中文字符占用字节即相关原理(实现中文(中英混合)字符串的反转)
如有不对欢迎指正。?
目录
2.但是并不是所有情况都是用无符号数(以下目前只是猜测,如有问题欢迎指正) :
3.我们上面说到的char是有符号类型,可我们平时使用可以直接表示字符呀??
?一.ASCLL字符和中文字符
char类型
char类型我们在写代码的时候经常会使用,它用于存储定义一个存储字符的变量,但是我们定义char类型一般是用来存放一些英文字符等,这些字符都有一个特点:都是ASCLL中指定的字符。?
说是字符其实存储的是一些二进制数,我们知道一个字节有八位,一位可以存储0,1两个二进制位,所以八位一共可以表示2^8 = 256 个数据,但是,对于ASCLL码我们使用的一般是128个,所以只需要低7位即可存储下。最高位存0即可。(后面新增的(128-255)有些编码可能不兼容)
所以,char定义的变量只能用来存放ASCLL码表中的字符,所以char类型的变量只占一个字节。(因为一个字节就足够表示全部ASCLL码的值,不需要再多占用内存了)。?
那么怎么能让这128个数据和字符对照起来呢,其实就是一个查表的过程(可以看下ASCLL码表)?。
但是,由于历史原因,ASCLL码表中是没有中文字符的,?(所以我们无法使用char类型的变量来表示一个中文字符)。为了能够使用中文字符,衍生出了GBK,GB2312等编码字符集,这些字符集兼容ASCLL码字符(只兼容前127个,后新增的不兼容)。
1.使用无符号数表示的原因(对于中文字符):?
因为ASCLL码字符已经基本占用了一个字节的内存来表示相应的字符,再加上中华文化博大精深,一个字节(最多才256个数据)怎么能放的下我们的汉字呢,所以中文字符使用两个字节来保存(大部分) ,而且为了能够确定你输出的是中文字符,相应编码做出了不同的规定。其中一个是:两个字节的高第一个字节必须为1(这也就说明了,存放这些数据需要一个无符号类型(因为有符号最高位是表示正负的,会出问题)--后面会说到)。GBK和GB2312都是如此。(当然其它不同编码可能会有不同--但是依然使用无符号数进行表示数据)。
2.但是并不是所有情况都是用无符号数(以下目前只是猜测,如有问题欢迎指正) :
?
1. 什么时候使用无符号数表示:? ???
当我们需要拿字符对应数据与一些数据进行比较或者运算的时候?
?
2. 不需要使用的情况:?
其实大部分情况下都不需要使用,我们平时也遇到很多,例如: 我们使用一个char a[] = "我爱你",对于这个字符串,就是一个包含7个字节的字符串,每个字节是一个char类型的空间,如果如上述(使用无符号数的原因)我们表示这个字符串,应该使用无符号类型才行,但是使用过的都知道,我们直接去输出这个字符串也是没有问题的。(也就是说,我们使用char这样的符号类型,它也能正确的查表)。
举一个例子,char类型字符的取值范围是 -128? ---? 127 ,当我们赋值超过127其就是一个负数了,那么按照上述所说(使用无符号数表示),应该是无法正确表示出字符的。但是经过测试之后发现是没有问题的,(但是由于我们默认使用的代码页(一般为936),是不包括新增的128-255位ASCLL码,所以输出需要修改代码页(看代码)),?
int main(void)
{
SetConsoleOutputCP(437);
char a = 254;
printf("%c", a);
system("pause");
return 0;
}?
上述代码,进行了代码页的转换,否则无法输出128-255位的ASCLL码数(因为是新增的不兼容),我们看代码 -- 使用char类型,赋值为254,但由于前面char类型的范围,这个值是溢出的,所以实际它的值为:-2, 原码: 1000 0010, 补码: 1111 1110, 我们如果将其补码看作无符号数转换成数字,为254。
当我们以字符形式输出时,会发现可以正常输出,而且正好是ASCLL码第254号位置的字符。?
![]() ?就是本图的正方形。
?就是本图的正方形。
结论:? 所以,我们数据在计算机中以补码形式存储,那么计算机在查表时(表中为无符号数),不会区分正负,只是看该数据与表中哪个数据对应,然后输出对应的字符。只有在我们使用数据计算,比较,以有符号数输出时才会有明确的正负。建议使用无符号类型。(这些都是自己的猜测,如果不对请指正)。?
所以,这也说明了,如果一个中文字符对应的二进制数据,最高位都为1的话(有符号类型应该是个负数),我们使用char类型输出字符串时却没有问题。?
?
3.对于使用使用无符号数表示字符对应的数据(就是二进制组成的数字),可能会有疑问。?
3.我们上面说到的char是有符号类型,可我们平时使用可以直接表示字符呀??
原因 : ?上面说到过,ASCLL一般使用低七位即可,最高位一般为0.
 ?如图。 作为无符号数,最高位为0的时候为正数,它和其对应的无符号数表示的值是一样的(如果为1就不一样了,多一个负号吗),所以我们平时使用char也是可以的。
?如图。 作为无符号数,最高位为0的时候为正数,它和其对应的无符号数表示的值是一样的(如果为1就不一样了,多一个负号吗),所以我们平时使用char也是可以的。
?
?二.对于中文字符,将一个字符串的中文字符传给另一个
对于字符串, 定义:? char? s[]?= "我爱你";? ?char s2[100] = {0}(定义了一个占用100字节的数组); 我们要将s指向的字符串拷贝到s2中。
1.2.首先, 我们上面说到一个中文字符占用两个字节,一个char占用一个字节,
?
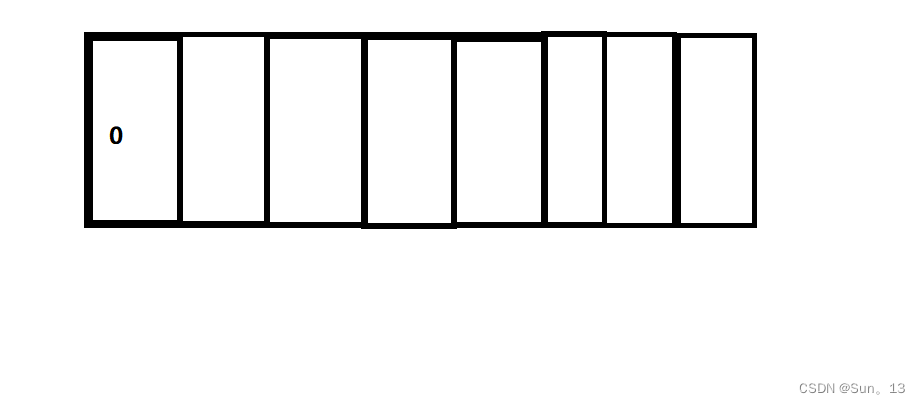
如上图,一个框子为一个字节(最后\0表示字符串的结束) ,所以对于字符数组,s它存储的字符串虽然只有三个元素,但是它却占七个字节(还有一个字符串结束符)。
从这可以更加直观的看出,为什么不能使用char来打印中文字符了,人家占用两个位置,你只给一个位置,不出问题才怪。?
2.想要将s中的字符串拷贝到s2中,与直接拷贝ASCLL字符不一样,但是也差不多。?
一个汉字占用两个字节,我们只需要将这两个字节按照顺序拷贝到s2中即可。例: s2[0] = s1[0],
s2[1] = s1[1] -- 后面的中文一起类推,最后加一个字符串结束符就可以了。(原因:其实一个汉字,对应的是这两个字节所组成的0,1数字组合,然后对应查表就可得到,此处,我们按照顺序,将这些数字组合拷贝到目标数组--它们的顺序是没有改变的所以对应的还是哪个汉字,所以实现了拷贝)?
对于字符串的输出,编译器使用相应的编码,所以可以输出中文等。?
三.实现中文字符串的反转?
方法一 :??
#include <iostream>
#include <Windows.h>
#include <string>
#include <errno.h>
#include <string.h>
using namespace std;
#define STRTEMPLEN 30
char* exchangeChineseStr(const char* str);
/*字符串常量的值为首字符的地址,使用指针+一个字符占用字节数,可以跳过相应字节输出后面字符串,中文字符一个占用两个
字节,所以+2*/
int main(void)
{
string str;
char* result = NULL;
cout << "请输入一个字符串" << endl;
cin >> str;
// 错误检测
if (cin.fail())
{
cerr << "输入失败,原因:" << strerror(errno) << endl;
exit(1);
}
if ((result = exchangeChineseStr(str.c_str())) != NULL)
{
printf("%s\n", result); //输出乱码的原因: 是因为返回了局部变量
}
system("pause");
return 0;
}
char* exchangeChineseStr(const char* str)
{
if (str == NULL)
{
cout << "传入字符串为空" << endl;
return NULL;
}
int len = strlen(str); // 计算长度
//printf("%d", len);
char strTemp[STRTEMPLEN] = { 0 };
strcat(strTemp, str); // 得到字符串的字节数
char strReturn[STRTEMPLEN] = { 0 };
//printf("%s\n",strReturn);
for (int i = len; i > 0; i -= 2) // 中文字符占两个字节,所以一次加2才能找到下一个字符,否则会出现乱码。
{
//printf("%s", strTemp);
//printf("%s", strTemp + 4);
strcat(strReturn, (strTemp + (i-2)));
*(strTemp + (i-2)) = '\0'; // 一个汉字占用两个字节,将这两个字节都设置为0
*(strTemp + (i-1)) = '\0';
}
char* a = strReturn;
printf("%s\n", a);
return strReturn;
}上面的代码,利用了中文字符串占两个字节的特性,从源字符串的尾部,以字符串的形式拼接到目的字符串的尾部,拼接之后将此位置设置成\0,然后再拼接下一位,直至结束。?(如图)
 ?
?
?
方法二:???
?此方法可以实现中文和英文混合反转。
#include <iostream>
#include <Windows.h>
#include <string>
using namespace std;
/*实现中英文混合转换-- 由于中英文占用字节数不同,所以需要判断相应字符是英文还是中文*/
void reserve(unsigned char* str); /*对字符串进行反向*/
int main(void)
{
unsigned char a[] = "我爱你";
reserve(a);
system("pause");
return 0;
}
void reserve(unsigned char* str)
{
int len = strlen((char *)str); // 计算传入字符串的字节数
unsigned char temp[1024]; // 创建一个1024字节的数组,用来临时存放转换后的数组
// 定义两个指针,分别对str和temp进行操作
unsigned char* p1 = str; // p1指向str的开头
unsigned char* p2 = temp + len; /*因为temp数组很大,但其实我们只需要它能够存放str所占字节数+1就行(因为还有一个结束符),此时p2存放数 据的结尾是,temp+len(首元素+len,就是最后一个位置--存放'\0')*/
*p2-- = '\0'; // 做后一位为'\0'
while (*p1)
{
if (*p1 < 0x80) // *p1中的数小于127,说明是英文字符
{
*p2-- = *p1++;
}
else // 否则是中文字符
{
*(p2 - 1) = *(p1++);
*p2 = *(p1++);
p2 -= 2;
}
}
printf("%s", temp);
}1. 我们要实现中英文混合转换,因为:中文和英文所占用的字节不同,所以转换的方式也有差距,所以,要分情况。?
首先, 我们前面我们说到,汉字的高位都是1,英文为ASCLL码高位为0,如果为无符号,那么汉字的每一个字节都应该大于127(0x80),-- 此处需要与数据进行比较,所以所有字符都定义成无符号类型(不使用无符号会出错,(不使用无符号,那就是有符号,在比较时,汉字对应数据都是负值,都比127小,就都以ASCLL字符算了肯定出错))所以,每一个字节,比127大的都是汉字字符,相反为英文字符,然后按照顺序将字符串拷贝到目标字符串即可。
注意: 因为是逆转,所以要从后向前拷贝,但是中文字符一定要注意,每个字符的每个字节顺序不能乱。?
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- UART接口简介
- 空调压缩机使用注意事项二
- C++ Primer Plus----第十三章--类继承
- 市场复盘总结 20240102
- 2024年品牌最核心增长路径——不是促销,而是回归客户体验,AI成得力助手
- 019、错误处理:不可恢复错误与panic!
- 信息学奥赛一本通:1071:菲波那契数
- 定类变量的频率分析(SPSS
- C#通过代码打开其他应用程序
- 全网最新整理覆盖全平台电脑、手机的7个开源免费流媒体直播平台以及完整源码和文档