【MySQL】SQL优化五个极简法则
发布时间:2024年01月11日
SQL 作为关系型数据库的标准语言,是 IT 从业人员必不可少的技能之一。SQL 本身并不难学,编写查询语句也很容易,但是想要编写出能够高效运行的查询语句却有一定的难度。
查询优化是一个复杂的工程,涉及从硬件到参数配置、不同数据库的解析器、优化器实现、SQL 语句的执行顺序、索引以及统计信息的采集等,甚至应用程序和系统的整体架构。本文介绍几个关键法则,可以帮助我们编写高效的 SQL 查询;尤其是对于初学者而言,这些法则至少可以避免我们写出性能很差的查询语句。
以下法则适用于各种关系型数据库,包括但不限于:MySQL、Oracle、SQL Server、PostgreSQL 以及 SQLite 等。
一、只返回需要的结果
一定要为查询语句指定 WHERE 条件,过滤掉不需要的数据行。通常来说,OLTP 系统每次只需要从大量数据中返回很少的几条记录;指定查询条件可以帮助我们通过索引返回结果,而不是全表扫描。绝大多数情况下使用索引时的性能更好,因为索引(B-树、B+树、B*树)执行的是二进制搜索,具有对数时间复杂度,而不是线性时间复杂度。以下是 MySQL 聚簇索引的示意图:
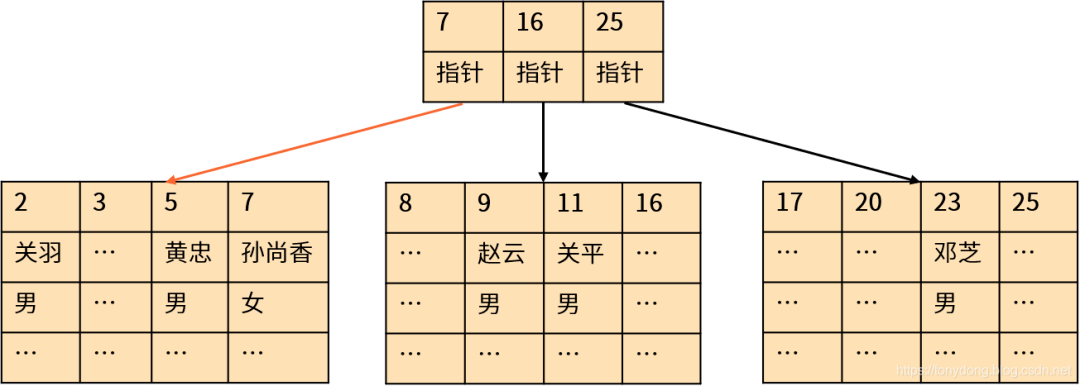
Clustered index?
举例来说,假设每个索引分支节点可以存储 100 个记录,100 万(
文章来源:https://blog.csdn.net/wjianwei666/article/details/135526661
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!