深度学习记录--指数加权平均
发布时间:2024年01月21日
指数加权移动平均(exponentially weighted moving averages)
如何对杂乱的数据进行拟合?
通过指数加权平均可以把数据图近似拟合成一条曲线

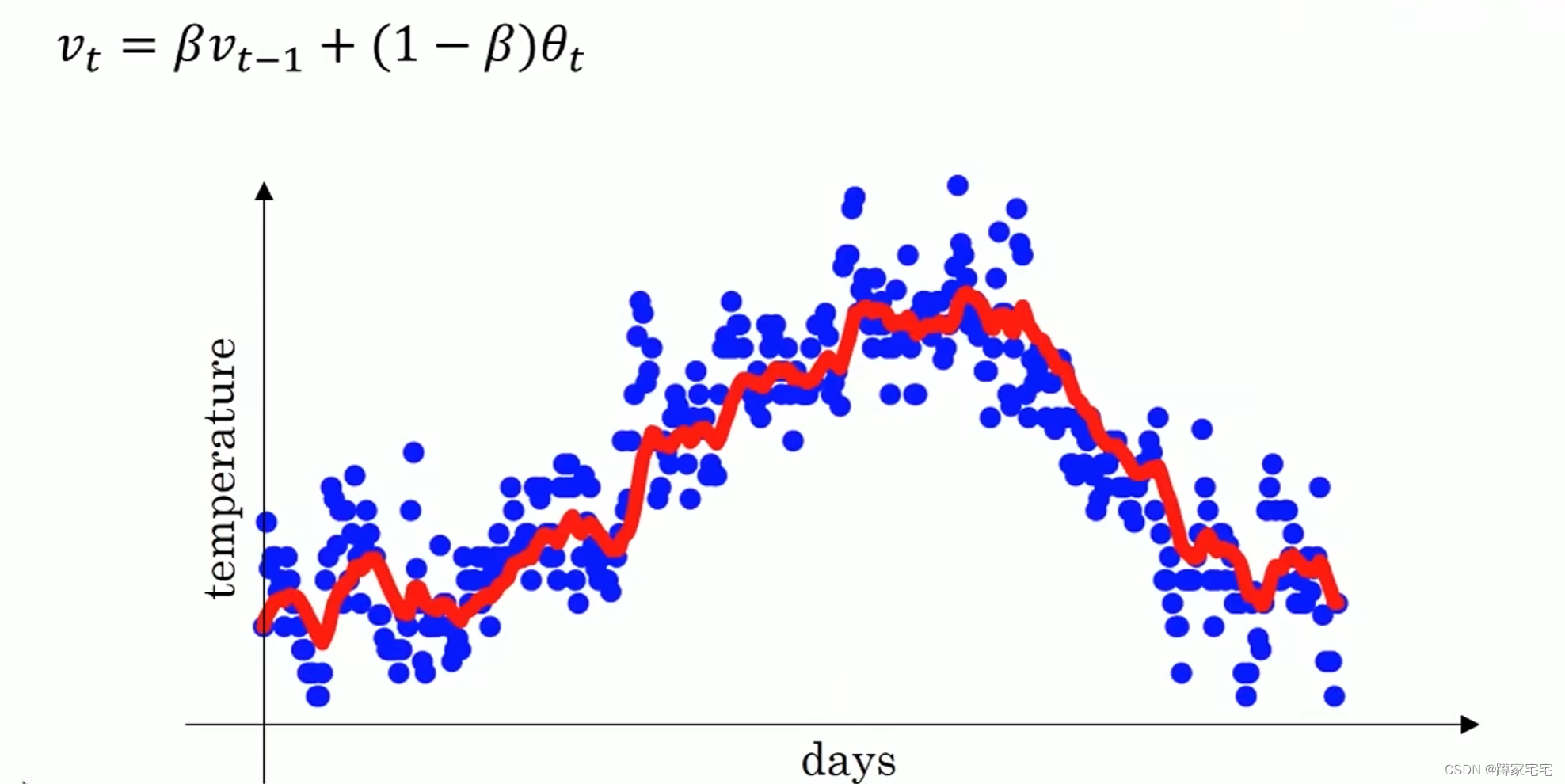
公式:
其中
表示第t个平均数,
表示第t-1个平均数,
表示第t个数据,
表示变化参数
下图为拟合结果()
当参数
例子:
?时,近似取10个数据平均值(红色曲线)
?时,近似取50个数据平均值(绿色曲线)
?时,近似取2个数据平均值(黄色曲线)
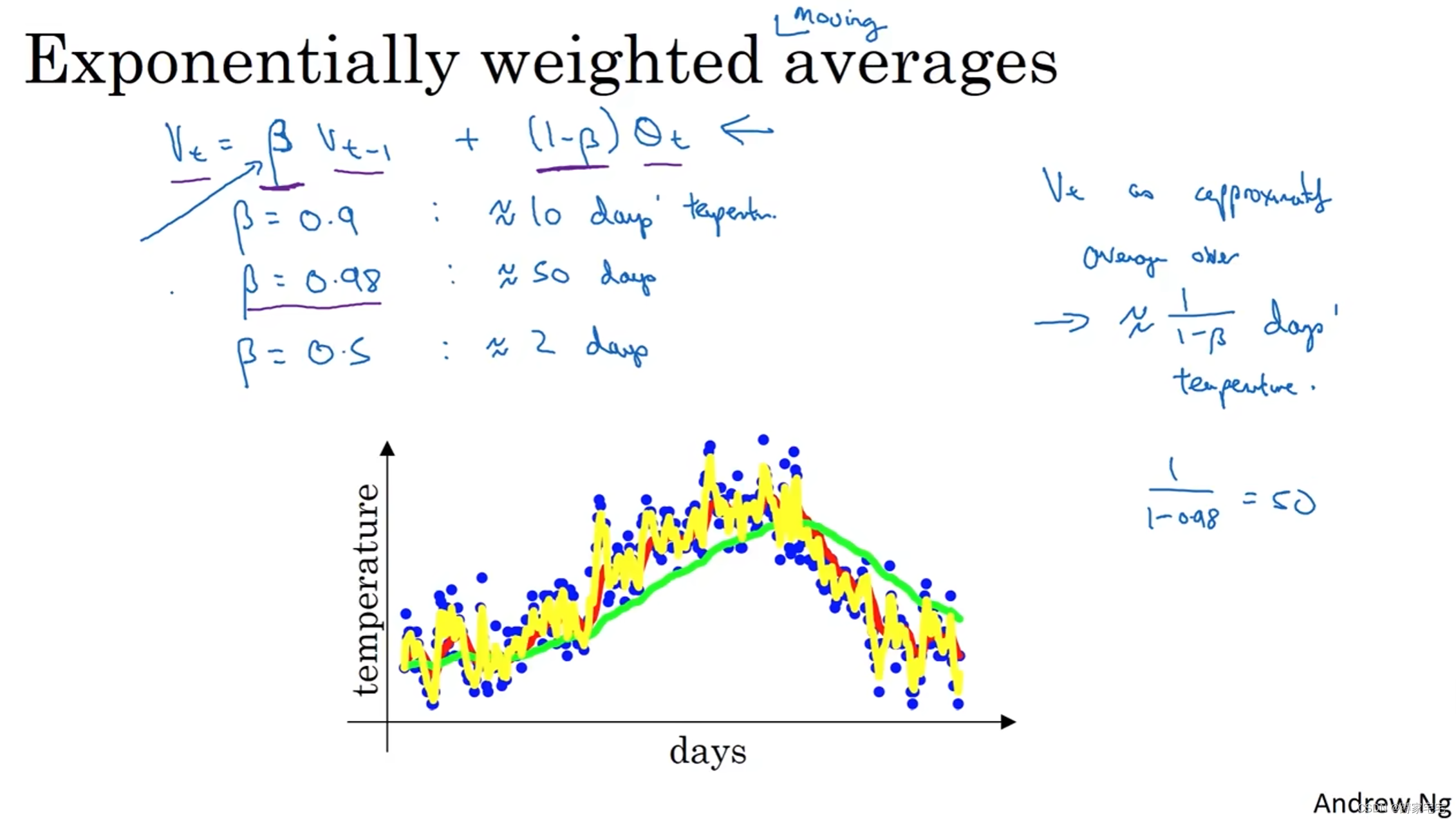
从上图三条曲线可知
参数
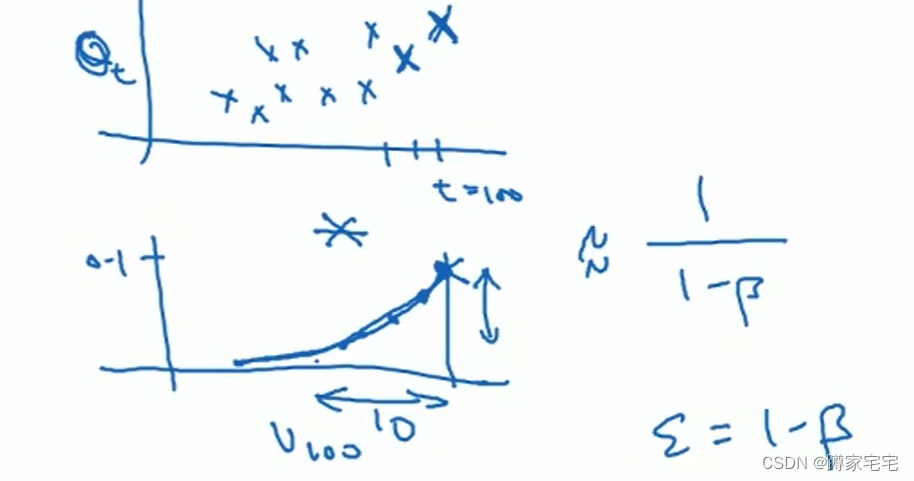
公式:
这个公式可以用来计算采样数据的数量
当
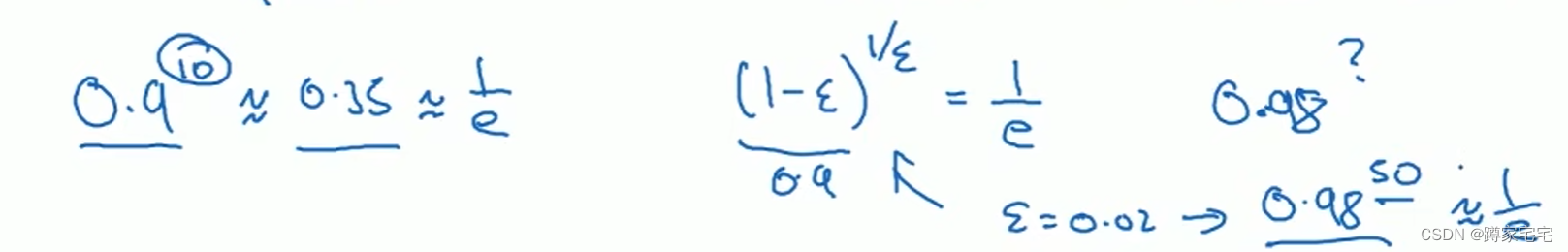
优点:
减少内存占用,只需一行代码实现重复更新
v=0
beta=0.9
theta=[1,2,4,5,6,8,10,14,18,22]
# theta[i]代表当前数据
for i in range(0,10):
v=beta*v+(1-beta)*theta[i]
print("v",i+1," = ",v)
偏差修正(bias correction)
当较大时,初期数据拟合可能偏差较大,为了更好地拟合初期的数据,故采用偏差修正
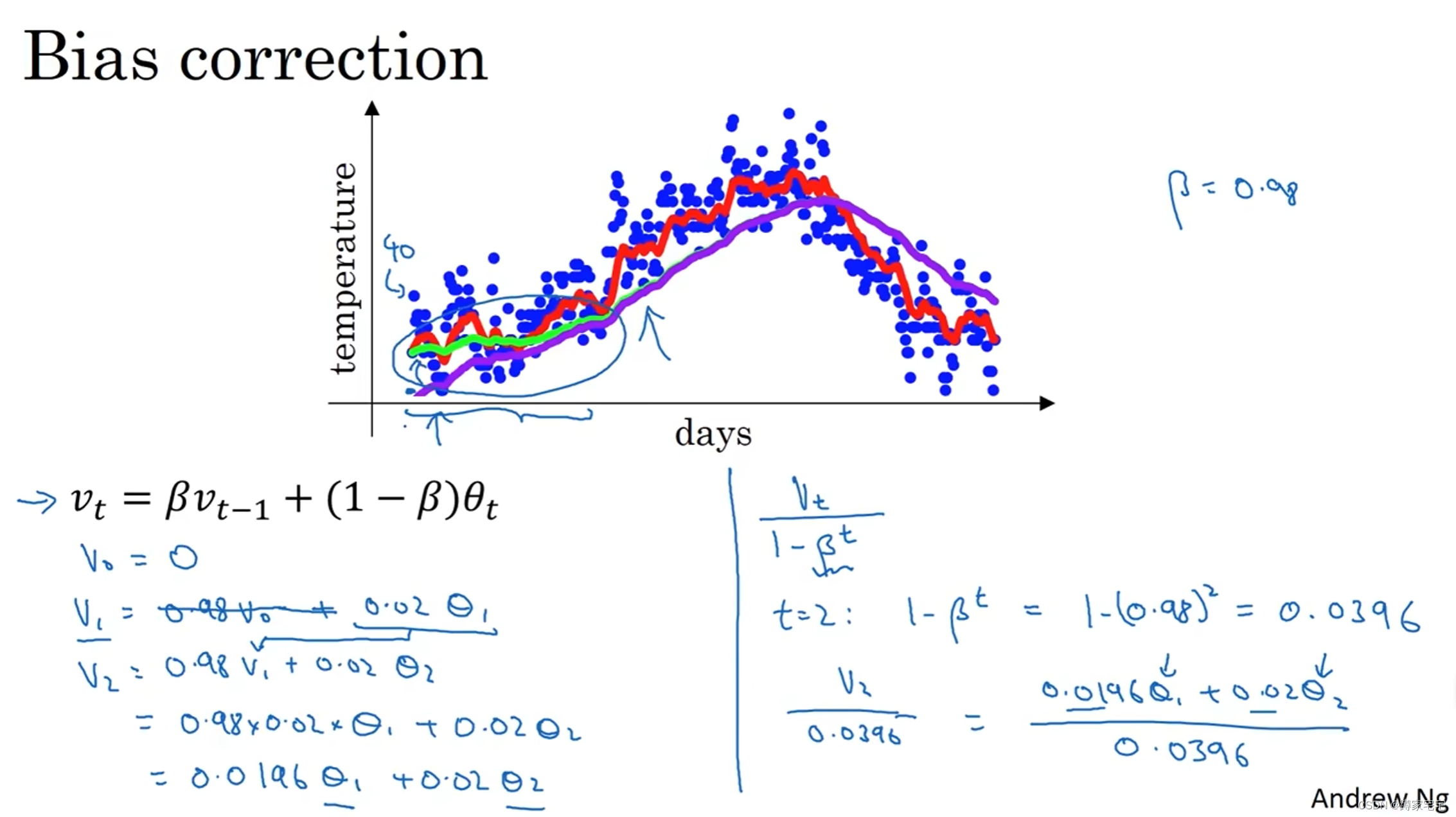
所得到的v值进行进一步的处理:
,其中t为天数
故当t较小时,可以被适当放大,更加拟合数据
当t变大,分母逐渐趋于1,所以后阶段偏差修正作用不大
总而言之,偏差修正是一种针对初期数据的修正偏差的方法
文章来源:https://blog.csdn.net/Xudong_12345/article/details/135707483
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ROS学习笔记(11)进一步深入了解ROS第五步
- 【CSS】垂直居中的四种实现方式
- Java-File:遍历目录下的所有文件
- 对 K8s 中的 NameSpace的ResourceList进行加减操作
- 深耕细作,持续发展|企业级快速开发平台助力实现流程化办公!
- 12.25广义分布外检测学习/代码复现
- JavaScript中的正则表达式构造函数和正则表达式字面量
- 超全的测试类型详解,再也不怕面试答不出来了!
- Python等高线图的绘制(Matplotlib篇-11)
- cpp_06_缺省构造_拷贝构造_拷贝赋值_初始化表