《Learning eBPF》读书笔记
文章目录
由于英文不好,看得过程中还要查单词,注定是要略读了,而且不知道能不能坚持下来。
章节内容简介
相关章节,标黑的是准备看下的:
第1章:介绍
第2章:hello world例子以及ebpf程序和ebpf map概念的介绍
第3章:ebpf程序以及他们是如何运行在内核中的
第4章:探索用户态进程和ebpf程序之间的接口
第5章:介绍co-re,即一次编译,任何地方运行
第6章:ebpf验证器
第7章:介绍许多不同类型的ebpf程序和他们的挂载点
第8章:网络特性的ebpf程序介绍
第9章:ebpf安全特性应用
第10章:许多编程语言应用的概览,用户态进程和epbf程序交互使用的库和框架。
第11章:展望
第1章 什么是ebpf,为什么它很重要?
一些基础知识介绍,ebpf相比与内核模块的优势等
第2章 ebpf版hello world
一个bcc的hello world程序:
#!/usr/bin/python3
from bcc import BPF
program = r"""
int hello(void *ctx) {
bpf_trace_printk("Hello World!");
return 0;
}
"""
b = BPF(text=program)#一旦执行,则bpf程序立即被加载
syscall = b.get_syscall_fnname("execve")#屏蔽不同版本内核差异
b.attach_kprobe(event=syscall, fn_name="hello")#挂接
b.trace_print()#读取内容
bpf_trace_printk()输出内容查看:cat /sys/kernel/debug/tracing/trace_pipe,需要注意的是,所有ebpf的输出都会在这里显示,因此需要ebpf map来存储打印,数据结构等。
第3章 ebpf程序剖析
ebpf虚拟机
真正的epbf程序运行于ebpf虚拟机,用受限的c写的程序会先被编译成ebpf字节码,然后被解释成机器码
ebpf虚拟机使用10个通用寄存器0-9,而寄存器10被用作栈帧指针,是只读的。这些寄存器是软件实现的,不是真实的。0存放返回值,1~5存放参数。
ebpf指令是用这样的结构体实现的:
struct bpf_insn {
__u8 code; /* opcode */
__u8 dst_reg:4; /* dest register */
__u8 src_reg:4; /* source register */
__s16 off; /* signed offset */
__s32 imm; /* signed immediate constant */
};
一个xdp的hello word例子
c语言程序
这个例子是用c写的,如下:
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
int counter = 0;
SEC("xdp") //定义一个叫xdp的段,后面将会被编译进obj文件中。
int hello(struct xdp_md *ctx) {//函数名就是ebpf程序名
bpf_printk("Hello World %d", counter);//像之前bcc一样,打印信息
counter++;
return XDP_PASS;//让内容正常处理这个包
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";//验证器好像会来检查这个
编译为ebpf字节码
在开发工具章节中有提到:
LLVM是目前唯一提供BPF后端的编译器套件。gcc目前不支持BPF。
典型的工作流程是用C语言编写BPF程序,由LLVM编译成object / ELF文件,由用户空间BPF ELF加载程序解析,并通过BPF系统调用推入内核。内核验证BPF指令并将其jit,为程序返回一个新的文件描述符,然后可以将其附加到子系统(例如网络)。如果得到支持,子系统可以进一步将BPF程序卸载到硬件(例如网卡),即xdp。
编译上面代码的makefile如下:
hello.bpf.o: %.o: %.c
clang \
-target bpf \
-I/usr/include/$(shell uname -m)-linux-gnu \
-g \
-O2 -c $< -o $@
实际执行如下:
clang \
-target bpf \
-I/usr/include/aarch64-linux-gnu \
-g \
-O2 -o hello.bpf.o -c hello.bpf.c
编译生成的obj文件:
#file hello.bpf.o
hello.bpf.o: ELF 64-bit LSB relocatable, eBPF, version 1 (SYSV), with debug_info, not stripped
真正的c程序编出来是这样的:
# file a.out
a.out: ELF 64-bit LSB pie executable, ARM aarch64, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-aarch64.so.1, BuildID[sha1]=c9e265eba9305dc511e73fbdabebaabd5e1242cd, for GNU/Linux 3.7.0, not stripped
使用readelf -a查看hello.bpf.o:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Linux BPF
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 3968 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 27
Section header string table index: 1
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .strtab STRTAB 0000000000000000 00000e73
0000000000000109 0000000000000000 0 0 1
[ 2] .text PROGBITS 0000000000000000 00000040
0000000000000000 0000000000000000 AX 0 0 4
[ 3] xdp PROGBITS 0000000000000000 00000040
0000000000000060 0000000000000000 AX 0 0 8
可以看到有一个xdp的节。
看下对应汇编,直接使用objdump不认识:
# objdump -S hello.bpf.o
hello.bpf.o: file format elf64-little
objdump: can't disassemble for architecture UNKNOWN!
使用llvm-objdump:
# llvm-objdump -S hello.bpf.o
hello.bpf.o: file format elf64-bpf
Disassembly of section xdp:#xdp节的汇编,对应了c源码中用SEC()定义的
0000000000000000 <hello>:#这个节包含了hello这个函数
; bpf_printk("Hello World %d", counter);
0: 18 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r6 = 0 ll
2: 61 63 00 00 00 00 00 00 r3 = *(u32 *)(r6 + 0)
3: 18 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 r1 = 0 ll
5: b7 02 00 00 0f 00 00 00 r2 = 15
6: 85 00 00 00 06 00 00 00 call 6
; counter++;
7: 61 61 00 00 00 00 00 00 r1 = *(u32 *)(r6 + 0)
8: 07 01 00 00 01 00 00 00 r1 += 1
9: 63 16 00 00 00 00 00 00 *(u32 *)(r6 + 0) = r1
; return XDP_PASS;
10: b7 00 00 00 02 00 00 00 r0 = 2
11: 95 00 00 00 00 00 00 00 exit
上面的就是ebpf虚拟机的字节码
加载bpf程序到内核
在这一小节中,完成这个任务的是使用bpftool,使用如下命令:
bpftool prog load hello.bpf.o /sys/fs/bpf/hello
命令执行后没有输出,不过可以通过ls来确认:
# ls /sys/fs/bpf/
hello
这样,ebpf程序已经被成功加载了。
检查加载的程序
使用如下命令:
# bpftool prog list
85: cgroup_device tag 134b8a301991f6b7 gpl
loaded_at 2024-01-06T05:15:20+0000 uid 0
xlated 504B jited 464B memlock 4096B
pids systemd(1)
...
123: xdp name hello tag d35b94b4c0c10efb gpl
loaded_at 2024-01-06T15:46:54+0000 uid 0
xlated 96B jited 140B memlock 4096B map_ids 19,20
btf_id 126
可以看到刚刚的程序已经被加载了。
这个ebpf进程被分配的id是123,使用这个id,可以用bpftool查询更多信息。
其中jited表示程序已被jit-编译。
而map_ids表示程序使用了19和20这两个ebpf map。分别是ebpf的bss段和rodata段:
# bpftool map list
19: array name hello.bss flags 0x400
key 4B value 4B max_entries 1 memlock 4096B
btf_id 126
20: array name hello.rodata flags 0x80
key 4B value 15B max_entries 1 memlock 4096B
btf_id 126 frozen
...
# bpftool map dump name hello.bss
[{
"value": {
".bss": [{
"counter": 14750
}
]
}
}
]
root@lima-learning-ebpf:/Users/xuweidong/project/learning-ebpf/chapter3# bpftool map dump name hello.rodata
[{
"value": {
".rodata": [{
"hello.____fmt": "Hello World %d"
}
]
}
}
]
其中bss段也就是存放了全局变量counter,rodata段是我们的字符串。需要注意的是只有编译时加了-g以及支持BTF,才能打印出这个效果。
tag是程序指令的sha校验和,当程序加载卸载,id可能会变,但tag不会变。
可以直接使用bpftool查看被转换的ebpf字节码:
# bpftool prog dump xlated name hello
int hello(struct xdp_md * ctx):
; bpf_printk("Hello World %d", counter);
0: (18) r6 = map[id:19][0]+0
2: (61) r3 = *(u32 *)(r6 +0)
3: (18) r1 = map[id:20][0]+0
5: (b7) r2 = 15
6: (85) call bpf_trace_printk#-73840
; counter++;
7: (61) r1 = *(u32 *)(r6 +0)
8: (07) r1 += 1
9: (63) *(u32 *)(r6 +0) = r1
; return XDP_PASS;
10: (b7) r0 = 2
11: (95) exit
运行时编译机器码
jit即just in time,虽然上面看到的转换后的字节码已经是很低级了,但是还不是最终的机器码。ebpf使用即时编译器来将ebpf字节码转换成真正运行本地cpu上的机器码。
仍然使用bpftool查看真正的机器码:
# bpftool prog dump jited name hello
int hello(struct xdp_md * ctx):
bpf_prog_d35b94b4c0c10efb_hello:
; bpf_printk("Hello World %d", counter);
0: stp x29, x30, [sp, #-16]!
4: mov x29, sp
8: stp x19, x20, [sp, #-16]!
c: stp x21, x22, [sp, #-16]!
10: stp x25, x26, [sp, #-16]!
14: mov x25, sp
18: mov x26, #0
1c: sub sp, sp, #0
20: mov x19, #-281474976710656
24: movk x19, #32768, lsl #32
28: movk x19, #2184, lsl #16
2c: mov x10, #0
30: ldr w2, [x19, x10]
34: mov x0, #-239581865705473
38: movk x0, #16459, lsl #16
3c: movk x0, #44304
40: mov x1, #15
44: mov x10, #-15440
48: movk x10, #27055, lsl #16
4c: movk x10, #51572, lsl #32
50: blr x10
54: add x7, x0, #0
; counter++;
58: mov x10, #0
5c: ldr w0, [x19, x10]
60: add x0, x0, #1
64: mov x10, #0
68: str w0, [x19, x10]
; return XDP_PASS;
6c: mov x7, #2
70: mov sp, sp
74: ldp x25, x26, [sp], #16
78: ldp x21, x22, [sp], #16
7c: ldp x19, x20, [sp], #16
80: ldp x29, x30, [sp], #16
84: add x0, x7, #0
88: ret
至此“Hello World”程序已经加载到内核中,但是此时它还没有与事件关联,因此没有任何东西会触发它运行。它需要附加到一个事件。
附加到事件
仍然使用bpftool,额外的,如果是xdp程序,也可以使用ip link来加载到网络接口上:
bpftool net attach xdp name hello dev eth0
root@lima-learning-ebpf:/Users/xuweidong/project/learning-ebpf/chapter3# bpftool net list
xdp:
eth0(2) driver id 123
tc:
flow_dissector:
netfilter:
# ip link
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq_codel state UP mode DEFAULT group default qlen 1000
link/ether 52:55:55:c9:9e:d6 brd ff:ff:ff:ff:ff:ff
prog/xdp id 123 tag d35b94b4c0c10efb jited
查看输出,可以不使用/sys/kernel/debug/tracing/trace_pipe,而使用bpftool查看:
# bpftool prog tracelog
bpftool-16915 [002] d.s.. 39786.828735: bpf_trace_printk: Hello World 13115
<idle>-0 [002] d.s.. 39786.830403: bpf_trace_printk: Hello World 13116
<idle>-0 [003] d.s.. 39797.947963: bpf_trace_printk: Hello World 13117
...
分离程序
事件关联去除:
# bpftool net detach xdp dev eth0
root@lima-learning-ebpf:/Users/xuweidong/project/learning-ebpf/chapter3# bpftool net list
xdp:
tc:
flow_dissector:
netfilter:
卸载程序
从内核卸载ebpf程序很直接,直接rm就行了
# rm /sys/fs/bpf/hello
成功了同样没输出,可以使用bpftool prog show name hello查看,没输出代表卸载成功。
第4章 bpf()系统调用
这章探索了最原始的系统调用bpf(),也即前面的bcc,以及利用libbpf写的程序真正调用的系统接口。这章暂时先不看了。
第5章 CO-RE, BTF, and Libbpf
CO-RE概览
CO-RE即一次编译,任何地方运行compile once,run everywhere。CO-RE一般被读做和单词core同样发音,而不是读两个音节。
专有名词解释
BTF
一种用于表示数据结构布局和函数签名的格式,在CO-RE中用于确定在编译时和运行时的结构体的任何差异,也在bpftool中用来用更易读的格式打印结构体内容。linux 5.4开始支持
内核头文件
包含于内核源码,用来描述内核使用的数据结构,在不同版本的内核,头文件可能有变更。ebpf开发者可以选择包含单独的头文件,也可以使用bpftool来从运行的系统中生成一个叫vmlinux.h的头文件,这个头文件包含了所有的ebpf程序也许需要的内核的数据结构信息。
编译支持
clang编译器可以在加了-g的flag编译ebpf程序时包含CO-RE相关信息。GCC也添加了支持,但是要在GCC12才有。
数据结构重定位的库支持
当用户空间程序向内核加载ebpf程序时,CO-RE需要根据编译进obj的CO-RE重定位信息将字节码进行调整以适应结构体在编译时和目标机器运行时的实现的不同。目前libbpf,还有cilium的go库以及aya都实现了这个。
BPF skeleton
BPF skeleton可以在编译ebpf obj文件时自动生成,这里面包含了一些易用的函数,使用这些函数可以让用户态代码来调用去管理bpf程序的生命周期-比如加载到内核,关联到事件之类的。可以使用bpftool gen skeleton来生成skeleton。这些函数是高层抽象的,相比于libpbf等基础库,这些函数对开发者来说可以更方便。
BTF例子
BCC结构体:
struct user_msg_t {
char message[12];
};
BTF,定义了这个结构体的布局:
[1] TYPEDEF 'u32' type_id=2
[2] TYPEDEF '__u32' type_id=3
[3] INT 'unsigned int' size=4 bits_offset=0 nr_bits=32 encoding=(none)
[4] STRUCT 'user_msg_t' size=12 vlen=1
'message' type_id=6 bits_offset=0
[5] INT 'char' size=1 bits_offset=0 nr_bits=8 encoding=(none)
[6] ARRAY '(anon)' type_id=5 index_type_id=7 nr_elems=12
[7] INT '__ARRAY_SIZE_TYPE__' size=4 bits_offset=0 nr_bits=32 encoding=(none)
BCC函数
int hello(void *ctx)
BTF,typeid 32定义了函数原型信息:
[10] PTR '(anon)' type_id=0
...
[23] INT 'int' size=4 bits_offset=0 nr_bits=32 encoding=SIGNED
...
[31] FUNC_PROTO '(anon)' ret_type_id=23 vlen=1
'ctx' type_id=10
[32] FUNC 'hello' type_id=31 linkage=static
另外也可以这样来获取btf信息:
# bpftool btf dump map name config 4031 0 lima-guestagent Hey root!
[1] TYPEDEF 'u32' type_id=2 4033 0 lima-guestagent Hey root!
[4] STRUCT 'user_msg_t' size=12 vlen=1 4034 0 lima-guestagent Hey root!
'message' type_id=6 bits_offset=0
对应的BPF HASH:
BPF_HASH(config, u32, struct user_msg_t);
libbpf
生成内核头文件
就像前面提到的vmlinux.h可以减少的你工作,可以使用bpftool来生成:
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
如果没有/sys/kernel/btf/vmlinux这个文件,那可能需要开启CONFIG_DEBUG_INFO_BTF选项来重编内核。
如果你想要使用libbpf的bpf帮助函数,那么你就需要包含vmlinux.h或者linux/type.h,因为libbpf里使用了像u32,u64这种类型。
ebpf程序的节
使用libbpf的每个ebpf程序都需要使用SEC()来标记程序类型。
比如SEC("kprobe")会在编译的elf中产生一个kprobe的section,然后libbpf就知道应该将这个程序加载为BPF_PROG_TYPE_KPROBE。进一步的,通过程序类型,你可以指定这个程序关联的事件,libbpf将会使用这些信息自动的关联,比如使用SEC("ksyscall/execve"),将告诉加载器自动关联到kprobe的架构特定的execve上。
可用的节名和格式在libbpf手册可以查到。
以下是内核ebpf程序hello-buffer-config.bpf.c的部分节选,节的定义声明了ebpf程序应该挂接在哪,挂接的程序在其后定义:
SEC("ksyscall/execve")
int BPF_KPROBE_SYSCALL(hello, const char *pathname) //BPF_KPROBE_SYSCALL是一个宏,可以方便的访问syscall的参数,pathname就是即将被程序程序的路径名,而hello则是ebpf的程序名
{
struct data_t data = {};
struct user_msg_t *p;
data.pid = bpf_get_current_pid_tgid() >> 32;
data.uid = bpf_get_current_uid_gid() & 0xFFFFFFFF;
bpf_get_current_comm(&data.command, sizeof(data.command));
bpf_probe_read_user_str(&data.path, sizeof(data.path), pathname); //使用帮助函数,将pathname包含到perf 缓冲区输出的数据中去。
p = bpf_map_lookup_elem(&my_config, &data.uid);
if (p != 0) {
bpf_probe_read_kernel(&data.message, sizeof(data.message), p->message);
} else {
bpf_probe_read_kernel(&data.message, sizeof(data.message), message);
}
bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU,
&data, sizeof(data)); //BPF_KPROBE_SYSCALL中定义了ctx
return 0;
}
CO-RE 内存访问
ebpf验证器不允许你通过指针访问内存,libbpf提供了一些CO-RE包装函数,比如d= a->b->c->d;可以写成这样:
struct b_t *b;
struct c_t *c;
bpf_core_read(&b, 8, &a->b);
bpf_core_read(&c, 8, &b->c);
bpf_core_read(&d, 8, &c->d);
或更紧凑的:
d = BPF_CORE_READ(a, b, c, d);
在这之后,你就可以通过bpf_probe_read_kernel()从指针d来读取了。
编译CO-RE ebpf程序
编译参数
llvm-strip -g <object file> 保留-g,去除DWARF调试信息
-O2 clang产生ebpf字节码所需
-D __TARGET_ARCH_($ARCH) 当你使用了一些libbpf定义的宏,你必须在编译时指定目标架构,因为这些宏是架构相关的.在这里$ARCH是像arm64,amd64等架构名。
因此,一次编译,到处运行,也许应该叫做在每个架构上,一次编译,到处运行。
最终的编译脚本如下:
hello-buffer-config.bpf.o: %.o: %.c
clang \
-target bpf \
-D __TARGET_ARCH_$(ARCH) \
-I/usr/include/$(shell uname -m)-linux-gnu \
-Wall \
-O2 -g \
-c $< -o $@
llvm-strip -g $@
为何要生成CO-RE用户态代码
前面章节中,可以利用bpftool直接将ebpf程序加载到内核,甚至关联到事件,然而,在许多应用中,你可能并不想让用户自己来运行bpftool加载ebpf程序。相反,你希望将此功能构建到作为可执行文件提供的专用用户空间程序中。为此,你需要自己写一个用户态程序。
bpf skeletons
在这里的例子中,可以使用如下命令来从已经编译好的ebpf obj文件来自动生成skeletons:
bpftool gen skeleton hello-buffer-config.bpf.o > hello-buffer-config.skel.h
在这个生成的头文件中,你可以看到里面包含了ebpf程序和mas的结构体定义,还有一些以obj文件名字为开头的函数:hello_buffer_config_bpf__xxx。这些函数用来管理ebpf程序和maps的生命周期。
在这个头文件的最后,还有这个:
static inline const void *hello_buffer_config_bpf__elf_bytes(size_t *sz)
{
static const char data[] __attribute__((__aligned__(8))) = "\
\x7f\x45\x4c\x46\x02\x01\x01\0\0\0\0\0\0\0\0\0\x01\0\xf7\0\x01\0\0\0\0\0\0\0\0\
\0\0\0\0\0\0\0\0\0\0\0\x98\x13\0\0\0\0\0\0\0\0\0\0\x40\0\0\0\0\0\x40\0\x0e\0\
\x01\0\xbf\x16\0\0\0\0\0\0\x18\x01\0\0\0\0\0\0\0\0\0\0\0\0\0\0\x71\x11\0\0\0\0\
...
\0\0\0\0\0\0\0\x70\x0e\0\0\0\0\0\0\x20\x01\0\0\0\0\0\0\x01\0\0\0\x06\0\0\0\x08\
\0\0\0\0\0\0\0\x18\0\0\0\0\0\0\0";
*sz = sizeof(data) - 1;
return (const void *)data;
}
这个就是obj文件的内容,当skeleton文件生成后,obj文件就不在需要了。
这些函数在稍后编写的用户态程序中都会用到。
用户态程序
以下就是用户态程序hello-buffer-config.c:
... [other #includes]
#include "hello-buffer-config.h"
#include "hello-buffer-config.skel.h"
... [some callback functions]
int main()
{
struct hello_buffer_config_bpf *skel;
struct perf_buffer *pb = NULL;
int err;
libbpf_set_print(libbpf_print_fn); //设置回调函数显示libbpf产生的日志信息
skel = hello_buffer_config_bpf__open_and_load(); //skeleton内联函数,实现了所有maps和程序在elf里的定义以及内核加载
...
err = hello_buffer_config_bpf__attach(skel); //设置自动挂接到合适的事件
...
pb = perf_buffer__new(bpf_map__fd(skel->maps.output), 8, handle_event,
lost_event, NULL, NULL); //创建结构体来处理perfbuffer的输出
...
while (true) { //持续轮询perf buffer
err = perf_buffer__poll(pb, 100);
...}
perf_buffer__free(pb); //清理环境的代码
hello_buffer_config_bpf__destroy(skel);
return -err;
}
第6章 ebpf验证器
跳过,这章提到你写的程序很大可能通过不了验证器的验证,所以写程序也是个很大的挑战
第7章 ebpf程序和挂接类型
帮助函数的man手册,对应每种ebpf程序类型以及挂接类型,允许使用的帮助函数是不同的,比如在某些类型的ebpf程序中,某些帮助函数是没有意义的。可以使用bpftool feature命令来查看运行使用的帮助函数。
Kfuncs
在ebpf程序中允许调用一些内核内部的函数,这个机制被称为kfuncs。kfuncs允许内部的内核函数被注册到bpf子系统,这样,验证器可以允许ebpf程序来调用这些函数。一般认为程序类型分为两类:跟踪(或性能)程序类型和与网络相关的程序类型。下面将分别介绍这两种。
追踪程序
kprobe/ketprobe
kprobe几乎可以挂接到内核的任何地方,除了一些特殊的地方,比如kprobe本身,这是为了避免死循环。除了函数入口点和退出的地方,还可以设置偏移在特定指令。
系统调用kprobe的上下文参数是一个结构,表示用户空间传递给系统调用的值。“常规”(非系统调用)kprobe的上下文参数是一个结构,表示调用该函数的内核代码传递给该函数的参数,因此该结构取决于函数定义。
fentry/fexit
x86在5.5支持,arm在6.0支持。
fentry/fexit比kprobe/kretprobe更高效,并且fexit除了返回值还能访问函数入参,这是kretprobe办不到的。
SEC("kretprobe/do_unlinkat")
int BPF_KRETPROBE(do_unlinkat_exit, long ret)
SEC("fexit/do_unlinkat")
int BPF_PROG(do_unlinkat_exit, int dfd, struct filename *name, long ret)
tracepoint
跟踪点是在内核代码中标记的位置(我们将在本章后面讨论用户空间跟踪点)。它们绝不是eBPF所独有的,长期以来一直用于生成内核跟踪输出和SystemTap等工具。与使用kprobes附加到任意指令不同,跟踪点在内核版本之间是稳定的(尽管旧内核可能没有添加到新内核中的完整跟踪点集)。
使用cat /sys/kernel/tracing/available_events可以查看追踪点。
在这里,没有btf的帮助,需要自己使用命令查看格式:
# cat /sys/kernel/tracing/events/syscalls/sys_enter_execve/format
name: sys_enter_execve
ID: 627
format:
field:unsigned short common_type; offset:0; size:2; signed:0;
field:unsigned char common_flags; offset:2; size:1; signed:0;
field:unsigned char common_preempt_count; offset:3; size:1; signed:0;
field:int common_pid; offset:4; size:4; signed:1;
field:int __syscall_nr; offset:8; size:4; signed:1;
field:const char * filename; offset:16; size:8; signed:0;
field:const char *const * argv; offset:24; size:8; signed:0;
field:const char *const * envp; offset:32; size:8; signed:0;
print fmt: "filename: 0x%08lx, argv: 0x%08lx, envp: 0x%08lx", ((unsigned long)(REC->filename)), ((unsigned long)(REC->argv)), ((unsigned long)(REC->envp))
然后自己定义结构体并使用:
struct my_syscalls_enter_execve {
unsigned short common_type;
unsigned char common_flags;
unsigned char common_preempt_count;
int common_pid;
long syscall_nr;
long filename_ptr;
long argv_ptr;
long envp_ptr;
};
SEC("tp/syscalls/sys_enter_execve")
int tp_sys_enter_execve(struct my_syscalls_enter_execve *ctx) {
btf-enabled tracepoint
使用vmlinux.h中的结构体:
SEC("tp_btf/sched_process_exec")
int handle_exec(struct trace_event_raw_sched_process_exec *ctx)
用户态挂接点
uprobe/uretprobe,user statically defined tracepoints (USDTs)
如果想挂接到openssl的函数SSL_write(),可以像下面这样定义:
SEC("uprobe/usr/lib/aarch64-linux-gnu/libssl.so.3/SSL_write")
LSM
跳过,安全模块相关
网络程序
网络消息处理过程中有很多ebpf程序类型,当他们经过网络协议栈的很多流程时
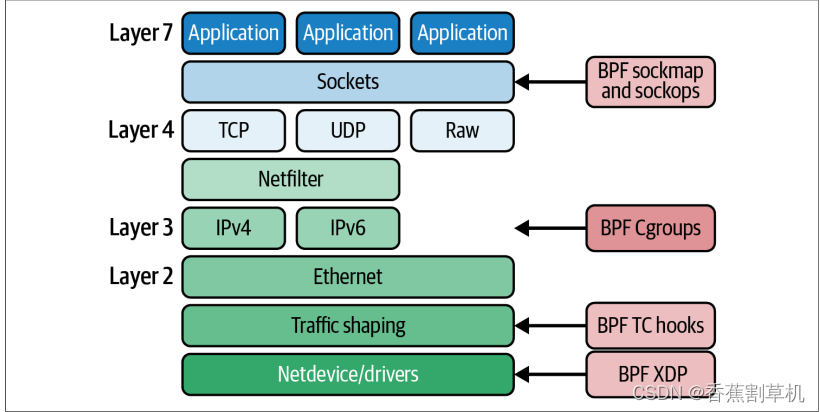
网络程序和跟踪程序不同,网络程序允许自定义网络行为:
1.使用返回值决定包处理行为,正常处理,丢弃,转发到不同目的地
2.允许ebpf程序修改网络包,socket配置参数等
sockets
tc:traffic control
xdp
flow dissector
lightweight tunnels
cgroups
control groups,
infrared controllers
bpf挂接类型
附件类型对程序在系统中的附加位置提供了更细粒度的控制。对于某些程序类型,它与可以附加到的钩子类型有一对一的关联,因此附加类型由程序类型隐式定义。例如,XDP程序被附加到网络栈中的XDP钩子上。对于一些程序类型,还必须指定附件类型。
附件类型涉及到决定哪些辅助函数有效,并且在某些情况下,它还限制对部分上下文信息的访问。
您还可以在内核函数bpf_prog_load_check_attach(在bpf/ sycall .c中定义)中查看哪些程序类型需要指定附件类型,以及哪些附件类型是有效的。
第8章 ebpf网络编程
跳过,看累了
第9章 ebpf安全
累
第10章 ebpf编程
第11章 ebpf的未来演变
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++实现模版模式 + 创建者模式的demo
- 安装ROS2-ubuntu
- FlinkSQL中的窗口
- 基于深度学习大模型实现离线翻译模型私有化部署使用,通过docker打包开源翻译模型,可到内网或者无网络环境下运行使用,可以使用一千多个翻译模型语言模型进行翻译
- 《佛法修学概要》期中座谈(五)
- PriorityBlockingQueue原理探究
- JavaScript面向对象编程实战
- vector函数介绍与实现(迭代器失效)
- 数据查询语言(Data Query Language,DQL)全部语法举例(一)单表查询
- 湘潭大学-软件工程-头歌-第一章-软件工程课程概述-实践准备 - 分布式版本管理工具