收到它。我们用过去时动词短语命名事件,比如“订单分配给库存”或“发货延迟”。
我们经常使用事件来传播关于成功命令的知识。
事件捕获过去发生的事情的事实。由于我们不知道谁在处理事件,发送者不应关心接收者成功与否。表 10-1 总结了差异。
表 10-1。事件与命令的差异
| 事件 | 命令 | |
|---|---|---|
| 命名 | 过去式 | 祈使句 |
| 错误处理 | 独立失败 | 失败时有噪音 |
| 发送至 | 所有监听器 | 一个接收者 |
我们的系统现在有什么样的命令?
提取一些命令(src/allocation/domain/commands.py)
class Command:
pass
@dataclass
class Allocate(Command): #(1)
orderid: str
sku: str
qty: int
@dataclass
class CreateBatch(Command): #(2)
ref: str
sku: str
qty: int
eta: Optional[date] = None
@dataclass
class ChangeBatchQuantity(Command): #(3)
ref: str
qty: int
①
commands.Allocate将替换events.AllocationRequired。
②
commands.CreateBatch将替换events.BatchCreated。
③
commands.ChangeBatchQuantity将替换events.BatchQuantityChanged。
异常处理的差异
只是改变名称和动词是很好的,但这不会改变我们系统的行为。我们希望以类似的方式处理事件和命令,但不完全相同。让我们看看我们的消息总线如何改变:
不同的调度事件和命令(src/allocation/service_layer/messagebus.py)
Message = Union[commands.Command, events.Event]
def handle( #(1)
message: Message,
uow: unit_of_work.AbstractUnitOfWork,
):
results = []
queue = [message]
while queue:
message = queue.pop(0)
if isinstance(message, events.Event):
handle_event(message, queue, uow) #(2)
elif isinstance(message, commands.Command):
cmd_result = handle_command(message, queue, uow) #(2)
results.append(cmd_result)
else:
raise Exception(f"{message} was not an Event or Command")
return results
①
它仍然有一个主要的handle()入口,接受一个message,它可以是一个命令或一个事件。
②
我们将事件和命令分派给两个不同的辅助函数,如下所示。
这是我们处理事件的方式:
事件不能中断流程(src/allocation/service_layer/messagebus.py)
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]: #(1)
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continue #(2)
①
事件发送到一个分发器,可以将每个事件委派给多个处理程序。
②
它捕获并记录错误,但不允许它们中断消息处理。
这是我们处理命令的方式:
命令重新引发异常(src/allocation/service_layer/messagebus.py)
def handle_command(
command: commands.Command,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
logger.debug("handling command %s", command)
try:
handler = COMMAND_HANDLERS[type(command)] #(1)
result = handler(command, uow=uow)
queue.extend(uow.collect_new_events())
return result #(3)
except Exception:
logger.exception("Exception handling command %s", command)
raise #(2)
①
命令调度程序期望每个命令只有一个处理程序。
②
如果引发任何错误,它们会快速失败并上升。
③
return result只是临时的;如“临时的丑陋的黑客:消息总线必须返回结果”中所述,这是一个临时的黑客,允许消息总线返回 API 使用的批次引用。我们将在第十二章中修复这个问题。
我们还将单个HANDLERS字典更改为命令和事件的不同字典。根据我们的约定,命令只能有一个处理程序:
新处理程序字典(src/allocation/service_layer/messagebus.py)
EVENT_HANDLERS = {
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
COMMAND_HANDLERS = {
commands.Allocate: handlers.allocate,
commands.CreateBatch: handlers.add_batch,
commands.ChangeBatchQuantity: handlers.change_batch_quantity,
} # type: Dict[Type[commands.Command], Callable]
讨论:事件、命令和错误处理
许多开发人员在这一点感到不舒服,并问:“当事件处理失败时会发生什么?我应该如何确保系统处于一致状态?”如果我们在messagebus.handle处理一半的事件之前由于内存不足错误而终止进程,我们如何减轻因丢失消息而引起的问题?
让我们从最坏的情况开始:我们未能处理事件,系统处于不一致状态。会导致这种情况的是什么样的错误?在我们的系统中,当只完成了一半的操作时,我们经常会陷入不一致状态。
例如,我们可以为客户的订单分配三个单位的DESIRABLE_BEANBAG,但在某种程度上未能减少剩余库存量。这将导致不一致的状态:三个单位的库存既被分配又可用,这取决于你如何看待它。后来,我们可能会将这些相同的沙发床分配给另一个客户,给客户支持带来麻烦。
然而,在我们的分配服务中,我们已经采取了措施来防止发生这种情况。我们已经仔细确定了作为一致性边界的聚合,并且我们引入了一个UoW来管理对聚合的更新的原子成功或失败。
例如,当我们为订单分配库存时,我们的一致性边界是Product聚合。这意味着我们不能意外地过度分配:要么特定订单行分配给产品,要么不分配——没有不一致状态的余地。
根据定义,我们不需要立即使两个聚合保持一致,因此如果我们未能处理事件并仅更新单个聚合,我们的系统仍然可以最终保持一致。我们不应违反系统的任何约束。
有了这个例子,我们可以更好地理解将消息分割为命令和事件的原因。当用户想要让系统执行某些操作时,我们将他们的请求表示为命令。该命令应修改单个聚合,并且要么完全成功,要么完全失败。我们需要做的任何其他簿记,清理和通知都可以通过事件来进行。我们不需要事件处理程序成功才能使命令成功。
让我们看另一个例子(来自不同的、虚构的项目)来看看为什么不行。
假设我们正在构建一个销售昂贵奢侈品的电子商务网站。我们的营销部门希望奖励重复访问的客户。他们在第三次购买后将客户标记为 VIP,并且这将使他们有资格获得优先处理和特别优惠。我们对这个故事的验收标准如下:
Given a customer with two orders in their history,
When the customer places a third order,
Then they should be flagged as a VIP.
When a customer first becomes a VIP
Then we should send them an email to congratulate them
使用我们在本书中已经讨论过的技术,我们决定要构建一个新的History聚合,记录订单并在满足规则时引发领域事件。我们将按照以下结构编写代码:
VIP 客户(另一个项目的示例代码)
class History: # Aggregate
def __init__(self, customer_id: int):
self.orders = set() # Set[HistoryEntry]
self.customer_id = customer_id
def record_order(self, order_id: str, order_amount: int): #(1)
entry = HistoryEntry(order_id, order_amount)
if entry in self.orders:
return
self.orders.add(entry)
if len(self.orders) == 3:
self.events.append(
CustomerBecameVIP(self.customer_id)
)
def create_order_from_basket(uow, cmd: CreateOrder): #(2)
with uow:
order = Order.from_basket(cmd.customer_id, cmd.basket_items)
uow.orders.add(order)
uow.commit() # raises OrderCreated
def update_customer_history(uow, event: OrderCreated): #(3)
with uow:
history = uow.order_history.get(event.customer_id)
history.record_order(event.order_id, event.order_amount)
uow.commit() # raises CustomerBecameVIP
def congratulate_vip_customer(uow, event: CustomerBecameVip): #(4)
with uow:
customer = uow.customers.get(event.customer_id)
email.send(
customer.email_address,
f'Congratulations {customer.first_name}!'
)
①
History聚合捕获了指示客户何时成为 VIP 的规则。这使我们能够在未来规则变得更加复杂时处理变化。
②
我们的第一个处理程序为客户创建订单,并引发领域事件OrderCreated。
③
我们的第二个处理程序更新History对象,记录已创建订单。
④
最后,当客户成为 VIP 时,我们会给他们发送一封电子邮件。
使用这段代码,我们可以对事件驱动系统中的错误处理有一些直觉。
在我们当前的实现中,我们在将状态持久化到数据库之后才引发关于聚合的事件。如果我们在持久化之前引发这些事件,并同时提交所有的更改,会怎样呢?这样,我们就可以确保所有的工作都已完成。这样不是更安全吗?
然而,如果电子邮件服务器稍微过载会发生什么呢?如果所有工作都必须同时完成,繁忙的电子邮件服务器可能会阻止我们接受订单的付款。
如果History聚合的实现中存在错误,会发生什么?难道因为我们无法识别您为 VIP 而放弃收取您的钱吗?
通过分离这些关注点,我们使得事情可以独立失败,这提高了系统的整体可靠性。这段代码中必须完成的部分只有创建订单的命令处理程序。这是客户关心的唯一部分,也是我们的业务利益相关者应该优先考虑的部分。
请注意,我们故意将事务边界与业务流程的开始和结束对齐。代码中使用的名称与我们的业务利益相关者使用的行话相匹配,我们编写的处理程序与我们的自然语言验收标准的步骤相匹配。名称和结构的一致性帮助我们推理系统在变得越来越大和复杂时的情况。
同步恢复错误
希望我们已经说服您,事件可以独立于引发它们的命令而失败。那么,当错误不可避免地发生时,我们应该怎么做才能确保我们能够从错误中恢复呢?
我们首先需要知道错误发生的时间,通常我们依赖日志来做到这一点。
让我们再次看看我们消息总线中的handle_event方法:
当前处理函数(src/allocation/service_layer/messagebus.py)
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork
):
for handler in EVENT_HANDLERS[type(event)]:
try:
logger.debug('handling event %s with handler %s', event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except Exception:
logger.exception('Exception handling event %s', event)
continue
当我们在系统中处理消息时,我们首先要做的是写入日志记录我们即将要做的事情。对于CustomerBecameVIP用例,日志可能如下所示:
Handling event CustomerBecameVIP(customer_id=12345)
with handler <function congratulate_vip_customer at 0x10ebc9a60>
因为我们选择使用数据类来表示我们的消息类型,我们可以得到一个整洁打印的摘要,其中包含了我们可以复制并粘贴到 Python shell 中以重新创建对象的传入数据。
当发生错误时,我们可以使用记录的数据来在单元测试中重现问题,或者将消息重新播放到系统中。
手动重放对于需要在重新处理事件之前修复错误的情况非常有效,但我们的系统将始终经历一定程度的瞬态故障。这包括网络故障、表死锁以及部署导致的短暂停机等情况。
对于大多数情况,我们可以通过再次尝试来优雅地恢复。正如谚语所说:“如果一开始你没有成功,就用指数增长的等待时间重试操作。”
带重试的处理(src/allocation/service_layer/messagebus.py)
from tenacity import Retrying, RetryError, stop_after_attempt, wait_exponential #(1)
...
def handle_event(
event: events.Event,
queue: List[Message],
uow: unit_of_work.AbstractUnitOfWork,
):
for handler in EVENT_HANDLERS[type(event)]:
try:
for attempt in Retrying( #(2)
stop=stop_after_attempt(3),
wait=wait_exponential()
):
with attempt:
logger.debug("handling event %s with handler %s", event, handler)
handler(event, uow=uow)
queue.extend(uow.collect_new_events())
except RetryError as retry_failure:
logger.error(
"Failed to handle event %s times, giving up!",
retry_failure.last_attempt.attempt_number
)
continue
①
Tenacity 是一个实现重试常见模式的 Python 库。
②
在这里,我们配置我们的消息总线,最多重试三次,在尝试之间等待的时间会指数增长。
重试可能会失败的操作可能是改善软件弹性的最佳方法。再次,工作单元和命令处理程序模式意味着每次尝试都从一致的状态开始,并且不会留下半成品。
警告
在某个时候,无论tenacity如何,我们都必须放弃尝试处理消息。构建可靠的分布式消息系统很困难,我们必须略过一些棘手的部分。在结语中有更多参考资料的指针。
总结
在本书中,我们决定在介绍命令的概念之前先介绍事件的概念,但其他指南通常是相反的。通过为系统可以响应的请求命名并为它们提供自己的数据结构,是一件非常基本的事情。有时你会看到人们使用“命令处理程序”模式来描述我们在事件、命令和消息总线中所做的事情。
表 10-2 讨论了在你加入之前应该考虑的一些事情。
表 10-2。分割命令和事件:权衡利弊
| 优点 | 缺点 |
|---|---|
| 将命令和事件区分对待有助于我们理解哪些事情必须成功,哪些事情可以稍后整理。 | 命令和事件之间的语义差异可能是微妙的。对于这些差异可能会有很多争论。 |
CreateBatch绝对比BatchCreated更清晰。我们明确了用户的意图,而明确比隐含更好,对吧? | 我们明确地邀请失败。我们知道有时会出现问题,我们选择通过使失败变得更小更隔离来处理这些问题。这可能会使系统更难以理解,并需要更好的监控。 |
在第十一章中,我们将讨论使用事件作为集成模式。
第十一章:事件驱动架构:使用事件集成微服务
原文:11: Event-Driven Architecture: Using Events to Integrate Microservices
译者:飞龙
在前一章中,我们实际上从未讨论过我们将如何接收“批量数量更改”事件,或者如何通知外部世界有关重新分配的情况。
我们有一个带有 Web API 的微服务,但是如何与其他系统进行通信呢?如果,比如说,发货延迟或数量被修改,我们将如何知道?我们将如何告诉仓库系统已经分配了订单并需要发送给客户?
在本章中,我们想展示事件隐喻如何扩展到涵盖我们处理系统中的传入和传出消息的方式。在内部,我们应用的核心现在是一个消息处理器。让我们跟进,使其在外部也成为一个消息处理器。如图 11-1 所示,我们的应用将通过外部消息总线(我们将使用 Redis pub/sub 队列作为示例)从外部来源接收事件,并将其输出以事件的形式发布回去。

图 11-1:我们的应用是一个消息处理器
提示
本章的代码在 GitHub 的 chapter_11_external_events 分支中。GitHub 链接
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_11_external_events
# or to code along, checkout the previous chapter:
git checkout chapter_10_commands
分布式泥球和名词思维
在我们深入讨论之前,让我们谈谈其他选择。我们经常与试图构建微服务架构的工程师交谈。通常,他们正在从现有应用程序迁移,并且他们的第一反应是将系统拆分为名词。
到目前为止,我们在系统中引入了哪些名词?嗯,我们有库存批次、订单、产品和客户。因此,对系统进行天真的尝试可能看起来像图 11-2(请注意,我们将系统命名为一个名词,Batches,而不是Allocation)。
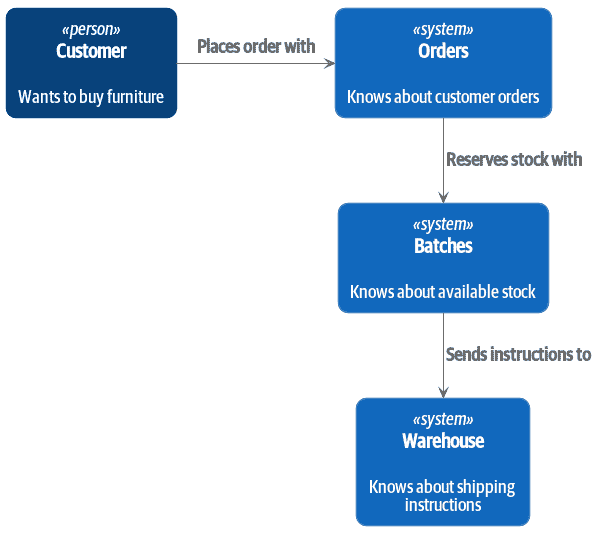
图 11-2:基于名词的服务的上下文图
[plantuml, apwp_1102, config=plantuml.cfg]
@startuml Batches Context Diagram
!include images/C4_Context.puml
System(batches, "Batches", "Knows about available stock")
Person(customer, "Customer", "Wants to buy furniture")
System(orders, "Orders", "Knows about customer orders")
System(warehouse, "Warehouse", "Knows about shipping instructions")
Rel_R(customer, orders, "Places order with")
Rel_D(orders, batches, "Reserves stock with")
Rel_D(batches, warehouse, "Sends instructions to")
@enduml
我们系统中的每个“东西”都有一个关联的服务,它公开了一个 HTTP API。
让我们通过图 11-3 中的一个示例顺畅流程来工作:我们的用户访问网站,可以从库存中选择产品。当他们将商品添加到购物篮时,我们将为他们保留一些库存。当订单完成时,我们确认预订,这会导致我们向仓库发送发货指示。我们还可以说,如果这是客户的第三个订单,我们希望更新客户记录以将其标记为 VIP。
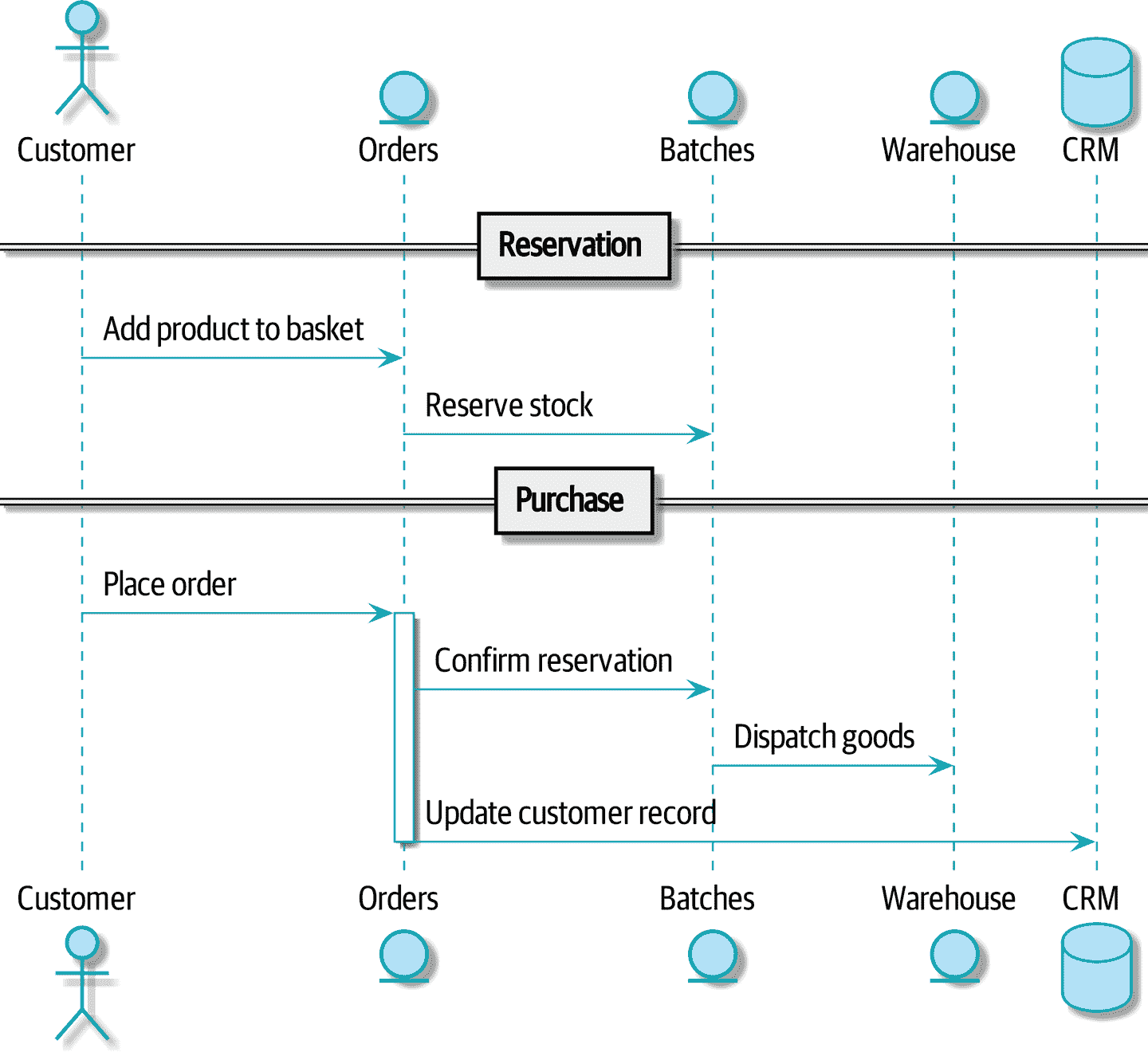
图 11-3:命令流程 1
[plantuml, apwp_1103, config=plantuml.cfg]
@startuml
actor Customer
entity Orders
entity Batches
entity Warehouse
database CRM
== Reservation ==
Customer -> Orders: Add product to basket
Orders -> Batches: Reserve stock
== Purchase ==
Customer -> Orders: Place order
activate Orders
Orders -> Batches: Confirm reservation
Batches -> Warehouse: Dispatch goods
Orders -> CRM: Update customer record
deactivate Orders
@enduml
我们可以将这些步骤中的每一个都视为我们系统中的一个命令:ReserveStock、ConfirmReservation、DispatchGoods、MakeCustomerVIP等等。
这种架构风格,即我们为每个数据库表创建一个微服务,并将我们的 HTTP API 视为贫血模型的 CRUD 接口,是人们最常见的初始服务设计方法。
这对于非常简单的系统来说是很好的,但很快就会变成一个分布式的泥球。
为了理解原因,让我们考虑另一种情况。有时,当库存到达仓库时,我们发现货物在运输过程中受潮。我们无法出售受潮的沙发,因此我们不得不将它们丢弃并向合作伙伴请求更多库存。我们还需要更新我们的库存模型,这可能意味着我们需要重新分配客户的订单。
这个逻辑应该放在哪里?
嗯,仓库系统知道库存已经受损,所以也许它应该拥有这个过程,就像图 11-4 中所示的那样。

图 11-4:命令流程 2
[plantuml, apwp_1104, config=plantuml.cfg]
@startuml
actor w as "Warehouse worker"
entity Warehouse
entity Batches
entity Orders
database CRM
w -> Warehouse: Report stock damage
activate Warehouse
Warehouse -> Batches: Decrease available stock
Batches -> Batches: Reallocate orders
Batches -> Orders: Update order status
Orders -> CRM: Update order history
deactivate Warehouse
@enduml
这种方法也可以,但现在我们的依赖图是一团糟。为了分配库存,订单服务驱动批次系统,批次系统驱动仓库;但为了处理仓库的问题,我们的仓库系统驱动批次,批次驱动订单。
将这种情况乘以我们需要提供的所有其他工作流程,你就会看到服务很快会变得混乱。
分布式系统中的错误处理
“事情会出错”是软件工程的普遍规律。当我们的请求失败时,我们的系统会发生什么?假设我们在为三个MISBEGOTTEN-RUG下订单后发生网络错误,如图 11-5 所示。
我们有两个选择:我们可以无论如何下订单并将其保留未分配,或者我们可以拒绝接受订单,因为无法保证分配。我们的批次服务的失败状态已经上升,并影响了我们订单服务的可靠性。
当两件事必须一起改变时,我们说它们是耦合的。我们可以将这种失败级联看作一种时间耦合:系统的每个部分都必须同时工作才能使系统的任何部分工作。随着系统变得越来越大,某个部分受损的可能性呈指数增长。
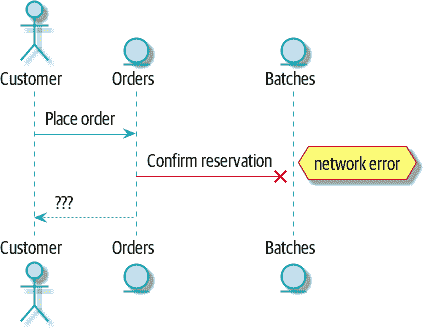
图 11-5:带错误的命令流
[plantuml, apwp_1105, config=plantuml.cfg]
@startuml
actor Customer
entity Orders
entity Batches
Customer -> Orders: Place order
Orders -[#red]x Batches: Confirm reservation
hnote right: network error
Orders --> Customer: ???
@enduml
另一种选择:使用异步消息进行时间解耦
我们如何获得适当的耦合?我们已经看到了部分答案,即我们应该从动词的角度思考,而不是名词。我们的领域模型是关于建模业务流程的。它不是关于一个静态事物的静态数据模型;它是一个动词的模型。
因此,我们不是考虑订单系统和批次系统,而是考虑下订单系统和分配系统,等等。
当我们以这种方式分离事物时,更容易看清哪个系统应该负责什么。在考虑顺序时,我们真的希望确保当我们下订单时,订单已经下了。其他事情可以稍后发生,只要它发生了。
注意
如果这听起来很熟悉,那就对了!分离责任是我们设计聚合和命令时经历的相同过程。
像聚合一样,微服务应该是一致性边界。在两个服务之间,我们可以接受最终一致性,这意味着我们不需要依赖同步调用。每个服务都接受来自外部世界的命令,并引发事件来记录结果。其他服务可以监听这些事件来触发工作流程的下一步。
为了避免分布式泥球反模式,我们不想使用临时耦合的 HTTP API 调用,而是想要使用异步消息传递来集成我们的系统。我们希望我们的BatchQuantityChanged消息作为来自上游系统的外部消息传入,并且我们希望我们的系统发布Allocated事件供下游系统监听。
为什么这样做更好?首先,因为事情可以独立失败,处理降级行为更容易:如果分配系统出现问题,我们仍然可以接受订单。
其次,我们正在减少系统之间的耦合强度。如果我们需要改变操作顺序或者在流程中引入新步骤,我们可以在本地进行。
使用 Redis Pub/Sub 频道进行集成
让我们看看它将如何具体运作。我们需要某种方式将一个系统的事件传递到另一个系统,就像我们的消息总线一样,但是针对服务。这种基础设施通常被称为消息代理。消息代理的作用是接收发布者的消息并将其传递给订阅者。
在 MADE.com,我们使用Event Store;Kafka 或 RabbitMQ 也是有效的替代方案。基于 Redis pub/sub 频道的轻量级解决方案也可以很好地工作,因为 Redis 对大多数人来说更加熟悉,所以我们决定在本书中使用它。
注意
我们忽略了选择正确的消息平台涉及的复杂性。像消息排序、故障处理和幂等性等问题都需要仔细考虑。有关一些建议,请参见“Footguns”。
我们的新流程将如下所示图 11-6:Redis 提供了BatchQuantityChanged事件,它启动了整个流程,并且我们的Allocated事件最终再次发布到 Redis。

图 11-6:重新分配流程的序列图
[plantuml, apwp_1106, config=plantuml.cfg]
@startuml
Redis -> MessageBus : BatchQuantityChanged event
group BatchQuantityChanged Handler + Unit of Work 1
MessageBus -> Domain_Model : change batch quantity
Domain_Model -> MessageBus : emit Allocate command(s)
end
group Allocate Handler + Unit of Work 2 (or more)
MessageBus -> Domain_Model : allocate
Domain_Model -> MessageBus : emit Allocated event(s)
end
MessageBus -> Redis : publish to line_allocated channel
@enduml
使用端到端测试来测试驱动所有内容
以下是我们可能如何开始端到端测试。我们可以使用我们现有的 API 创建批次,然后我们将测试入站和出站消息:
我们的发布/订阅模型的端到端测试(tests/e2e/test_external_events.py)
def test_change_batch_quantity_leading_to_reallocation():
# start with two batches and an order allocated to one of them #(1)
orderid, sku = random_orderid(), random_sku()
earlier_batch, later_batch = random_batchref("old"), random_batchref("newer")
api_client.post_to_add_batch(earlier_batch, sku, qty=10, eta="2011-01-01") #(2)
api_client.post_to_add_batch(later_batch, sku, qty=10, eta="2011-01-02")
response = api_client.post_to_allocate(orderid, sku, 10) #(2)
assert response.json()["batchref"] == earlier_batch
subscription = redis_client.subscribe_to("line_allocated") #(3)
# change quantity on allocated batch so it's less than our order #(1)
redis_client.publish_message( #(3)
"change_batch_quantity",
{"batchref": earlier_batch, "qty": 5},
)
# wait until we see a message saying the order has been reallocated #(1)
messages = []
for attempt in Retrying(stop=stop_after_delay(3), reraise=True): #(4)
with attempt:
message = subscription.get_message(timeout=1)
if message:
messages.append(message)
print(messages)
data = json.loads(messages[-1]["data"])
assert data["orderid"] == orderid
assert data["batchref"] == later_batch
①
您可以从注释中阅读此测试中正在进行的操作的故事:我们希望向系统发送一个事件,导致订单行被重新分配,并且我们也看到该重新分配作为一个事件出现在 Redis 中。
②
api_client是一个小助手,我们对其进行了重构,以便在两种测试类型之间共享;它包装了我们对requests.post的调用。
③
redis_client是另一个小测试助手,其详细信息并不重要;它的工作是能够从各种 Redis 频道发送和接收消息。我们将使用一个名为change_batch_quantity的频道来发送我们的更改批次数量的请求,并且我们将监听另一个名为line_allocated的频道,以寻找预期的重新分配。
④
由于系统测试的异步性质,我们需要再次使用tenacity库添加重试循环 - 首先,因为我们的新的line_allocated消息可能需要一些时间才能到达,但也因为它不会是该频道上唯一的消息。
Redis 是我们消息总线周围的另一个薄适配器
我们的 Redis 发布/订阅监听器(我们称其为事件消费者)非常类似于 Flask:它将外部世界转换为我们的事件:
简单的 Redis 消息监听器(src/allocation/entrypoints/redis_eventconsumer.py)
r = redis.Redis(**config.get_redis_host_and_port())
def main():
orm.start_mappers()
pubsub = r.pubsub(ignore_subscribe_messages=True)
pubsub.subscribe("change_batch_quantity") #(1)
for m in pubsub.listen():
handle_change_batch_quantity(m)
def handle_change_batch_quantity(m):
logging.debug("handling %s", m)
data = json.loads(m["data"]) #(2)
cmd = commands.ChangeBatchQuantity(ref=data["batchref"], qty=data["qty"]) #(2)
messagebus.handle(cmd, uow=unit_of_work.SqlAlchemyUnitOfWork())
①
main()在加载时订阅了change_batch_quantity频道。
②
我们作为系统的入口点的主要工作是反序列化 JSON,将其转换为Command,并将其传递到服务层 - 就像 Flask 适配器一样。
我们还构建了一个新的下游适配器来执行相反的工作 - 将领域事件转换为公共事件:
简单的 Redis 消息发布者(src/allocation/adapters/redis_eventpublisher.py)
r = redis.Redis(**config.get_redis_host_and_port())
def publish(channel, event: events.Event): #(1)
logging.debug("publishing: channel=%s, event=%s", channel, event)
r.publish(channel, json.dumps(asdict(event)))
①
我们在这里采用了一个硬编码的频道,但您也可以存储事件类/名称与适当频道之间的映射,从而允许一个或多个消息类型发送到不同的频道。
我们的新出站事件
Allocated事件将如下所示:
新事件(src/allocation/domain/events.py)
@dataclass
class Allocated(Event):
orderid: str
sku: str
qty: int
batchref: str
它捕获了我们需要了解的有关分配的一切内容:订单行的详细信息,以及它被分配到哪个批次。
我们将其添加到我们模型的allocate()方法中(自然地先添加了一个测试):
产品分配()发出新事件来记录发生了什么(src/allocation/domain/model.py)
class Product:
...
def allocate(self, line: OrderLine) -> str:
...
batch.allocate(line)
self.version_number += 1
self.events.append(events.Allocated(
orderid=line.orderid, sku=line.sku, qty=line.qty,
batchref=batch.reference,
))
return batch.reference
ChangeBatchQuantity的处理程序已经存在,所以我们需要添加的是一个处理程序,用于发布出站事件:
消息总线增长(src/allocation/service_layer/messagebus.py)
HANDLERS = {
events.Allocated: [handlers.publish_allocated_event],
events.OutOfStock: [handlers.send_out_of_stock_notification],
} # type: Dict[Type[events.Event], List[Callable]]
发布事件使用我们从 Redis 包装器中的辅助函数:
发布到 Redis(src/allocation/service_layer/handlers.py)
def publish_allocated_event(
event: events.Allocated, uow: unit_of_work.AbstractUnitOfWork,
):
redis_eventpublisher.publish('line_allocated', event)
内部与外部事件
清楚地保持内部和外部事件之间的区别是个好主意。一些事件可能来自外部,一些事件可能会升级并在外部发布,但并非所有事件都会这样。如果你涉足事件溯源(尽管这是另一本书的主题),这一点尤为重要。
提示
出站事件是重要的应用验证的地方之一。参见附录 E 了解一些验证哲学和示例。
总结
事件可以来自外部,但也可以在外部发布——我们的publish处理程序将事件转换为 Redis 通道上的消息。我们使用事件与外部世界交流。这种时间解耦为我们的应用集成带来了很大的灵活性,但是,像往常一样,这是有代价的。
事件通知很好,因为它意味着低耦合,并且设置起来相当简单。然而,如果真的有一个在各种事件通知上运行的逻辑流,这可能会成为问题……很难看到这样的流,因为它在任何程序文本中都不是显式的……这可能会使调试和修改变得困难。
——Martin Fowler,“你所说的‘事件驱动’是什么意思”
表 11-1 显示了一些需要考虑的权衡。
表 11-1. 基于事件的微服务集成:权衡
| 优点 | 缺点 |
|---|---|
| 避免分布式的大泥球。 | 信息的整体流更难以看到。 |
| 服务是解耦的:更容易更改单个服务并添加新服务。 | 最终一致性是一个新的概念来处理。 |
| 消息可靠性和至少一次与至多一次交付的选择需要深思熟虑。 |
更一般地,如果你从同步消息传递模型转移到异步模型,你也会遇到一系列与消息可靠性和最终一致性有关的问题。继续阅读“Footguns”。
第十二章:命令-查询责任分离(CQRS)
原文:12: Command-Query Responsibility Segregation (CQRS)
译者:飞龙
在本章中,我们将从一个相当无争议的观点开始:读取(查询)和写入(命令)是不同的,因此它们应该被不同对待(或者说它们的责任应该被分开,如果你愿意的话)。然后我们将尽可能地推动这一观点。
如果你像哈利一样,起初这一切都会显得极端,但希望我们能够证明这并不是完全不合理。
图 12-1 显示了我们可能会达到的地方。
提示
本章的代码位于 GitHub 的 chapter_12_cqrs 分支中(https://oreil.ly/YbWGT)。
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_12_cqrs
# or to code along, checkout the previous chapter:
git checkout chapter_11_external_events
不过,首先,为什么要费这个劲呢?
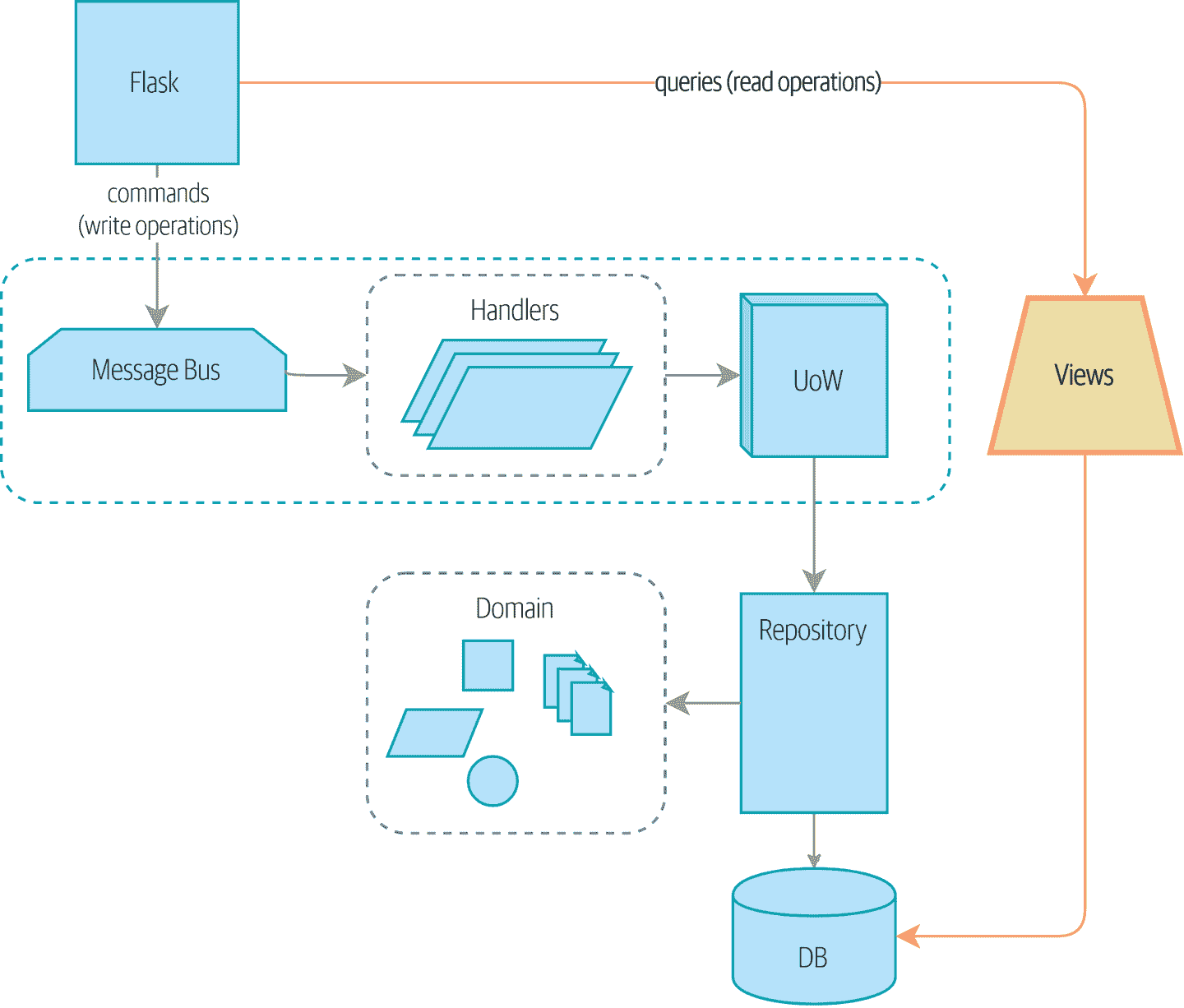
图 12-1. 将读取与写入分开
领域模型是用于写入的
在本书中,我们花了很多时间讨论如何构建强制执行我们领域规则的软件。这些规则或约束对于每个应用程序都是不同的,它们构成了我们系统的有趣核心。
在本书中,我们已经明确规定了“你不能分配超过可用库存的库存”,以及“每个订单行都分配给一个批次”等隐含约束。
我们在书的开头将这些规则写成了单元测试:
我们的基本领域测试(tests/unit/test_batches.py)
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine('order-ref', "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
...
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
为了正确应用这些规则,我们需要确保操作是一致的,因此我们引入了工作单元和聚合等模式,这些模式帮助我们提交小块工作。
为了在这些小块之间传达变化,我们引入了领域事件模式,这样我们就可以编写规则,比如“当库存损坏或丢失时,调整批次上的可用数量,并在必要时重新分配订单。”
所有这些复杂性存在是为了在我们改变系统状态时强制执行规则。我们已经构建了一套灵活的工具来编写数据。
那么读取呢?
大多数用户不会购买你的家具
在 MADE.com,我们有一个与分配服务非常相似的系统。在繁忙的一天,我们可能每小时处理一百个订单,并且我们有一个庞大的系统来为这些订单分配库存。
然而,在同一忙碌的一天,我们可能每秒有一百次产品浏览。每当有人访问产品页面或产品列表页面时,我们都需要弄清产品是否仍有库存以及我们需要多长时间才能将其交付。
领域是相同的——我们关心库存批次、它们的到货日期以及仍然可用的数量——但访问模式却大不相同。例如,我们的客户不会注意到查询是否过时几秒钟,但如果我们的分配服务不一致,我们将搞乱他们的订单。我们可以利用这种差异,通过使我们的读取最终一致来使它们的性能更好。
我们可以将这些要求看作是系统的两个部分:读取端和写入端,如表 12-1 所示。
对于写入方面,我们的精密领域架构模式帮助我们随着时间的推移发展我们的系统,但到目前为止我们建立的复杂性对于读取数据并没有带来任何好处。服务层、工作单元和聪明的领域模型只是多余的。
表 12-1. 读取与写入
| 读取端 | 写入端 | |
|---|---|---|
| 行为 | 简单读取 | 复杂业务逻辑 |
| 可缓存性 | 高度可缓存 | 不可缓存 |
| 一致性 | 可能过时 | 必须具有事务一致性 |
Post/Redirect/Get 和 CQS
如果你从事 Web 开发,你可能熟悉 Post/Redirect/Get 模式。在这种技术中,Web 端点接受 HTTP POST 并响应重定向以查看结果。例如,我们可能接受 POST 到*/batches来创建一个新批次,并将用户重定向到/batches/123*来查看他们新创建的批次。
这种方法修复了当用户在浏览器中刷新结果页面或尝试将结果页面加为书签时出现的问题。在刷新的情况下,它可能导致我们的用户重复提交数据,从而购买两张沙发,而他们只需要一张。在书签的情况下,我们的不幸顾客将在尝试获取 POST 端点时得到一个损坏的页面。
这两个问题都是因为我们在响应写操作时返回数据。Post/Redirect/Get 通过将操作的读取和写入阶段分开来规避了这个问题。
这种技术是命令查询分离(CQS)的一个简单示例。在 CQS 中,我们遵循一个简单的规则:函数应该要么修改状态,要么回答问题,但不能两者兼而有之。这使得软件更容易推理:我们应该始终能够询问,“灯亮了吗?”而不用去拨动开关。
注意
在构建 API 时,我们可以通过返回 201 Created 或 202 Accepted,并在 Location 标头中包含新资源的 URI 来应用相同的设计技术。这里重要的不是我们使用的状态代码,而是将工作逻辑上分为写入阶段和查询阶段。
正如你将看到的,我们可以使用 CQS 原则使我们的系统更快、更可扩展,但首先,让我们修复现有代码中的 CQS 违规。很久以前,我们引入了一个allocate端点,它接受一个订单并调用我们的服务层来分配一些库存。在调用结束时,我们返回一个 200 OK 和批次 ID。这导致了一些丑陋的设计缺陷,以便我们可以获得我们需要的数据。让我们将其更改为返回一个简单的 OK 消息,并提供一个新的只读端点来检索分配状态:
API 测试在 POST 之后进行 GET(tests/e2e/test_api.py)
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_202_and_batch_is_allocated():
orderid = random_orderid()
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
api_client.post_to_add_batch(laterbatch, sku, 100, '2011-01-02')
api_client.post_to_add_batch(earlybatch, sku, 100, '2011-01-01')
api_client.post_to_add_batch(otherbatch, othersku, 100, None)
r = api_client.post_to_allocate(orderid, sku, qty=3)
assert r.status_code == 202
r = api_client.get_allocation(orderid)
assert r.ok
assert r.json() == [
{'sku': sku, 'batchref': earlybatch},
]
@pytest.mark.usefixtures('postgres_db')
@pytest.mark.usefixtures('restart_api')
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
r = api_client.post_to_allocate(
orderid, unknown_sku, qty=20, expect_success=False,
)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'
r = api_client.get_allocation(orderid)
assert r.status_code == 404
好的,Flask 应用可能是什么样子?
用于查看分配的端点 (src/allocation/entrypoints/flask_app.py)
from allocation import views
...
@app.route("/allocations/<orderid>", methods=["GET"])
def allocations_view_endpoint(orderid):
uow = unit_of_work.SqlAlchemyUnitOfWork()
result = views.allocations(orderid, uow) #(1)
if not result:
return "not found", 404
return jsonify(result), 200
①
好吧,views.py,可以,我们可以将只读内容放在那里,它将是一个真正的views.py,不像 Django 的那样,它知道如何构建我们数据的只读视图…
坚持住你的午餐,伙计们
嗯,我们可能只需向我们现有的存储库对象添加一个列表方法:
Views do…raw SQL? (src/allocation/views.py)
from allocation.service_layer import unit_of_work
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = list(uow.session.execute(
'SELECT ol.sku, b.reference'
' FROM allocations AS a'
' JOIN batches AS b ON a.batch_id = b.id'
' JOIN order_lines AS ol ON a.orderline_id = ol.id'
' WHERE ol.orderid = :orderid',
dict(orderid=orderid)
))
return [{'sku': sku, 'batchref': batchref} for sku, batchref in results]
“对不起?原始 SQL?”
如果你像哈里第一次遇到这种模式一样,你会想知道鲍勃到底在抽什么烟。我们现在自己手动编写 SQL,并直接将数据库行转换为字典?在构建一个漂亮的领域模型时,我们付出了那么多的努力?存储库模式呢?它不是应该是我们围绕数据库的抽象吗?为什么我们不重用它?
好吧,让我们先探索这个看似更简单的替代方案,看看它在实践中是什么样子。
我们仍将保留我们的视图在一个单独的views.py模块中;在应用程序中强制执行读取和写入之间的明确区分仍然是一个好主意。我们应用命令查询分离,很容易看出哪些代码修改了状态(事件处理程序),哪些代码只是检索只读状态(视图)。
提示
将只读视图与修改状态的命令和事件处理程序分离出来可能是一个好主意,即使你不想完全实现 CQRS。
测试 CQRS 视图
在探索各种选项之前,让我们先谈谈测试。无论你决定采用哪种方法,你可能至少需要一个集成测试。就像这样:
用于视图的集成测试 (tests/integration/test_views.py)
def test_allocations_view(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory)
messagebus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None), uow) #(1)
messagebus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today), uow)
messagebus.handle(commands.Allocate("order1", "sku1", 20), uow)
messagebus.handle(commands.Allocate("order1", "sku2", 20), uow)
# add a spurious batch and order to make sure we're getting the right ones
messagebus.handle(commands.CreateBatch("sku1batch-later", "sku1", 50, today), uow)
messagebus.handle(commands.Allocate("otherorder", "sku1", 30), uow)
messagebus.handle(commands.Allocate("otherorder", "sku2", 10), uow)
assert views.allocations("order1", uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]
①
我们通过使用应用程序的公共入口点——消息总线来设置集成测试的环境。这样可以使我们的测试与任何关于如何存储事物的实现/基础设施细节解耦。
“显而易见”的替代方案 1:使用现有存储库
我们如何向我们的products存储库添加一个辅助方法呢?
一个使用存储库的简单视图(src/allocation/views.py)
from allocation import unit_of_work
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
products = uow.products.for_order(orderid=orderid) #(1)
batches = [b for p in products for b in p.batches] #(2)
return [
{'sku': b.sku, 'batchref': b.reference}
for b in batches
if orderid in b.orderids #(3)
]
①
我们的存储库返回Product对象,我们需要为给定订单中的 SKU 找到所有产品,因此我们将在存储库上构建一个名为.for_order()的新辅助方法。
②
现在我们有产品,但实际上我们想要批次引用,因此我们使用列表推导式获取所有可能的批次。
③
我们再次进行过滤,以获取我们特定订单的批次。这又依赖于我们的Batch对象能够告诉我们它已分配了哪些订单 ID。
我们使用.orderid属性来实现最后一个:
我们模型上一个可以说是不必要的属性(src/allocation/domain/model.py)
class Batch:
...
@property
def orderids(self):
return {l.orderid for l in self._allocations}
您可以开始看到,重用我们现有的存储库和领域模型类并不像您可能认为的那样简单。我们不得不向两者都添加新的辅助方法,并且我们在 Python 中进行了大量的循环和过滤,而这些工作在数据库中可以更有效地完成。
所以是的,好的一面是我们在重用现有的抽象,但坏的一面是,这一切都感觉非常笨拙。
您的领域模型并非针对读操作进行了优化
我们在这里看到的是,领域模型主要设计用于写操作,而我们对读取的需求在概念上通常是完全不同的。
这是下巴抚摸式架构师对 CQRS 的辩解。正如我们之前所说,领域模型不是数据模型——我们试图捕捉业务的运作方式:工作流程,状态变化规则,交换的消息;对系统如何对外部事件和用户输入做出反应的关注。这些大部分内容对只读操作来说是完全无关紧要的。
提示
这种对 CQRS 的辩解与对领域模型模式的辩解有关。如果您正在构建一个简单的 CRUD 应用程序,读取和写入将是密切相关的,因此您不需要领域模型或 CQRS。但是,您的领域越复杂,您就越有可能需要两者。
为了做出一个肤浅的观点,您的领域类将有多个修改状态的方法,而您对只读操作不需要其中任何一个。
随着领域模型的复杂性增加,您将发现自己需要做出越来越多关于如何构建该模型的选择,这使得它对于读操作变得越来越笨拙。
“显而易见”的备选方案 2:使用 ORM
您可能会想,好吧,如果我们的存储库很笨拙,与Products一起工作也很笨拙,那么至少我可以使用我的 ORM 并与Batches一起工作。这就是它的用途!
一个使用 ORM 的简单视图(src/allocation/views.py)
from allocation import unit_of_work, model
def allocations(orderid: str, uow: unit_of_work.AbstractUnitOfWork):
with uow:
batches = uow.session.query(model.Batch).join(
model.OrderLine, model.Batch._allocations
).filter(
model.OrderLine.orderid == orderid
)
return [
{'sku': b.sku, 'batchref': b.batchref}
for b in batches
]
但是,与代码示例中的原始 SQL 版本相比,这样写或理解起来是否实际上更容易呢?在上面看起来可能还不错,但我们可以告诉您,这花了好几次尝试,以及大量查阅 SQLAlchemy 文档。SQL 就是 SQL。
但 ORM 也可能使我们面临性能问题。
SELECT N+1 和其他性能考虑
所谓的SELECT N+1问题是 ORM 的常见性能问题:当检索对象列表时,您的 ORM 通常会执行初始查询,例如,获取它所需对象的所有 ID,然后为每个对象发出单独的查询以检索它们的属性。如果您的对象上有任何外键关系,这种情况尤其可能发生。
注意
公平地说,我们应该说 SQLAlchemy 在避免SELECT N+1问题方面做得相当不错。它在前面的示例中没有显示出来,而且当处理连接的对象时,您可以显式请求急切加载以避免这种问题。
除了SELECT N+1,您可能还有其他原因希望将状态更改的持久化方式与检索当前状态的方式解耦。一组完全规范化的关系表是确保写操作永远不会导致数据损坏的好方法。但是,使用大量连接来检索数据可能会很慢。在这种情况下,通常会添加一些非规范化的视图,构建读取副本,甚至添加缓存层。
完全跳进大白鲨的时间
在这一点上:我们是否已经说服您,我们的原始 SQL 版本并不像最初看起来那么奇怪?也许我们是夸大其词了?等着瞧吧。
因此,无论合理与否,那个硬编码的 SQL 查询都相当丑陋,对吧?如果我们让它更好……
一个更好的查询(src/allocation/views.py)
def allocations(orderid: str, uow: unit_of_work.SqlAlchemyUnitOfWork):
with uow:
results = list(uow.session.execute(
'SELECT sku, batchref FROM allocations_view WHERE orderid = :orderid',
dict(orderid=orderid)
))
...
…通过保持一个完全独立的、非规范化的数据存储来构建我们的视图模型?
嘿嘿嘿,没有外键,只有字符串,YOLO(src/allocation/adapters/orm.py)
allocations_view = Table(
'allocations_view', metadata,
Column('orderid', String(255)),
Column('sku', String(255)),
Column('batchref', String(255)),
)
好吧,更好看的 SQL 查询不会成为任何事情的理由,但是一旦您达到了使用索引的极限,构建一个针对读操作进行优化的非规范化数据的副本并不罕见。
即使使用调整良好的索引,关系数据库在执行连接时会使用大量 CPU。最快的查询将始终是SELECT * from *mytable* WHERE *key* = :*value*。
然而,这种方法不仅仅是为了提高速度,而是为了扩展规模。当我们向关系数据库写入数据时,我们需要确保我们在更改的行上获得锁定,以免出现一致性问题。
如果多个客户端同时更改数据,我们将出现奇怪的竞争条件。然而,当我们读取数据时,可以同时执行的客户端数量是没有限制的。因此,只读存储可以进行水平扩展。
提示
由于读取副本可能不一致,我们可以拥有无限数量的读取副本。如果您正在努力扩展具有复杂数据存储的系统,请问您是否可以构建一个更简单的读模型。
保持读模型的最新状态是挑战!数据库视图(实体化或其他)和触发器是常见的解决方案,但这将限制您在数据库中的操作。我们想向您展示如何重用我们的事件驱动架构。
使用事件处理程序更新读模型表
我们在Allocated事件上添加了第二个处理程序:
Allocated 事件获得了一个新的处理程序(src/allocation/service_layer/messagebus.py)
EVENT_HANDLERS = {
events.Allocated: [
handlers.publish_allocated_event,
handlers.add_allocation_to_read_model
],
我们的更新视图模型代码如下:
更新分配(src/allocation/service_layer/handlers.py)
def add_allocation_to_read_model(
event: events.Allocated, uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
'INSERT INTO allocations_view (orderid, sku, batchref)'
' VALUES (:orderid, :sku, :batchref)',
dict(orderid=event.orderid, sku=event.sku, batchref=event.batchref)
)
uow.commit()
信不信由你,这基本上会起作用!而且它将与我们的其他选项的完全相同的集成测试一起工作。
好吧,您还需要处理Deallocated:
读模型更新的第二个监听器
events.Deallocated: [
handlers.remove_allocation_from_read_model,
handlers.reallocate
],
...
def remove_allocation_from_read_model(
event: events.Deallocated, uow: unit_of_work.SqlAlchemyUnitOfWork,
):
with uow:
uow.session.execute(
'DELETE FROM allocations_view '
' WHERE orderid = :orderid AND sku = :sku',
图 12-2 显示了两个请求之间的流程。
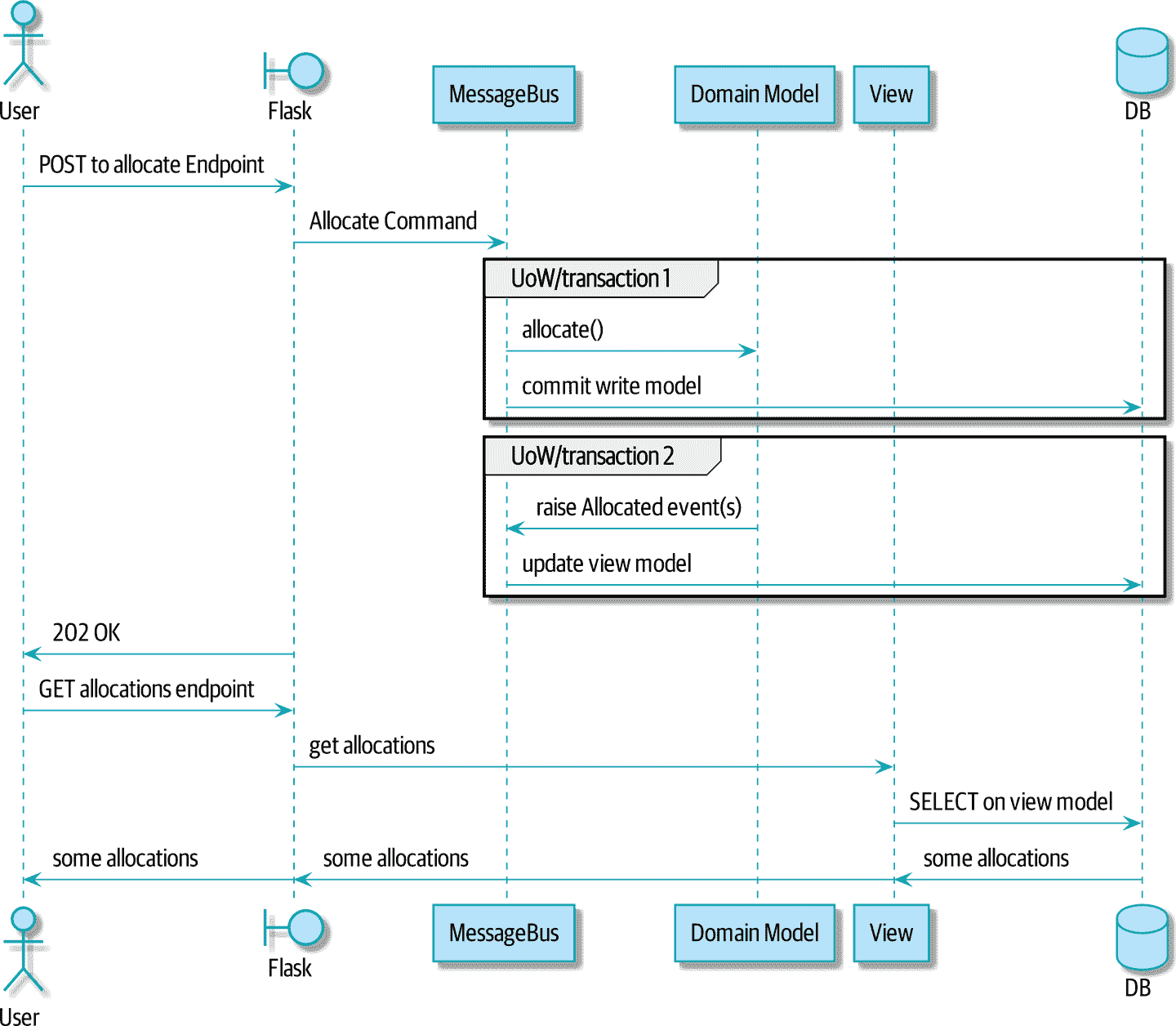
图 12-2. 读模型的序列图
[plantuml, apwp_1202, config=plantuml.cfg]
@startuml
actor User order 1
boundary Flask order 2
participant MessageBus order 3
participant "Domain Model" as Domain order 4
participant View order 9
database DB order 10
User -> Flask: POST to allocate Endpoint
Flask -> MessageBus : Allocate Command
group UoW/transaction 1
MessageBus -> Domain : allocate()
MessageBus -> DB: commit write model
end
group UoW/transaction 2
Domain -> MessageBus : raise Allocated event(s)
MessageBus -> DB : update view model
end
Flask -> User: 202 OK
User -> Flask: GET allocations endpoint
Flask -> View: get allocations
View -> DB: SELECT on view model
DB -> View: some allocations
View -> Flask: some allocations
Flask -> User: some allocations
@enduml
在图 12-2 中,您可以看到在 POST/write 操作中有两个事务,一个用于更新写模型,另一个用于更新读模型,GET/read 操作可以使用。
更改我们的读模型实现很容易
让我们通过看看我们的事件驱动模型在实际中带来的灵活性,来看看如果我们决定使用完全独立的存储引擎 Redis 来实现读模型会发生什么。
只需观看:
处理程序更新 Redis 读模型(src/allocation/service_layer/handlers.py)
def add_allocation_to_read_model(event: events.Allocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, event.batchref)
def remove_allocation_from_read_model(event: events.Deallocated, _):
redis_eventpublisher.update_readmodel(event.orderid, event.sku, None)
我们 Redis 模块中的辅助程序只有一行代码:
Redis 读模型读取和更新(src/allocation/adapters/redis_eventpublisher.py)
def update_readmodel(orderid, sku, batchref):
r.hset(orderid, sku, batchref)
def get_readmodel(orderid):
return r.hgetall(orderid)
(也许现在redis_eventpublisher.py的名称有点不准确,但您明白我的意思。)
而且视图本身也略有变化,以适应其新的后端:
适应 Redis 的视图(src/allocation/views.py)
def allocations(orderid):
batches = redis_eventpublisher.get_readmodel(orderid)
return [
{'batchref': b.decode(), 'sku': s.decode()}
for s, b in batches.items()
]
而且,我们之前编写的完全相同的集成测试仍然通过,因为它们是以与实现解耦的抽象级别编写的:设置将消息放入消息总线,断言针对我们的视图。
提示
如果您决定需要,事件处理程序是管理对读模型的更新的好方法。它们还可以轻松地在以后更改该读模型的实现。
总结
表 12-2 提出了我们各种选项的一些利弊。
事实上,MADE.com 的分配服务确实使用了“全面的”CQRS,在 Redis 中存储了一个读模型,甚至还提供了由 Varnish 提供的第二层缓存。但其用例与我们在这里展示的情况相当不同。对于我们正在构建的分配服务,似乎不太可能需要使用单独的读模型和事件处理程序进行更新。
但随着您的领域模型变得更加丰富和复杂,简化的读模型变得更加引人注目。
表 12-2。各种视图模型选项的权衡
| 选项 | 优点 | 缺点 |
|---|---|---|
| 只使用存储库 | 简单、一致的方法。 | 预期在复杂的查询模式中出现性能问题。 |
| 使用 ORM 自定义查询 | 允许重用 DB 配置和模型定义。 | 添加另一种具有自己怪癖和语法的查询语言。 |
| 使用手动编写的 SQL | 通过标准查询语法可以对性能进行精细控制。 | 必须对手动编写的查询和 ORM 定义进行数据库模式更改。高度规范化的模式可能仍然存在性能限制。 |
| 使用事件创建单独的读取存储 | 只读副本易于扩展。在数据更改时可以构建视图,以使查询尽可能简单。 | 复杂的技术。哈里将永远怀疑你的品味和动机。 |
通常,您的读操作将作用于与写模型相同的概念对象,因此可以使用 ORM,在存储库中添加一些读取方法,并对读取操作使用领域模型类非常好。
在我们的书例中,读操作涉及的概念实体与我们的领域模型非常不同。分配服务以单个 SKU 的“批次”为单位思考,但用户关心的是整个订单的分配,包括多个 SKU,因此使用 ORM 最终有点尴尬。我们可能会倾向于选择我们在本章开头展示的原始 SQL 视图。
在这一点上,让我们继续进入我们的最后一章。
第十三章:依赖注入(和引导)
原文:13: Dependency Injection (and Bootstrapping)
译者:飞龙
依赖注入(DI)在 Python 世界中备受怀疑。迄今为止,我们在本书的示例代码中一直很好地没有使用它!
在本章中,我们将探讨代码中的一些痛点,这些痛点导致我们考虑使用 DI,并提出一些如何实现它的选项,让您选择最符合 Python 风格的方式。
我们还将向我们的架构添加一个名为bootstrap.py的新组件;它将负责依赖注入,以及我们经常需要的一些其他初始化工作。我们将解释为什么这种东西在面向对象语言中被称为组合根,以及为什么引导脚本对我们的目的来说是完全合适的。
图 13-1 显示了我们的应用程序在没有引导程序的情况下的样子:入口点做了很多初始化和传递我们的主要依赖项 UoW。
提示
如果您还没有这样做,建议在继续本章之前阅读第三章,特别是功能与面向对象依赖管理的讨论。
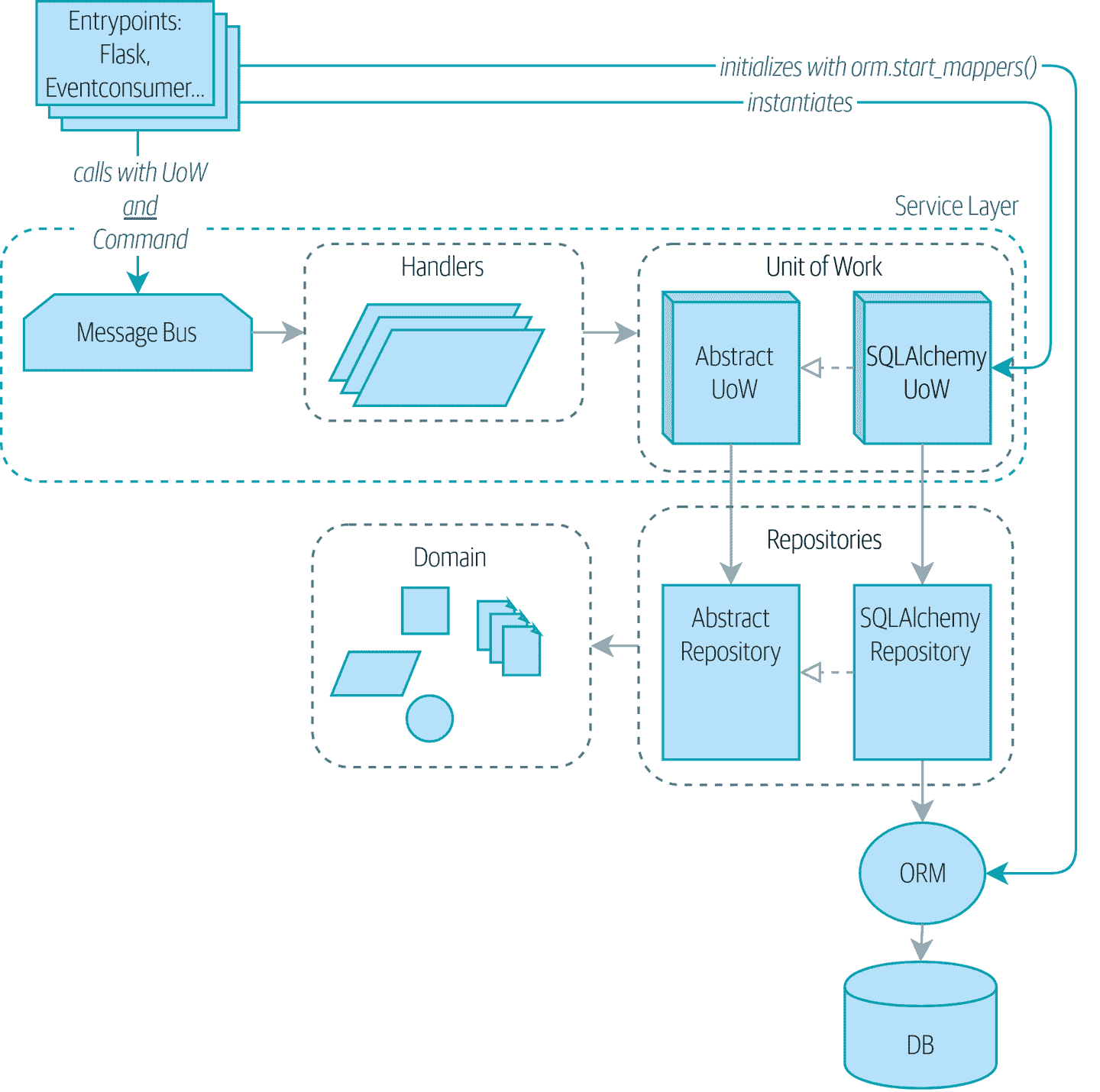
图 13-1:没有引导:入口点做了很多事情
提示
本章的代码位于 GitHub 上的 chapter_13_dependency_injection 分支中(https://oreil.ly/-B7e6):
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_13_dependency_injection
# or to code along, checkout the previous chapter:
git checkout chapter_12_cqrs
图 13-2 显示了我们的引导程序接管了这些责任。
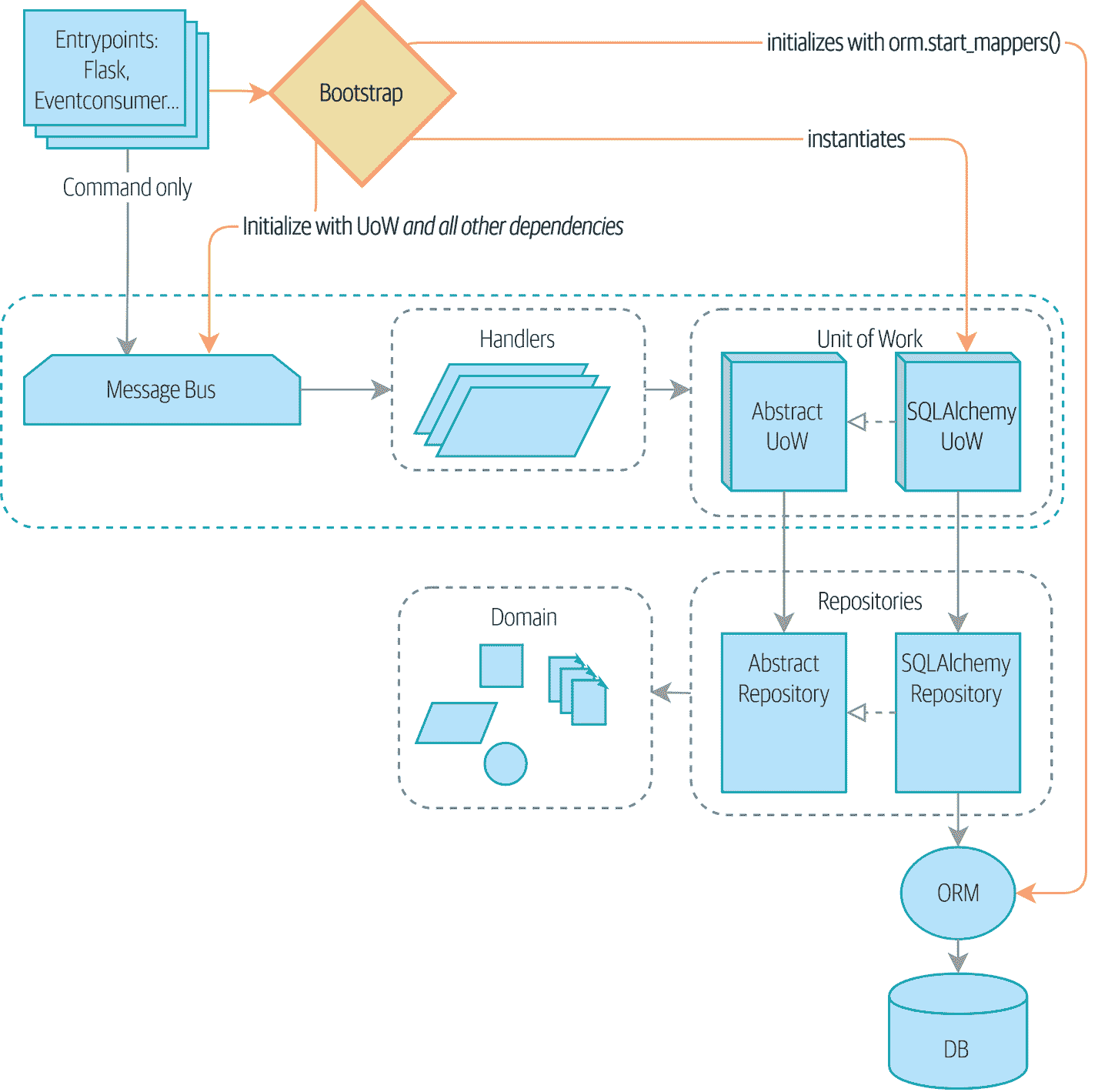
图 13-2:引导程序在一个地方处理所有这些
隐式依赖与显式依赖
根据您特定的大脑类型,您可能在心中略感不安。让我们把它公开化。我们向您展示了两种管理依赖项并对其进行测试的方式。
对于我们的数据库依赖,我们建立了一个明确的依赖关系框架,并提供了易于在测试中覆盖的选项。我们的主处理程序函数声明了对 UoW 的明确依赖:
我们的处理程序对 UoW 有明确的依赖(src/allocation/service_layer/handlers.py)
def allocate(
cmd: commands.Allocate, uow: unit_of_work.AbstractUnitOfWork
):
这使得在我们的服务层测试中轻松替换虚假 UoW 成为可能:
针对虚假 UoW 的服务层测试:(tests/unit/test_services.py)
uow = FakeUnitOfWork()
messagebus.handle([...], uow)
UoW 本身声明了对会话工厂的明确依赖:
UoW 依赖于会话工厂(src/allocation/service_layer/unit_of_work.py)
class SqlAlchemyUnitOfWork(AbstractUnitOfWork):
def __init__(self, session_factory=DEFAULT_SESSION_FACTORY):
self.session_factory = session_factory
...
我们利用它在我们的集成测试中,有时可以使用 SQLite 而不是 Postgres:
针对不同数据库的集成测试(tests/integration/test_uow.py)
def test_rolls_back_uncommitted_work_by_default(sqlite_session_factory):
uow = unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory) #(1)
①
集成测试将默认的 Postgres session_factory替换为 SQLite。
显式依赖完全奇怪和 Java 风格吗?
如果您习惯于 Python 中通常发生的事情,您可能会觉得这有点奇怪。标准做法是通过简单导入隐式声明我们的依赖,然后如果我们需要在测试中更改它,我们可以进行 monkeypatch,这在动态语言中是正确和正确的:
电子邮件发送作为正常的基于导入的依赖(src/allocation/service_layer/handlers.py)
from allocation.adapters import email, redis_eventpublisher #(1)
...
def send_out_of_stock_notification(
event: events.OutOfStock,
uow: unit_of_work.AbstractUnitOfWork,
):
email.send( #(2)
"stock@made.com",
f"Out of stock for {event.sku}",
)
①
硬编码导入
②
直接调用特定的电子邮件发送器
为了我们的测试,为什么要用不必要的参数污染我们的应用程序代码?mock.patch使得 monkeypatch 变得简单而容易:
模拟点补丁,谢谢 Michael Foord(tests/unit/test_handlers.py)
with mock.patch("allocation.adapters.email.send") as mock_send_mail:
...
问题在于,我们让它看起来很容易,因为我们的玩具示例不发送真正的电子邮件(email.send_mail只是print),但在现实生活中,您最终将不得不为每个可能引起缺货通知的测试调用mock.patch。如果您曾经在大量使用模拟以防止不需要的副作用的代码库上工作过,您将知道那些模拟的样板代码有多讨厌。
您会知道模拟将我们紧密耦合到实现。通过选择对email.send_mail进行 monkeypatch,我们将绑定到执行import email,如果我们想要执行from email import send_mail,一个微不足道的重构,我们将不得不更改所有我们的模拟。
因此这是一个权衡。是的,严格来说,声明显式依赖是不必要的,并且使用它们会使我们的应用代码稍微更复杂。但作为回报,我们将获得更容易编写和管理的测试。
此外,声明显式依赖是依赖倒置原则的一个例子 - 而不是对特定细节的(隐式)依赖,我们对抽象有一个(显式)依赖:
显式胜于隐式。
——Python 之禅
显式依赖更抽象(src/allocation/service_layer/handlers.py)
def send_out_of_stock_notification(
event: events.OutOfStock, send_mail: Callable,
):
send_mail(
'stock@made.com',
f'Out of stock for {event.sku}',
)
但是,如果我们改为显式声明所有这些依赖关系,谁会注入它们,以及如何注入?到目前为止,我们真的只是在传递 UoW:我们的测试使用FakeUnitOfWork,而 Flask 和 Redis 事件消费者入口使用真正的 UoW,并且消息总线将它们传递给我们的命令处理程序。如果我们添加真实和假的电子邮件类,谁会创建它们并传递它们?
这对于 Flask、Redis 和我们的测试来说是额外的(重复的)累赘。此外,将所有传递依赖项到正确处理程序的责任都放在消息总线上,感觉像是违反了 SRP。
相反,我们将寻找一种称为组合根(对我们来说是引导脚本)的模式,1,我们将进行一些“手动 DI”(无需框架的依赖注入)。请参阅图 13-3。2

图 13-3:入口点和消息总线之间的引导程序
准备处理程序:使用闭包和部分函数进行手动 DI
将具有依赖关系的函数转换为一个准备好以后使用这些依赖项已注入的函数的方法之一是使用闭包或部分函数将函数与其依赖项组合起来:
使用闭包或部分函数进行 DI 的示例
# existing allocate function, with abstract uow dependency
def allocate(
cmd: commands.Allocate,
uow: unit_of_work.AbstractUnitOfWork,
):
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with uow:
...
# bootstrap script prepares actual UoW
def bootstrap(..):
uow = unit_of_work.SqlAlchemyUnitOfWork()
# prepare a version of the allocate fn with UoW dependency captured in a closure
allocate_composed = lambda cmd: allocate(cmd, uow)
# or, equivalently (this gets you a nicer stack trace)
def allocate_composed(cmd):
return allocate(cmd, uow)
# alternatively with a partial
import functools
allocate_composed = functools.partial(allocate, uow=uow) #(1)
# later at runtime, we can call the partial function, and it will have
# the UoW already bound
allocate_composed(cmd)
①
闭包(lambda 或命名函数)和functools.partial之间的区别在于前者使用变量的延迟绑定,如果任何依赖项是可变的,这可能会导致混淆。
这里是send_out_of_stock_notification()处理程序的相同模式,它具有不同的依赖项:
另一个闭包和部分函数的例子
def send_out_of_stock_notification(
event: events.OutOfStock, send_mail: Callable,
):
send_mail(
'stock@made.com',
...
# prepare a version of the send_out_of_stock_notification with dependencies
sosn_composed = lambda event: send_out_of_stock_notification(event, email.send_mail)
...
# later, at runtime:
sosn_composed(event) # will have email.send_mail already injected in
使用类的替代方法
对于那些有一些函数式编程经验的人来说,闭包和部分函数会让人感到熟悉。这里有一个使用类的替代方法,可能会吸引其他人。尽管如此,它需要将所有我们的处理程序函数重写为类:
使用类进行 DI
# we replace the old `def allocate(cmd, uow)` with:
class AllocateHandler:
def __init__(self, uow: unit_of_work.AbstractUnitOfWork): #(2)
self.uow = uow
def __call__(self, cmd: commands.Allocate): #(1)
line = OrderLine(cmd.orderid, cmd.sku, cmd.qty)
with self.uow:
# rest of handler method as before
...
# bootstrap script prepares actual UoW
uow = unit_of_work.SqlAlchemyUnitOfWork()
# then prepares a version of the allocate fn with dependencies already injected
allocate = AllocateHandler(uow)
...
# later at runtime, we can call the handler instance, and it will have
# the UoW already injected
allocate(cmd)
①
该类旨在生成可调用函数,因此它具有*call*方法。
②
但我们使用init来声明它需要的依赖项。如果您曾经制作过基于类的描述符,或者接受参数的基于类的上下文管理器,这种事情会让您感到熟悉。
使用您和您的团队感觉更舒适的那个。
引导脚本
我们希望我们的引导脚本执行以下操作:
-
声明默认依赖项,但允许我们覆盖它们
-
做我们需要启动应用程序的“init”工作
-
将所有依赖项注入到我们的处理程序中
-
给我们返回应用程序的核心对象,消息总线
这是第一步:
一个引导函数(src/allocation/bootstrap.py)
def bootstrap(
start_orm: bool = True, #(1)
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(), #(2)
send_mail: Callable = email.send,
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:
if start_orm:
orm.start_mappers() #(1)
dependencies = {"uow": uow, "send_mail": send_mail, "publish": publish}
injected_event_handlers = { #(3)
event_type: [
inject_dependencies(handler, dependencies)
for handler in event_handlers
]
for event_type, event_handlers in handlers.EVENT_HANDLERS.items()
}
injected_command_handlers = { #(3)
command_type: inject_dependencies(handler, dependencies)
for command_type, handler in handlers.COMMAND_HANDLERS.items()
}
return messagebus.MessageBus( #(4)
uow=uow,
event_handlers=injected_event_handlers,
command_handlers=injected_command_handlers,
)
①
orm.start_mappers()是我们需要在应用程序开始时执行一次的初始化工作的示例。我们还看到一些设置logging模块的事情。
②
我们可以使用参数默认值来定义正常/生产默认值。将它们放在一个地方很好,但有时依赖项在构建时会产生一些副作用,这种情况下,您可能更喜欢将它们默认为None。
③
我们通过使用一个名为inject_dependencies()的函数来构建我们注入的处理程序映射的版本,接下来我们将展示它。
④
我们返回一个配置好的消息总线,可以立即使用。
这是我们通过检查将依赖项注入处理程序函数的方法:
通过检查函数签名进行 DI(src/allocation/bootstrap.py)
def inject_dependencies(handler, dependencies):
params = inspect.signature(handler).parameters #(1)
deps = {
name: dependency
for name, dependency in dependencies.items() #(2)
if name in params
}
return lambda message: handler(message, **deps) #(3)
①
我们检查我们的命令/事件处理程序的参数。
②
我们按名称将它们与我们的依赖项匹配。
③
我们将它们作为 kwargs 注入以产生一个 partial。
消息总线在运行时被赋予处理程序
我们的消息总线将不再是静态的;它需要已经注入的处理程序。因此,我们将其从模块转换为可配置的类:
MessageBus 作为一个类(src/allocation/service_layer/messagebus.py)
class MessageBus: #(1)
def __init__(
self,
uow: unit_of_work.AbstractUnitOfWork,
event_handlers: Dict[Type[events.Event], List[Callable]], #(2)
command_handlers: Dict[Type[commands.Command], Callable], #(2)
):
self.uow = uow
self.event_handlers = event_handlers
self.command_handlers = command_handlers
def handle(self, message: Message): #(3)
self.queue = [message] #(4)
while self.queue:
message = self.queue.pop(0)
if isinstance(message, events.Event):
self.handle_event(message)
elif isinstance(message, commands.Command):
self.handle_command(message)
else:
raise Exception(f"{message} was not an Event or Command")
①
消息总线变成了一个类…
②
…它已经注入了依赖项。
③
主要的handle()函数基本相同,只是一些属性和方法移到了self上。
④
像这样使用self.queue是不线程安全的,如果您使用线程可能会有问题,因为我们已经将总线实例在 Flask 应用程序上下文中全局化了。这是需要注意的问题。
总线中还有什么变化?
事件和命令处理逻辑保持不变(src/allocation/service_layer/messagebus.py)
def handle_event(self, event: events.Event):
for handler in self.event_handlers[type(event)]: #(1)
try:
logger.debug("handling event %s with handler %s", event, handler)
handler(event) #(2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling event %s", event)
continue
def handle_command(self, command: commands.Command):
logger.debug("handling command %s", command)
try:
handler = self.command_handlers[type(command)] #(1)
handler(command) #(2)
self.queue.extend(self.uow.collect_new_events())
except Exception:
logger.exception("Exception handling command %s", command)
raise
①
handle_event和handle_command基本相同,但是不再索引静态的EVENT_HANDLERS或COMMAND_HANDLERS字典,而是使用self上的版本。
②
我们不再将 UoW 传递给处理程序,我们期望处理程序已经具有了所有它们的依赖项,因此它们只需要一个参数,即特定的事件或命令。
在我们的入口点中使用 Bootstrap
在我们应用程序的入口点中,我们现在只需调用bootstrap.bootstrap(),就可以得到一个准备就绪的消息总线,而不是配置 UoW 和其他内容:
Flask 调用 bootstrap(src/allocation/entrypoints/flask_app.py)
-from allocation import views
+from allocation import bootstrap, views
app = Flask(__name__)
-orm.start_mappers() #(1)
+bus = bootstrap.bootstrap()
@app.route("/add_batch", methods=["POST"])
@@ -19,8 +16,7 @@ def add_batch():
cmd = commands.CreateBatch(
request.json["ref"], request.json["sku"], request.json["qty"], eta
)
- uow = unit_of_work.SqlAlchemyUnitOfWork() #(2)
- messagebus.handle(cmd, uow)
+ bus.handle(cmd) #(3)
return "OK", 201
①
我们不再需要调用start_orm();启动脚本的初始化阶段会处理这个问题。
②
我们不再需要显式构建特定类型的 UoW;启动脚本的默认值会处理这个问题。
③
现在我们的消息总线是一个特定的实例,而不是全局模块。3
在我们的测试中初始化 DI
在测试中,我们可以使用bootstrap.bootstrap()并覆盖默认值以获得自定义消息总线。以下是集成测试中的一个示例:
覆盖引导默认值(tests/integration/test_views.py)
@pytest.fixture
def sqlite_bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True, #(1)
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory), #(2)
send_mail=lambda *args: None, #(3)
publish=lambda *args: None, #(3)
)
yield bus
clear_mappers()
def test_allocations_view(sqlite_bus):
sqlite_bus.handle(commands.CreateBatch("sku1batch", "sku1", 50, None))
sqlite_bus.handle(commands.CreateBatch("sku2batch", "sku2", 50, today))
...
assert views.allocations("order1", sqlite_bus.uow) == [
{"sku": "sku1", "batchref": "sku1batch"},
{"sku": "sku2", "batchref": "sku2batch"},
]
①
我们确实希望启动 ORM…
②
…因为我们将使用真实的 UoW,尽管使用的是内存数据库。
③
但我们不需要发送电子邮件或发布,所以我们将它们设置为 noops。
在我们的单元测试中,相反,我们可以重用我们的FakeUnitOfWork:
在单元测试中引导(tests/unit/test_handlers.py)
def bootstrap_test_app():
return bootstrap.bootstrap(
start_orm=False, #(1)
uow=FakeUnitOfWork(), #(2)
send_mail=lambda *args: None, #(3)
publish=lambda *args: None, #(3)
)
①
不需要启动 ORM…
②
…因为虚假的 UoW 不使用它。
③
我们也想伪造我们的电子邮件和 Redis 适配器。
这样就消除了一些重复,并且我们将一堆设置和合理的默认值移到了一个地方。
“正确”构建适配器的示例
为了真正了解它是如何工作的,让我们通过一个示例来演示如何“正确”构建适配器并进行依赖注入。
目前,我们有两种类型的依赖关系:
两种类型的依赖关系(src/allocation/service_layer/messagebus.py)
uow: unit_of_work.AbstractUnitOfWork, #(1)
send_mail: Callable, #(2)
publish: Callable, #(2)
①
UoW 有一个抽象基类。这是声明和管理外部依赖关系的重量级选项。当依赖关系相对复杂时,我们将使用它。
②
我们的电子邮件发送器和发布/订阅发布者被定义为函数。这对于简单的依赖关系完全有效。
以下是我们在工作中发现自己注入的一些东西:
-
一个 S3 文件系统客户端
-
一个键/值存储客户端
-
一个
requests会话对象
其中大多数将具有更复杂的 API,无法将其捕获为单个函数:读取和写入,GET 和 POST 等等。
尽管它很简单,但让我们以send_mail为例,讨论如何定义更复杂的依赖关系。
定义抽象和具体实现
我们将想象一个更通用的通知 API。可能是电子邮件,可能是短信,也可能是 Slack 帖子。
一个 ABC 和一个具体的实现(src/allocation/adapters/notifications.py)
class AbstractNotifications(abc.ABC):
@abc.abstractmethod
def send(self, destination, message):
raise NotImplementedError
...
class EmailNotifications(AbstractNotifications):
def __init__(self, smtp_host=DEFAULT_HOST, port=DEFAULT_PORT):
self.server = smtplib.SMTP(smtp_host, port=port)
self.server.noop()
def send(self, destination, message):
msg = f'Subject: allocation service notification\n{message}'
self.server.sendmail(
from_addr='allocations@example.com',
to_addrs=[destination],
msg=msg
)
我们在引导脚本中更改了依赖项:
消息总线中的通知(src/allocation/bootstrap.py)
def bootstrap(
start_orm: bool = True,
uow: unit_of_work.AbstractUnitOfWork = unit_of_work.SqlAlchemyUnitOfWork(),
- send_mail: Callable = email.send,
+ notifications: AbstractNotifications = EmailNotifications(),
publish: Callable = redis_eventpublisher.publish,
) -> messagebus.MessageBus:
为您的测试创建一个虚假版本
我们通过并为单元测试定义一个虚假版本:
虚假通知(tests/unit/test_handlers.py)
class FakeNotifications(notifications.AbstractNotifications):
def __init__(self):
self.sent = defaultdict(list) # type: Dict[str, List[str]]
def send(self, destination, message):
self.sent[destination].append(message)
...
并在我们的测试中使用它:
测试稍作更改(tests/unit/test_handlers.py)
def test_sends_email_on_out_of_stock_error(self):
fake_notifs = FakeNotifications()
bus = bootstrap.bootstrap(
start_orm=False,
uow=FakeUnitOfWork(),
notifications=fake_notifs,
publish=lambda *args: None,
)
bus.handle(commands.CreateBatch("b1", "POPULAR-CURTAINS", 9, None))
bus.handle(commands.Allocate("o1", "POPULAR-CURTAINS", 10))
assert fake_notifs.sent['stock@made.com'] == [
f"Out of stock for POPULAR-CURTAINS",
]
弄清楚如何集成测试真实的东西
现在我们测试真实的东西,通常使用端到端或集成测试。我们在 Docker 开发环境中使用MailHog作为真实的电子邮件服务器:
具有真实虚假电子邮件服务器的 Docker-compose 配置(docker-compose.yml)
version: "3"
services:
redis_pubsub:
build:
context: .
dockerfile: Dockerfile
image: allocation-image
...
api:
image: allocation-image
...
postgres:
image: postgres:9.6
...
redis:
image: redis:alpine
...
mailhog:
image: mailhog/mailhog
ports:
- "11025:1025"
- "18025:8025"
在我们的集成测试中,我们使用真正的EmailNotifications类,与 Docker 集群中的 MailHog 服务器通信:
电子邮件的集成测试(tests/integration/test_email.py)
@pytest.fixture
def bus(sqlite_session_factory):
bus = bootstrap.bootstrap(
start_orm=True,
uow=unit_of_work.SqlAlchemyUnitOfWork(sqlite_session_factory),
notifications=notifications.EmailNotifications(), #(1)
publish=lambda *args: None,
)
yield bus
clear_mappers()
def get_email_from_mailhog(sku): #(2)
host, port = map(config.get_email_host_and_port().get, ["host", "http_port"])
all_emails = requests.get(f"http://{host}:{port}/api/v2/messages").json()
return next(m for m in all_emails["items"] if sku in str(m))
def test_out_of_stock_email(bus):
sku = random_sku()
bus.handle(commands.CreateBatch("batch1", sku, 9, None)) #(3)
bus.handle(commands.Allocate("order1", sku, 10))
email = get_email_from_mailhog(sku)
assert email["Raw"]["From"] == "allocations@example.com" #(4)
assert email["Raw"]["To"] == ["stock@made.com"]
assert f"Out of stock for {sku}" in email["Raw"]["Data"]
①
我们使用我们的引导程序构建一个与真实通知类交互的消息总线。
②
我们弄清楚如何从我们的“真实”电子邮件服务器中获取电子邮件。
③
我们使用总线来进行测试设置。
④
出乎意料的是,这实际上非常顺利地完成了!
就是这样。
总结
一旦你有了多个适配器,除非你进行某种依赖注入,否则手动传递依赖关系会让你感到很痛苦。
设置依赖注入只是在启动应用程序时需要做的许多典型设置/初始化活动之一。将所有这些放在一个引导脚本中通常是一个好主意。
引导脚本也是一个很好的地方,可以为适配器提供合理的默认配置,并且作为一个单一的地方,可以用虚假的适配器覆盖测试。
如果你发现自己需要在多个级别进行 DI,例如,如果你有一系列组件的链式依赖需要 DI,那么依赖注入框架可能会很有用。
本章还提供了一个实际示例,将隐式/简单的依赖关系改变为“适当”的适配器,将 ABC 分离出来,定义其真实和虚假的实现,并思考集成测试。
这些是我们想要覆盖的最后几个模式,这将我们带到了第二部分的结尾。在结语中,我们将尝试为您提供一些在现实世界中应用这些技术的指导。
1 因为 Python 不是一个“纯”面向对象的语言,Python 开发人员并不一定习惯于需要将一组对象组合成一个工作应用程序的概念。我们只是选择我们的入口点,然后从上到下运行代码。
2 Mark Seemann 将这称为Pure DI,有时也称为Vanilla DI。
3 但是,如果有意义的话,它仍然是flask_app模块范围内的全局变量。如果你想要使用 Flask 测试客户端而不是像我们一样使用 Docker 来测试你的 Flask 应用程序,这可能会导致问题。如果你遇到这种情况,值得研究Flask 应用程序工厂。
结语
译者:飞龙
现在怎么办?
哇!在这本书中,我们涵盖了很多内容,对于我们的大多数读者来说,所有这些想法都是新的。考虑到这一点,我们不能希望让您成为这些技术的专家。我们真正能做的只是向您展示大致的想法,并提供足够的代码让您可以开始从头写东西。
我们在这本书中展示的代码并不是经过严格测试的生产代码:它是一组乐高积木,你可以用它来建造你的第一个房子、太空飞船和摩天大楼。
这给我们留下了两项重要任务。我们想讨论如何在现有系统中真正应用这些想法,并且我们需要警告您有些我们不得不跳过的事情。我们已经给了您一整套新的自毁方式,所以我们应该讨论一些基本的枪支安全知识。
我怎样才能从这里到那里?
很多人可能会想到这样的问题:
“好的鲍勃和哈里,这一切都很好,如果我有机会被聘用来开发一个全新的服务,我知道该怎么做。但与此同时,我在这里面对我的 Django 泥球,我看不到任何办法可以达到你们的干净、完美、无瑕、简单的模型。从这里没有办法。”
我们明白你的想法。一旦您已经构建了一个大球泥,就很难知道如何开始改进。实际上,我们需要一步一步地解决问题。
首先要明确的是:您要解决什么问题?软件是否太难更改?性能是否令人无法接受?是否有奇怪的、无法解释的错误?
有一个明确的目标将有助于您优先处理需要完成的工作,并且重要的是,向团队的其他成员传达做这些工作的原因。企业倾向于对技术债务和重构采取务实的方法,只要工程师能够就修复问题提出合理的论据。
提示
对系统进行复杂的更改通常更容易推销,如果将其与功能工作联系起来。也许您正在推出新产品或将您的服务开放给新市场?这是在修复基础设施上花费工程资源的正确时机。在一个需要交付的六个月项目中,更容易争取三周的清理工作。鲍勃称之为架构税。
分离纠缠的责任
在书的开头,我们说大球泥的主要特征是同质性:系统的每个部分看起来都一样,因为我们没有明确每个组件的责任。为了解决这个问题,我们需要开始分离责任并引入明确的边界。我们可以做的第一件事之一是开始构建一个服务层(图 E-1)。
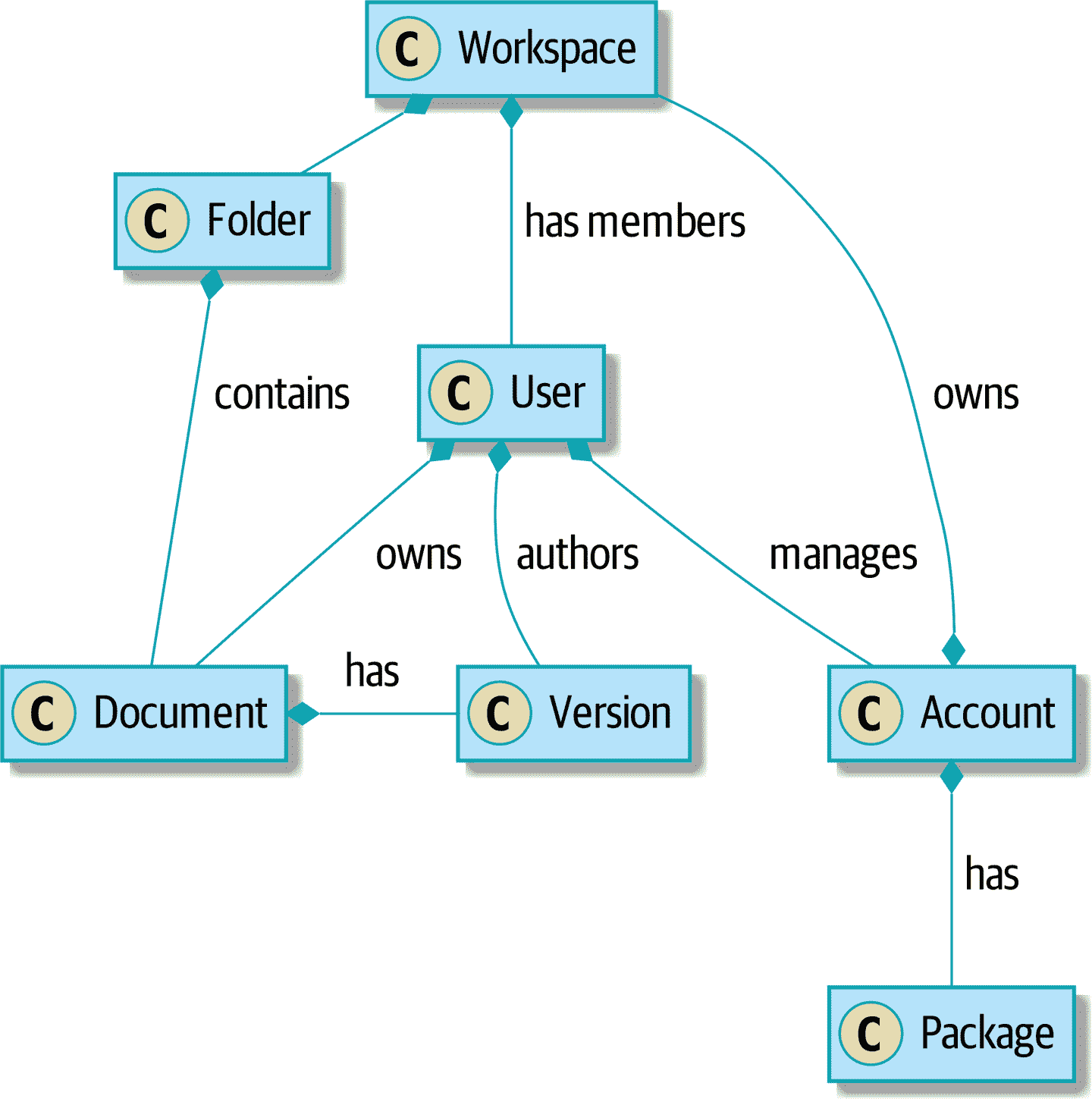
图 E-1. 协作系统的领域
[plantuml, apwp_ep01, config=plantuml.cfg]
@startuml
hide empty members
Workspace *- Folder : contains
Account *- Workspace : owns
Account *-- Package : has
User *-- Account : manages
Workspace *-- User : has members
User *-- Document : owns
Folder *-- Document : contains
Document *- Version: has
User *-- Version: authors
@enduml
这就是鲍勃第一次学会如何分解泥球的系统,而且这是一个难题。逻辑无处不在——在网页中,在经理对象中,在辅助程序中,在我们编写的用于抽象经理和辅助程序的庞大服务类中,以及在我们编写的用于分解服务的复杂命令对象中。
如果您正在处理已经到达这一步的系统,情况可能会让人感到绝望,但开始清理一个长满杂草的花园永远不会太晚。最终,我们雇了一个知道自己在做什么的架构师,他帮助我们重新控制了局面。
首先要做的是弄清楚系统的用例。如果您有用户界面,它执行了哪些操作?如果您有后端处理组件,也许每个 cron 作业或 Celery 作业都是一个单独的用例。您的每个用例都需要有一个命令式的名称:例如,应用计费费用、清理废弃账户或提高采购订单。
在我们的情况下,大多数用例都是经理类的一部分,名称如创建工作空间或删除文档版本。每个用例都是从 Web 前端调用的。
我们的目标是为每个支持的操作创建一个单独的函数或类,用于编排要执行的工作。每个用例应执行以下操作:
-
如有需要,启动自己的数据库事务
-
获取所需的任何数据
-
检查任何前提条件(请参阅[附录 E]中的确保模式(app05.xhtml#appendix_validation))
-
更新领域模型
-
持久化任何更改
每个用例应作为一个原子单元成功或失败。您可能需要从另一个用例中调用一个用例。没问题;只需做个记录,并尽量避免长时间运行的数据库事务。
注意
我们遇到的最大问题之一是管理器方法调用其他管理器方法,并且数据访问可以发生在模型对象本身。很难在不跨越整个代码库进行寻宝之旅的情况下理解每个操作的含义。将所有逻辑汇总到一个方法中,并使用 UoW 来控制我们的事务,使系统更容易理解。
提示
如果在用例函数中存在重复,也没关系。我们不是要编写完美的代码;我们只是试图提取一些有意义的层。在几个地方重复一些代码要比让用例函数在长链中相互调用要好。
这是一个很好的机会,可以将任何数据访问或编排代码从领域模型中提取出来,并放入用例中。我们还应该尝试将 I/O 问题(例如发送电子邮件、写文件)从领域模型中提取出来,并放入用例函数中。我们应用第三章中关于抽象的技术,以便在执行 I/O 时保持我们的处理程序可单元测试。
这些用例函数主要涉及日志记录、数据访问和错误处理。完成此步骤后,您将了解程序实际执行的操作,并且有一种方法来确保每个操作都有明确定义的开始和结束。我们将迈出一步,朝着构建纯领域模型迈进。
阅读 Michael C. Feathers 的《与遗留代码有效地工作》(Prentice Hall)以获取有关对遗留代码进行测试和开始分离责任的指导。
识别聚合和有界上下文
在我们的案例研究中,代码库的一部分问题是对象图高度连接。每个帐户都有许多工作空间,每个工作空间都有许多成员,所有这些成员都有自己的帐户。每个工作空间包含许多文档,每个文档都有许多版本。
你无法在类图中表达事物的全部恐怖。首先,实际上并没有一个与用户相关的单个帐户。相反,有一个奇怪的规则要求您通过工作空间枚举与用户关联的所有帐户,并选择创建日期最早的帐户。
系统中的每个对象都是继承层次结构的一部分,其中包括SecureObject和Version。这种继承层次结构直接在数据库模式中进行了镜像,因此每个查询都必须跨越 10 个不同的表进行连接,并查看鉴别器列,以便确定正在处理的对象的类型。
代码库使得可以像这样“点”穿过这些对象:
user.account.workspaces[0].documents.versions[1].owner.account.settings[0];
使用 Django ORM 或 SQLAlchemy 构建系统很容易,但应该避免。尽管这很方便,但很难理解性能,因为每个属性可能触发对数据库的查找。
提示
聚合是一致性边界。一般来说,每个用例应一次只更新一个聚合。一个处理程序从存储库中获取一个聚合,修改其状态,并引发任何作为结果发生的事件。如果您需要来自系统其他部分的数据,完全可以使用读取模型,但要避免在单个事务中更新多个聚合。当我们选择将代码分离为不同的聚合时,我们明确选择使它们最终一致。
一堆操作需要我们以这种方式循环遍历对象,例如:
# Lock a user's workspaces for nonpayment
def lock_account(user):
for workspace in user.account.workspaces:
workspace.archive()
甚至可以递归遍历文件夹和文档的集合:
def lock_documents_in_folder(folder):
for doc in folder.documents:
doc.archive()
for child in folder.children:
lock_documents_in_folder(child)
这些操作严重影响了性能,但修复它们意味着放弃我们的单个对象图。相反,我们开始识别聚合并打破对象之间的直接链接。
注意
我们在第十二章中谈到了臭名昭著的SELECT N+1问题,以及在查询数据和命令数据时可能选择使用不同的技术。
大多数情况下,我们通过用标识符替换直接引用来实现这一点。
在聚合之前:
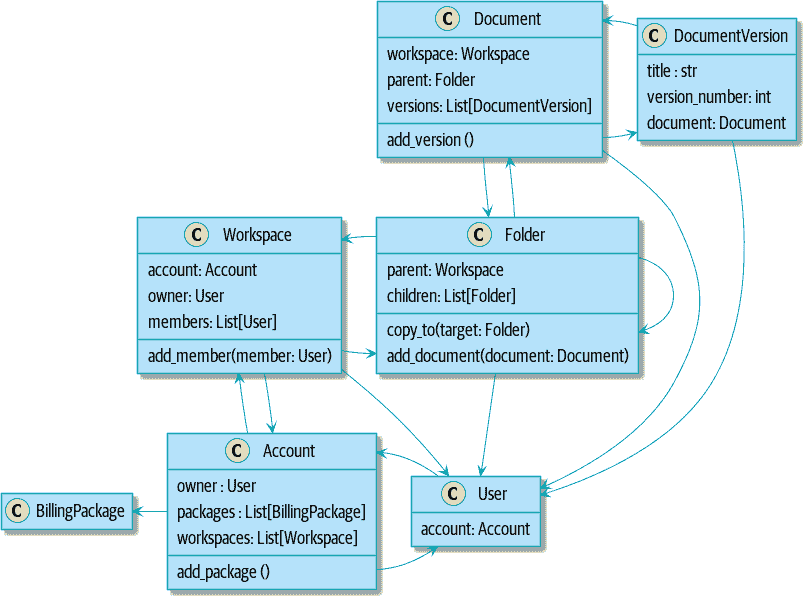
[plantuml, apwp_ep02, config=plantuml.cfg]
@startuml
hide empty members
class Document {
add_version ()
workspace: Workspace
parent: Folder
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
document: Document
}
class Account {
add_package ()
owner : User
packages : List[BillingPackage]
workspaces: List[Workspace]
}
class BillingPackage {
}
class Workspace {
add_member(member: User)
account: Account
owner: User
members: List[User]
}
class Folder {
parent: Workspace
children: List[Folder]
copy_to(target: Folder)
add_document(document: Document)
}
class User {
account: Account
}
Account --> Workspace
Account --> BillingPackage
Account --> User
Workspace --> User
Workspace --> Folder
Workspace --> Account
Folder --> Folder
Folder --> Document
Folder --> Workspace
Folder --> User
Document --> DocumentVersion
Document --> Folder
Document --> User
DocumentVersion --> Document
DocumentVersion --> User
User --> Account
@enduml
建模后:

[plantuml, apwp_ep03, config=plantuml.cfg]
@startuml
hide empty members
frame Document {
class Document {
add_version ()
workspace_id: int
parent_folder: int
versions: List[DocumentVersion]
}
class DocumentVersion {
title : str
version_number: int
}
}
frame Account {
class Account {
add_package ()
owner : int
packages : List[BillingPackage]
}
class BillingPackage {
}
}
frame Workspace {
class Workspace {
add_member(member: int)
account_id: int
owner: int
members: List[int]
}
}
frame Folder {
class Folder {
workspace_id : int
children: List[int]
copy_to(target: int)
}
}
Document o-- DocumentVersion
Account o-- BillingPackage
@enduml
提示
双向链接通常表明您的聚合不正确。在我们的原始代码中,Document知道其包含的Folder,而Folder有一组Documents。这使得遍历对象图很容易,但阻止我们正确思考我们需要的一致性边界。我们通过使用引用来拆分聚合。在新模型中,Document引用其parent_folder,但无法直接访问Folder。
如果我们需要读取数据,我们会避免编写复杂的循环和转换,并尝试用直接的 SQL 替换它们。例如,我们的一个屏幕是文件夹和文档的树形视图。
这个屏幕在数据库上非常重,因为它依赖于触发延迟加载的 ORM 的嵌套for循环。
提示
我们在第十一章中使用了相同的技术,用一个简单的 SQL 查询替换了对 ORM 对象的嵌套循环。这是 CQRS 方法的第一步。
经过长时间的思考,我们用一个又大又丑的存储过程替换了 ORM 代码。代码看起来很糟糕,但速度要快得多,并有助于打破Folder和Document之间的联系。
当我们需要写入数据时,我们逐个更改单个聚合,并引入消息总线来处理事件。例如,在新模型中,当我们锁定一个账户时,我们可以首先查询所有受影响的工作空间。通过SELECT *id* FROM *workspace* WHERE *account_id* = ?。
然后我们可以为每个工作空间提出一个新的命令:
for workspace_id in workspaces:
bus.handle(LockWorkspace(workspace_id))
通过 Strangler 模式实现微服务的事件驱动方法
Strangler Fig模式涉及在旧系统的边缘创建一个新系统,同时保持其运行。逐渐拦截和替换旧功能,直到旧系统完全无事可做,可以关闭。
在构建可用性服务时,我们使用了一种称为事件拦截的技术,将功能从一个地方移动到另一个地方。这是一个三步过程:
-
引发事件来表示系统中发生的变化。
-
构建一个消耗这些事件并使用它们构建自己领域模型的第二个系统。
-
用新的系统替换旧的系统。
我们使用事件拦截从图 E-2 移动…

图 E-2。之前:基于 XML-RPC 的强大的双向耦合
[plantuml, apwp_ep04, config=plantuml.cfg]
@startuml E-Commerce Context
!include images/C4_Context.puml
Person_Ext(customer, "Customer", "Wants to buy furniture")
System(fulfilment, "Fulfilment System", "Manages order fulfilment and logistics")
System(ecom, "E-commerce website", "Allows customers to buy furniture")
Rel(customer, ecom, "Uses")
Rel(fulfilment, ecom, "Updates stock and orders", "xml-rpc")
Rel(ecom, fulfilment, "Sends orders", "xml-rpc")
@enduml
到图 E-3。
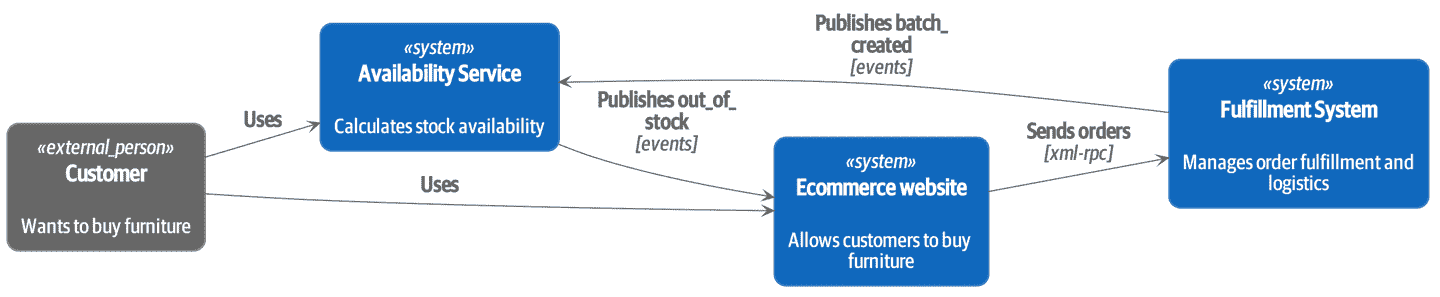
图 E-3。之后:与异步事件的松散耦合(您可以在 cosmicpython.com 找到此图的高分辨率版本)
[plantuml, apwp_ep05, config=plantuml.cfg]
@startuml E-Commerce Context
!include images/C4_Context.puml
Person_Ext(customer, "Customer", "Wants to buy furniture")
System(av, "Availability Service", "Calculates stock availability")
System(fulfilment, "Fulfilment System", "Manages order fulfilment and logistics")
System(ecom, "E-commerce website", "Allows customers to buy furniture")
Rel(customer, ecom, "Uses")
Rel(customer, av, "Uses")
Rel(fulfilment, av, "Publishes batch_created", "events")
Rel(av, ecom, "Publishes out_of_stock", "events")
Rel(ecom, fulfilment, "Sends orders", "xml-rpc")
@enduml
实际上,这是一个长达几个月的项目。我们的第一步是编写一个可以表示批次、装运和产品的领域模型。我们使用 TDD 构建了一个玩具系统,可以回答一个问题:“如果我想要 N 个单位的 HAZARDOUS_RUG,它们需要多长时间才能被交付?”
提示
在部署事件驱动系统时,从“walking skeleton”开始。部署一个只记录其输入的系统迫使我们解决所有基础设施问题,并开始在生产中工作。
一旦我们有了一个可行的领域模型,我们就转而构建一些基础设施。我们的第一个生产部署是一个可以接收batch_created事件并记录其 JSON 表示的小型系统。这是事件驱动架构的“Hello World”。它迫使我们部署消息总线,连接生产者和消费者,构建部署管道,并编写一个简单的消息处理程序。
有了部署管道、我们需要的基础设施和一个基本的领域模型,我们就开始了。几个月后,我们投入生产并为真正的客户提供服务。
说服利益相关者尝试新事物
如果你正在考虑从一个庞大的泥球中切割出一个新系统,你可能正在遭受可靠性、性能、可维护性或三者同时出现的问题。深层次的、棘手的问题需要采取激烈的措施!
我们建议首先进行领域建模。在许多庞大的系统中,工程师、产品所有者和客户不再使用相同的语言交流。业务利益相关者用抽象的、流程为中心的术语谈论系统,而开发人员被迫谈论系统在其野生和混乱状态下的实际存在。
弄清楚如何对领域进行建模是一个复杂的任务,这是许多不错的书籍的主题。我们喜欢使用诸如事件风暴和 CRC 建模之类的互动技术,因为人类擅长通过玩耍来合作。事件建模是另一种技术,它将工程师和产品所有者聚集在一起,以命令、查询和事件的方式来理解系统。
提示
查看www.eventmodeling.org和www.eventstorming.org,了解一些关于使用事件进行系统可视化建模的很好的指南。
目标是能够通过使用相同的通用语言来谈论系统,这样你就可以就复杂性所在达成一致。
我们发现将领域问题视为 TDD kata 非常有价值。例如,我们为可用性服务编写的第一行代码是批处理和订单行模型。你可以将其视为午餐时间的研讨会,或者作为项目开始时的一个突发事件。一旦你能够证明建模的价值,就更容易为优化项目结构提出论点。
我们的技术审阅者提出的问题,我们无法融入散文中
以下是我们在起草过程中听到的一些问题,我们无法在书中其他地方找到一个好地方来解决:
我需要一次做完所有这些吗?我可以一次只做一点吗?
不,你绝对可以逐步采用这些技术。如果你有一个现有的系统,我们建议建立一个服务层,试图将编排保持在一个地方。一旦你有了这个,将逻辑推入模型并将边缘关注点(如验证或错误处理)推入入口点就容易得多。
即使你仍然有一个庞大混乱的 Django ORM,也值得拥有一个服务层,因为这是开始理解操作边界的一种方式。
提取用例将破坏我现有的大量代码;它太混乱了
只需复制粘贴。在短期内造成更多的重复是可以的。把这看作一个多步过程。你的代码现在处于糟糕的状态,所以将其复制粘贴到一个新的地方,然后使新代码变得干净整洁。
一旦你做到了这一点,你可以用新代码替换旧代码的使用,最终删除混乱。修复庞大的代码库是一个混乱而痛苦的过程。不要指望事情会立即变得更好,如果你的应用程序的某些部分保持混乱,也不要担心。
我需要做 CQRS 吗?那听起来很奇怪。我不能只是使用存储库吗?
当然可以!我们在这本书中提出的技术旨在让你的生活变得更轻松。它们不是一种用来惩罚自己的苦行修行。
在我们的第一个案例研究系统中,我们有很多视图构建器对象,它们使用存储库来获取数据,然后执行一些转换以返回愚蠢的读取模型。优点是,当您遇到性能问题时,很容易重写视图构建器以使用自定义查询或原始 SQL。
用例在一个更大的系统中如何交互?一个调用另一个会有问题吗?
这可能是一个临时步骤。同样,在第一个案例研究中,我们有一些处理程序需要调用其他处理程序。然而,这会变得非常混乱,最好的方法是使用消息总线来分离这些关注点。
通常,您的系统将有一个单一的消息总线实现和一堆以特定聚合或一组聚合为中心的子域。当您的用例完成时,它可以引发一个事件,然后其他地方的处理程序可以运行。
如果一个用例使用多个存储库/聚合,这是一种代码异味吗?如果是,为什么?
聚合是一致性边界,所以如果你的用例需要在同一个事务中原子地更新两个聚合,那么严格来说你的一致性边界是错误的。理想情况下,你应该考虑将其移动到一个新的聚合中,该聚合将同时更改所有你想要更改的内容。
如果您实际上只更新一个聚合并使用其他聚合进行只读访问,那么这是可以的,尽管您可以考虑构建一个读取/视图模型来获取这些数据——如果每个用例只有一个聚合,这样做会使事情变得更清晰。
如果你确实需要修改两个聚合,但这两个操作不必在同一个事务/UoW 中,那么考虑将工作拆分成两个不同的处理程序,并使用领域事件在两者之间传递信息。您可以在Vaughn Vernon 的这些聚合设计论文中阅读更多内容。
如果我有一个只读但业务逻辑复杂的系统呢?
视图模型中可能包含复杂的逻辑。在本书中,我们鼓励您将读取模型和写入模型分开,因为它们具有不同的一致性和吞吐量要求。大多数情况下,我们可以对读取使用更简单的逻辑,但并非总是如此。特别是,权限和授权模型可能会给我们的读取端增加很多复杂性。
我们编写了需要进行广泛单元测试的视图模型的系统。在这些系统中,我们将视图构建器与视图获取器分开,如图 E-4 所示。
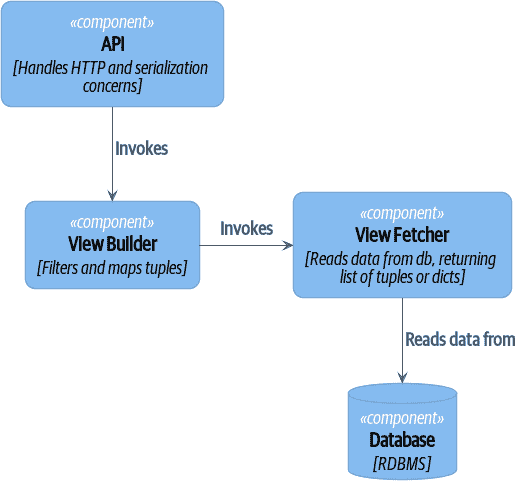
图 E-4. 视图构建器和视图获取器(您可以在 cosmicpython.com 找到此图的高分辨率版本)
[plantuml, apwp_ep06, config=plantuml.cfg]
@startuml View Fetcher Component Diagram
!include images/C4_Component.puml
LAYOUT_LEFT_RIGHT
ComponentDb(db, "Database", "RDBMS")
Component(fetch, "View Fetcher", "Reads data from db, returning list of tuples or dicts")
Component(build, "View Builder", "Filters and maps tuples")
Component(api, "API", "Handles HTTP and serialization concerns")
Rel(fetch, db, "Read data from")
Rel(build, fetch, "Invokes")
Rel(api, build, "Invokes")
@enduml
- 这使得通过提供模拟数据(例如,字典列表)来测试视图构建器变得很容易。“Fancy CQRS”与事件处理程序实际上是一种在写入时运行我们复杂的视图逻辑的方法,以便我们在读取时避免运行它。
我需要构建微服务来做这些事情吗?
天哪,不!这些技术早在十年前就出现了微服务。聚合、领域事件和依赖反转是控制大型系统复杂性的方法。恰好当您构建了一组用例和业务流程模型时,将其移动到自己的服务相对容易,但这并不是必需的。
我正在使用 Django。我还能做到这一点吗?
我们为您准备了整个附录:附录 D!
脚枪
好的,所以我们给了你一堆新玩具来玩。这是详细说明。Harry 和 Bob 不建议您将我们的代码复制粘贴到生产系统中,并在 Redis pub/sub 上重建您的自动交易平台。出于简洁和简单起见,我们对许多棘手的主题进行了手波。在尝试这个之前,这是我们认为您应该知道的一些事情的清单。
可靠的消息传递很困难
Redis pub/sub 不可靠,不应作为通用消息工具使用。我们选择它是因为它熟悉且易于运行。在 MADE,我们将 Event Store 作为我们的消息工具,但我们也有 RabbitMQ 和 Amazon EventBridge 的经验。
Tyler Treat 在他的网站bravenewgeek.com上有一些优秀的博客文章;您至少应该阅读“您无法实现精确一次交付”和“您想要的是您不想要的:理解分布式消息传递中的权衡”。
我们明确选择了可以独立失败的小型、专注的交易
在第八章中,我们更新了我们的流程,以便释放订单行和重新分配行发生在两个单独的工作单元中。您将需要监控以了解这些事务失败的时间,并使用工具重放事件。使用交易日志作为您的消息代理(例如 Kafka 或 EventStore)可以使其中一些变得更容易。您还可以查看Outbox 模式。
我们没有讨论幂等性
我们还没有认真考虑处理程序重试时会发生什么。在实践中,您将希望使处理程序幂等,这样重复调用它们不会对状态进行重复更改。这是构建可靠性的关键技术,因为它使我们能够在事件失败时安全地重试事件。
关于幂等消息处理有很多好的材料,可以从“如何确保在最终一致的 DDD/CQRS 应用程序中的幂等性”和“消息传递中的(不)可靠性”开始阅读。
您的事件将需要随时间改变其模式
您需要找到一种方式来记录您的事件并与消费者共享模式。我们喜欢使用 JSON 模式和 markdown,因为它简单易懂,但也有其他先前的技术。Greg Young 写了一整本关于随时间管理事件驱动系统的书籍:事件驱动系统中的版本控制(Leanpub)。
更多必读书籍
我们还想推荐一些书籍,以帮助您更好地理解:
-
Leonardo Giordani(Leanpub)在 2019 年出版的《Python 中的干净架构》是 Python 应用架构的少数几本先前的书籍之一。
-
Gregor Hohpe 和 Bobby Woolf(Addison-Wesley Professional)的企业集成模式是消息模式的一个很好的起点。
-
Sam Newman 的从单体到微服务(O’Reilly)和 Newman 的第一本书构建微服务(O’Reilly)。Strangler Fig 模式被提及为一个喜欢的模式,还有许多其他模式。如果您正在考虑转向微服务,这些都是值得一看的,它们也对集成模式和异步消息传递的考虑非常有帮助。
总结
哇!这是很多警告和阅读建议;我们希望我们没有完全吓到您。我们撰写本书的目标是为您提供足够的知识和直觉,让您能够开始为自己构建一些东西。我们很乐意听听您的进展以及您在自己系统中使用这些技术时遇到的问题,所以为什么不通过www.cosmicpython.com与我们联系呢?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 黑马Java——面向对象进阶(static&继承)
- MwdpNet:致力于提高高分辨率遥感图像微小目标的识别精度
- 【flink番外篇】12、ParameterTool使用示例
- 一、UNIX基础知识(4)
- JAVA那些事(二)程序控制结构
- WPF入门到跪下 第十章 MVVM-基本数据处理
- java数据结构与算法刷题-----LeetCode167:两数之和 II - 输入有序数组
- LeetCode精选算法200题------(1)266.回文排列
- c++函数怎么返回多个值
- 小红书数据分析:二次元兴起,营销如何读懂ta们心!