T2I-Adapter: 让马良之神笔(扩散模型)从文本生成图像更加可控
文章信息

单位:北大深张健团队,腾讯ARC lab
源码: https://github.com/TencentARC/T2I-Adapter
前言
大规模的text2image模型具有不可置信的生成能力,已经在学习复杂结构和高层语义上展现了超能力。但是,仅依赖文本提示还不够充分挖掘这些能力,特别是在灵活以及准确地控制下(例如颜色和结构)。在这篇文章中,作者尝试去发掘这种T2I模型隐性学习的能力,然后直接使用它们去控制更加有颗粒度的生成。特别地,作者提出学习简单的轻量级的T2I-Adapters去对齐模型内部的知识。作者会固定住原始的T2I模型,并调控外部的控制信息,以这样的方式,作者能够训练不同的适配器来对应不同的场景,提升丰富的控制和编辑效果在颜色和结构上。并且,提出的适配器具有实用价值,例如泛化性与组合性。更多的实验证明了作者的适配器取得了优秀的生成效果和广泛的应用。
一、介绍
由于在海量数据和超大算力的训练,T2I模型在给定文本的情况下用于生产图片,已经被证明具有很强的生成能力。这些生成式的结果通常具有丰富的纹理,清晰的边界,合理的结构以及正确的语义。这些现象潜在地表明T2I模型能够以隐性的方式去较好捕捉到不同级别的信息,从低级别(纹理),中层级别(边缘)到高级别(语义)。
尽管取得了不错的合成质量,它非常依赖于设计良好的提示【22,26】,并且生成式的基线模型缺少灵活的用户控制能力,这种能力能够指导合成的图片能够更加精确地实现用户的意图。对于一个不专业的用户,生成的结果通常是不可控的和不稳定的。例如,最近提出的Stable Diffusion SD模型在想象的场景下表现不太好,例如下图所示“带有翅膀的小车”,“带有兔耳朵的钢铁侠”。作者觉得并不是T2I没有这种生成的能力,而是提示文本不能提供精确的结构指引。


作者比较好奇的是,是否可能去挖掘T2I模型的隐性学习能力,特别是高层级的结构与语义能力,然后直接使用它们去控制更加准确地生成。
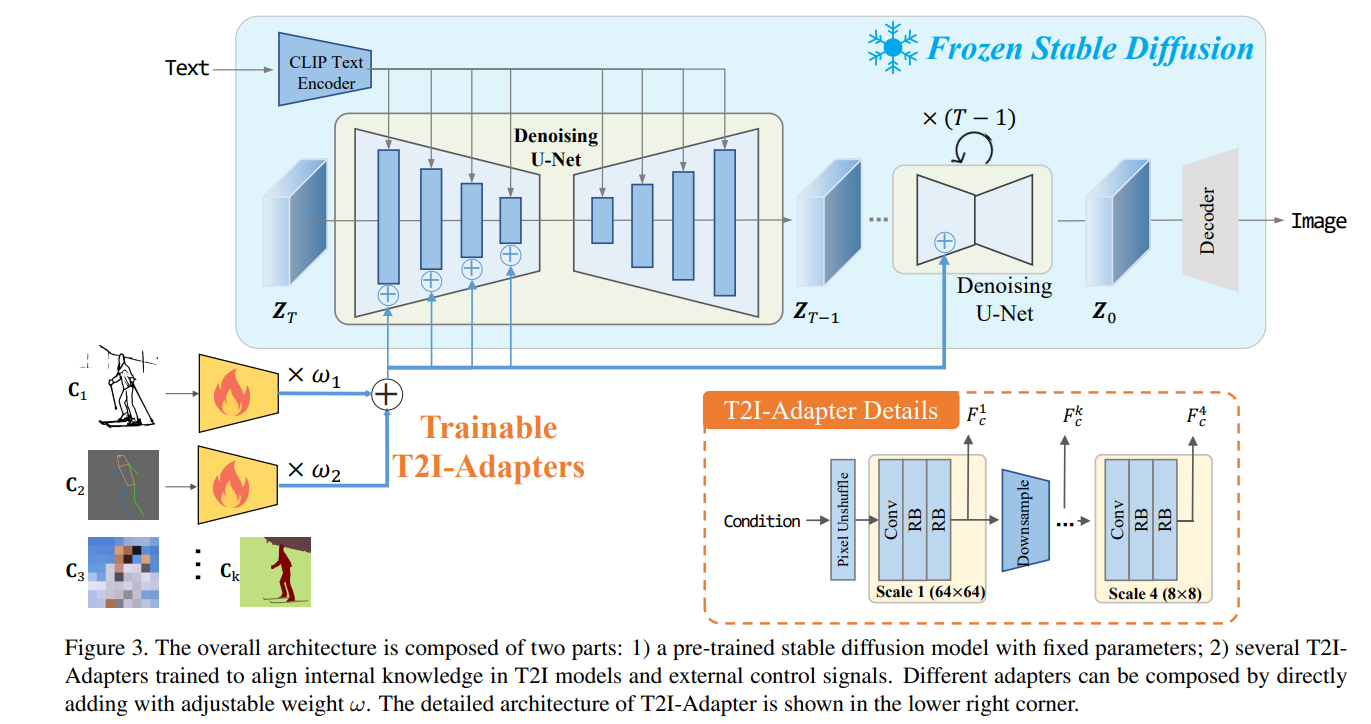
作者觉得一个小的适配器模型能够取得这个目的,因为它不是学习新的生成能力,而是学习一个从控制信息到模型内部知识的映射。也就是说,主要的问题是对齐任务,即内部的只是和外部的控制信号应该被对齐。因此,作者提出T2I-Adapters,一个轻量级的模型能够用于学习这种对齐,在使用相对少量的数据下。T2I适配器提供了带有额外提示的预训练的SD模型。通过这样的方式,作者能够训练不同的适配器以适应不同的场景,然后提供了更加精确可控的生产指导。如下图所示,这种适配器,作为额外的网络注射指导信息,具有以下优点:
- 插件可玩。他们不影响原始的网络结构和生成能力;
- 结构简单。他们能够简单地插入到当前的T2I模型中,在花费少量的训练代价下。并且他们在扩散过程中仅需要一次推理。他们只有77M参数量和300M的存储空间。
- 灵活性。作者能够训练不同的适配器用于不同的控制条件,包括空间颜色控制,和更加精细的结构控制。
- 组合性。不止一个的适配器能够组合起来获得更多条件的控制;
- 泛化性。一旦被训练好,他们能够直接用于微调的SD模型。
二、相关工作
1.图像合成与转换
这种高维的结构化的特点给自然图像生成带来了挑战。生产对抗网络GAN允许有效的采用在随机分布中,并取得了不错的合成质量。一些其他方法比如可变的自编码器也被提出来用于构建一个更加稳定的优化过程。这些早期的工作通常执行一个不可控的图像合成。不同于不可控的图像合成,一些有条件的策略被提出来。常用的情况是在另一个域如草稿,语义分割图和关键点姿态。几个有条件的GAN方法【16,24】被提出用于转换其他域的条件图到自然图像。除了图像控制的情况外,文本是另外一个重要的情况,它用于给出文本描述下生成图像。多数这类方法对待不同的情况是单独训练的。最近的一些尝试【15】在探索多模态情况下的图像合成。
2 扩散模型
近些年,扩散模型在图像合成中取得了非凡的成就。它用于从高斯噪声中生成图像,通过一个迭代的去噪过程。它的实现是基于严格的物理用法,包括一个扩散过程和一个相反的过程。在扩散过程,一个图像X0被转换为一个高斯分布X_T,通过在T次迭代内添加随机的高斯噪声。反向过程是从X_T中复原X0通过不断去噪步骤。
最近的扩散方法关注在文本到图像的生成任务。例如,Glide方法提出在去噪过程中结合文本特征到transformer块。后来,DALLE,Cogview, Make-a-scene,SD和Imagen等快速地提升了T2I的生成能力。这些快速传播的策略在特征空间执行去噪过程通过交叉注意力模型。尽管他们获得了不错的生成质量,文本提示不能提供可信结构的合成结果。PITI【43】提出提供结构化的指引通过关闭其他条件与文本条件之间的特征之间的距离。方法【42】提出采用目标手稿与中间结果的相似梯度来越苏最终结果的结构。一些其他方法也尝试调制交叉注意力图区指导生成过程。这类方法的好处是他们不需要额外的单独数据。但是他们在复杂场景仍然不实用。后来的工作【45】尝试学习特定任务的ControlNet来实现有条件下的合成。方法【14】就是采用一组可控条件下来重新训练扩散模型。
3 适配器
适配器的概率源自NLP。适配器【13】发现微调一个大的预训练模型用于每个下游任务是不高效的,提出使用适配器来转换。适配器是一个紧凑的可扩展的模型。方法【40】探讨多任务的方法通过共享一个简单的BERT模型,带有少量的额外的特定任务参数。在CV领域,方法【20】提出微调ViT在最小改动下用于目标检测。最近,ViT-Adapter采用适配器使得一个原始的ViT能够执行不同的下游任务。但是,在预训练的T2I模型上使用低成本的适配器,仍然是一个开放的问题。
三、T2I适配器
总结
作者迈出的这一步,对于玩SD的人来说是一个锦上添花的过程。我们知道SD非常强大,但是要生成满意的图像,需要良好的文字提示。但是文字提示也是一个有技巧的工程。作者提出的T2I适配器,能够减少对文字提示的依赖,获得更想要的图像生成效果。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- unity shaderGraph实例-武器特效(纹理遮罩,纹理动画,纹理变形)
- 【windows】右键添加git bash here菜单
- 【Python可视化实战】钻石数据可视化
- Python学习从0到1 day3 python变量和debug
- 启动docker报错解决方法:Job for docker.service failed because start of the service was attempted too often.
- 最大流—EK算法,流网络,残留网络,定理证明,详细代码
- Web08--JavaScript高级
- 操作系统复习 五、六章
- 亚马逊店铺注册步骤,亚马逊多店铺,店群模式需要扣店租怎么办?
- 我们是如何测试人工智能的(三)数据构造与性能测试篇