Linux重定向原理,由重定向原理贯穿讲解 进程、文件描述符及缓冲区

?个人主页:Lei宝啊?
愿所有美好如期而遇
目录
一、输出重定向
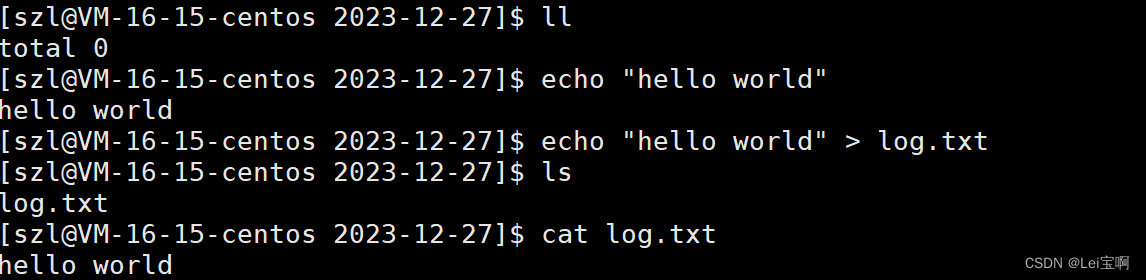
我们使用echo来进行演示,echo后面加上内容会将内容输出到显示器上,我们再加上 ">" 符号指定方向,代表重定向,将内容输出到符号后的文件里,也就是说将内容输出重定向。
二、输入重定向
"<" 代表输入重定向,我们平时都是从键盘上读取数据,输入重定向就是说我们输入数据时可以不从键盘上读取,而是从文件里读取。

显得有点挫,没关系,我们使用代码模拟的时候就能真正理解输入重定向是怎么用的。?
三、追加重定向?
">>"表示追加重定向,echo "内容" > 向文件中写入时,每一次都会先清空文件,然后再写入数据,所以我们的追加重定向就是为了解决这个问题。

背景知识
上面我们粗略的了解了三个重定向是如何使用的,接下来我们就要理解他们是怎么做到的,原理是什么,但是我们要真正理解他们,不可避免的要先理解一些背景知识。
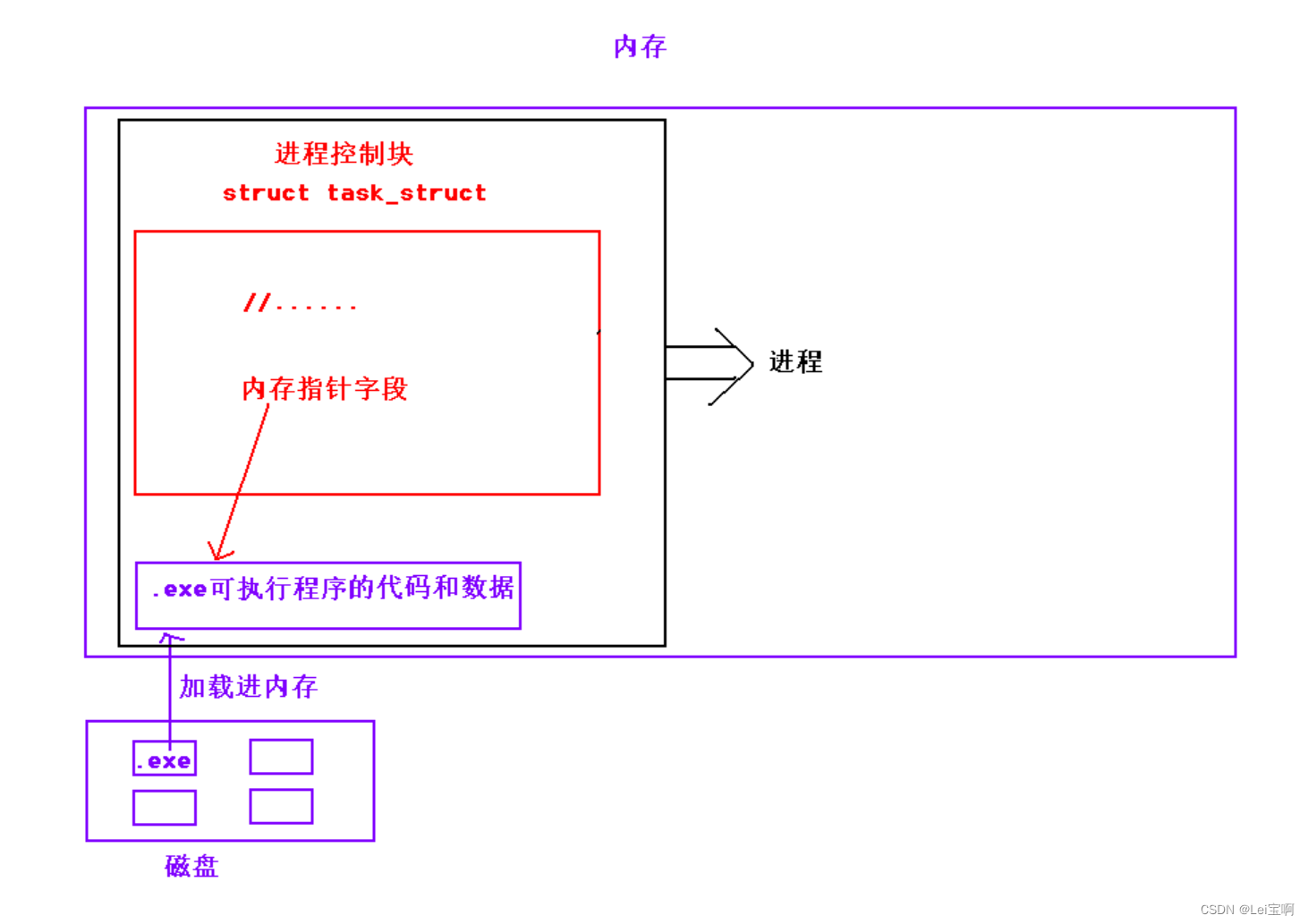
1.进程
首先,我们要理解进程,进程 = 内核数据结构 + 程序的数据和代码,在可执行程序运行起来时,先在内存中创建task_struct内核数据结构,将可执行程序的数据和代码加载进内存变成进程,同时我们也知道,task_struct结构体里有很多类型的变量,他们可以是指针,也可以是结构体类型,也可以是int等等。
看图深刻理解:
2.文件描述符
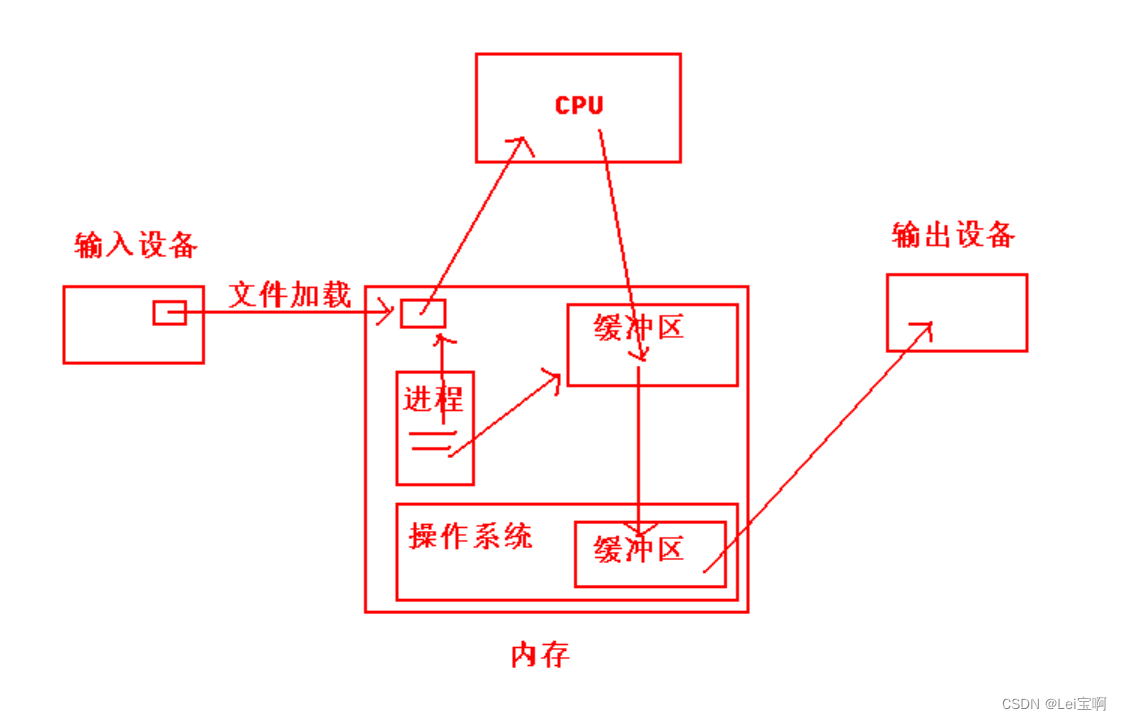
第二个就是文件描述符--fd,什么是文件描述符?本质上fd就是数组的下标,为什么这么说?
2.1、struct file
我们上面说到进程的内核数据结构,task_struct里有一个struct files_struct *file这样的结构体指针,他指向一个结构体,指向的这个结构体里有一个struct file* fd_array[]数组,这个数组的每个元素都是struct file*类型的指针,指向struct file类型的结构体,而这个结构体里包含着我们从磁盘打开的文件的几乎所有内容,不仅仅是属性,我们称之为内存文件,通过这个结构体,我们可以实现对磁盘文件的一系列操作。
看图深刻理解:

2.2、FILE*与系统调用
同时你真的了解FILE*吗?你真的了解C语言标准库支持的文件类函数吗?你真的了解Linux下文件类函数封装的系统调用吗?
- 我们使用Linux下的系统调用,例如fopen封装了open,open返回值是fd,这能说明什么呢?
- fwrite,fprintf等函数传的参数包含FILE*类型,而他们封装的系统调用write的参数是int fd,系统调用只认识fd,不认识什么FILE*。
既然你说系统调用不认识FILE*,那我们库函数传的参数FILE*你怎么解释?为什么库函数底层封装的系统调用却可以使用呢??
很简单,FILE结构体里封装了fd!给系统调用传参时传递FILE*->fd,也就是说,我们使用fopen函数,他底层的open函数打开一个文件,在内存中创建了struct file,将这个结构体的地址填入fd_array[],然后将填入位置的下标返回,也就是返回了fd,于是FILE*里封装的fd得到了返回的fd的值,FILE* pf = fopen(参数),pf指向的FILE结构体里就有了fd,fwrite参数传入FILE*,他封装的write得到参数pf->fileno(就是我们说的fd),这个系统调用由操作系统执行,操作系统会找到调用这个系统调用的进程,找到该进程,找到*file,由fd_array[fd]找到struct file,由struct file里的函数指针,找到对应硬件的驱动方法,对硬件进行读写!
所以我们最终得到结论:fd本质就是数组下标!
我们看个图来更深刻的理解一下:

理解原理,实现重定向
原理及实现
我们上面解释了背景知识,现在可以提及重定向的原理了
现在,我们使用系统调用open让一个进程同时创建打开多个文件,同时输出这些文件的fd,我们来观察现象并可以得到一个结论。
O_WRONLY,O_CREAT,O_TRUNC,O_APPEND都是宏,是open系统调用要传的参数,有兴趣可以深入理解,我们这里只简单介绍
- O_WRONLY--只读
- O_CREAT--若文件不存在则创建
- O_TRUNC--打开一个文件时先清空文件内容
- O_APPEND--追加
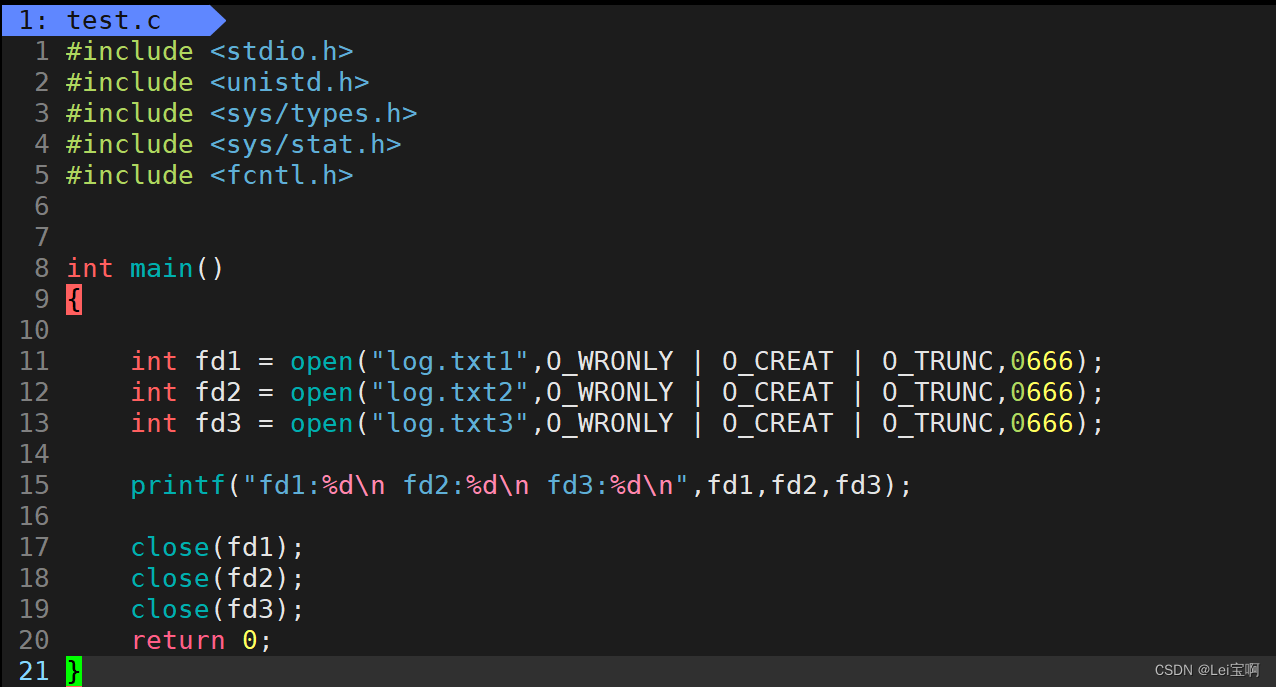

好像有点不对劲,0,1,2呢?为什么fd会从3开始呢?
这就要提到我们的stdin(标准输入),stdout(标准输出),stderr(标准错误),三者都是FILE*类型,也许你已经猜到了,是的,他们指向的FILE里的fd的值分别为0,1,2,而且这三个文件在进程运行时会被默认打开,占据了0,1,2,所以新打开的文件的fd也就是3,那么我们现在又有一个问题,fd的分配是按照先后顺序是吗?假如前面的文件关闭了,后面新打开文件,他的fd是从最后打开文件的fd的下一个开始,还是说fd的值是前面关闭的文件的fd?
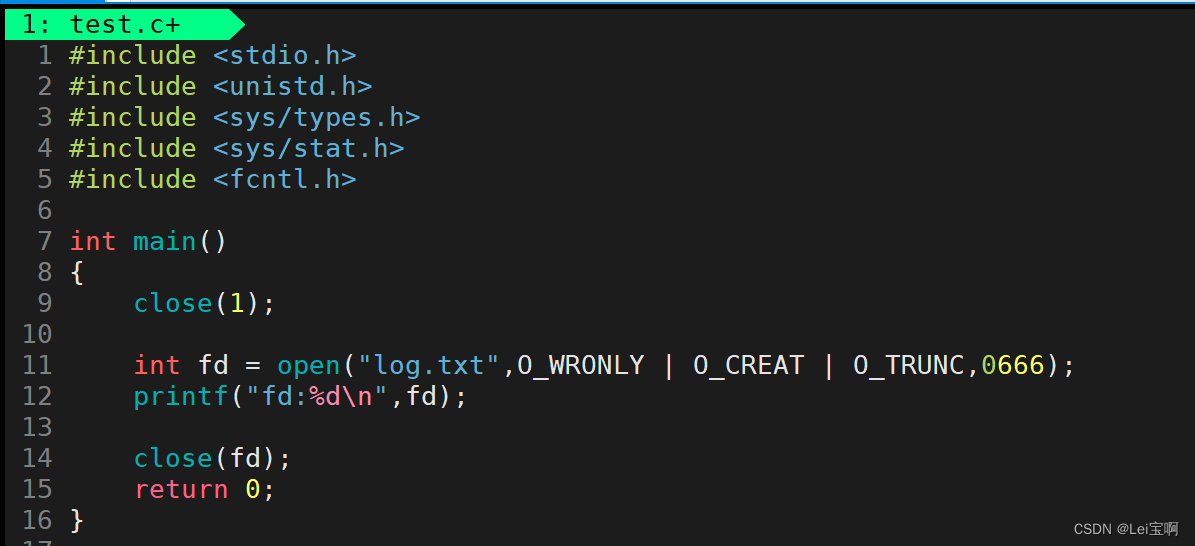

这下我们就很疑惑,为什么什么也不输出,而且文件里什么也没有?这里涉及到缓冲区,我们先谈完原理,然后谈缓冲区,最后返回来解决这里的问题,我们先解决,不说原因。
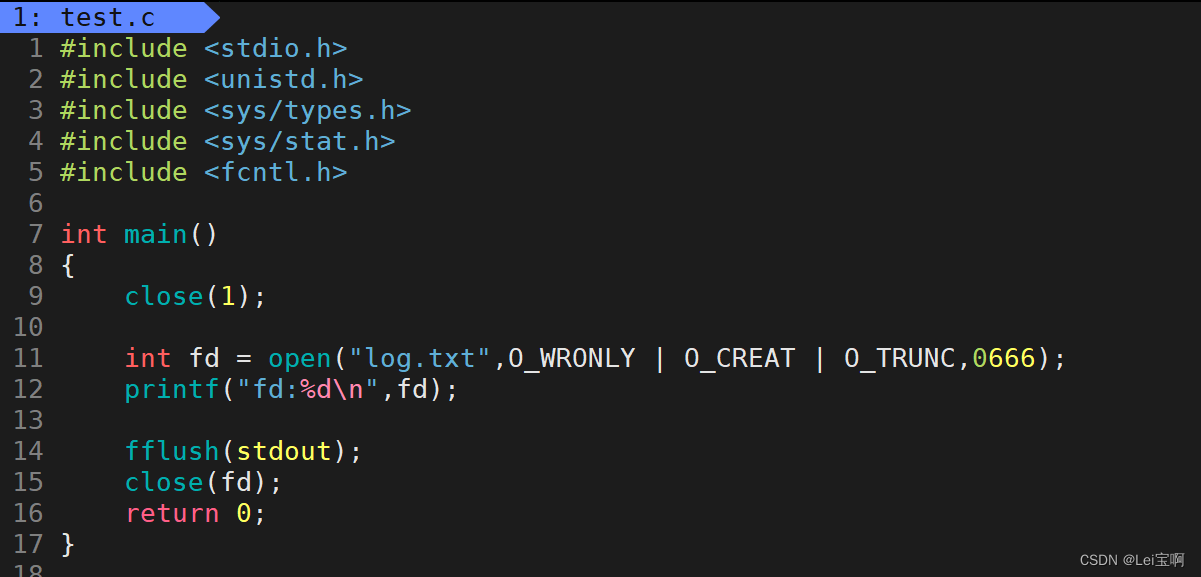
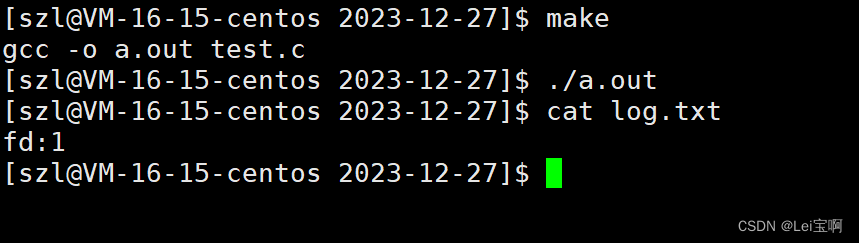
我们可以知道,fd的分配规则就是分配到最小的未被占据的位置。
那么还有一个问题啊,printf不是应该输出到显示器上吗,怎么输出到文件中了?为了使现象更明显,我们使用fprintf函数再来看现象。
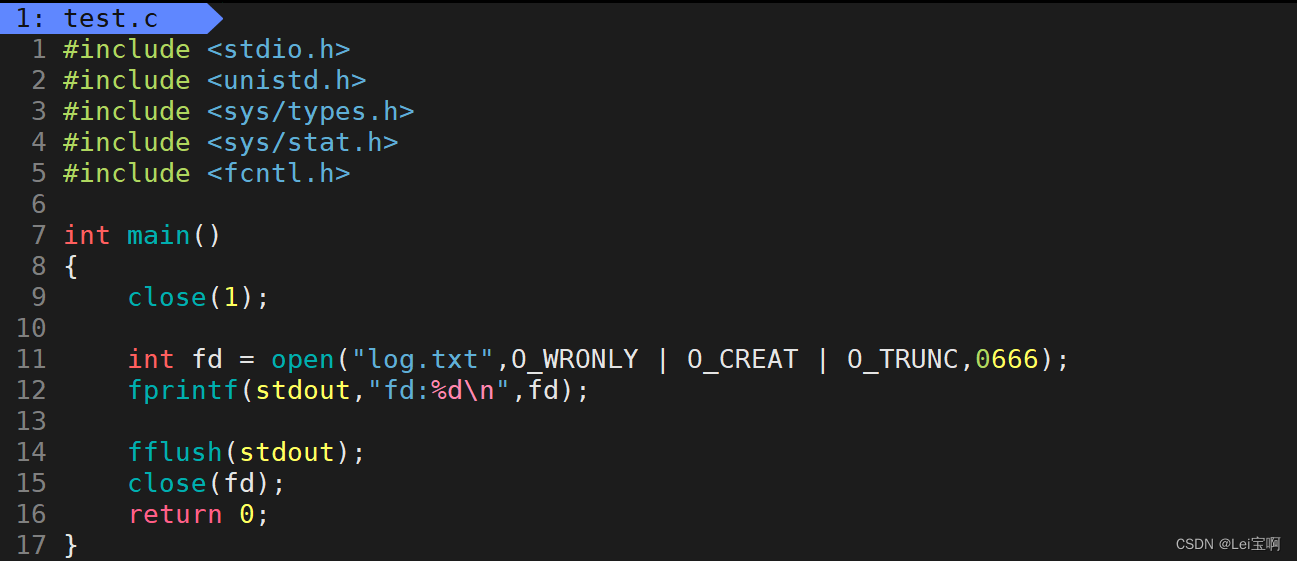
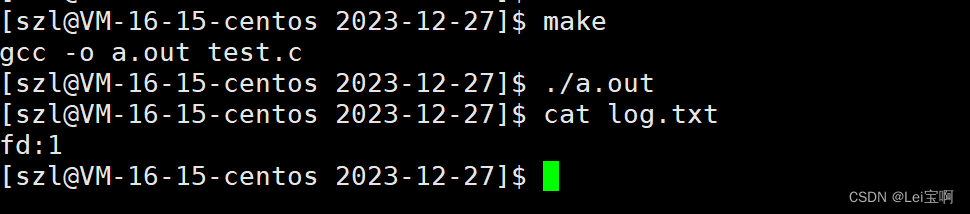
是谁的问题呢?stdout里封装的fd的值好像是1啊,但是我们也看到新打开的文件的fd的值也是1啊,stdout作为标准输出,应该将内容输出到显示器上,怎么输出到文件里了呢?
close的参数是fd,他的作用是清空fd_array[]数组fd位置的内容,也就是说,本来指向显示器内存文件struct file的指针被清空成NULL了,然后新文件打开,新文件struct file的地址填到了fd为1的位置,但是stdout里的fd还是1,我们再去使用封装了stdout的函数printf等去输出时,根据fd位置的指针找到的也就不是显式器内存文件了,而是磁盘内存文件,根据磁盘内存文件struct file里的函数指针去找的驱动方法自然也就是磁盘的读写方法,当然也就输出不到显示器上了,而是输出到了我们新打开的文件里。
这莫非就是传说中的输出重定向原理?那输入重定向,追加重定向也是这样喽?!
是的,我们无非就是先关闭fd为0的内存文件,然后打开一个新文件,使用fread,或者fsancf等传stdin参数从新文件里读取数据,这就是输入重定向原理
追加重定向也就是关闭fd为1的内存文件,然后打开一个新文件,再使用fwrite进行写入,当然,传参要传stdout了,我们来实现一下追加重定向,当然,同shell的用法不一样,但是,我们这里主要目的是更好地理解重定向原理。


说到这里其实我们就理解了重定向的原理,并且我们也模拟实现了 ,但是这种做法可能有一点挫,我们能不能不关闭文件实现重定向呢?
可以,使用系统调用dup2,我们看简介


那么dup2怎么用呢?(叫你好好学英语你不学,现在好了,介绍都看不懂)
这段英文的意思是newfd将作为oldfd的拷贝,如果必要的话,先关闭newfd。
哦,所以最终newfd和oldfd是一样的喽,并且newfd位置的内容不需要我们操心,操作系统会在必要时做处理,那什么是newfd,什么是oldfd?
我们想想刚才重定向时,我们清空了1号位置的内容,换上了我们新文件struct file的地址,最终1号位置的内容和新文件的地址相同了,也就是说,他是oldfd喽?是的,我们来使用看现象。


这样就显得优雅多了~
即使到这里,我们先前仍然有一个问题没有解决,就是为什么要加fflush(stdout),还有涉及到缓冲区,我们再来往下理解。
缓冲区
什么是缓冲区
缓冲区就是一段内存空间,由用户(char buffer[]),语言,或者操作系统提供。
为什么要有缓冲区
由冯诺依曼体系我们知道,一个文件要被读取,首先要从磁盘加载进内存,然后被CPU计算解读后返回到内存,再由内存输出到输出设备上,但是内存和磁盘交互的效率并不高,相比于内存和内存交互速度差了近千倍,如果说CPU计算解读后返回的数据内存立刻就输出到外设中,那么IO次数必然会增多,效率必然会下降。
所以我们在内存中加了缓冲区,这样CPU返回的数据写到内存的缓冲区中,缓冲区内的数据并不会立即输出到输出设备中,而是根据输出设备对应的缓冲区刷新策略将数据刷新到输出设备中,这样,就大大减少了IO次数,也就提高了整机效率。
但是我们主要的目的还是提高用户的响应速度,如果没有缓冲区,那么用户想要向一个文件写入数据,首先文件从磁盘加载进内存,CPU计算解读后返回给内存,解读一点,内存就给输出设备刷新一点,这样做的效率是很低的,而且直到文件被完全解读完,被全部给输出设备刷新后才会返回给用户,用户才知道,哦,我的操作成功了。
但是有了缓冲区,CPU返回的数据全部写进缓冲区后是否成功的结果直接就返回给用户,由于省去了和外设交互的过程,响应速度会快很多,这种方式叫做写回模式(WB),而没有缓冲区那种方式叫做(WT)写透模式,这种方式的时间成本比较高,很慢。
缓冲区刷新策略?
一般而言
- 立即刷新
- 行刷新(行缓冲),即刚开始遇到换行符\n时将\n前的内容全部刷新,下次会将两个换行符间的内容刷新。
- 满刷新(全缓冲),缓冲区满了将内容一次性全部刷新。
特殊情况
- 人为强制刷新(fflush(stdout))
- 进程退出时刷新缓冲区内容
关于缓冲区的认识?
上面我们特别用蓝色标注了一句话,根据输出设备对应的缓冲区刷新策略将数据刷新到输出设备中
一般而言
- 行缓冲的设备文件---显示器
- 全缓冲的设备文件---磁盘文件
但是,我们要知道的是所有设备都是倾向于全缓冲的,原因就是IO次数,全缓冲是缓冲区满了才刷新,IO次数少,也就意味着更少的外设访问,也就意味着更少的时间耗费,效率当然是比行缓冲高的,但是为什么显示器是行缓冲?你不是说所有设备都倾向于全缓冲吗?
这是显示器结合具体情况做的妥协,因为显示器是给我们人看的,如果说采用全缓冲,那么数据要么不显示,要么就一下出来一大堆,这显然不符合我们人的阅读习惯,我们人是习惯于一行一行阅读的,所以显式器结合效率和用户的体验最终选择了行缓冲。
而对于磁盘而言,用户并不需要立即看到输出数据的结果,并不需要考虑用户的体验,只需要出于效率而言考虑,选择了全缓冲。
缓冲区在哪里
我们先看一段代码:


fputs,fprintf,printf都输出了两次,而write只输出了一次,这是我们直观可以看到的现象,其次,我们调用了fork函数,并且知道的是,调用fork函数时,前面的代码都已经执行完了!
fork是做什么的?创建子进程!创建的子进程又会怎样呢?创建自己的进程地址空间和页表,同时进程地址空间继承大部分父进程的数据,与父进程共享fork后的代码,拷贝父进程的页表。
看图深刻理解:

但是,为什么我们直接运行可执行程序,不会重复输出,而重定向以后,C标准库提供的函数却重复输出了呢?
我们说过行缓冲,全缓冲,直接运行我们的可执行程序,是向显示器输出,显示器对应的刷新策略是行缓冲,所以在fork之前,数据已经刷新出去了,再fork,子进程得到的也只是空的缓冲区。
而我们重定向以后,变成了向磁盘文件输出,刷新策略也就隐性的变成了全缓冲,此时缓冲区里的数据是可以被子进程拿到的,父子进程不管谁先退出去刷新缓冲区,另一个一定会写时拷贝,再去刷新,这样也就将数据刷新了两次。
并且,我们说fork之后父进程和子进程代码和数据共享,我们还说过,进程退出后,缓冲区全部刷新,而从缓冲区刷新到stdout文件里也是一种写入,你父进程如果将数据刷新了,我子进程不就被影响了吗?这当然不行,那我就写时拷贝,进程退出时,你父进程刷新你的数据,我子进程刷新自己的数据,所以我们可以看到C提供的函数输出了两次。
那我的系统调用没有被影响啊!所以我们说到的"缓冲区"是谁维护的呢?首先一定不是用户,再者,不是操作系统,如果是操作系统的话,我们看到的现象应该是都输出两遍,所以我们只剩下了一个答案,就是语言,我们这里用C语言写的代码,理所应当就由C标准库来维护这个缓冲区!
接下来我们看一个图来更深刻的理解:
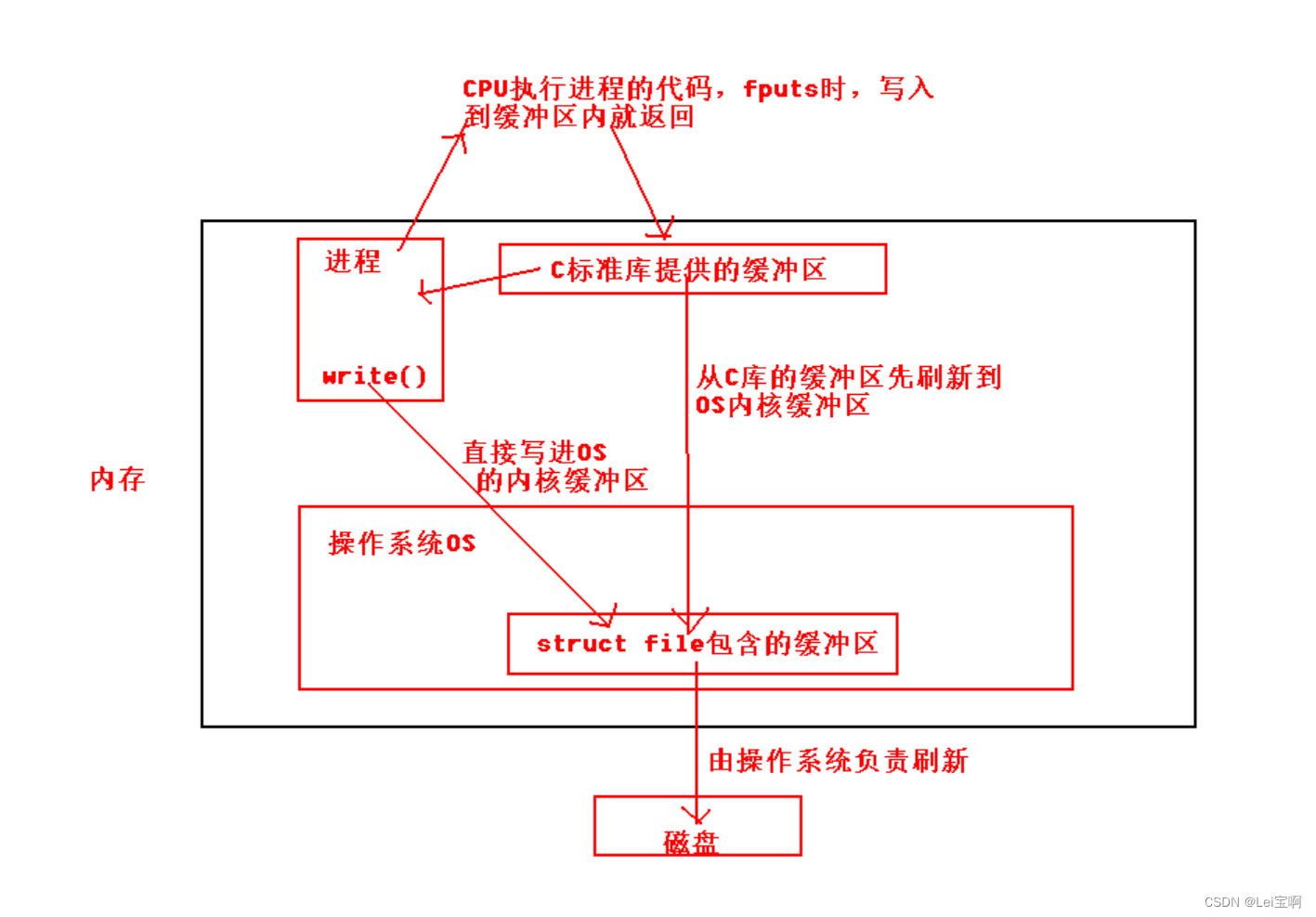
正是因为这个原因,write系统调用并不会输出两次,因为他直接将数据写进了struct file的缓冲区内,并不在C库的缓冲区,当子进程或父进程写时拷贝,你去拷贝C库缓冲区内的数据,我操作系统内部缓冲区的数据关你进程的写时拷贝什么事。
回答遗留问题
我们之前遗留了一个问题:
首先我们关闭了fd_array中下标为1的文件,然后打开的新文件fd就为1,也就是说,我们的输出由显示器重定向到了磁盘,缓冲区刷新策略由行缓冲变成了全缓冲,那么我们printf即使加了\n也不会刷新出去,后面我们关闭了fd,也就是说。关闭了struct file,即使进程退出,C库缓冲区里的数据也刷新不到struct file的缓冲区里了,自然无法写到磁盘里,所以我们显示器看不到,文件里也没有。
到这里,我们关于重定向,进程,文件描述符,以及缓冲区已经可以全部串起来理解了,如果觉得博主写的还可以,点个关注,我们下期再见。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!