监控k8s controller和scheduler,创建serviceMonitor以及Rules
发布时间:2023年12月19日
目录
一、修改kube-controller和kube-schduler的yaml文件
二、创建service、endpoint、serviceMonitor
直接上干货
一、修改kube-controller和kube-schduler的yaml文件
注意:修改时要一个节点一个节点的修改,等上一个修改的节点服务正常启动后再修改下个节点
kube-controller文件路径:/etc/kubernetes/manifests/kube-controller-manager.yaml
kube-scheduler文件路径:/etc/kubernetes/manifests/kube-scheduler.yaml
vim?/etc/kubernetes/manifests/kube-controller-manager.yaml
vim /etc/kubernetes/manifests/kube-scheduler.yaml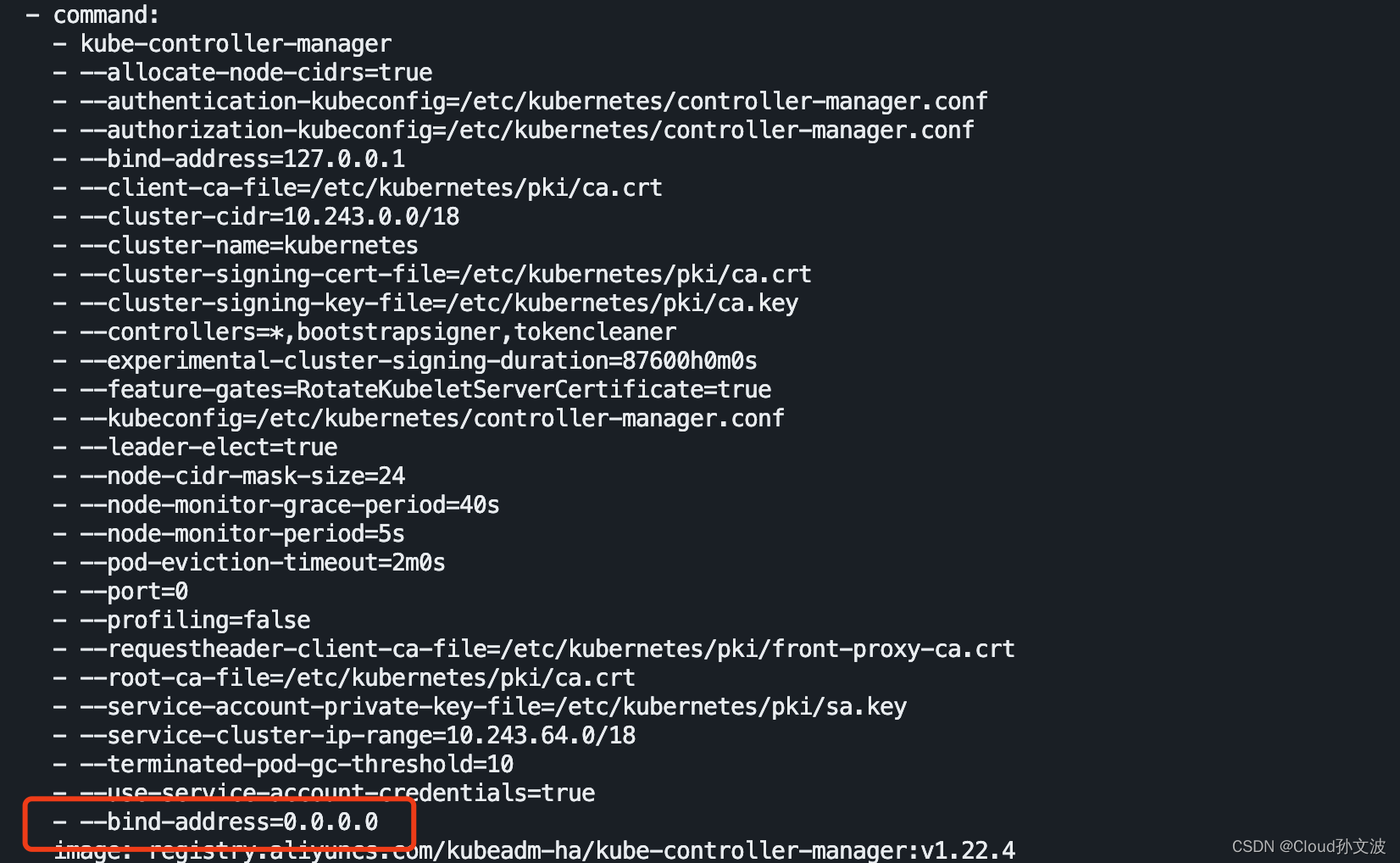

二、创建service、endpoint、serviceMonitor
kube-controller-monitor.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manage-monitor
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manage-monitor
namespace: kube-system
subsets:
- addresses:
- ip: 10.50.238.191
- ip: 10.50.107.48
- ip: 10.50.140.151
ports:
- name: https-metrics
port: 10257
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-controller-managerkube-scheduler-monitor.yaml
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler-monitor
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10259
protocol: TCP
targetPort: 10259
sessionAffinity: None
type: ClusterIP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler-monitor
namespace: kube-system
subsets:
- addresses:
- ip: 10.50.238.191
- ip: 10.50.107.48
- ip: 10.50.140.151
ports:
- name: https-metrics
port: 10259
protocol: TCP
---
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: k8s-app
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
k8s-app: kube-schedulerroot@10-50-238-191:/home/sunwenbo/prometheus-serviceMonitor/serviceMonitor/kubernetes-cluster# kubectl apply -f ./
service/kube-controller-manage-monitor created
endpoints/kube-controller-manage-monitor created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
service/kube-scheduler-monitor created
endpoints/kube-scheduler-monitor created
servicemonitor.monitoring.coreos.com/kube-scheduler created三、Prometheus验证

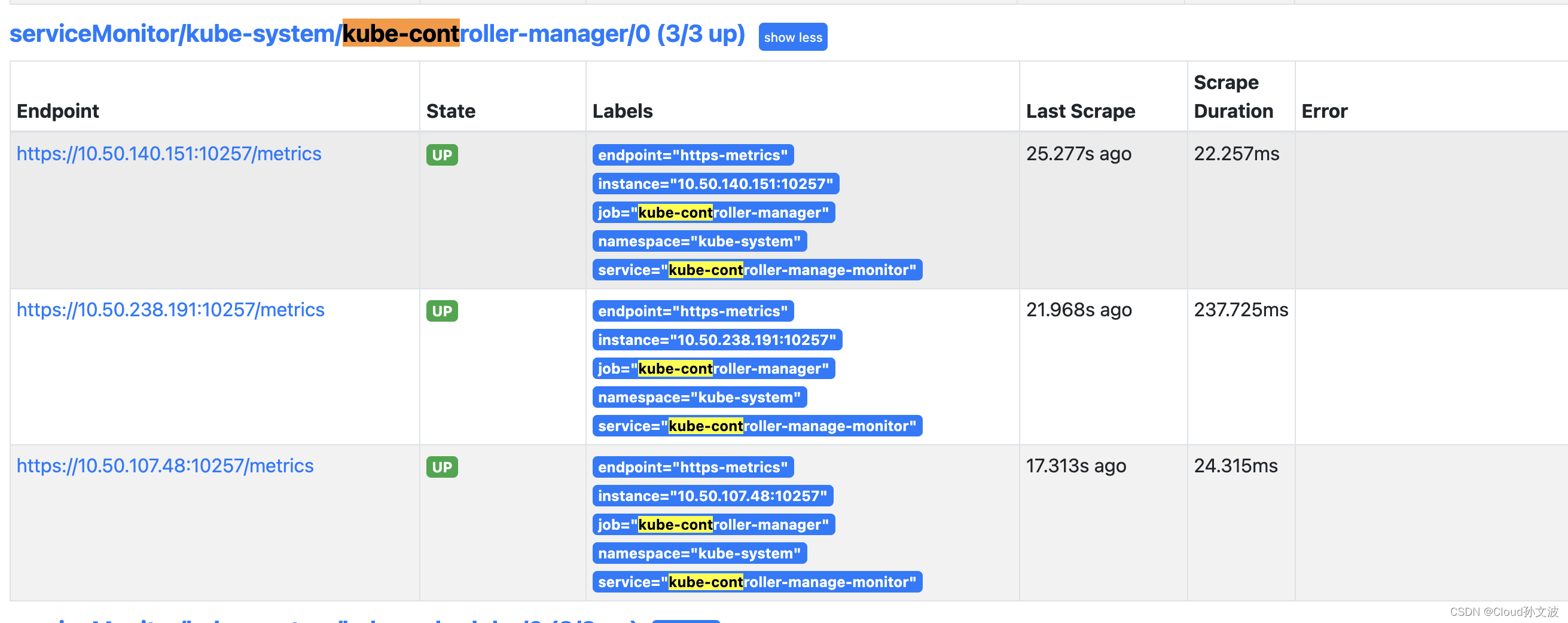
四、创建PrometheusRule资源
kube-controller-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
annotations:
meta.helm.sh/release-namespace: cattle-monitoring-system
prometheus-operator-validated: "true"
generation: 3
labels:
app: rancher-monitoring
app.kubernetes.io/instance: rancher-monitoring
app.kubernetes.io/part-of: rancher-monitoring
name: kube-controller-manager
namespace: cattle-monitoring-system
spec:
groups:
- name: kube-controller-manager.rule
rules:
- alert: K8SControllerManagerDown
expr: absent(up{job="kube-controller-manager"} == 1)
for: 1m
labels:
severity: critical
cluster: manage-prod
annotations:
description: There is no running K8S controller manager. Deployments and replication controllers are not making progress.
summary: No kubernetes controller manager are reachable
- alert: K8SControllerManagerDown
expr: up{job="kube-controller-manager"} == 0
for: 1m
labels:
severity: warning
cluster: manage-prod
annotations:
description: kubernetes controller manager {{ $labels.instance }} is down. {{ $labels.instance }} isn't reachable
summary: kubernetes controller manager is down
- alert: K8SControllerManagerUserCPU
expr: sum(rate(container_cpu_user_seconds_total{pod=~"kube-controller-manager.*",container_name!="POD"}[5m]))by(pod) > 5
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
description: kubernetes controller manager {{ $labels.instance }} is user cpu time > 5s. {{ $labels.instance }} isn't reachable
summary: kubernetes controller 负载较高超过5s
- alert: K8SControllerManagerUseMemory
expr: sum(rate(container_memory_usage_bytes{pod=~"kube-controller-manager.*",container_name!="POD"}[5m])/1024/1024)by(pod) > 20
for: 5m
labels:
severity: info
cluster: manage-prod
annotations:
description: kubernetes controller manager {{ $labels.instance }} is use memory More than 20MB
summary: kubernetes controller 使用内存超过20MB
- alert: K8SControllerManagerQueueTimedelay
expr: histogram_quantile(0.99, sum(rate(workqueue_queue_duration_seconds_bucket{job="kubernetes-controller-manager"}[5m])) by(le)) > 10
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
description: kubernetes controller manager {{ $labels.instance }} is QueueTimedelay More than 10s
summary: kubernetes controller 队列停留时间超过10秒,请检查ControllerManagerkube-scheduler-rules.yaml
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
annotations:
meta.helm.sh/release-namespace: cattle-monitoring-system
prometheus-operator-validated: "true"
generation: 3
labels:
app: rancher-monitoring
app.kubernetes.io/instance: rancher-monitoring
app.kubernetes.io/part-of: rancher-monitoring
name: kube-scheduler
namespace: cattle-monitoring-system
spec:
groups:
- name: kube-scheduler.rule
rules:
- alert: K8SSchedulerDown
expr: absent(up{job="kube-scheduler"} == 1)
for: 1m
labels:
severity: critical
cluster: manage-prod
annotations:
description: "There is no running K8S scheduler. New pods are not being assigned to nodes."
summary: "all k8s scheduler is down"
- alert: K8SSchedulerDown
expr: up{job="kube-scheduler"} == 0
for: 1m
labels:
severity: warning
cluster: manage-prod
annotations:
description: "K8S scheduler {{ $labels.instance }} is no running. New pods are not being assigned to nodes."
summary: "k8s scheduler {{ $labels.instance }} is down"
- alert: K8SSchedulerUserCPU
expr: sum(rate(container_cpu_user_seconds_total{pod=~"kube-scheduler.*",container_name!="POD"}[5m]))by(pod) > 1
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: "kubernetes scheduler {{ $labels.instance }} is user cpu time > 1s. {{ $labels.instance }} isn't reachable"
summary: "kubernetes scheduler 负载较高超过1s,当前值为{{$value}}"
- alert: K8SSchedulerUseMemory
expr: sum(rate(container_memory_usage_bytes{pod=~"kube-scheduler.*",container_name!="POD"}[5m])/1024/1024)by(pod) > 20
for: 5m
labels:
severity: info
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: "kubernetess scheduler {{ $labels.instance }} is use memory More than 20MB"
summary: "kubernetes scheduler 使用内存超过20MB,当前值为{{$value}}MB"
- alert: K8SSchedulerPodPending
expr: sum(scheduler_pending_pods{job="kubernetes-scheduler"})by(queue) > 5
for: 5m
labels:
severity: info
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: "kubernetess scheduler {{ $labels.instance }} is Pending pod More than 5"
summary: "kubernetes scheduler pod无法调度 > 5,当前值为{{$value}}"
- alert: K8SSchedulerPodPending
expr: sum(scheduler_pending_pods{job="kubernetes-scheduler"})by(queue) > 10
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: kubernetess scheduler {{ $labels.instance }} is Pending pod More than 10
summary: "kubernetes scheduler pod无法调度 > 10,当前值为{{$value}}"
- alert: K8SSchedulerPodPending
expr: sum(rate(scheduler_binding_duration_seconds_count{job="kubernetes-scheduler"}[5m])) > 1
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: kubernetess scheduler {{ $labels.instance }}
summary: "kubernetes scheduler pod 无法绑定调度有问题,当前值为{{$value}}"
- alert: K8SSchedulerVolumeSpeed
expr: sum(rate(scheduler_volume_scheduling_duration_seconds_count{job="kubernetes-scheduler"}[5m])) > 1
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: kubernetess scheduler {{ $labels.instance }}
summary: "kubernetes scheduler pod Volume 速度延迟,当前值为{{$value}}"
- alert: K8SSchedulerClientRequestSlow
expr: histogram_quantile(0.99, sum(rate(rest_client_request_duration_seconds_bucket{job="kubernetes-scheduler"}[5m])) by (verb, url, le)) > 1
for: 5m
labels:
severity: warning
cluster: manage-prod
annotations:
current_value: '{{$value}}'
description: kubernetess scheduler {{ $labels.instance }}
summary: "kubernetes scheduler 客户端请求速度延迟,当前值为{{$value}}"root@10-50-238-191:/home/sunwenbo/prometheus-serviceMonitor/rules# kubectl apply -f kube-controller-rules.yaml
prometheusrule.monitoring.coreos.com/kube-apiserver-rules configured
root@10-50-238-191:/home/sunwenbo/prometheus-serviceMonitor/rules# kubectl apply -f kube-scheduler-rules.yaml
prometheusrule.monitoring.coreos.com/kube-apiserver-rules configured
root@10-50-238-191:/home/sunwenbo/prometheus-serviceMonitor/rules# 五、Prometheus验证

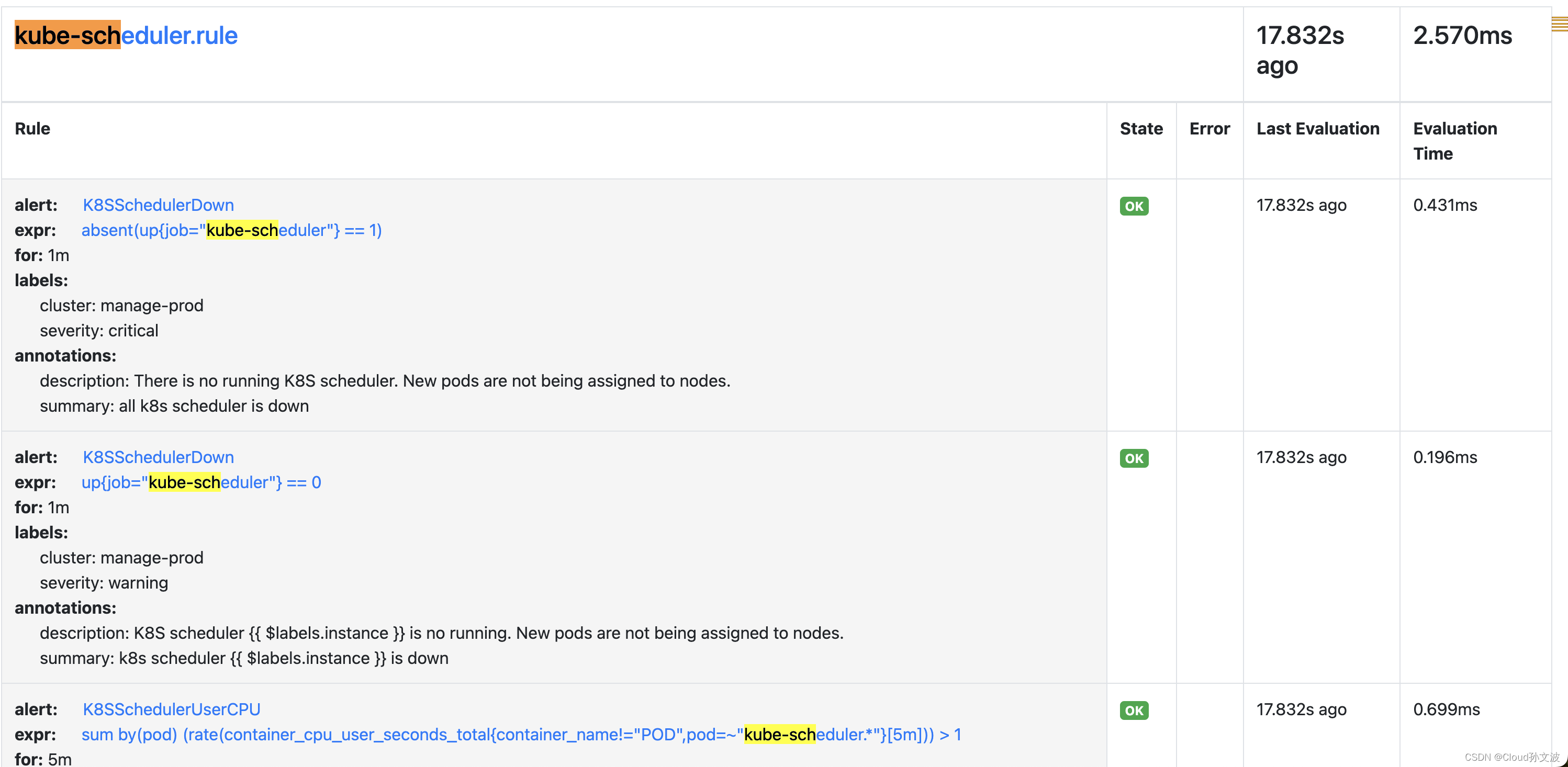
文章来源:https://blog.csdn.net/weixin_43798031/article/details/135083766
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!