【MS-CLIP】共享参数的ModalityShared CLIP (MS-CLIP) 架构
MS-CLIP
Paper : Learning Visual Representation from Modality-Shared Contrastive Language-Image Pre-training
Author : Haoxuan You , Luowei Zhou , Bin Xiao , Noel Codella , Yu Cheng , Ruochen Xu , Shih-Fu Chang , and Lu Yuan
Affiliation : Columbia University, Microsoft Cloud and AI, Microsoft Research(微软)
Publication : ECCV-2022
Code : https://github.com/Hxyou/MSCLIP
前景
目前的多模态算法,大多都采用两种方法,做模态交互:要么是两个模态使用独立的 transformer encoder,在编码后进行对比学习(比如 CLIP);要么直接将两个模态拼接后灌入一个融合 transformer 里(比如 ViLBERT)。
而微软最新发布的 MS-CLIP,与两者都不同 —— 虽然它脱胎于 CLIP,设计了只处理单模态的 transformer encoder,但两个 encoder 之间是共享部分参数的。同时,它还为模型添加了基于 CNN 的两种辅助结构,让模型能够获取更多的图像信息。
在这样的优化下,MS-CLIP 模态间的交互比 CLIP 更加显著,在视觉相关的任务中,也取得了更优异的性能。
1.1 动机
对比语言图像预训练(CLIP)最近在计算机视觉和自然语言处理领域引起了广泛关注,利用大规模图像描述数据通过对比损失从语言监督中学习通用视觉表示。这允许学习开放集视觉概念,并使学习到的特征具有转移到不同视觉任务的强大能力。利用大规模图像描述数据通过对比损失从语言监督中学习通用视觉表示。这允许学习开放集视觉概念,并使学习到的特征具有转移到不同视觉任务的强大能力。
这个领域先前的工作通常采用单独的语言和图像编码器,但是这两种模式的编码器之间的架构相似。例如,最初的 CLIP 工作使用基于 ViT的图像编码器和基于独立 Transformer 的语言编码器。然而,最近发现,在语言数据上预先训练的 Transformer 模型可以很好地推广到视觉任务,而无需改变大多数参数,这表明一种模态学习的模式可以转移到另一种模态。这些观察结果表明,CLIP 的统一编码器很有可能促进学习跨模态的一般有用表示,以实现性能和效率的提升。
因此,在本文中,作者研究了构建 ModalityShared CLIP (MS-CLIP) 架构的可行性,其中视觉编码器和文本编码器中的参数可以共享。通过这个框架,作者寻求以下三个问题的答案:
(i)在每一层中,哪些子模块应该共享,哪些不应该共享?
(ii) 在 CLIP 训练环境中,两种模态的编码器的哪些层应该共享,哪些层应该是特定于模态的?
(iii) 最后,当包含轻量级特定于模态的辅助模块以适应每种模态的专业化时,对性能和效率有什么影响?
为了回答这些问题,作者对不同层之间不同的组件共享程度的影响进行了全面的分析。作者的结果表明,为了最大限度地提高性能,输入嵌入、层归一化 (LN) 和输出投影应该是特定于模态的。相比之下,所有其余组件都可以在视觉和文本转换器之间共享,包括自注意力和前馈模块中的权重。此外,共享所有Transformer层甚至优于更复杂的策略,在这些策略中,作者采用贪婪的层选择或使用神经架构搜索(NAS)来搜索最佳层共享策略。
最后,作者探讨将轻量级特定于模态的组件引入共享主干是否可以在跨模态建模和每种模态的专业化之间产生更好的平衡。研究的设计包括:
(i)早期专业化:第一个 Transformer 块分别被专门针对每种模态的模块所取代。这包括一组用于视觉的轻量级级联的残差卷积神经网络 (CNN) 和一个用于语言的 Transformer 层。这种早期的适应允许每种模态的表示在统一编码之前抽象到更高的水平,并在视觉分支的早期引入移位不变性。
(ii) 高效并行分支:对于视觉模态,作者探索了一个轻量级多尺度 CNN 网络,与主模态共享分支并行,并通过深度卷积适配器将其多尺度特征合并到主分支中。这个并行分支能够利用卷积从更好的空间关系建模中获得的好处来增强主分支。
作者在 YFCC100M 和具有相似大小的 Laion-400M子集上预训练 MS-CLIP 架构,并对涵盖各种视觉任务的 25 个下游数据集进行评估。实验结果表明,MS-CLIP 架构虽然参数较少,但在大多数任务上都可以优于原始 CLIP,包括零样本识别、零样本检索和线性探测。此外,为了更好地理解为什么MS-CLIP架构如此有效,作者对学习嵌入空间进行了研究,即对多模态特征融合程度的测量,并定量评估了语义结构(如注意力模式)在模态间共享的程度。作者的研究结果表明,共享参数可以将不同模态的语义相似概念拉得更近,并促进共同语义结构(如注意力模式)的学习。
1.2 相关工作
1.2.1 从文本中学习视觉表示
作者的工作建立在最近从文本监督中学习视觉表示的成功基础上。 VirTex提出通过图像字幕目标来学习视觉编码。 LocTex 引入本地化文本监督来指导视觉表示学习。
这两项研究的规模都相对较小。最近的工作,如 CLIP 和 ALIGN 表明,通用多模态预训练可以受益于超大规模训练(即具有数亿或数十亿数据对的私有数据集),并获得强大的零样本迁移能力。他们采用简单而有效的对比目标,吸引配对的图像和标题并排斥不配对的图像和标题。继 CLIP/ALIGN 之后,还有一些其他的工作。 Florence 和 BASIC扩展了数据集并使用各种主干进行训练。 FILIP 专注于将对比损失推广到本地tokens以进行细粒度的监督。 DeCLIP 、SLIP和其他最近的作品从自监督、多视图监督、最近邻监督、对象检测 或外部语言知识 扩展了监督信号。与上述工作正交,这项工作的重点是在大规模对比预训练中跨视觉和文本模式共享权重。
1.2.2 视觉和语言建模
另一个类似的工作是视觉和语言预训练(或 VLP),在这其中视觉和语言信号被输入到一个统一的模型中,以实现下游的多模式任务。此外,利用一组跨不同模态的共享tokens来实现多模态融合。但 VLP 和这项工作之间有两个主要区别:首先,在 VLP 方法中,模型输入同时包含图像和文本模态,模型同时关注两种模态(本质上是进行模态融合)。在 CLIP 和 MS-CLIP 中,Transformer 的输入要么是图像,要么是单独的文本:每种模态都是单独处理的,两种模态永远不会同时处理(除了最后计算对比损失)。
其次,VLP的工作重点是设计统一的融合模块以很好地融合多模态输入并针对多模态任务(例如VQA、接地),而作者工作的目标是允许单模态输入的参数和知识共享,并且主要服务于仅视觉的下游任务。
1.2.3 跨模态参数共享
随着人类同时对各种模态进行推理,多模态处理的共享模块最近引起了研究界越来越多的兴趣。有人建议跨层和模态共享 Transformer 的参数以保存参数。他们专注于视频音频多模态下游任务,并有一个额外的多模态 Transformer 用于模态融合。有人建议在 12 个视觉语言数据集上训练一个完全共享的多模态 Transformer。 有人进一步介绍了用于多任务多模态学习的共享 Transformer 解码器。与作者最相关的工作是 VATT 。 VATT 引入了一种与模态无关的Transformer,可以处理视频、文本和音频输入,并在对比目标上进行了预训练。但是提出的模型天真地重用了所有模态的整个网络,产生的结果比非共享模型更差。相比之下,作者工作研究的不仅仅是模型是否可以共享,而是不同程度的共享和设计细微差别的行为方式,以及哪些设计选择可能有助于提高性能。
2 方法
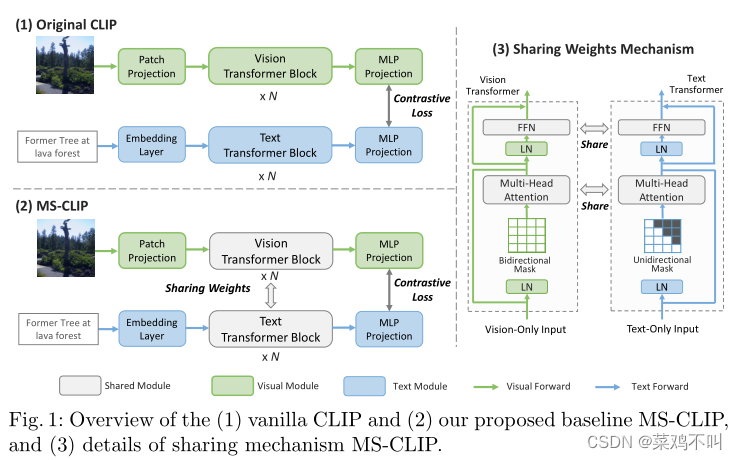
2.1 可共享模块
作者使用Vision Transformer作为基本视觉编码器(默认为ViTB/32),并使用Transformer编码器作为基本文本编码器,如图1-1所示。挑战在于合并这两种架构。为了实现这一点,作者将文本转换器的隐藏维度从 512 调整为 768,以匹配视觉转换器中的隐藏维度。由此产生的附加基线方法被标记为 CLIP (ViT-B/32, T768)。调整后,最终的共享编码器使用 12 层,绝大多数参数能够在两种模态之间共享,包括注意力模块、前馈模块和 LayerNorm (LN) 层。无法共享的模块包括输入嵌入层(其中视觉编码器部署投影层来嵌入图像patches,而文本编码器对单词tokens进行编码)和输出投影层。
作者进行了一项实验分析,以检查跨模态不同程度的权重共享的影响。总而言之,该研究的观察结果如下
1)逻辑网络需要是特定于模态的,而其余的可以是模态共享的;
2)共享所有层优于共享子集。
随后,共享注意力和前馈模块,同时在所有 12 层中保持 LN 模态特定的模型被视为作者模型系列的基线。作者将这种 Naìve 模态共享模型称为 MS-CLIP(见图 1-2 和 1-3)。
2.2 特定于模态的辅助模块架构
在本节中,作者描述了引入两个轻量级特定于模态的辅助模块的修改,如图 2 所示。作者将具有两种特定于模态的设计的完整模型命名为 MS-CLIP-S,其中“S”表示“专用分支”。
2.2.1 早期专业化
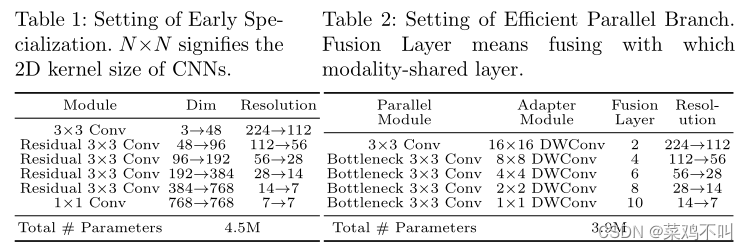
第一个特定于模态的设计仅第一层对于视觉和文本模态专用,而其他层则共享。具体来说,在视觉方面,作者采用一系列具有残差连接的卷积网络作为作者的专业化层,其中特征分辨率被下采样并增加通道维度。详细配置如表 1 所示。 以ViT-B/32作为视觉编码器,对于其他视觉编码器,例如 ViT-B/16,配置仅在卷积步长上有所不同。作者进一步在卷积层之间添加残差连接,这对于大规模训练来说在经验上更加稳定。在语言方面,作者重用实际上的 Transformer 层进行语言建模。
2.2.2 高效并行分支
对于图像表示,多尺度信息已被证明是有价值的。然而, Vision Transformers 通常按固定尺度运作。在最近将多尺度信息引入ViT的工作中,补丁大小逐渐减小,通道的维度逐步增加。然而,由于通道维度的差异,在多尺度 ViT 和语言 Transformer 之间直接共享权重并非易事。作者建议在共享 Transformer 旁边设置一个辅助并行视觉分支,该分支由一个卷积层和四个残差卷积层组成,以降低分辨率并增加通道维度(见图 2)。与 Early Specialization 中的普通残差卷积相比,这里作者利用 ResNet 中的瓶颈设计来提高参数效率。**并行分支的主要作用是为共享分支补充图像信息的多尺度特征。**因此,作者在每个并行层之后使用一个适配器,将不同尺度的特征集成到共享 Transformer 的各层中。为了进一步提高效率,作者在适配器中采用深度卷积(DWConv)和逐点卷积(PWConv)来调整特征图大小和深度。adapter可以表示为:
H
P
‘
=
b
n
(
P
W
C
o
n
v
(
D
W
C
o
n
v
(
H
p
)
)
)
(
1
)
H
‘
=
l
n
(
b
n
(
D
W
C
o
n
v
(
H
)
)
+
H
p
‘
)
H_P^`=bn(PWConv(DWConv(H_p)))\quad (1)\\ H^`=ln(bn(DWConv(H))+H_p^`)\quad \quad
HP‘?=bn(PWConv(DWConv(Hp?)))(1)H‘=ln(bn(DWConv(H))+Hp‘?)
其中Hp是并行分支中的多尺度特征,(H,H′)分别是适配器的输入和输出。 bn 和 ln 表示批量归一化和层归一化。请注意,CLS token未与并行分支融合,并且保持不变。 5 个并行层的输出与其他所有共享 Transformer 层融合。 ViT-B/32 作为视觉编码器时的详细配置如表 1 所示。 对于其他视觉编码器,例如ViT-B/16,只有内核大小和步幅不同,作者在补充中附上配置。
3 实验
3.1 设置
3.1.1 训练细节
与原始 CLIP 论文 类似,作者为图像和文本保持单独的注意力mask:视觉转换器允许上层使用双向蒙版关注下层的所有token,而文本转换器中的蒙版是自回归的。优化器是 AdamW。学习率从 1.6e-3 衰减到 1.6e-4,使用余弦调度器并在前 5 个 epoch 进行预热。作者在 16 个 NVIDIA V100 GPU 上训练模型,每个 GPU 的批量大小设置为 256。对于 MS-CLIP 和 MS-CLIP-S,非共享参数和共享参数的权重衰减分别设置为 0.05 和 0.2。作者发现共享参数的较高权重衰减效果更好,因为共享参数在每次迭代中更新两次,并且较高的权重衰减可以减轻过度拟合。
3.1.2 预训练数据集
默认情况下,作者使用YFCC100M进行预训练。过滤过程,作者只保留标题为英文的图像文本对。这给作者留下了大约 2200 万个数据对。作者所有的结果都在此数据版本上报告,包括普通 CLIP 。随后,作者还在最新数据集的子集上对作者的模型和普通 CLIP 进行了预训练:LAION-400M。
3.1.3 评估数据集
作者总共采用 25 个公共数据集通过零样本学习或线性探测进行评估:ImageNet 、Food-101、CIF AR10 、CIF AR-100 、SUN397 、、、、。这些数据集涵盖各种类别,包括通用对象、场景等。作者在提取的图像特征之上使用逻辑回归进行线性探测,完全遵循原始 CLIP 论文中的方法。对于零样本识别,作者报告 ImageNet 验证集上的零样本精度。按照 CLIP,作者使用多个提示的集合来提取文本特征作为类别特征。对于零样本图像文本检索,作者在 MSCOCO 上报告了召回率。
3.2 实验结果
3.2.1 比较模型
作者对提出的 MS-CLIP-S 和 vanilla CLIP 进行了实验。采用ViT-B/32和ViT-B/16作为视觉编码器。
3.2.2 零样本 ImageNet 分类
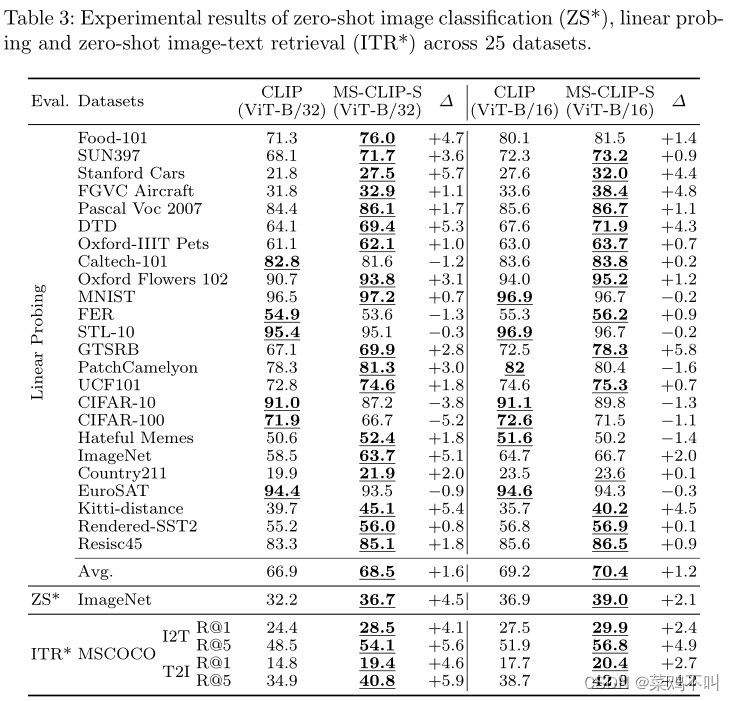
实验结果报告在表 3 中的 ZS* 行中。 通过比较四列,作者发现,基于ViT-B/32(ViT-B/16),MS-CLIP-S可以比CLIP高出4.5(2.1)个百分点,即13.9%(5.6%)相对而言,ImageNet 上的零样本识别精度。
3.2.3 线性探测
为了将作者的模型与普通 CLIP 进行全面比较,表 3 中显示了 24 个不同数据集上的线性探测结果。 总体而言,ViT-B/32 (ViT-B/16) 作为骨干,MS-CLIP-S 在 24 项任务中的 18 (17) 项上优于普通 CLIP,24 项任务的平均改进为 1.62 (1.16) 分。
3.2.4 零样本图像文本检索
作者在两个子任务上评估 MS-CLIP-S:零样本设置下的图像到文本检索和文本到图像检索。作者使用的数据集是 MSCOCO 测试集,其中有 5,000 张图像。表 3 的最后 4 行显示了 MS-CLIP-S 和 vanilla CLIP 之间的比较,两者都在 YFCC 上进行了预训练。 3. 对于 ViT-B/32 和 ViT-B/16,作者的 MS-CLIP-S 的性能全面优于普通 CLIP。
3.3 消融实验
对于以下消融分析,作者使用 ViT-B/32,并在 ImageNet 验证集上报告零样本精度。
3.3.1 关于模态共享组件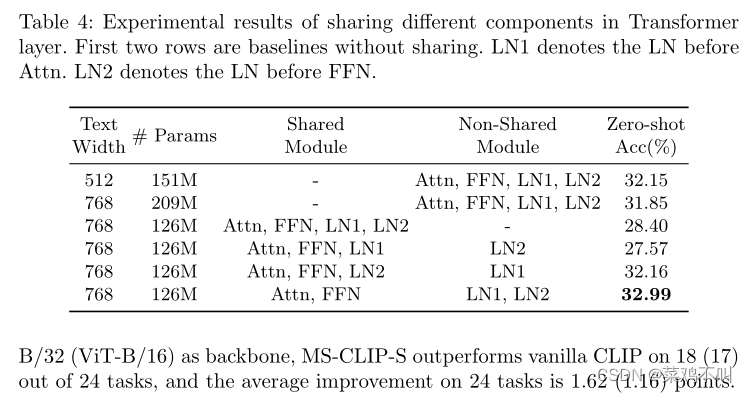
作者系统地研究了不同层之间不同的组件共享程度的影响,并做出以下观察:
- LN 需要特定于模态。作者检查每个 Transformer 层内的可共享模块,不包括无法共享的输入和输出投影层。如表4所示。第一个模型变体共享所有组件(为了简单起见,跨所有层),包括两个 LN 层以及自注意力和前馈模块中的转换权重,与 CLIP(ViT-B/ 32) (32.15%) 和 CLIP (ViT-B/32, T768)(31.85%)。然后作者研究使两个 LN 层特定于模态,这在零样本精度 (32.99%) 和参数效率方面产生了更好的性能。请注意,与变换权重相比,逻辑网络中的参数数量可以忽略不计。作者的观察结果与 FPT 中的发现相呼应,即只有在大部分冻结的预训练语言模型中调整 LN 才能在视觉任务上产生令人满意的性能。
- 少即是多:共享所有层比共享一些层更好。作者进一步研究哪一层应该是特定于模态的,哪一层应该是模态共享的。作者对共享最后 N 层进行了实验,其中 N 的范围从 12 到 0。N = 12 表示所有层都是共享的,N = 0 表示非共享基线 CLIP(ViT-B/32,T768)。表 5 表明共享所有 12 层性能最佳,同时需要的参数数量最少。这种共享所有层的设计就是作者所说的MS-CLIP。此外,受到最近神经架构搜索(NAS)工作的启发,作者训练了一个模型,该模型学习通过 Gumbel Softmax 控制哪一层共享(不共享)的策略。尽管它很复杂,但它的性能仍然低于 MS-CLIP。
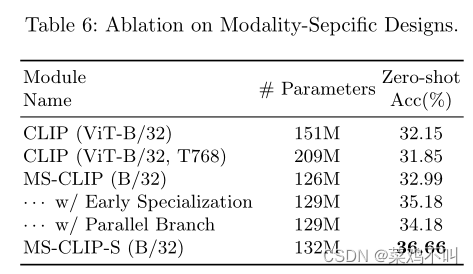
作者使用以下设置进行实验:
(1)CLIP(ViT-B/32):使用ViT-B/32作为视觉编码器,并将Text Transformer宽度设置为 512.
(2)CLIP (ViTB/32, T768):该模型将 Text Transformer 的宽度设置为 768,以统一两个编码器的尺寸。
(3)MS-CLIP(B/32):与CLIP(ViT-B/32,T768)相比,该模型利用模态共享Transformer块来替代视觉和文本编码器中的非共享Transformer块。作者使用最佳设置,共享除两层归一化之外的所有内容。
(4) MS-CLIP (B/32) + 早期专业化:基于 (3),作者专业化第 2 节之后的第一层共享视觉和文本编码器。
(5)MS-CLIP(B/32)+并行分支:在(3)的基础上,作者为共享视觉编码器添加并行分支。
(6) MS-CLIP-S (B/32):基于(3),作者将早期专业化和并行分支应用于作者共享的视觉和文本编码器。
结果总结在表6中。通过比较第2行和第3行,作者发现直接增加文本转换器的容量会产生更差的结果。然后比较第 3 行和第 4 行,作者发现视觉和文本转换器中共享参数提高了性能,甚至可以超越 CLIP (ViT-B/32)(如之前对模态共享模块的消融所示)。将第 4 行和第 5 行与第 1 行进行比较,作者注意到早期专业化仅增加 4M 参数就可以带来 2.1% 的提升,并且视觉上的辅助并行分支有 1.1% 的提升。第 6 行的完整模型进一步提升至 36.66%,比基线 CLIP (ViT-B/32) 绝对增益 4.5%。
3.4 预训练数据质量
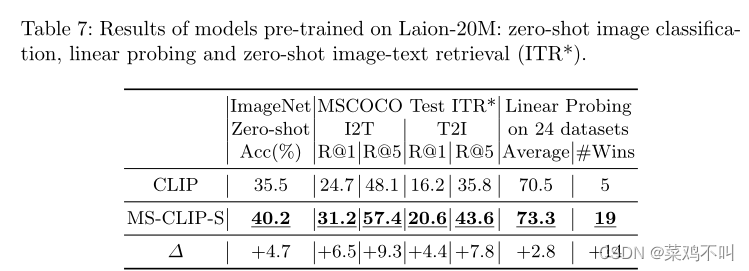
为了验证作者提出的模型可以推广到各种质量的预训练数据集,作者基于公共 Laion-400M 数据集的子集预训练了 vanilla CLIP (ViT-B/32) 和 MS-CLIP-S(ViT-B/32)。该概念验证子集包含来自 Laion-400M 的 20M 个随机采样的图像标题对,类似于过滤后的 YFCC 的大小。作者将其命名为 Laion20M。
完整的实验结果如表7所示。 作者的模型大大优于普通 CLIP。由于在Laion-400M的构建中,使用预训练的CLIP来过滤掉噪声图像文本对,因此该数据集被认为具有更高的数据质量。这也可以通过比较 vanilla CLIP 在 Laion 和 YFCC 中的结果来证明。通过同时比较表3和表7,作者发现在 Laion-20M 上预训练的 MS-CLIP-S 带来的改进通常高于 YFCC (22M)。这可能意味着当预训练数据质量更高时,作者的方法可以受益更多。
3.5 更深入的分析
可能有多种原因可以解释所观察到的性能改进。首先,共享视觉和语言的大部分参数可以隐式地鼓励模型关注两种模态的共同模式,并减轻琐碎视觉(例如照明)或语言提示(例如停用词)的过度拟合。此外,辅助模态特定模块、早期专业化和并行分支提供视觉特定的多尺度特征和特定于语言的功能来补充共享模块。为了更深入的了解,作者进行以下进一步分析:
3.5.1 NMI评分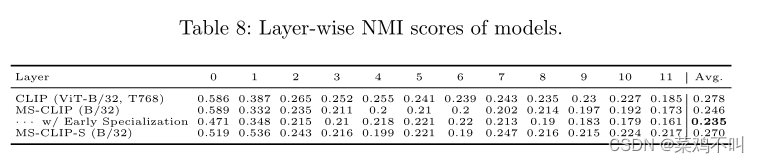
共享模型表现出更高的多模态融合程度。为了探讨多模态融合程度,作者测量每一层视觉特征和文本特征之间的归一化互信息(NMI)。对于每个图像标题对,作者使用 K-means 算法 (K=2) 将来自视觉输入和文本输入的前向传递的所有特征向量分组为 2 个簇。
然后,应用 NMI 来测量生成的聚类与真实聚类之间的差异。 NMI得分越高,视觉特征和文本特征越容易分离,多模态融合程度越低。
然后使用 NMI 分数来探测共享模型 (MS-CLIP (B/32)) 与非共享模型 (CLIP (ViT-B/32, T768)) 的多模态融合程度。这里作者选择 CLIP (ViT-B/32, T768) 而不是 CLIP (ViT-B/32),因为两种模态的特征维度必须相同才能进行聚类。该测量是在 YFCC100M 数据集中随机采样的 50k 个图像标题对上进行的。表8的前两行列出了所有 12 层的 NMI 分数和平均值。 共享模型在几乎所有层和平均值上的 NMI 得分均低于原始 CLIP,表明多模态融合程度更高。
按照与上述相同的程序,作者进一步报告 MS-CLIP (B/32) + Early Specialization 和 MS-CLIP-S (B/32) 的 NMI 分数(见表 8)。
结果表明,共享参数和引入早期专业化可以提高多模态融合程度,这与作者上面提到的假设相符。然而,添加并行分支会导致融合分数较低。
这与作者在 Tab 6中看到的有些冲突。 其中添加并行分支增强了学习到的表示。在下面的小节中,作者将探讨其他指标,以进一步探讨造成这种行为的因素。
3.5.2 多模态通用语义结构
模态共享模块和模态特定模块的集成可以学习更好的通用模式。其中一个假说是MS-CLIP 架构表现更好的原因在于它们能够更好地捕获不同模态概念固有的常见语义结构。
为了证明这一假设的合理性,作者提案测量视觉概念和相应语言概念的注意力权重之间的相似性(见图 3)。该测量是在名为 Flick30K-Entities 的代理数据集上执行的,其中每个图像中的对象区域都以边界框的形式扎根于标题中相应的短语。给定图像,假设存在对应对象区域(视觉概念)
{
v
c
1
,
v
c
2
,
.
.
.
,
v
c
n
}
\{vc_1,vc_2,...,vc_n\}
{vc1?,vc2?,...,vcn?}和真实的对象词(语言概念)
{
t
c
1
,
t
c
2
,
.
.
.
,
t
c
n
}
\{tc_1,tc_2,...,tc_n\}
{tc1?,tc2?,...,tcn?},其中
t
c
i
tc_i
tci?与
v
c
i
vc_i
vci? 语义上联系。在第 l 个注意力层的第 h 个头中,作者将原始视觉注意力矩阵表示为$ M^{ lh}$,将原始文本注意力矩阵表示为
K
l
h
K^{lh}
Klh。然后,作者将
t
c
i
tc_i
tci? 和
t
c
j
tc_j
tcj? 之间的注意力值视为
K
i
j
l
h
K^{lh}_{ij}
Kijlh? ,将
v
c
i
vc_i
vci? 和
v
c
j
vc_j
vcj? 之间的注意力值视为
M
i
j
l
h
M ^{lh}_{ij}
Mijlh? 。作者将注意力值从概念 i 提取到所有其他概念(即 j),并分别对视觉注意力和语言注意力进行归一化(表示为“注意力向量”)。最终的注意力向量是该注意力层中所有头的平均。作者计算所有概念对 i 的注意力向量。最后,作者测量视觉注意向量和语言注意向量之间的 l1 距离,并将它们在所有概念对上求和,并将其视为该注意层的通用语义结构(CSC)距离。 CSC 距离越短意味着跨模式学到更多常见的注意力模式。整个过程可以表述为:
d
i
s
i
j
t
=
∣
∑
H
h
=
1
1
H
s
o
f
t
m
a
x
i
(
M
i
j
l
h
)
?
∑
H
h
=
1
1
H
s
o
f
t
m
a
x
i
(
K
i
j
l
h
)
∣
(
2
)
C
S
C
l
=
d
i
s
l
=
∑
n
i
=
1
∑
n
j
=
1
(
d
i
s
i
j
l
)
(
3
)
dis_{ij}^t=|\underset{h=1}{\overset{H}\sum}\frac{1}{H}softmax_i(M ^{lh}_{ij})- \underset{h=1}{\overset{H}\sum}\frac{1}{H}softmax_i(K ^{lh}_{ij})|\quad (2) \\ CSC^l=dis^l=\underset{i=1}{\overset{n}\sum}\underset{j=1}{\overset{n}\sum}(dis^l_{ij})\quad (3)
disijt?=∣h=1∑H??H1?softmaxi?(Mijlh?)?h=1∑H??H1?softmaxi?(Kijlh?)∣(2)CSCl=disl=i=1∑n??j=1∑n??(disijl?)(3)
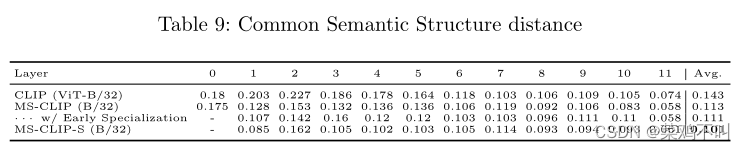
表 9 中报告了 CLIP (ViT-B/32)、MS-CLIP (B/32)、MSCLIP (B/32) + Early Specialization 和 MS-CLIP-S (B/32) 的逐层 CSC 距离。 MS-CLIP (B/32) + Early Specialization 和 MSCLIP-S (B/32) 的第一层被省略,因为它们的视觉分支不包含任何注意力权重。平均分数是根据最后 11 层的 CSC 距离计算的。作者发现作者提出的模块降低了 CSC 距离并学习更多与模态无关的表示。毫不奇怪,共享参数可以增强注意力以学习更多常见信息。同时,可能会减少单独训练带来的过拟合。至于作者提出的特定于模态的模块,作者怀疑这些精心设计的模块可以解释各个模态的差异,特别是通过特定于视觉的多尺度特征,从而促进共享组件的共同模式的学习。
3.5.3 共享注意力头的可视化
为了直观地理解共享注意力模块的工作原理,作者在推理过程中可视化同一共享注意力头的视觉注意力模式和文本注意力模式。更准确地说,对于视觉,作者可视化最后一层从 CLS token到其所有输入token的注意力权重。对于文本,作者执行相同的操作(除了 EOS token)。请注意,CLS 代币和 EOS 代币都被视为特征表示。 MS-CLIP-S (B/32) 的结果如图 4 所示。有趣的是,一些头能够从不同的模式关注相同的概念。
作者以图4(a)为例。分别将图像和标题作为输入,第 9 个注意力层的第 1 个头对图像中的“cat”区域和文本中的token“cats”给予最高的注意力值。它表现了学习跨模态的共指。
5 结论
作者提出了 MS-CLIP,一种模态共享的对比语言图像预训练方法,其中视觉和文本编码器中的大多数参数是共享的。为了探索有多少参数/层可以跨模式共享,作者通过广泛的实验仔细研究了各种架构设计选择。
此外,作者提出了两种特定于模态的辅助设计:早期专业化和辅助并行分支。零样本识别和线性探测的实验证明了 MS-CLIP 架构在有效性和参数效率方面优于普通 CLIP。最后,对所提出的架构的进一步分析表明,共享参数可以帮助将两种模态映射到更紧密的嵌入空间中,并促进学习共同的语义结构。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- EasyCode代码生成器插件
- 天津医科大学临床医学院专升本护理学专业护理学基础考试大纲
- Python---搭建Python自带静态Web服务器
- 论文阅读<CF-YOLO: Cross Fusion YOLO for Object Detection in Adverse Weather.....>
- 金和OA jc6 Upload 任意文件上传漏洞复现
- 微信小程序页面传值的几种方式
- 分享一些实用工具和学习网站
- STL--stack、queue实现
- leetCode-42.接雨水
- 让大模型忘掉隐私数据,卡内基开源TOFU