爬虫案例—抓取豆瓣电影的电影名称、评分、简介、评价人数
发布时间:2024年01月15日
爬虫案例—抓取豆瓣电影的电影名称、评分、简介、评价人数
豆瓣电影网址:https://movie.douban.com/top250
主页截图和要抓取的内容如下图:
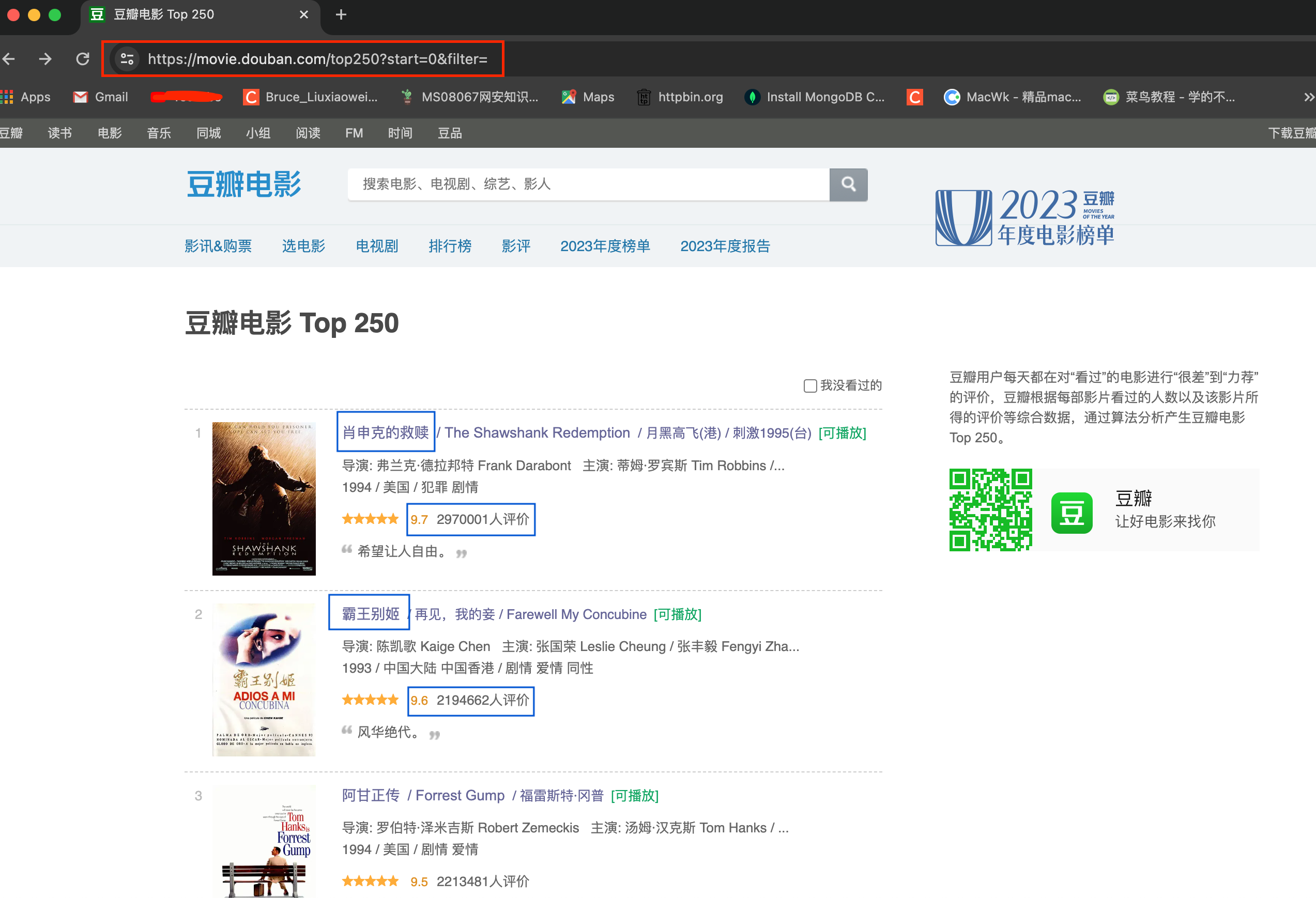
分析:
第一页的网址:https://movie.douban.com/top250?start=0&filter=
第二页的网址:https://movie.douban.com/top250?start=25&filter=
第三页的网址:https://movie.douban.com/top250?start=50&filter=
…
以此类推,不难发现页面的网址的start值与25多倍数有关。这样可以格式化网址为:f"https://movie.douban.com/top250?start={i*25}&filter="。
按F12进入浏览器的开发者模式,用xpath匹配到页面所有列表标签。如下图:
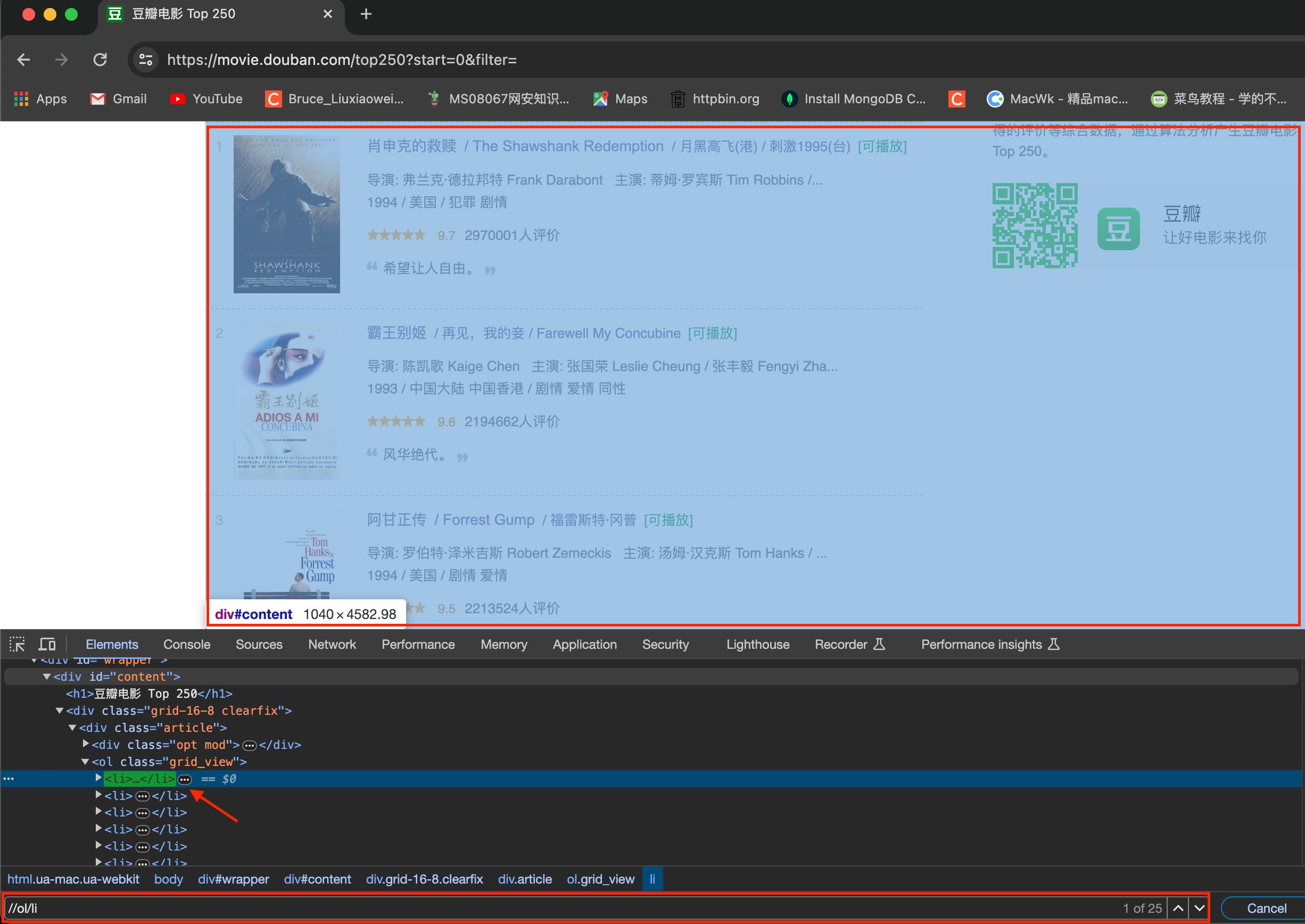
进一步分析,进入li标签内,用xpath匹配到对应的电影标题和评分,评价人数。每部电影的详细简介在电影的浏览页面内,需要先获取到电影的href,然后再进行获取。
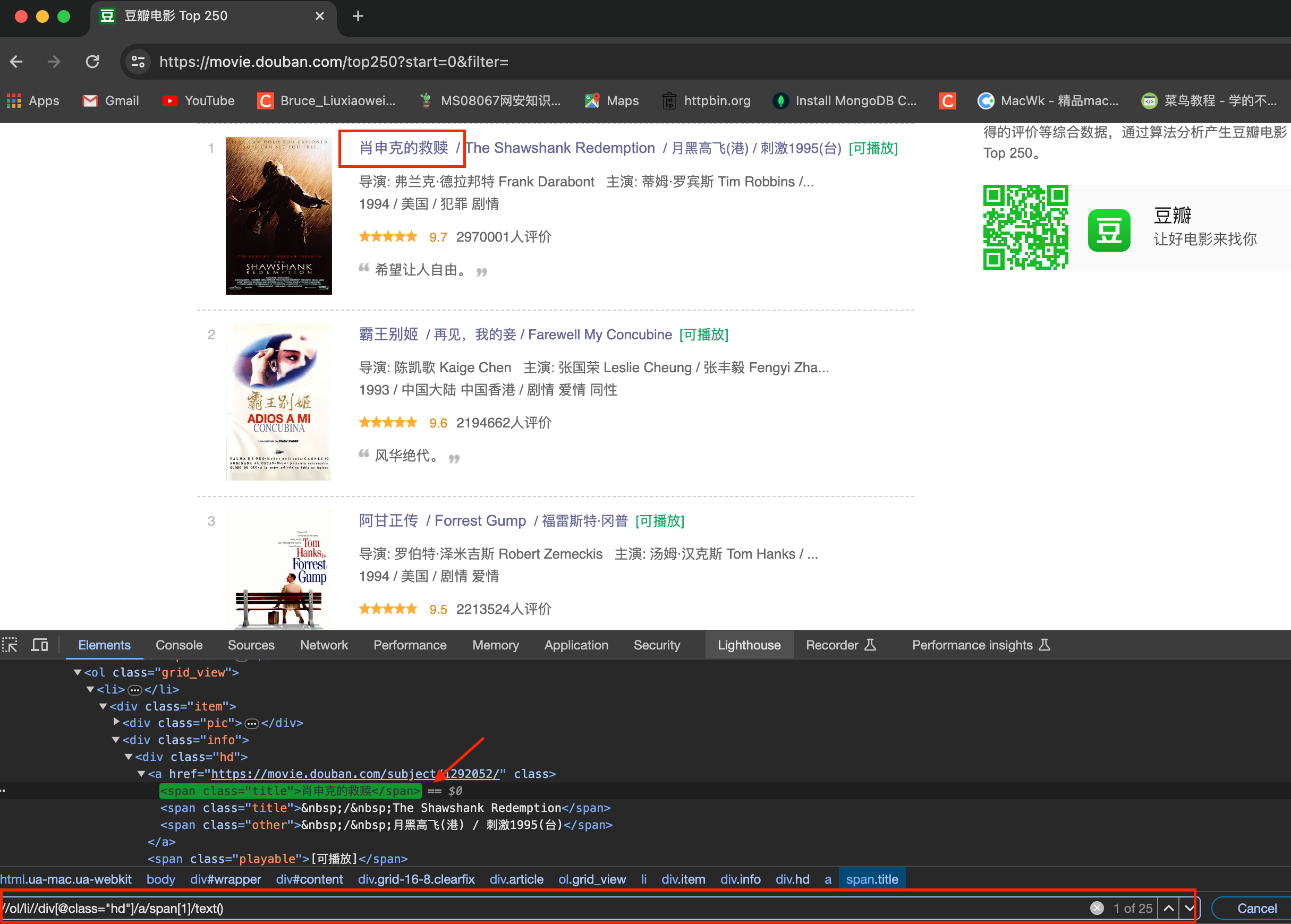
其他内容的匹配与上图类似,不再赘述。
具体的代码如下:
import requests
from lxml import etree
import time
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
# 获取页面响应内容函数
def get_page(url):
res = requests.get(url, headers=headers)
res.encoding = res.apparent_encoding
html = res.content.decode() # 如果用res.text,某些页面的简介会返回乱码
return html
# 返回响应页面的所有电影列表标签
def get_li_lst(url):
tree = etree.HTML(get_page(url))
li_lst = tree.xpath('//ol/li')
return li_lst
# 获取电影名,评分,评价人数的函数
def get_page_datail(url):
li_lst = get_li_lst(url)
for li in li_lst:
print('-' * 50)
title = li.xpath('.//div[@class="hd"]/a/span[1]/text()')
print('电影名:', title[0], end=' | ')
score = li.xpath('./div[@class="item"]//div[@class="star"]/span[2]/text()')
print('评分:', score[0], end=' | ')
person_num = li.xpath('./div[@class="item"]//div[@class="star"]/span[4]/text()')
print('评价人数:', person_num[0])
movie_href = li.xpath('.//div[@class="hd"]/a/@href')[0]
movie_html = get_page(movie_href)
movie_tree = etree.HTML(movie_html)
movie_short = movie_tree.xpath('//div[@class ="indent"]//span[@property="v:summary"]/text()')
print('电影简介:')
print(movie_short[0].strip())
time.sleep(0.5)
print('-' * 50)
if __name__ == '__main__':
page_num = int(input('请输入要获取的页码数: '))
for i in range(page_num):
print(f'第{i + 1}页电影数据:')
new_url = f'https://movie.douban.com/top250?start={i * 25}'
time.sleep(0.3)
get_page_datail(new_url)
print()
运行结果如下图:

文章来源:https://blog.csdn.net/weixin_41905135/article/details/135592308
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章