T+1 到秒级实时性提升,Apache Doris 在中国邮政储蓄银行金融反欺诈领域的应用探索
导读:中国邮政储蓄银行是中国领先的大型零售银行,拥有近 4 万个营业网点,服务个人客户超 6.5 亿。从 2023 年起,中国邮政储蓄银行引入 Apache Doris 作为其核心分析引擎来构建智能风控反欺诈平台,打造事前检测、事中阻断、事后分析的全方位一体风险防控体系,实现对全行网络金融、个人金融、信用卡、消费信贷等业务交易的全面风险监控。反欺诈平台的上线实现了毫秒间的风险识别、日均拦截风险交易数万笔、有效阻止客户损失数千万,全面提升了中国邮政储蓄银行的风险防控能力和金融服务的安全性,也为客户提供了更加安全、便捷、高效的金融服务体验。
作者|中国邮储银行 软件研发中心技术专家 狄潇然
中国邮政储蓄银行是中国领先的大型零售银行,拥有近 4 万个营业网点,服务个人客户超 6.5 亿,定位于服务“三农”、城乡居民和中小企业,依托独特的“自营+代理”的模式和资源禀赋,致力于为中国经济转型中最具活力的客户群体提供服务,并加速向数据驱动、渠道协同、批零联动、运营高效的新零售银行转型。
随着科技的发展和互联网的普及,移动支付以其方便、快捷、高效的特点,逐渐成为人们日常生活中主要的支付方式。然而,这种支付方式的普及也为不法分子提供了可乘之机,比如面临支付账号盗窃、交易欺诈、未经授权支付、信息泄露等威胁。为应对这些挑战,移动支付平台和金融机构采取了一系列安全措施和反欺诈手段,以保护企业和客户的利益及资产安全。
中国邮政储蓄银行高度重视反欺诈工作,投入了大量资源来升级技术平台,致力于为客户提供安全可靠的金融服务环境。从 2023 年起,中国邮政储蓄银行引入 Apache Doris 作为其核心分析引擎来构建智能风控反欺诈平台,并基于反欺诈平台构建了智能风控体系屏障,打造事前检测、事中阻断、事后分析的全方位一体风险防控体系,实现对全行网络金融、个人金融、信用卡、消费信贷等业务交易的全面风险监控。
反欺诈平台的上线实现了毫秒间的风险识别、日均拦截风险交易数万笔、有效阻止客户损失数千万,全面提升了中国邮政储蓄银行的风险防控能力和金融服务的安全性,也为客户提供了更加安全、便捷、高效的金融服务体验。
业务背景
时间是金融反欺诈行动中的关键指标,从反欺诈平台中能否实时监控并快速获取反诈骗相关数据进行分析,并基于数据挖掘出具备关键价值的线索,直接影响反欺诈行动的成败。为了满足这一需求,中国邮政储蓄银行重视时间敏感性,对反欺诈平台提出了以下三个关键要求:
- 案件溯源:需支持对已生成案件即席深入溯源分析,包括对欺诈行为的源头、路径、涉及人员、设备和其他相关信息的分析;
- 运营监测:需支持对交易数据、行为数据、模型策略、风险特征进行实时监测,一旦发生风险事件,及时进行风险预警和干预;
- 实时准确:需支持实时精准的报表分析,能够实时捕获各类风险变化,具备高效、准确的快速响应能力。
其中核心实时分析引擎是反欺诈平台最关键的组成部分,需要负责汇集和处理海量实时交易数据、并向多个风控数据应用提供分析服务,如若想满足上述业务要求,实时分析引擎需要具备灵活、高效、准确的处理和分析能力:
- 多表关联性能优异:邮储银行内部分级建模、风险运营分析会涉及多表关联分析,具有数据规模大、分析维度不固定和查询逻辑复杂等特点,因此对多表关联性能和复杂 SQL 处理能力有较高的要求;
- 承载高并发查询:计划向数万网点的众多一线业务人员开放查询权限,因此查询并发量巨大、查询业务高峰集中、案件溯源逻辑愈加复杂等问题,因此对引擎的并发查询量要求非常高;
- 实时高频写入:反诈行动强调高实时性、需要在欺诈行为发生时立即作出响应,这是反诈能否成功的关键要素,因此分析引擎需支持上游数据的实时写入以迅速捕获风控特征变化;
- 支持写入事务、保证数据的一致性:某些运营指标对统计精度要求较高,需要做到端到端的“精准一次消费”语义,避免提高命中率的同时对正常的客户造成不必要的干扰;
- 运维难度低:上手简单,在监控、灾备、扩缩容、数据迁移等方面有自动化工具,以降低运维成本和使用风险。
技术选型
在过去很长一段时间里,当人们讨论起大数据分析时经常提及 Hive,似乎 Hive 已经成为大数据分析的代名词。然而以 Hadoop 体系无疑会引入大量的数据组件,导致数据架构愈加复杂、带来高昂的使用成本和极大的运维及管控压力,且每个组件只能解决单场景的业务痛点,却难以满足业务快速增长对于数据分析效率和时效性的需求。
因此我们在 Apache Doris、ClickHouse 以及 Greenplum、Cassandra、Kylin 等多个分析组件中进行了对比,其中重点对以实时分析性能强悍著称的 Apache Doris 和 Clickhouse 进行横向对比。在整个调研测试的过程中,我们根据实际业务场景特点设计了 89 个测试用例、前后进行了五轮部署及测试、形成了近十万字的调研结论报告, 最终得出以下结果:
- 从实时写入性能来看,Apache Doris 在写入性能方面表现优异,在同等硬件资源下其实时写入速度是 ClickHouse 的 6 倍, 且支持事务写入、“精准一次消费”语义;
- 在单表查询场景下,Apache Doris 与 ClickHouse 能力持平,均能够满足当前业务场景中对单表查询性能的要求。
- 在多表关联场景下,Apache Doris 在多表 Join、复杂聚合以及高并发场景下的查询性能相较于 ClickHouse 具备显著优势。
- 从运维管理角度来看,Apache Doris 拥有完整的高可用方案, 无论单节点故障、节点扩缩容、集群升级等都不会影响在线业务运转,并集成了多个运维管理工具,无需人工干预、可大大降低运维管理的难度。
经过综合评估,我们最终决定采用 Apache Doris 来构建中国邮政储蓄银行的反欺诈平台。
基于 Apache Doris 构建金融反欺诈平台
在反欺诈平台的整体架构中,主要数据链路如下图所示:
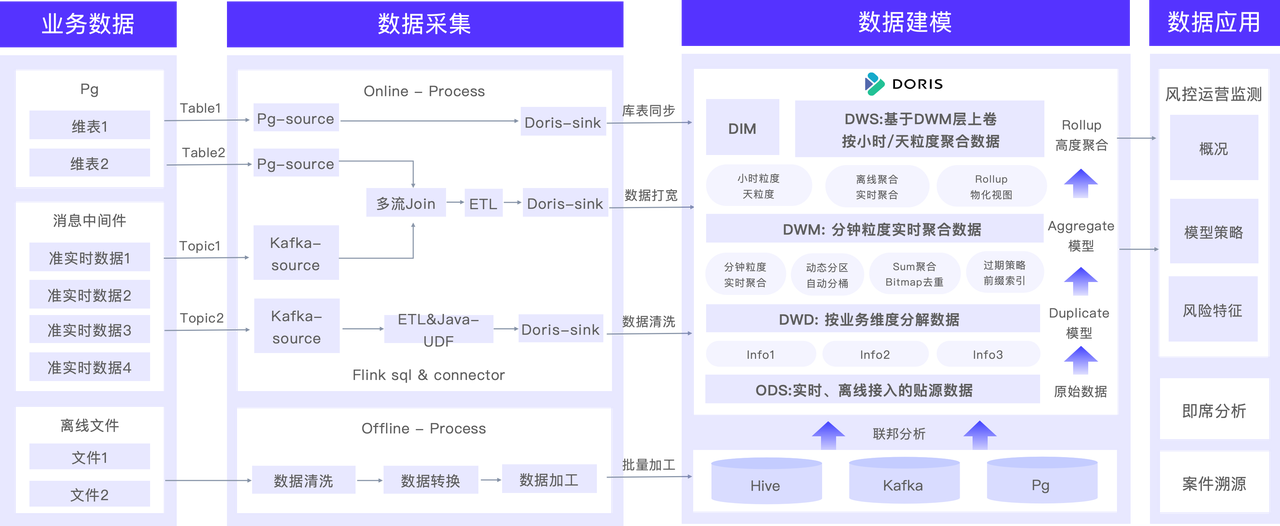
业务数据主要包括以下三类:
- 维表数据:维表类数据主要存储在关系型数据库 PostgreSQL 中,包括机构号或码表类数据;
- 交易数据:大部分实时交易数据通过消息队列 Kafka 与各外部系统进行解耦;
- 离线数据:部分外部系统的离线数据直接接入进 Hive 中,便于数仓进行补数操作。
在数据采集阶段, 我们通过 Apache Doris 的 JDBC Catalog 与 PostgreSQL 数据库进行关联,实现元数据信息和用户数据的实时库表同步。
为了处理和分析交易数据,我们利用 Flink SQL API 分别从 Kafka 中读取实时交易数据、从 PostgreSQL 数据库中获取维表数据并在 Flink 中进行多流 Join 和打宽操作。为了实现维表的即时刷新,我们采用了 Lookup Join 机制,在处理数据流时动态地查询和更新维表数据。此外我们还采用了 Java UDF 进行数据的 ETL 处理,以满足特定的业务需求和数据转换要求,最终处理完成的数据通过 Flink Doris Connector 写入至 Apache Doris 中。
对于离线数据,在进行离线清洗和转换加工后会分别进入到 Hive 等多个数据源中,通过 Multi-Catalog 来建立对应的外部数据目录,通过 Hive Metastore 来自动获取及刷新 Hive 的库表信息,便于后续进行数据联邦查询操作。
在数据建模部分, 我们在 Apache Doris 内部构建了从 ODS 到 DWS 的数据仓库分层体系,实时和离线接入的数据会进入 ODS 贴源层,随后按照业务维度进行数据分解、按照从分钟级到小时级到天级的时间粒度逐层向上抽取和聚合数据,最终建立高度聚合的 Rollup/物化视图,面向业务提供风控报表服务。
以上就是数据采集和数据建模的全流程,目前这套体系已能够有效监控风险运营,并支持对机器进行深入分析以及对案件进行溯源。通过这一体系帮助我们全面了解风险情况,并采取相应的措施来应对和管理风险,对于保障业务的安全和稳定发展至关重要。
从 T+1 缩短至分钟级,风控报表实时展示
实时特征的统计可以帮助系统及时捕捉到异常行为和模式,这对反欺诈工作的指导非常关键。过去主要存在风险特征展示不全面和风险趋势变化捕获不及时等问题,因此我们需要通过对交易数据、用户行为以及其他关键信息的全面实时监测,及时发现异常措施并采取相应的措施,以减少和避免欺诈事件的发生。
从具体实现而言,我们利用 Apache Flink 与 Apache Doris 进行风控数据实时 ETL 和实时统计。首先按照规则、模型、设备、地址等 17 个维度对数据进行建模统计,过程包括清洗、聚合、计算等,将处理后的报表实时展示在大屏上,实现了风控信息的可视化,便于业务人员及时捕捉风险信息,提供决策支持并进一步开展风控拦截操作。上线至今已支持超过 1000 万客户、3 万柜员、1 万个支行网点和 1 千个产品的在线统计分析, 该方案的成功应用为反诈工作带来了显著的收益,确保整个反欺诈行动的顺畅进行:
- 风控报表的更新周期大幅缩短,从以往的 T+1 离线处理提升至分钟级准实时处理;
- 支持复杂的即席分析,能够监控模型和规则的运行情况,及时捕捉当前的风险信息;
- 定向分析的速度从原来的小时级缩短至分钟级,且无需人工接入即可完成,极大的提升了分析效率。
多维特征复杂分析,实现案件全面溯源
案件溯源在反欺诈工作中的重要性不可忽视,其在证据收集、责任追究、风险预防和反欺诈工作效果提升等方面发挥着关键作用。当案件或案件报告生成后,我们需要建立一套完整的溯源分析手段,以实现对案件的全面追溯和分析。同时,我们还需要进行准实时的案件统计分析,并将结果以可视化的方式展示,帮助业务人员更好地了解案件情况,并能够及时采取相应的行动。
为实现上述需求,我们采用 Apache Doris 对案件生成后的多维度特征进行统计分析, 无论是基于案件来源、类型、时间等维度,还是其他相关特征,我们都能够进行全面的统计。同时 Apache Doris 具备强大的的即席查询能力,支持 10+ 种复杂条件的实时统计分析。 它能够根据实际需求进行复杂条件下的即席统计,包括多个维度的组合、筛选条件等统计计算。
该方案目前已经支持超 1 万笔案件的数据分析和详情分析,大幅缩短了案件溯源的时间成本,并能够在秒级内返回按键锁涉及的维度统计信息。 无论是对于案件的规则命中还是名单命中,均能在完全无人工干预的情况下,实现秒级别的案件统计信息反馈, 以帮助用户更高效的进行案件分析。
工单实时快速标记,分钟级定位阻断
工单标记是对特定风险事件或疑似风险事件进行标识、分类和记录的过程,通过工单标记可以精准识别风险类型、确保高风险事件得到及时关注和处理、降低潜在损失,因此在整个反欺诈工作中扮演着至关重要的角色。
在工单数据非常庞大且无法直接获取到对应的特征信息时,就需要对工单信息与交易数据进行关联分析、通过分析结果来定位风险并进行快速阻断。在日终处理中,我们需要获取增量工单信息,这个过程包括遍历工单与基础信息表以获取每个工单的 ID,利用这些 ID 在 Apache Doris 中查询存储的各项维度特征,并将其与工单进行关联。最终在前端展示具体的工单信息,实现对工单在特征维度的即席查询。
受益于 Apache Doris 强大的关联分析性能,在该场景中通过工单信息与交易信息的快速关联分析,能够快速定位阻断详情,相比之前需要进行人工关联分析的所用耗时,现在仅需几分钟即可完成, 极大提高业务团队问题定位的效率。
自动化运营预警,告警有效率高达 95%
反欺诈系统依赖于各项策略、模型和规则,而在离线环境中,数据更新可能存在一定的延迟,规则、模型和策略的命中结果以及统计信息需要等待 T+1 报表生成后才能了解实际效果,这将对反欺诈系统信息的准确性带来一定影响。
为了保证策略模型的良好运行并为后续的运营提供决策支持,我们基于 Apache Doris 设计了规则、模型和策略的自动运营预警功能。该功能实现了系统告警信息的实时接收,并监控作业运行数据和模型策略运行数据。通过前端页面实时监听命中情况,并在需要时触发预警。通过这种机制,我们能够快速发现运营告警事件。如果新规则产生负面效果,可以迅速发现并作出调整甚至下线;如果新规则效果良好,可以迅速进行推广。这种实时反馈机制使得我们能够更快速、准确地调整我们的策略。
自动运营预警功能可动态检测近百种不同类别的告警规则,实现系统级别的预警提醒。近两个月触发模型预警超 100 次、告警有效率超 95%,且预警速度非常快、能够在 5s 内进行告警。 该功能的上线降低了人工查询规则和策略命中情况所需的成本,为业务人员提供了更好的风险拦截和检测支持。
展望与规划
Apache Doris 的成功应用在中国邮政储蓄银行的反欺诈领域确实取得了显著的成效,通过引入 Apache Doris,中国邮政储蓄银行成功地构建了从数据采集、分析到预警以及动态调整上线的闭环链路,极大地提升了反欺诈工作的效率和效果。
核心报表数据的实时性从以前的 1-2 天大幅缩短至仅需 5 秒内,80% 的即席分析可以在 2 秒内返回结果,95% 的即席分析则可以在 5 秒内返回结果, 这使得银行能够快速发现和识别潜在的诈骗行为,并及时采取相应的措施进行防范和打击,最终实现日均拦截风险交易数万笔,有效阻止客户损失数千万。 除此以外,借助 Apache Doris 高效的存储压缩比,存储成本相较之前答复下降,在节省硬件资源的同时还降低了系统维护和管理的成本。
未来,中国邮政储蓄银行也将持续推广 Apache Doris 在更多业务场景得到应用,并探索最新技术特性与业务的结合,以下是后续探索的重要方向:
- 日志存储与检索: 当前使用 ELK、Kafka、Flink、Hive 等多个组件进行日志采集和存储,涉及组件较多,存在管理难度大、开发运维成本高、占用服务器硬件资源较多等问题。未来将统一采用 Kafka+Doris 的轻量级日志采集存储框架,实现日志统一管控、并可以使用 SQL 便捷查询,不仅降低了开发运维难度,还可以在不影响原业务的基础上节省服务器资源;
- 高并发点查: Apache Doris 基于列式存储引擎构建,在应对大宽表高并发查询整行数据时,可能会因为 IOPS 放大导致 CPU 开销升高,进而影响其他业务的正常使用。在 Apache Doris 2.0 版本中增加了行列混存,单节点可承载数万 QPS 的超高并发。未来我们计划引入这一能力对原有系统进行优化,使实时数仓能够直接面向给不同的分行、支行时提供服务,承受住高并发下的行式数据检索和分析,提供大数量级下的明细数据查询。
- 跨集群复制能力: 对于金融机构来说,异地灾备(如两地三中心、三地六中心)非常必要,因此跨集群复制能力是我们一直关注的能力,该能力可以实现数据的快速、准确复制,确保在灾难发生时能够及时进行主备集群切换、快速恢复业务运行并减少损失。目前 Apache Doris 已支持跨集群复制的能力,未来我们将继续关注该能力的发展并进行应用尝试。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Latexlive和Latexstudio 2022下载与安装
- STL之list
- visual Studio MFC 平台实现图片的傅里叶变换
- 解决Docker添加Docker官方的GPG密钥报错gpg: can‘t open ‘–‘: No such file or directory
- 银行数据仓库体系实践(2)--系统架构
- 华清远见嵌入式学习——ARM——作业1
- 众和策略:四部门联合印发!这一板块大爆发!
- Vue3 移动端自适应方案postcss-px-to-viewport
- linux 网络工具(二)
- (代码模板)JAVA_返回类R