模型创建与nn.Module
发布时间:2024年01月08日
一、网络模型创建步骤

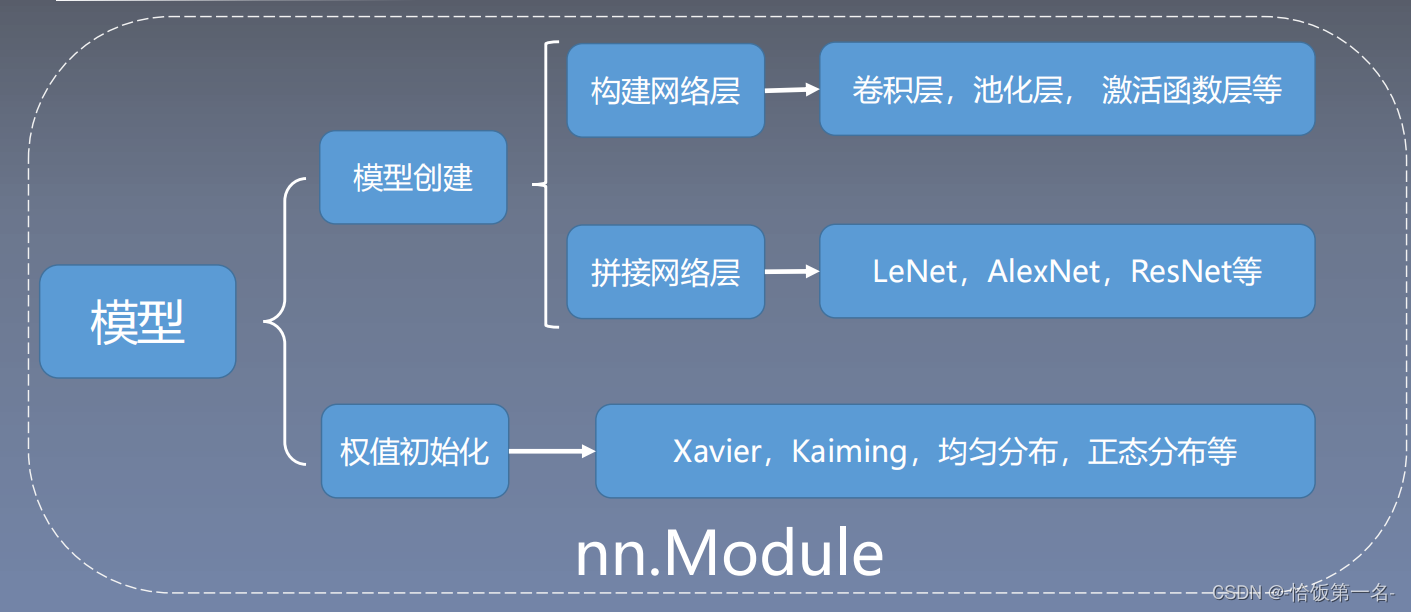
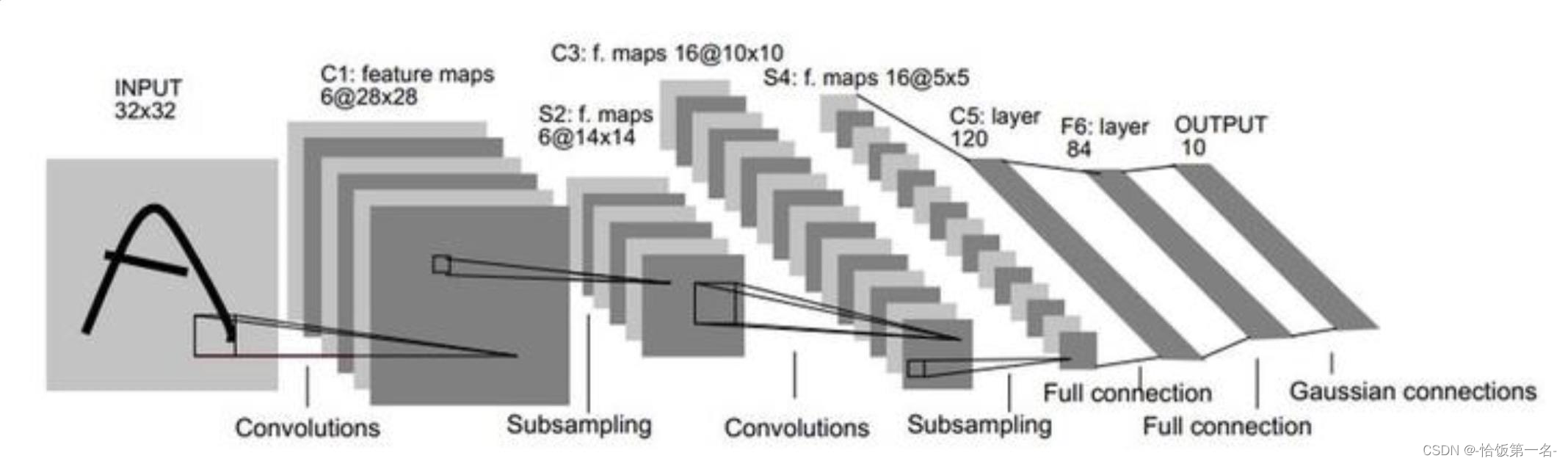

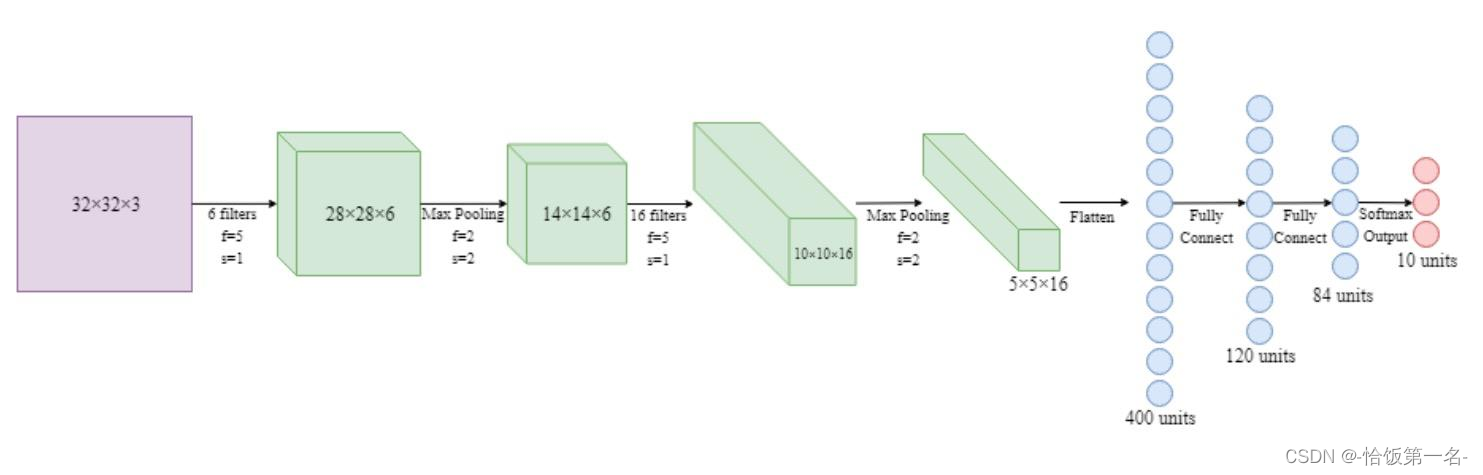

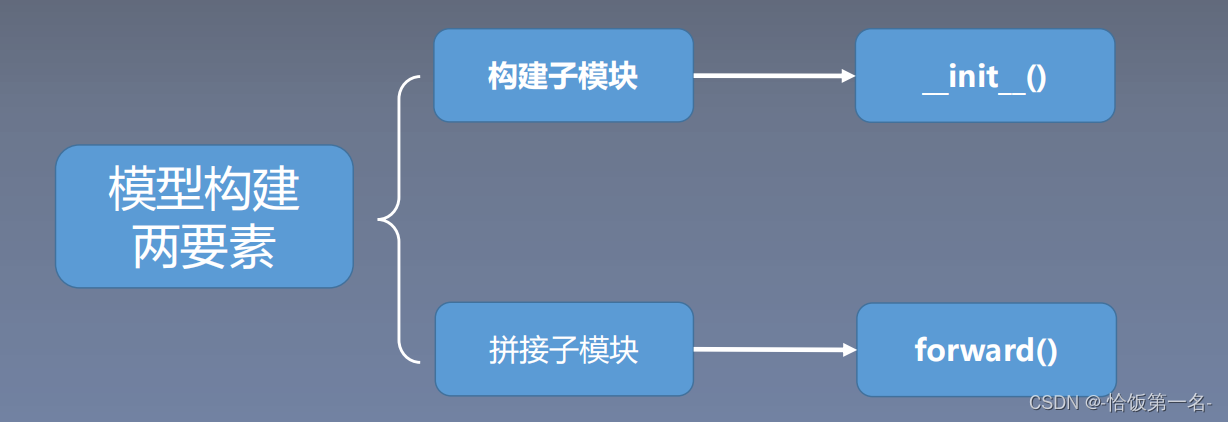
二、nn.Module

下面描述了在 PyTorch 中常见的一些属性和功能,用于存储和管理神经网络模型的参数、模块、缓冲属性和钩子函数。
parameters:用于存储和管理nn.Parameter类的属性。nn.Parameter是一种特殊的张量,它被自动注册为模型的参数,可以进行梯度计算和优化。parameters属性是一个可迭代对象,可以通过遍历它来访问模型的所有参数。modules:用于存储和管理nn.Module类的属性。nn.Module是神经网络模型的基类,可以包含其他模块、参数和计算图。modules属性是一个可迭代对象,可以通过遍历它来访问模型中的所有模块。buffers:用于存储和管理缓冲属性,例如 Batch Normalization 层中的running_mean和running_var。缓冲属性不会被视为模型的参数,但在模型的计算过程中会被使用和更新。*_hooks:用于存储和管理钩子函数。钩子函数是一种在模型的前向或后向传播过程中被调用的函数,可以用于获取中间特征、梯度等信息,或者在计算过程中进行一些额外的操作。*_hooks属性可以注册和管理多个钩子函数,以便在需要的时候进行调用。
这段代码展示了在 PyTorch 中 nn.Module 类的构造函数中常见的属性初始化操作。这些属性用于存储和管理模型的参数、缓冲属性、钩子函数和模块。
self._parameters:用于存储模型的参数。它是一个有序字典(OrderedDict),用于保存参数的名称和对应的张量值。self._buffers:用于存储模型的缓冲属性。它也是一个有序字典,用于保存缓冲属性的名称和对应的张量值。self._backward_hooks:用于存储模型的后向传播钩子函数。它是一个有序字典,用于保存钩子函数的名称和对应的函数。self._forward_hooks:用于存储模型的前向传播钩子函数。同样是一个有序字典,用于保存钩子函数的名称和对应的函数。self._forward_pre_hooks:用于存储模型的前向传播前钩子函数。同样是一个有序字典,用于保存钩子函数的名称和对应的函数。self._state_dict_hooks:用于存储模型的状态字典钩子函数。同样是一个有序字典,用于保存钩子函数的名称和对应的函数。self._load_state_dict_pre_hooks:用于存储模型的加载状态字典前钩子函数。同样是一个有序字典,用于保存钩子函数的名称和对应的函数。self._modules:用于存储模型的子模块。同样是一个有序字典,用于保存子模块的名称和对应的模块实例。
通过使用这些属性,nn.Module 类可以方便地管理模型的参数、缓冲属性、钩子函数和子模块,并提供了一些方法(如 state_dict() 和 load_state_dict())来进行模型的状态保存和加载。
nn.Module总结
nn.Module 是 PyTorch 中用于构建神经网络模型的基类,具有以下特点:
- 一个
nn.Module可以包含多个子模块:nn.Module具有层次结构,可以嵌套包含其他nn.Module实例作为其子模块。这样可以方便地构建复杂的神经网络结构。 - 一个
nn.Module相当于一个运算:每个nn.Module类都必须实现forward()函数,该函数定义了模型的前向传播过程。在调用模型对象时,会自动调用forward()函数来执行模型的前向计算。 - 每个
nn.Module都有 8 个字典管理它的属性:这些字典分别是_parameters、_buffers、_backward_hooks、_forward_hooks、_forward_pre_hooks、_state_dict_hooks、_load_state_dict_pre_hooks和_modules。这些字典用于存储和管理模型的参数、缓冲属性、钩子函数和子模块。
通过继承 nn.Module 类,我们可以定义自己的神经网络模型,并利用其提供的属性和方法来方便地管理模型的组件和状态。同时,nn.Module 类还提供了一些常用的方法,如 state_dict() 和 load_state_dict(),用于模型的状态保存和加载。
文章来源:https://blog.csdn.net/weixin_46334272/article/details/135467269
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 电影《名侦探柯南:黑铁的鱼影》观后感
- Vue ThreeJs实现银河系行星运动
- python开发案例教程-清华大学出版社(张基温)答案(4.3)
- LVM逻辑卷管理在线扩容命令
- 样本处理之SMOTE算法
- 【图像融合】基于分数阶样条小波变换实现多光谱图像与全色图像融合(含融合评价指标)附Matlab代码
- 通过头文件和makefile编译多个cpp文件
- JavaSE-Java基础-笔记
- 10个你不知道的JavaScript技巧,让你的代码更加的优雅!
- css3新增的伪类有哪些?