MATLAB Deep learning
发布时间:2024年01月14日

文章目录
Chapter 1: Machine Learning
- 深度学习是一种机器学习,而机器学习是一种人工智能。
机器学习的本质:机器学习是一种从“数据”中找到“模型”的技术。在这里,数据的字面意思是指文档、音频、图像等信息。这个“模型”是机器学习的最终产物。
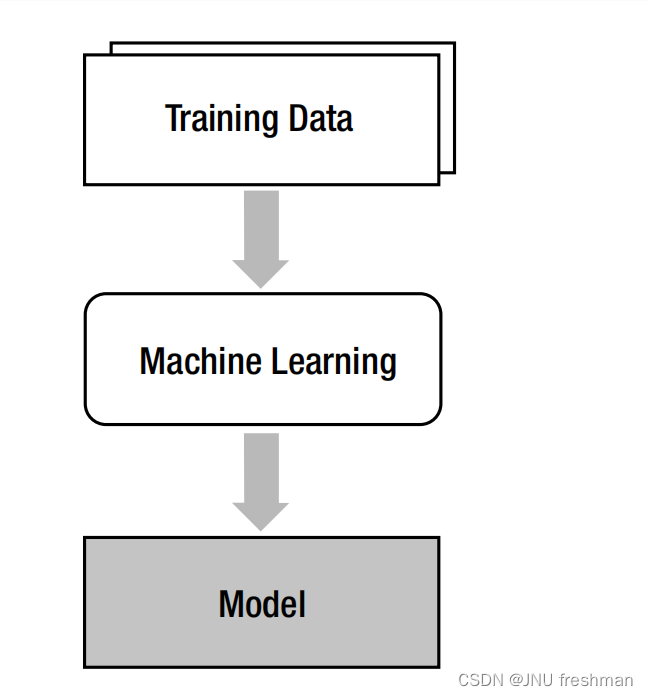
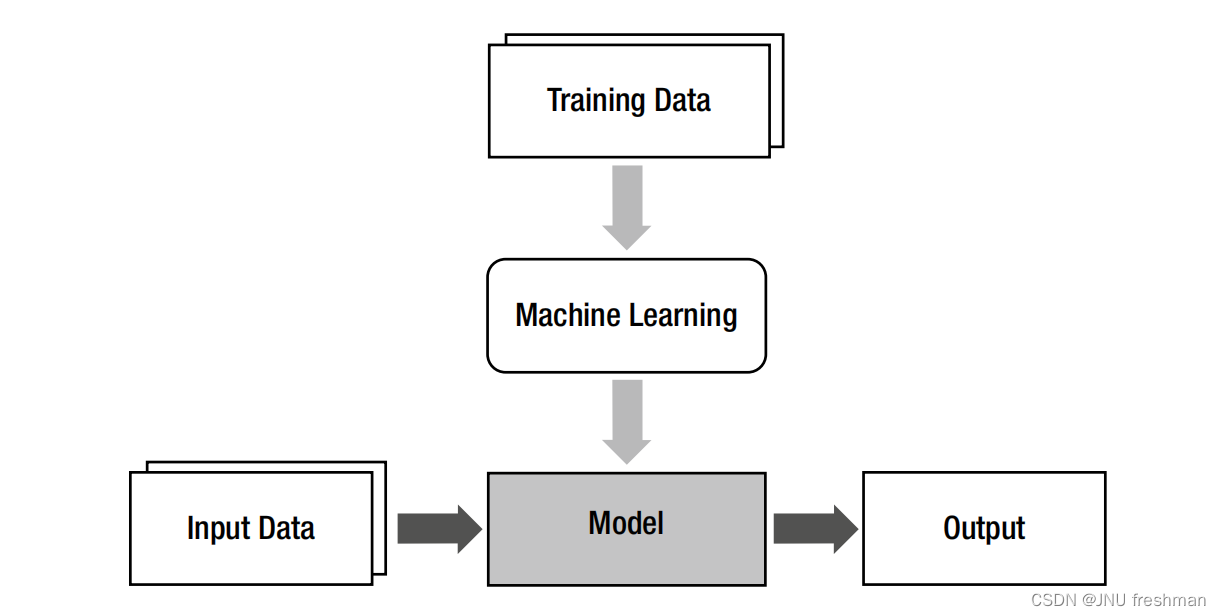
- 机器学习的创建是为了
解决分析模型几乎不可用的问题。机器学习的主要思想是在方程和定律不好时使用训练数据实现一个模型.
- 但是由于训练的数据与得出的模型是存在不同的
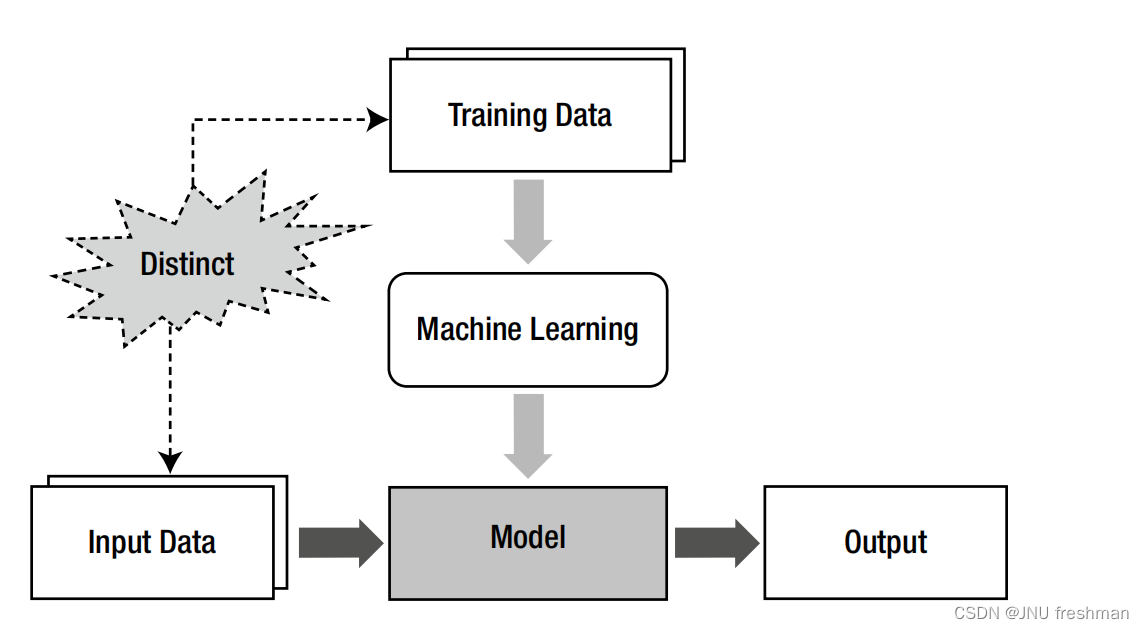
存在的问题
过拟合Overfitting
- 训练数据中始终会存在异常点,这些异常点会影响边界的分类,机器识别是不能识别这些异常点的,这就会造成,当你将训练数据全部考虑的时候,就会得到通用性较低的模型
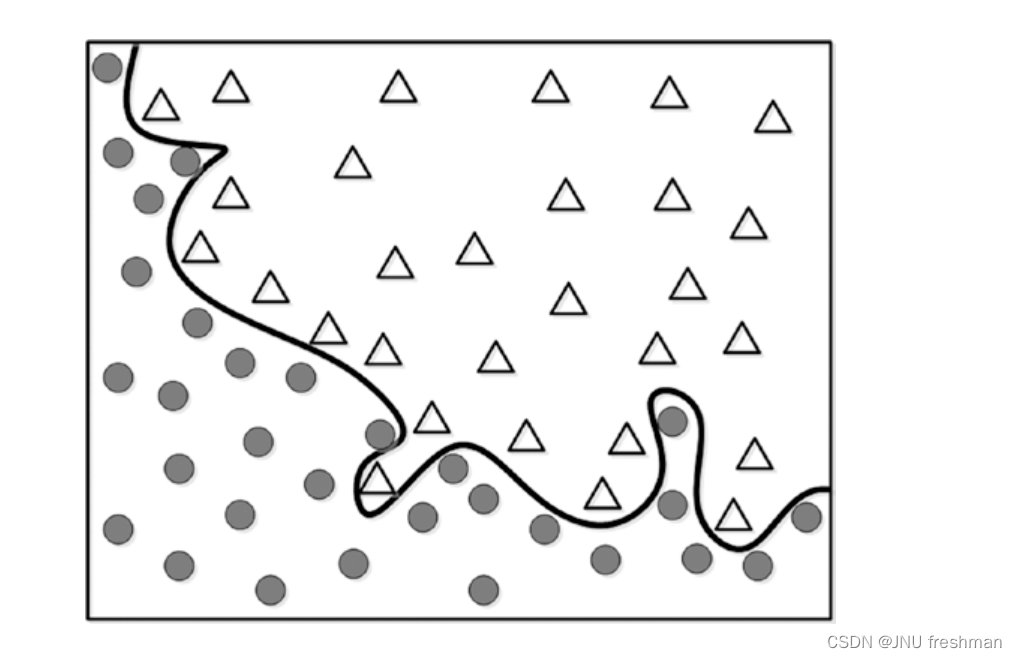
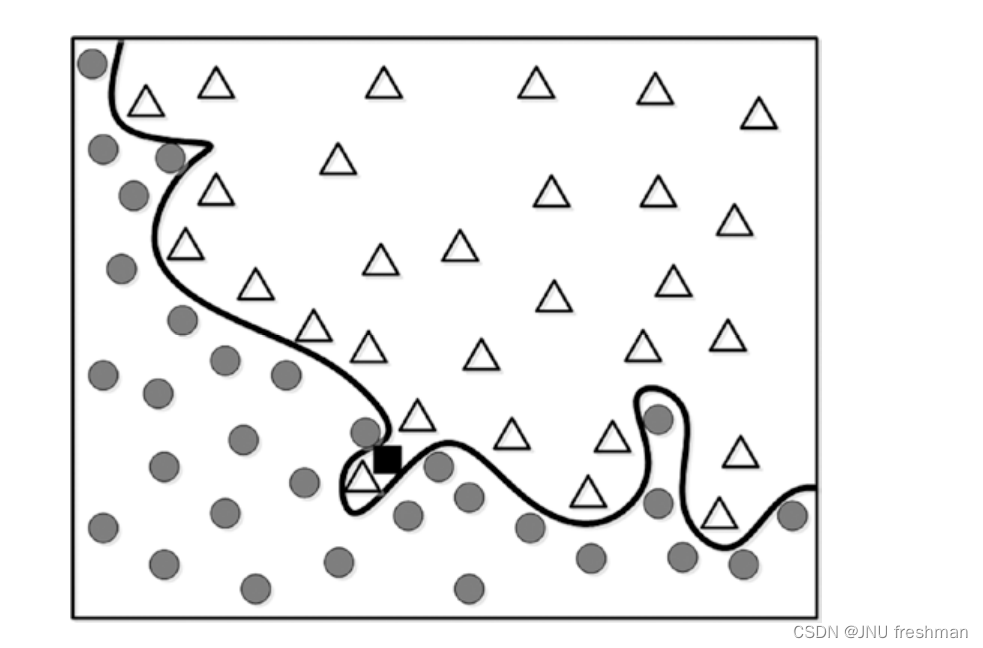
以上面的图为例子:对于图一,似乎拟合的十分成功,但是对于应用在图二的身上的正确性就有待确认
解决过拟合 regularization and validation
regularization 正则化
- 正则化是一种尽可能
简单地试图构建模型结构的数值方法。简化的模型可以在较小的性能代价下避免过拟合的影响。
validation 验证
- 验证是一个保留一部分训练数据并使用其来监控性能的过程。验证集不用于培训过程。当训练后的模型对保留数据输入的性能水平较低时,模型被过拟合。在这种情况下,我们将修改模型,以防止过拟合。
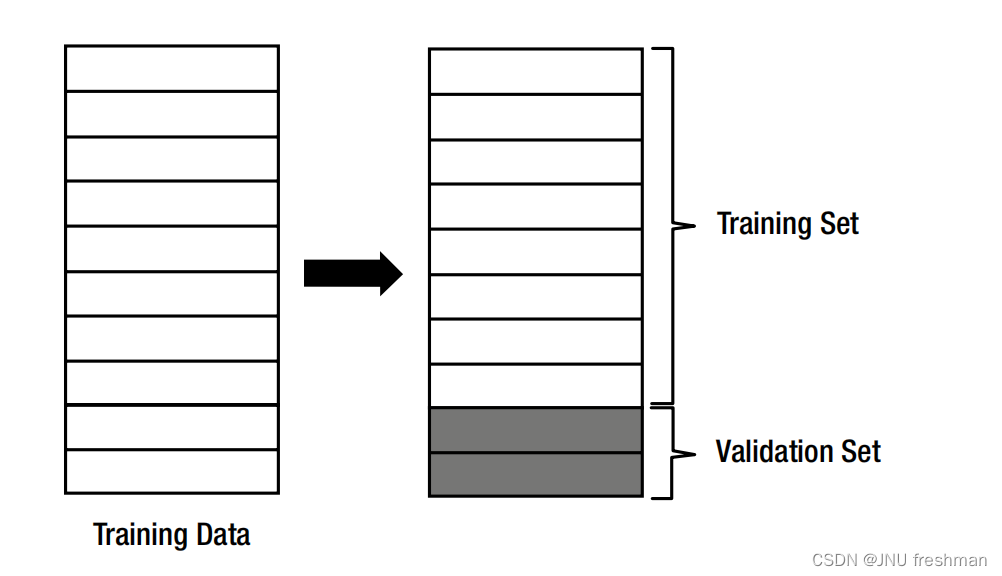
机器学习的验证的过程:
1.将训练数据分为两组:一组用于训练,另一组用于验证。根据经验,训练集与验证集的比率是8:2。
2.用训练集来训练模型。
3.使用验证集来评估模型的性能。
a.如果该模型的表现令人满意,则完成训练。
b.如果性能不能产生足够的结果,则修改模型并重复步骤2中的过程。
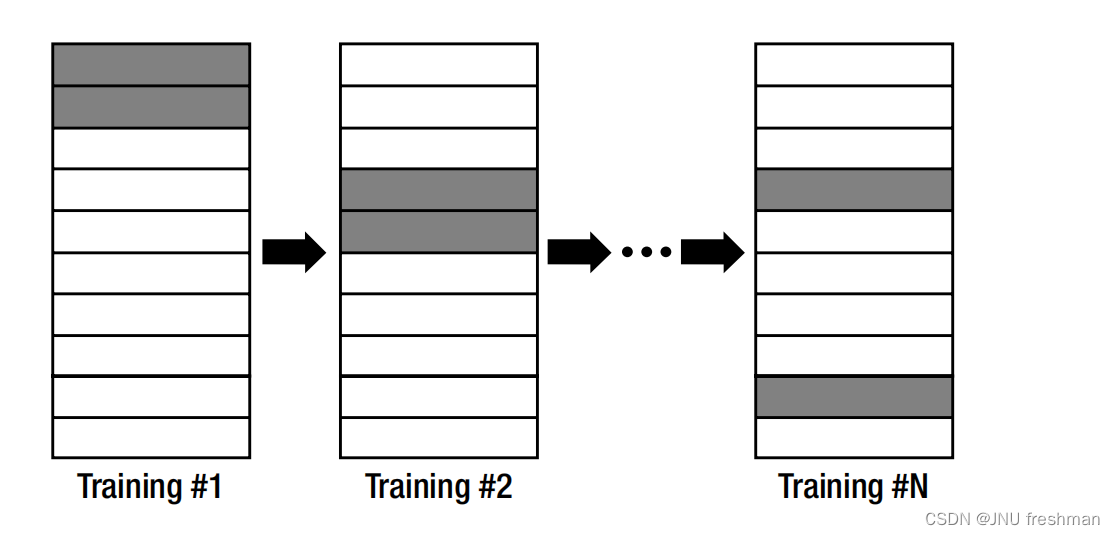
交叉验证:交叉验证是验证过程中的一个细微变化。它仍然将训练数据分成组进行训练和验证,但不断改变数据集。交叉验证不是保留最初的划分集,而是重复对数据的划分。这样做的原因是,当模型是固定的时,模型也会过度拟合。由于交叉验证保持了验证数据集的随机性,它可以更好地检测模型的过拟合。
机器学习的类型
- 根据训练方法,这些机器学习技术可以分为三种类型
有监督学习(Supervised Learning),无监督学习(Unsupervised Learning),强化学习(Reinforcement Learning)
有监督学习
有监督学习步骤:
1.选择一个练习问题。运用现有的知识来解决这个问题。比较一下答案和解决方案。
2.如果答案是错误的,请修改当前的知识。
3.对所有的练习问题,重复步骤1和步骤2。
- 在监督学习中,每个训练数据集都应该由
输入对和正确的输出对组成。正确的输出是模型应该为给定的输入而产生的输出。- 在监督学习中,学习就是对模型进行一系列修正,以减少相同输入的正确输出和模型输出之间的差异。
无监督学习
- 相比之下,无监督学习的训练数据
只包含没有正确输出的输入。- 无监督学习通常用于
研究数据的特征和对数据进行预处理。这个概念类似于一个学生,他只是通过构造和属性来分类问题,而不学习如何解决它们,因为没有已知的正确输出
强化学习
- 强化学习采用输入、一些输出和等级作为训练数据。它通常在需要最佳交互时使用,如控制和游戏玩法。
Chapter 2: Neural Network
Chapter 3: Training of Multi-Layer Neural Network
Chapter 4: Neural Network and Classification
Chapter 5: Deep Learning
Chapter 6: Convolutional Neural Network
文章来源:https://blog.csdn.net/weixin_74850661/article/details/135584646
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- docker容器添加新的端口映射
- 《知识文库》期刊投稿方式
- DevicData-D-XXXXXXXX勒索病毒的最新威胁:如何恢复您的数据?
- 「HDLBits题解」Counters
- 如何在 Photoshop 中创建草文本效果
- Python使用余弦相似度比较两个图片
- python 如何获取两个span的最长公共子序列(包含中文和英文版本)
- 手把手带你死磕ORBSLAM3源代码(三十七)Tracking.cc CheckReplacedInLastFrame TrackReferenceKeyFrame
- MySQL之视图&外连接、内连接和子查询的使用
- Python3多线程爬虫实例讲解