经典论文之(二)——Resnet
论文简介
《Deep Residual Learning for Image Recognition》——用于图像识别的深度残差学习是由何凯明团队提出的,在当时获得分类任务,目标检测,图像分割第一名。该论文的四位作者何恺明、张祥雨、任少卿和孙剑如今在人工智能领域里都是响当当的名字。在本文中,提出的残差网络框架对后世影响深远。在本文做出的实验中,结果表明残差网络更容易优化,并且加深网络层数有助于提高正确率。
在ImageNet数据集上,评估了深度高达152层的残差网——比VGG网深8倍[40],但仍然具有较低的复杂性。这些残差网的集合在ImageNet测试集上实现了3.57%的误差。这一结果在ILSVRC 2015分类任务中获得了第一名。
背景
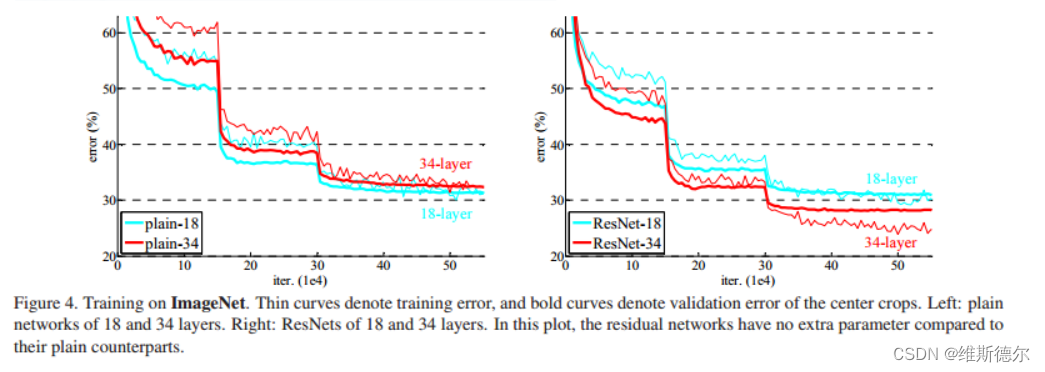
在之前图形分类方面,都在追寻网络的深度,都在通过加深网络的层数来提高模型的效率。但这也面临着一个问题,是网络的深度越深模型的效率越好吗?其实不然,学习更好的网络并不等同于堆叠更多的层数。当更深层次的网络能够开始收敛时,就会暴露出一个退化的问题:随着网络深度的增加,精度就会饱和,然后迅速退化。就像下图中给出的例子,随着网络深度的增加并不一定会使网络变得更好。

在本文中,通过引入深度残差学习框架来解决退化问题。
Deep Residual Learning
Residual Learning–残差学习
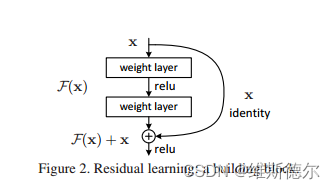
在本文中,我们通过引入深度残差学习框架来解决退化问题。我们不希望每个堆叠的层直接适合所需的底层映射,而是明确地让这些层适合残差映射。形式上,将所需的底层映射表示为H(x),我们让堆叠的非线性层拟合F(x)的另一个映射:=H(x,x)。原始映射被重新转换为F(x)+x。我们假设优化残差映射比优化原始的未引用映射更容易。在极端情况下,如果单位映射是最优的,那么将残差推至零比通过一堆非线性层拟合单位映射更容易。
Network Architectures–网络体系结构
本文测试了各种plain/residual的网络,并观察了一致的现象。
残差网络。基于上述普通网络,我们插入快捷连接(图3,右),将网络转换为其对应的残差版本。当输入和输出具有相同尺寸时,可以直接使用身份快捷方式(等式(1))(图3中的实线快捷方式)。当维度增加时(图3中的虚线快捷方式),我们考虑两个选项:(A)快捷方式仍然执行身份映射,为增加维度填充额外的零条目。此选项不引入额外的参数;(B) 方程中的投影快捷方式。(2) 用于匹配维度(通过1×1卷积完成)。对于这两个选项,当快捷方式跨越两种大小的要素图时,它们将以2的步幅执行
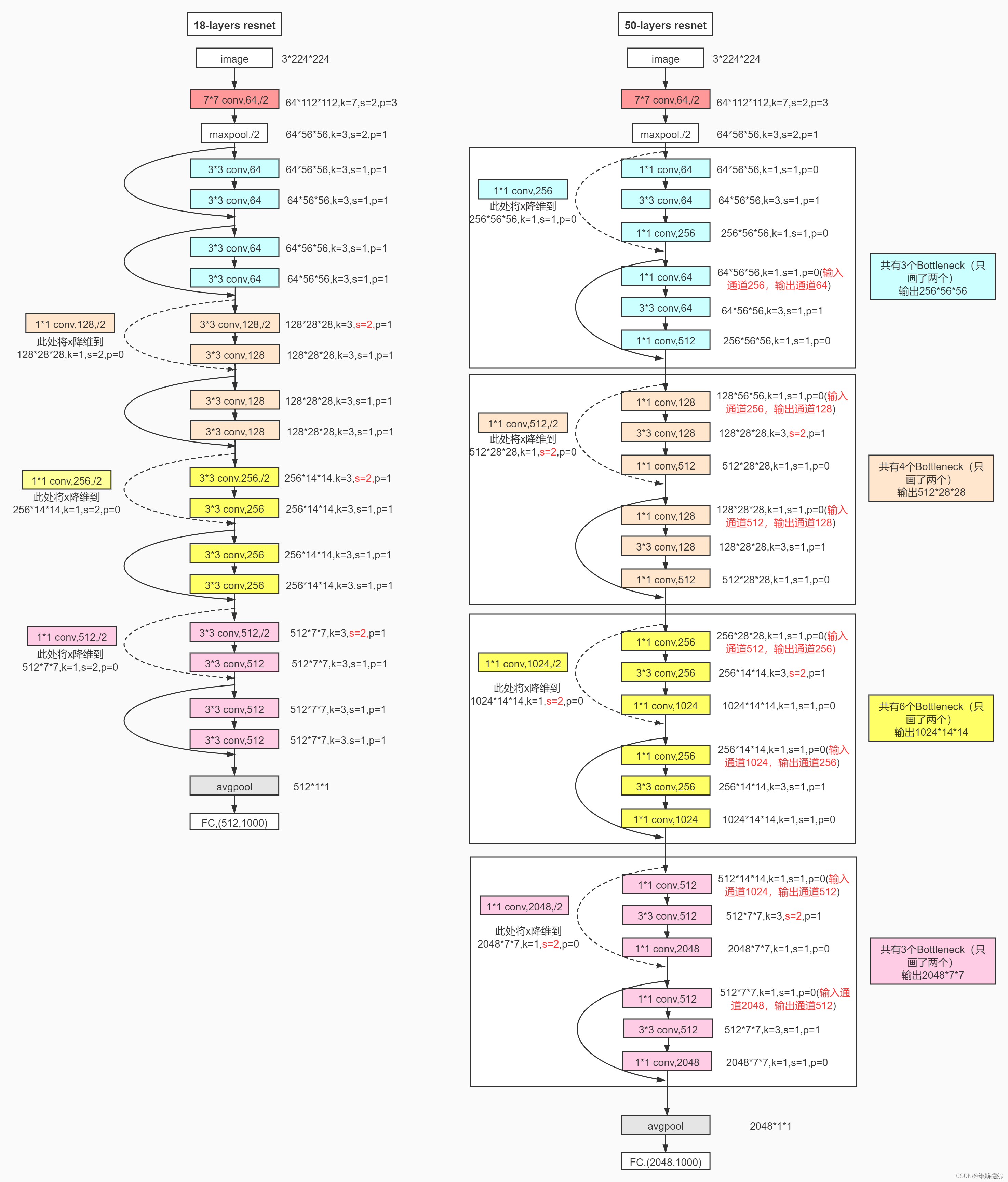
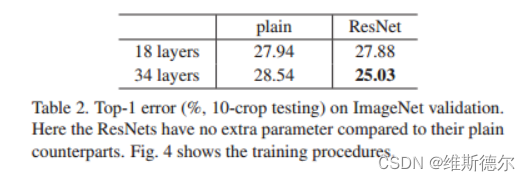
不同层的Resnet的分类
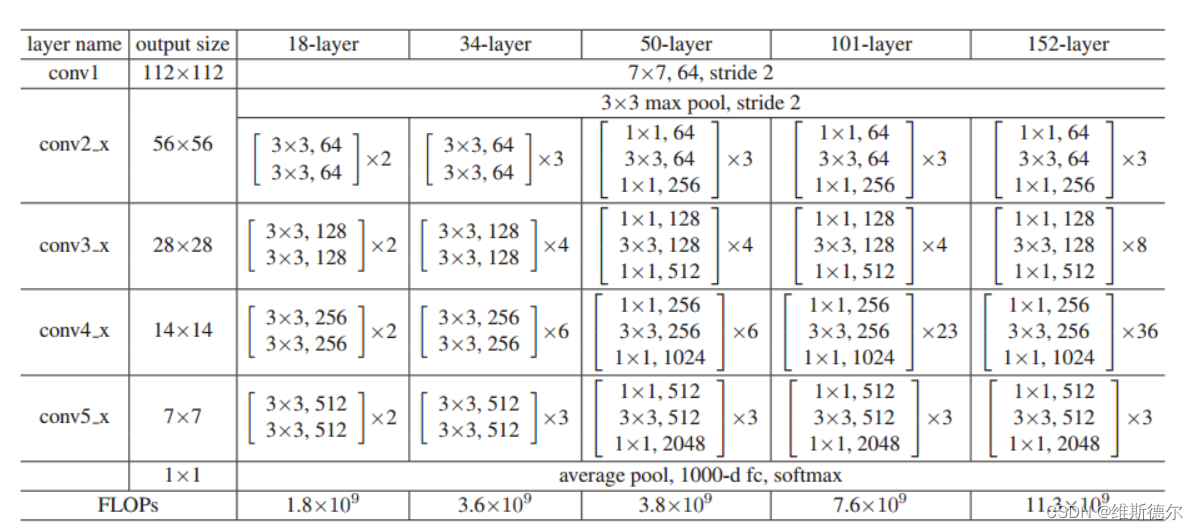
ImageNet的体系结构。构建块显示在括号中(另见图5),块的数量堆叠在一起。下采样由conv3 1、conv4 1和conv5 1执行,步长为2。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!