AI绘画Stable Diffusion进阶使用
本文讲解,模型底模,VAE美化模型,Lora模型,hypernetwork。
文本Stable Diffusion 简称sd
欢迎关注
使用模型
C站:https://civitai.com/
huggingface:https://huggingface.co/models?pipeline_tag=text-to-image
大模型(底模型)

stable diffusion webui 部署完成后,checkpoint是放底模
home\webui\models 目录下
常见模式:后缀ckpt/safetensors
常见大小:2G-7G
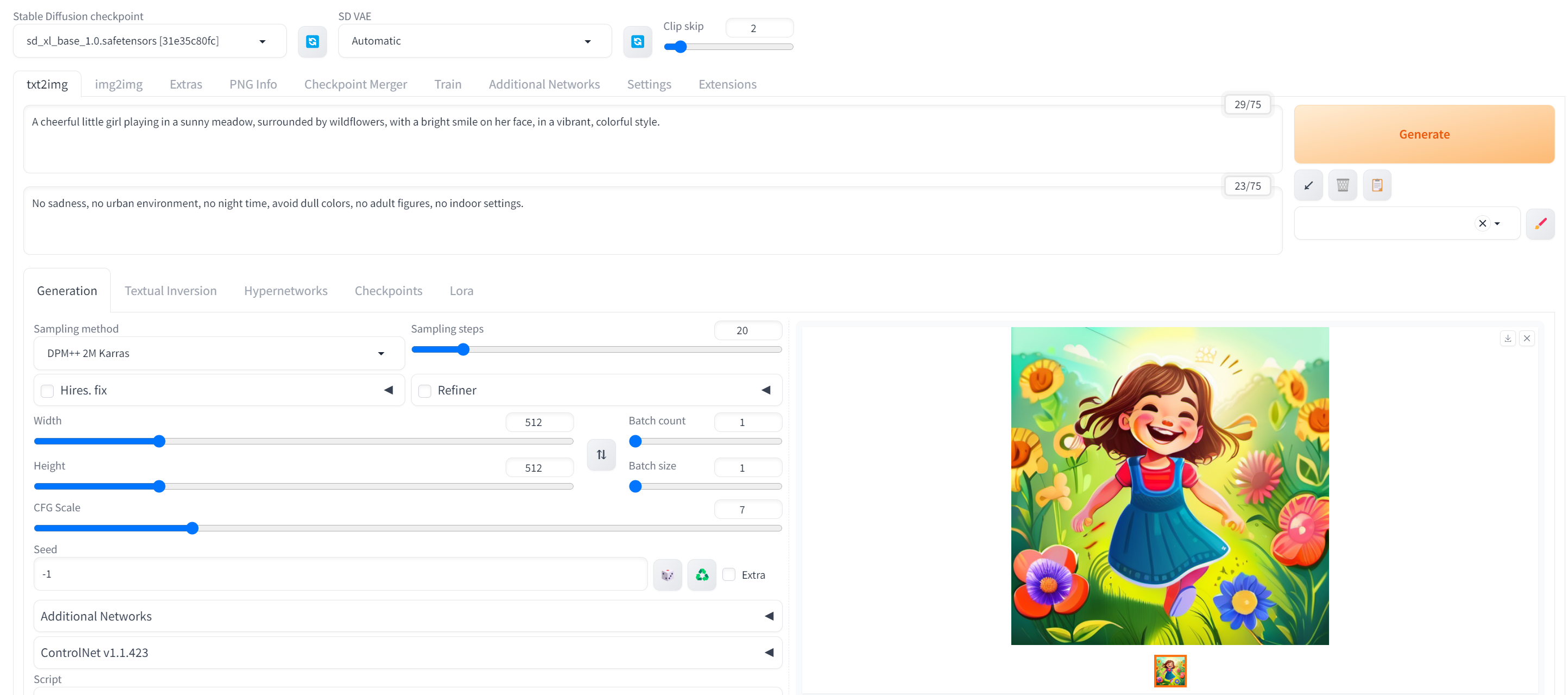
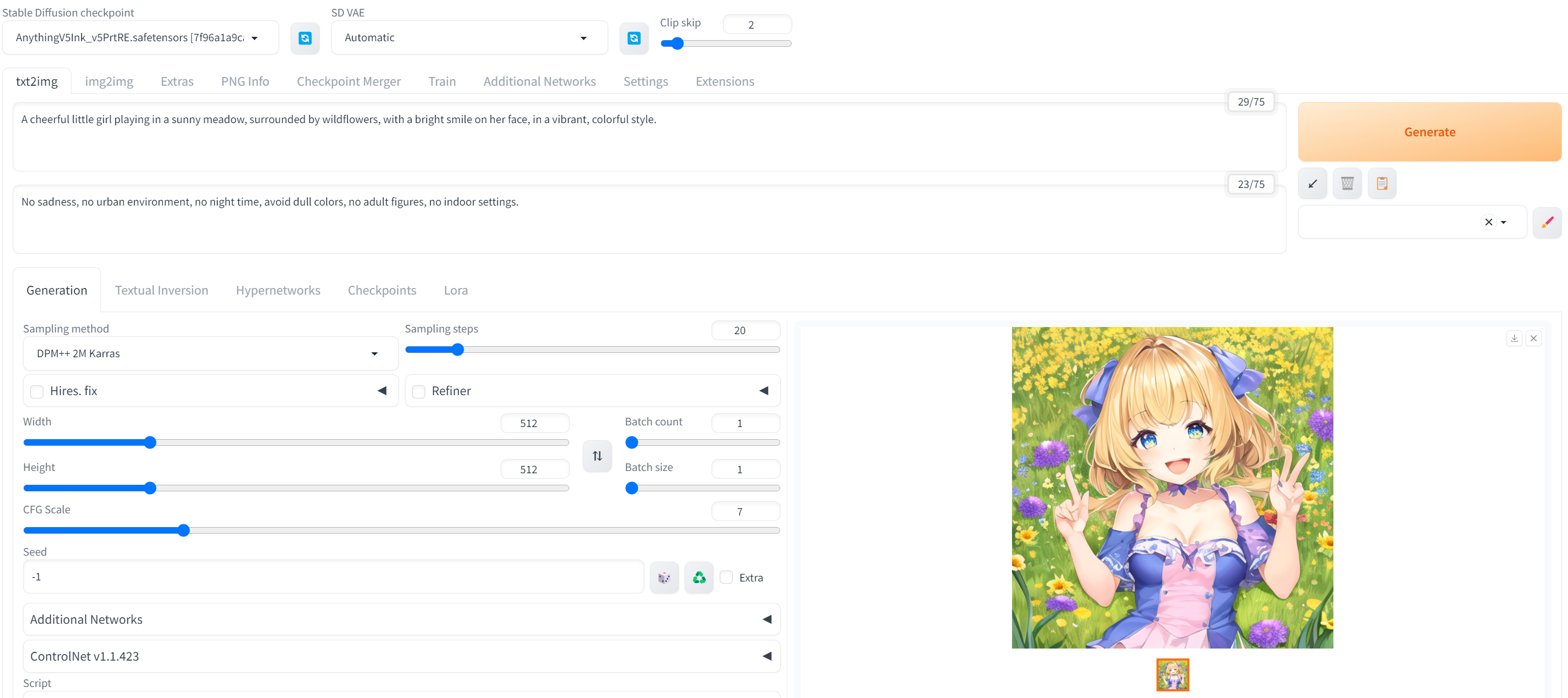
Realistic Vision:逼真的照片风格。
Anything v5:动漫风格。
Dreamshaper:写实绘画风格。
VAE美化模型
可以理解为滤镜,选择VAE就像给图片套上了一层滤镜,会改变图片原有的颜色风格;一般默认是无,而且有些大模型中会自带VAE
常见模式:后缀ckpt/pt
名字中带有vae
stable-diffusion-webui 默认页面并没有显示 VAE 设置部分,所以需要先设置一下。首先点击「Settings」,然后点左侧菜单的「User interface」这个 Tab,拉到下面有个选项叫做Quicksettings list,在输入框里面添加,sd_vae,CLIP_stop_at_last_layers:
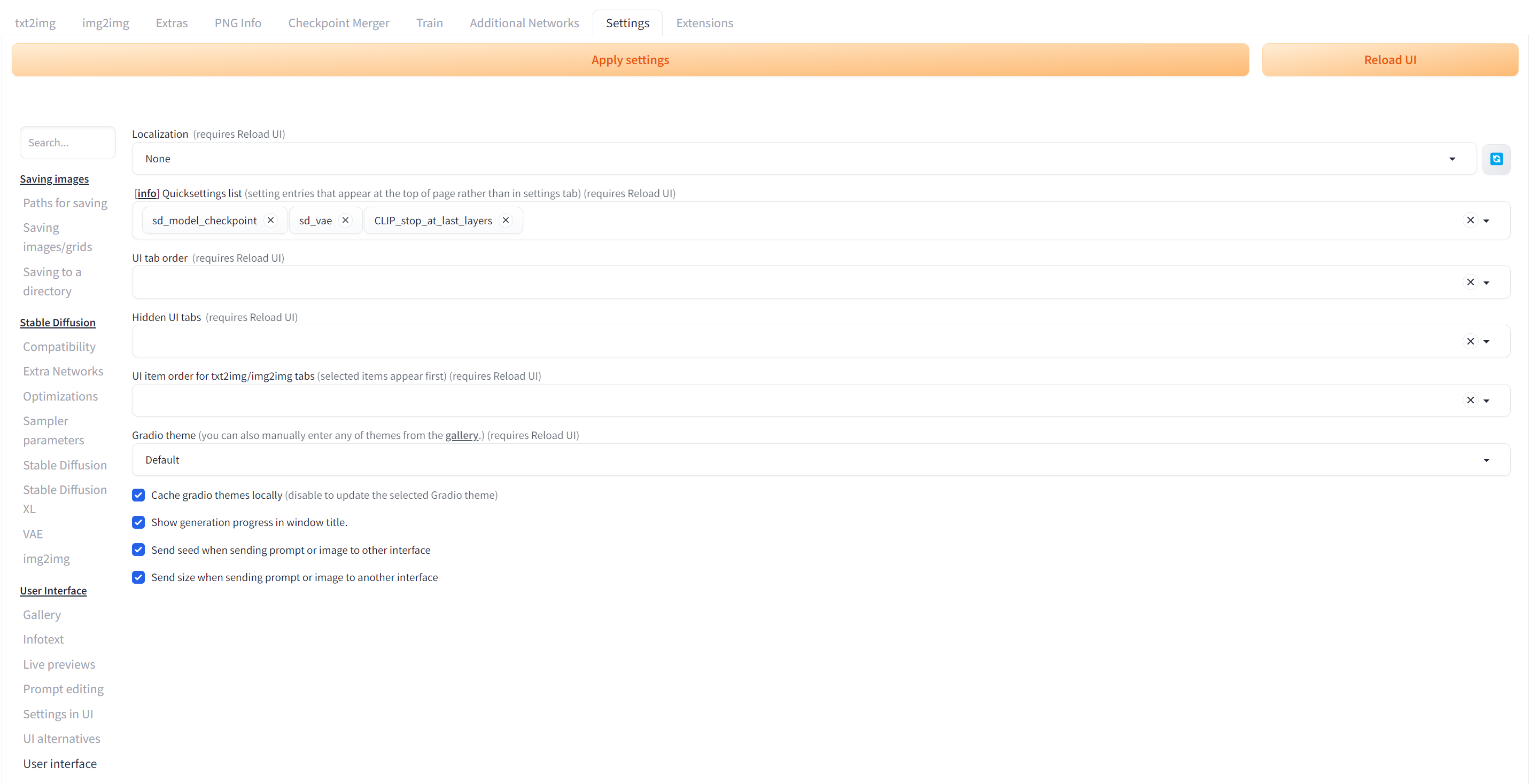
最后点击上面的「Apply settings」,在点「Reload UI」就会重新刷新页面,即可看到头部的 VAE 区域:

可以去C站和huggingface下载
我们把这些 VAE 模型下载并把它放入到models/VAE目录下:
wget https://huggingface.co/stabilityai/sd-vae-ft-mse-original/resolve/main/vae-ft-mse-840000-ema-pruned.ckpt -O ~/workspace/stable-diffusion-webui/models/VAE/vae-ft-mse-840000-ema-pruned.ckpt
wget https://huggingface.co/AIARTCHAN/aichan_blend/resolve/main/vae/Anything-V3.0.vae.safetensors -O ~/workspace/stable-diffusion-webui/models/VAE/Anything-V3.0.vae.safetensors
wget "https://huggingface.co/AIARTCHAN/aichan_blend/resolve/main/vae/Berry's%20Mix.vae.safetensors" -O ~/workspace/stable-diffusion-webui/models/VAE/BerrysMix.vae.safetensors

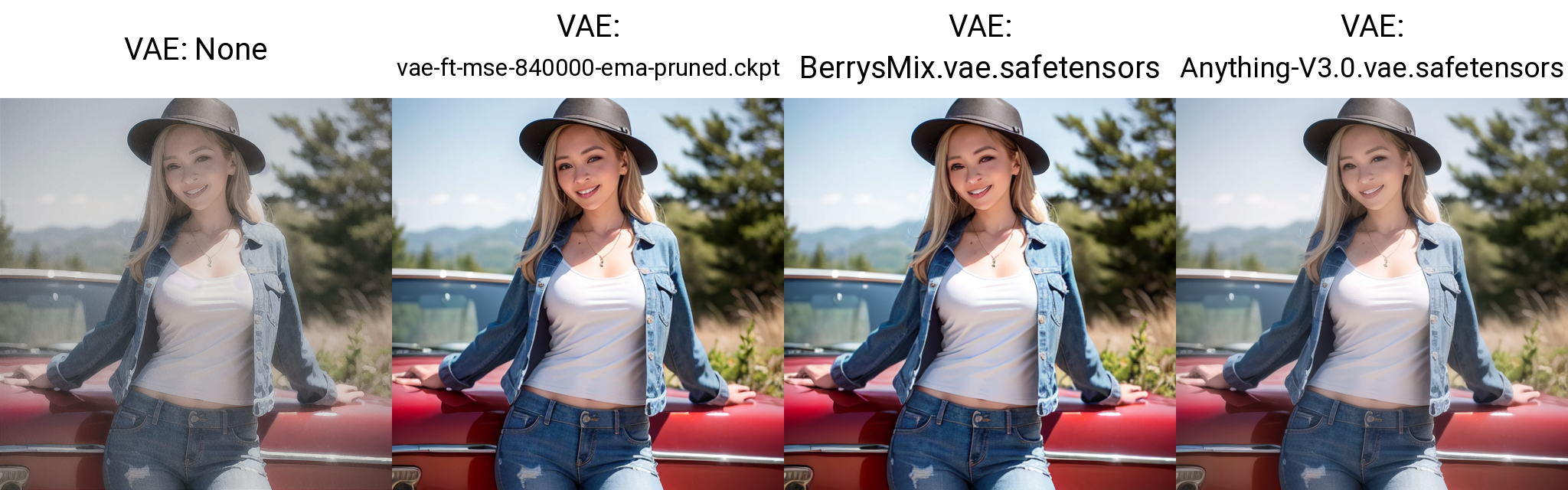
所谓没有对比就没有伤害,对比明显可以感受到不加 VAE 图片优点灰蒙蒙的,不够鲜艳,另外是细节不够,而加了不同的 VAE 都有了更好的颜色效果,细节更全了 (微调)。
最后,注意不同的 VAE 适配的模型不同,也不是某个 VAE 可以用在任何模型下,否则可能会生成非常奇怪的图。
Lora模型
LoRA模型是通过截取大模型的某一特定部分生成的小模型,虽然不如大模型的能力完整,但短小精悍。因为训练方向明确,所以在生成特定内容的情况下,效果会更多。
常见模式:后缀ckpt/safetensors/pt
常见大小:100MB
模型下载并把它放入到models/Lora目录下
可以去C站下载搜索Lora模型
Embeddings
通过角色训练产出,能够让你的主模型识别某个指定的角色,因为你的主模型不可能每个角色都认识,通过文件名触发。
常见模式:后缀pt
常见大小:几十KB
模型下载放到webui\embeddings
可以去C站下载搜索Embeddings模型
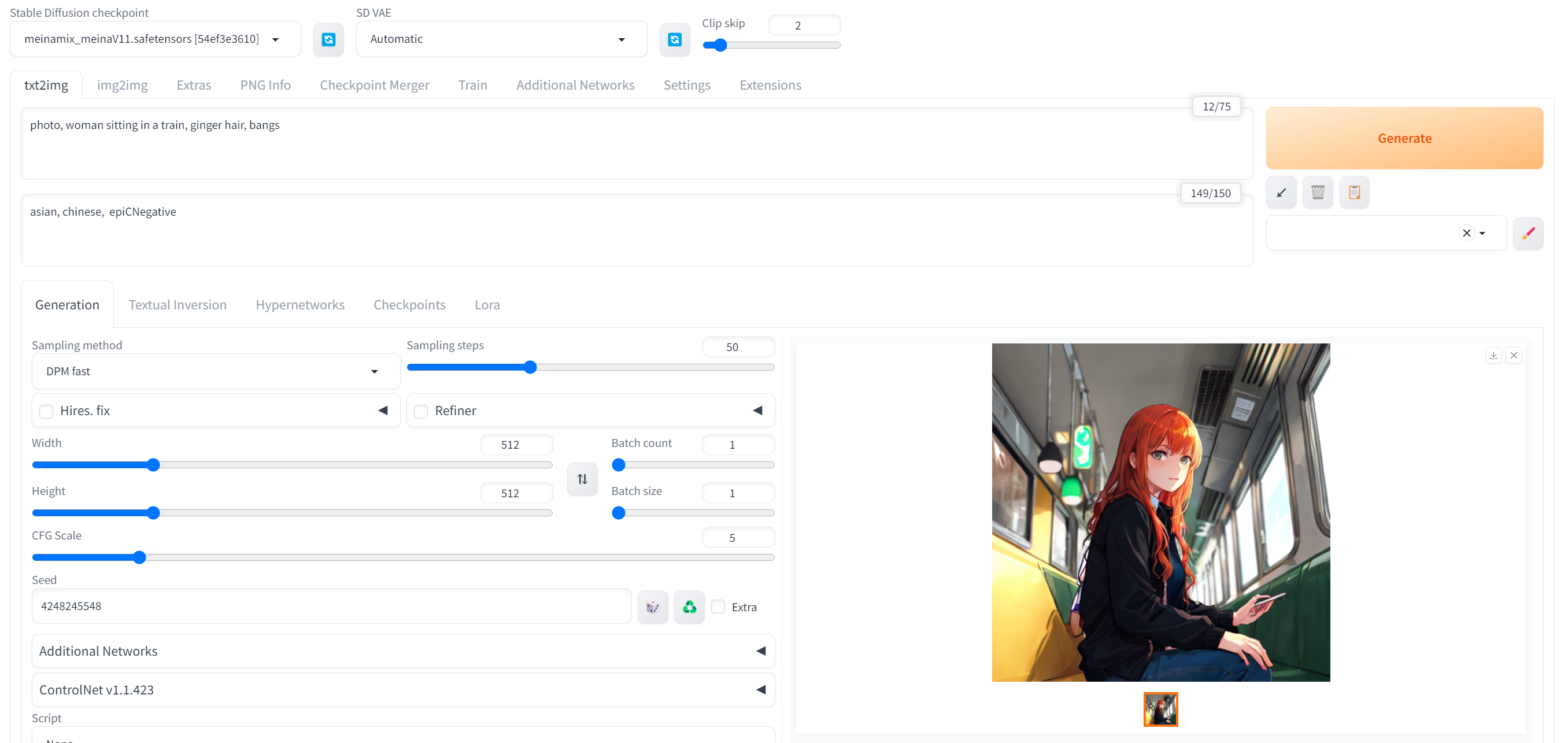
Hypernetworks
通过画风训练产出,能够指定特定的画风!
常见模式:后缀pt
常见大小:几十KB
模型下载放到webui\models\hypernetworks
可以去C站下载搜索hypernetworks模型
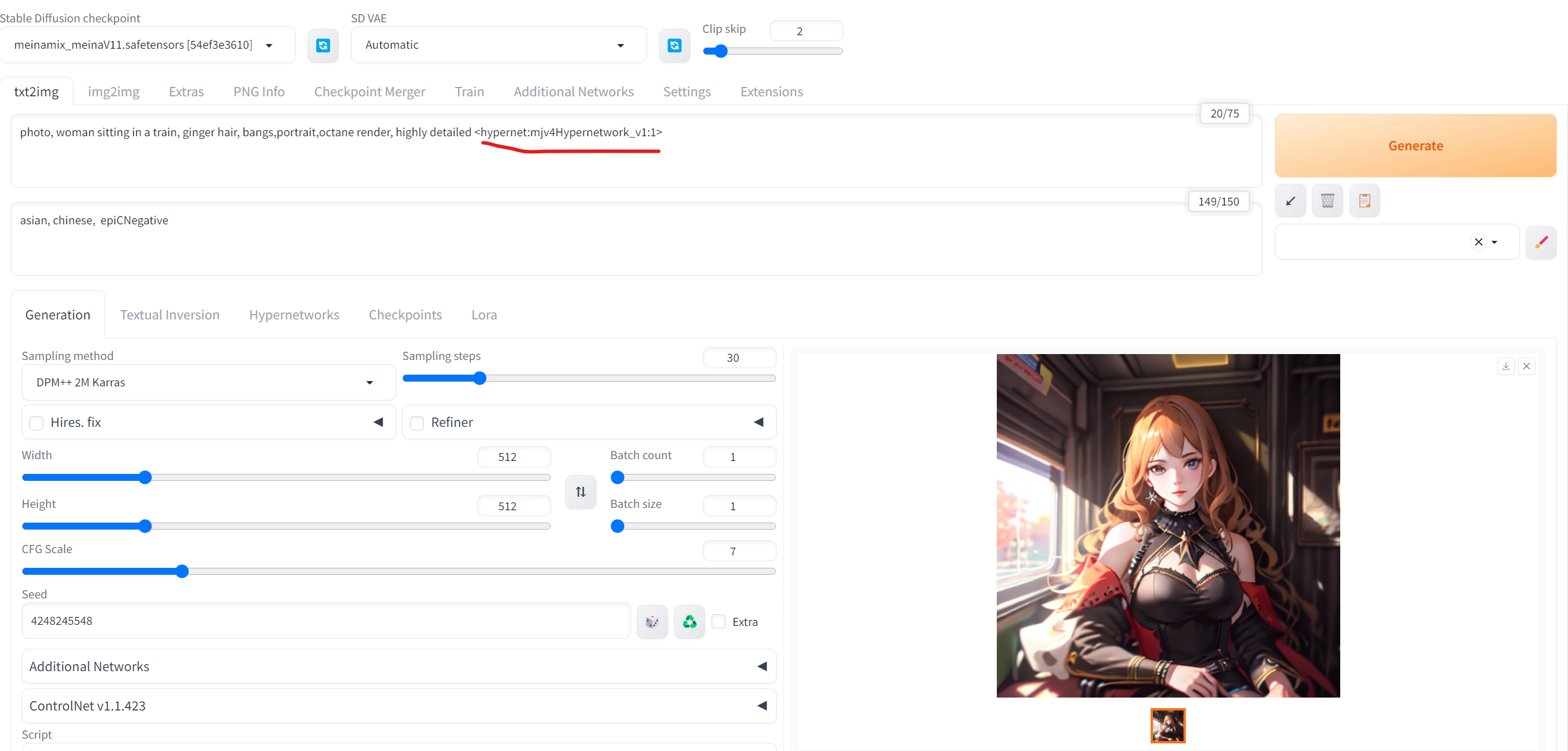
功能类型选择
除了文生图,也可根据自己的需求选择其他选项卡进行操作,以下简单介绍正常流程会用到的选项卡:
图生图(img2img):将文生图的结果继续生成图片,或自己上传一张图片,常用于调整和优化图片,或修改图片风格、背景、人物形象等场景;
附加功能(Extras):对单张或批量图片进行缩放的操作;
图片信息(PNG Info):将本地图片上传后,可以用于其他选项卡的功能中;
模型合并(Checkpoint Merger):将多个模型进行不同权重的合并,从而获得一个新的模型;
扩展:SD的扩展插件配置区,可以查看已安装的插件内容,并控制开启和禁用状态;也支持通过URL的方式获取其他插件。
掌握提示词技巧
提示语输入基本要求
使用英语描述最佳,避免出现单词拼写错误;(不同模型可能有训练中文和日文,可自行判断)
标点符号同样使用英文半角进行输入;
建议使用逗号隔开的单词作为提示词;(也可用句号、甚至是空字符(\0)来分隔关键词,可以提高图像质量;
也可以使用自然语言描述图片内容,比如:A handsome hero armed with a sword(一个英俊的英雄装配着剑)
提示语描述和图像风格搭配,相近的描述不要重复出现
善于利用反向提示语来去除图片的负面效果;
尽可能使用特定含义的词汇,比如将 big 调整为 huge ,避免使用有多种含义的词汇;
避免使用with、and之类的连接词;
可使用emoji(💰,💶,💷,💴,💵,🎊,🎀,👩) 进行补充描述;
逗号前后的少量空格并不影响实际效果;
可以通过指定风格提示语来创作带有特效或指定画风的图片;(风格获取参考下文👇)
姿势的描述越精简越好,否则容易出现肢体重复的情况;(肢体生成是AI硬伤,可用controlnet来解决)
避免过长提示词,越尾部的提示词在图片中的权重默认就越低,因此关键特征尽可能放在头部或通过语法来提高权重;(过长提示词可适当提高生成步数获取更好效果)
输入提示词技巧
输入模板
将自己构思的图片特征抽象为标签描述,并将标签按分类进行排列,以下为模板示例:
(quality), (subject)(style), (action/scene), (artist), (filters)
(quality) 代表画面的品质,比如 low res 结合 sticker使用来“利用”更多数据集,1girl结合high quality使用来获得高质量图像。
(subject) 代表画面主题,锁定画面内容,这是任何提示词基本组成部分。
(style) 是画面风格,可选。
(action/scene) 代表动作/场景,描述了主体在哪里做了什么。
(artist) 代表艺术家名字或者出品公司名称
(filters) 代表一些细节,补充。可以使用 艺术家,工作室,摄影术语,角色名字,风格,特效等等。
提示词语法
(word) - 将权重提高 1.1 倍
((word)) - 将权重提高 1.21 倍(= 1.1 * 1.1),乘法的关系。
[word] - 将权重降低 90.91%
(word:1.5) - 将权重提高 1.5 倍
(word:0.25) - 将权重减少为原先的 25%
(word) - 在提示词中使用字面意义上的 () 字符
使用数字指定权重时,必须使用() 括号。如果未指定数字权重,则假定为 (权重增加通常会占一个提示词位,应当避免加特别多括号)
(n)=(n:1.1)
((n))=(n:1.21)
(((n)))=(n:1.331)
((((n))))=(n:1.4641)
(((((n)))))=(n:1.61051)
((((((n))))))=(n:1.771561)
相关模板
正向提示语:
#万能画质要求#
(masterpiece, best quality),
反向提示语:
#避免糟糕人像的#
ugly, fat, obese, chubby, (((deformed))), [blurry], bad anatomy,disfigured, poorly drawn face, mutation, mutated, (extra_limb),(ugly), (poorly drawn hands fingers), messy drawing, morbid,mutilated, tranny, trans, trannsexual, [out of frame], (bad proportions),(poorly drawn body), (poorly drawn legs), worst quality, low quality,normal quality, text, censored, gown, latex, pencil,
#避免生成水印和文字内容#
lowres, bad anatomy, bad hands, text, error, missing fingers,extra digit, fewer digits, cropped, worst quality, low quality,normal quality, jpeg artifacts, signature, watermark, username, blurry,
#通用#
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry,
#避免变形的手和多余的手#
extra fingers,fused fingers,too many fingers,mutated hands,malformed limbs,extra limbs,missing arms,poorly drawn hands,
辅助工具推荐
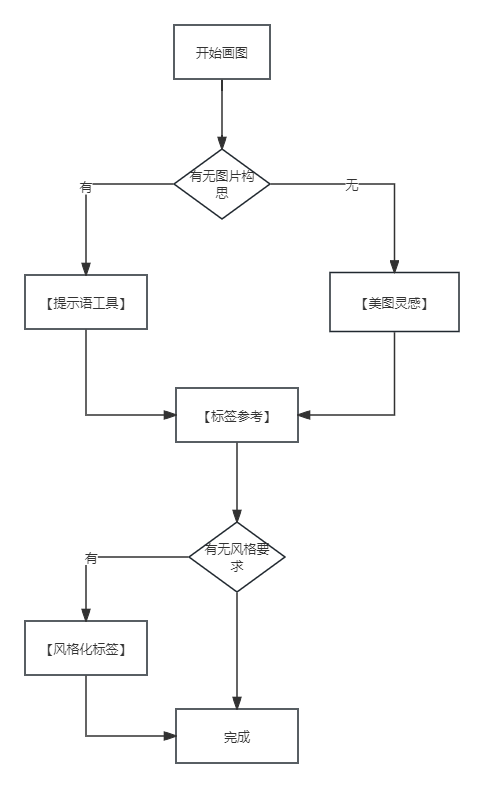
标签参考
最全tag库(根据分类查找):https://danbooru.donmai.us/
颜色列表:https://en.wikipedia.org/wiki/List_of_colors_by_shade
表情符号:https://unicode.org/emoji/charts/emoji-list.html
标签冰山图:https://icebergcharts.com/i/Danbooru_Tags
美图灵感
OpenArt:https://openart.ai/discovery
prompthero:https://prompthero.com/
ptsearch(韩风):https://www.ptsearch.info/home/
arthub :https://arthub.ai/
lexica(艺术风格):https://lexica.art/
提示词工具
Danbooru 标签超市:https://tags.novelai.dev/
AI绘画提示词生成器:http://www.atoolbox.net/Tool.php?Id=1101
魔咒百科词典:https://aitag.top/
风格化标签
Stable Diffusion V1 Artist Style Studies(风格化总结):
https://proximacentaurib.notion.site/e28a4f8d97724f14a784a538b8589e7d?v=42948fd8f45c4d47a0edfc4b78937474
艺术家风格:https://www.urania.ai/top-sd-artists
Artists To Study:https://artiststostudy.pages.dev/
MidLibrary 这个网站提供了不同的图像风格,每一种都带有鲜明的特色:https://midlibrary.io/midjourney-style-classifier#styles-by-categories
看到这里,说明你已经完成进阶,继续加油,帮忙关注!
更多参考:欢迎关注
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为何浮点数不能精确表示?——浮点数在计算机中的存储方式
- 浅析红色舞蹈作品对当代新青年的教育意义—LW
- FreeRTOS之二值信号量(实践)
- 【23.12.30期--Spring篇】Spring的AOP介绍(详解)
- 数组、排序和查找
- C++实现字符串匹配的暴力法
- 【Unity美术】如何用3DsMax做一个水桶模型
- Docker容器安全漏洞管理与测试
- 中国电子学会2023年9月份青少年软件编程Scratch图形化等级考试试卷二级真题(含答案)
- 字母异位词分组【哈希】