蓝奏云获取下载链接js逆向
发布时间:2024年01月12日
本期地址如下,使用base64解密获得
aHR0cHM6Ly9meGpkLmxhbnpvdXcuY29tL2l6bkxrMTdncnkyZA==
获取最终的下载链接需要经过三次请求获得,如下图
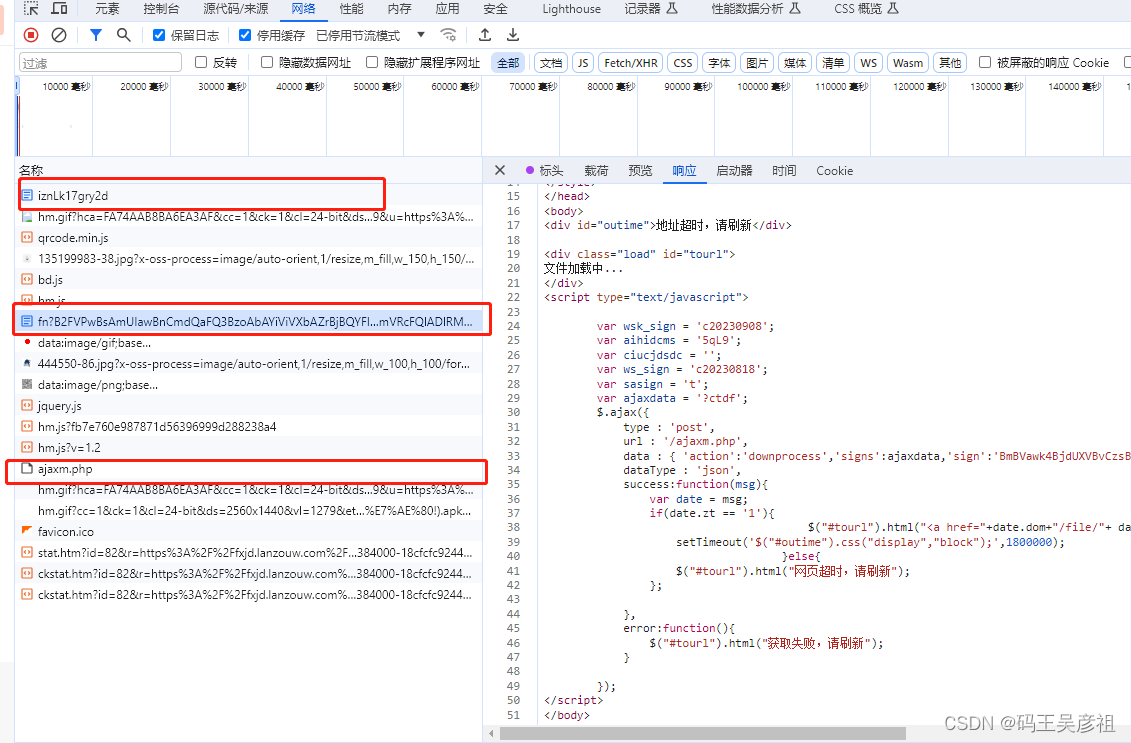
每个请求都包含下一次请求的信息,我们逐步分析请求
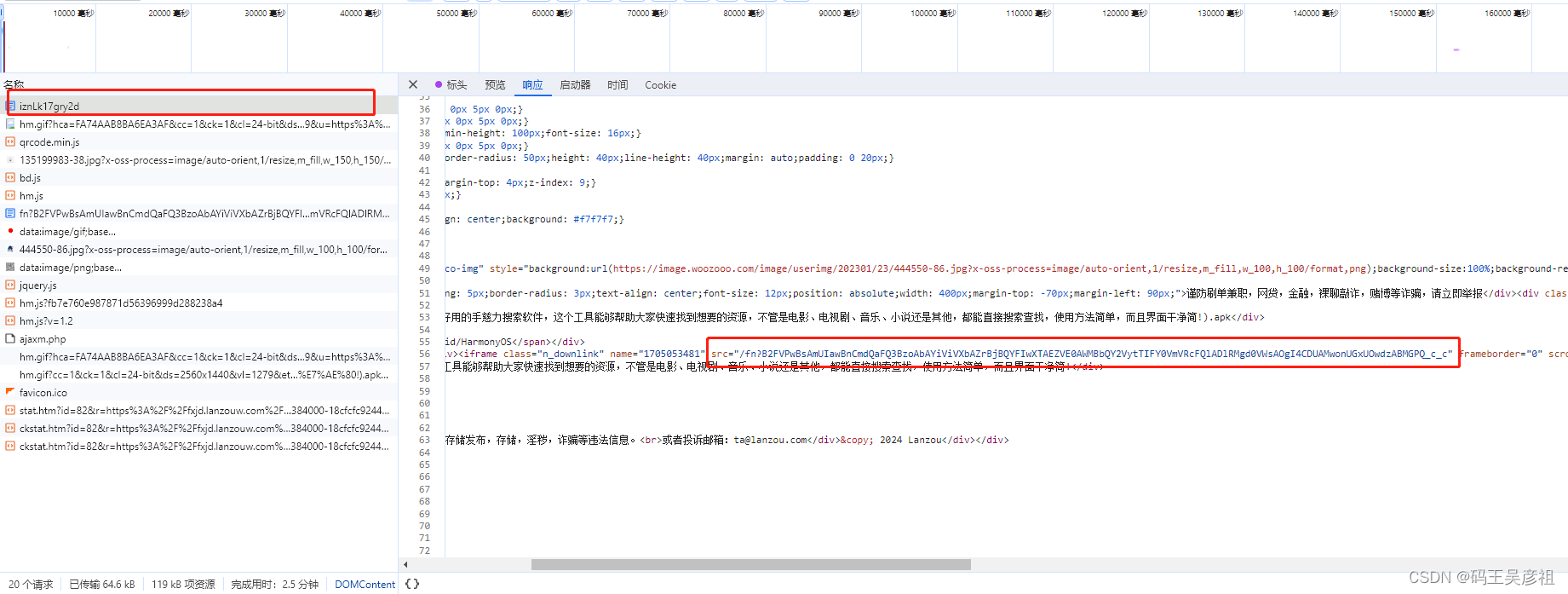
第一个请求直接包含了第二次请求的src
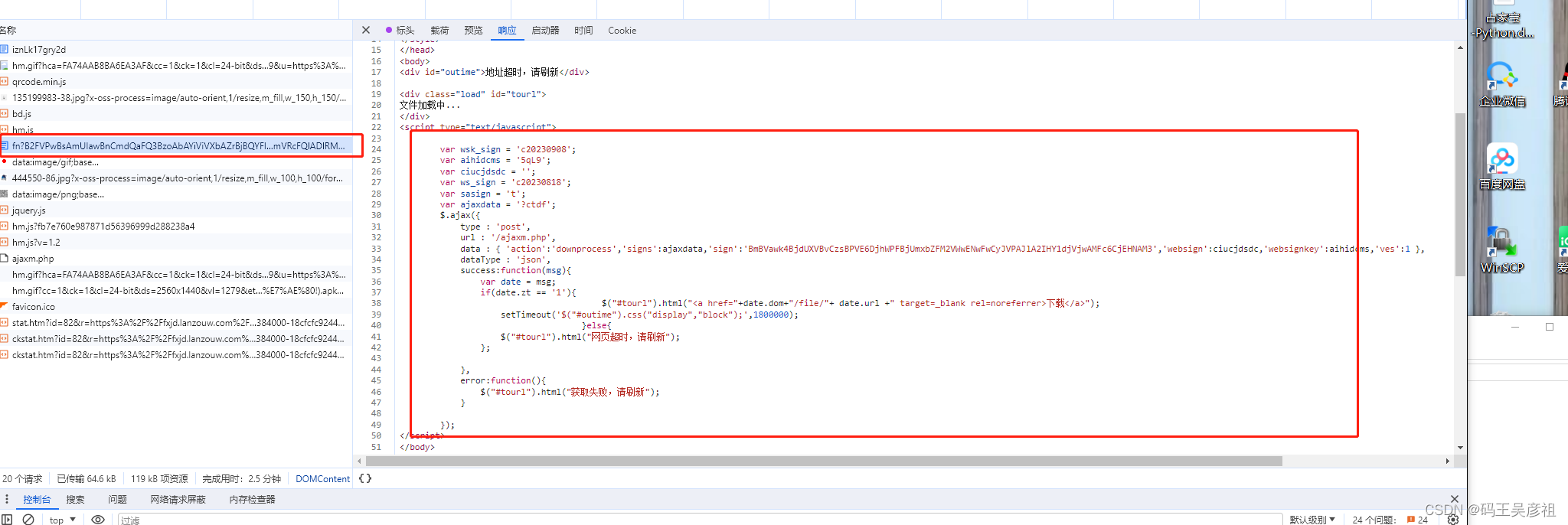
第二个请求直接包含了第三次post请求所需要传的data参数

第三个请求直接包含了文件下载的url
所以本质上,这里面没有js逆向的逻辑,只是请求的逻辑而已,python代码如下
import requests
import re
from bs4 import BeautifulSoup
session = requests.session()
headers = {
'Accept': 'application/json, text/javascript, */*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Content-Type': 'application/x-www-form-urlencoded',
# 'Cookie': 'codelen=1; Hm_lvt_fb7e760e987871d56396999d288238a4=1705051448; pc_ad1=1; uz_distinctid=18cfcfc9243e23-06f6015bb3f86a-26001951-384000-18cfcfc9244134c; STDATA82=czst_eid%3D130820850-3821-https%253A%252F%252Ffxjd.lanzouw.com%252F%26ntime%3D3821; Hm_lpvt_fb7e760e987871d56396999d288238a4=1705051547',
'Origin': 'https://fxjd.lanzouw.com',
'Pragma': 'no-cache',
'Referer': 'https://fxjd.lanzouw.com/fn?VzEGbAhkD2hWNQJlC2ZVbQRnAz4FaQQgBXZTaAVoBDJVZQVnCWRQMQVhAmUEZF1qA38CcVc1ATIFJFUkV25XNFckBjgIMg81VmsCMQsmVWkEawN3BRYEPw_c_c',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
host = "https://fxjd.lanzouw.com"
response = session.get('https://fxjd.lanzouw.com/iW8O40no7fni', headers=headers)
print(response)
soup = BeautifulSoup(response.text, 'html.parser')
divs = soup.find('div', {'class': 'n_downlink'})
src = soup.find(class_="n_downlink").get("src")
second_src = host + src
response = session.get(second_src, headers=headers)
print(response)
pattern = r'<script\b[^>]*>(.*?)</script>'
matches = re.findall(pattern, response.text, re.DOTALL)
dowload_js = matches[1]
aihidcms = re.search(r"var aihidcms\s*=\s*'(.*?)';", dowload_js).group(1)
action = re.search(r"'action':'(.*?)'", dowload_js).group(1)
ajaxdata = re.search(r"var ajaxdata\s*=\s*'(.*?)';", dowload_js).group(1)
sign = re.search(r"'sign':'(.*?)'", dowload_js).group(1)
ciucjdsdc = re.search(r"var ciucjdsdc\s*=\s*'(.*?)';", dowload_js).group(1)
ves = re.search(r"'ves':(\d+)", dowload_js).group(1)
print("aihidcms:", aihidcms)
print("action:", action)
print("ajaxdata:", ajaxdata)
print("sign:", sign)
print("ciucjdsdc:", ciucjdsdc)
print("ves:", ves)
data = {
'action': action,
'signs': ajaxdata,
'sign': sign,
'websign': ciucjdsdc,
'websignkey': aihidcms,
'ves': ves,
}
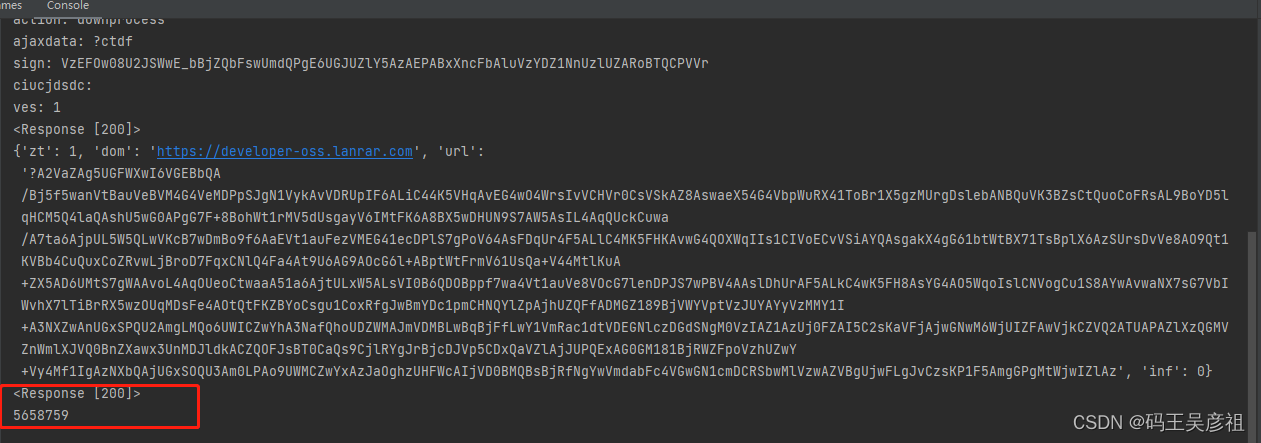
response = session.post('https://fxjd.lanzouw.com/ajaxm.php', headers=headers, data=data)
print(response)
print(response.json())
data_src = 'https://developer-oss.lanrar.com/file/' + response.json().get('url')
response = session.get(data_src, headers=headers)
print(response)
print(len(response.content))
拿到最后的文件content,大小也是正确
文章来源:https://blog.csdn.net/qq_36551453/article/details/135559350
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 为CT_P自动注册与CT_Run相关的方法
- SSM人事管理系统----计算机毕业设计
- XSS漏洞:利用多次提交技巧实现存储型XSS
- HugggingFace 推理 API、推理端点和推理空间相关模型部署和使用以及介绍
- 案例125:基于微信小程序的个人健康数据管理系统的设计与实现
- WEB 3D技术 three.js 解决几何体移动后 包围盒还留在原地问题
- 数据库-列的类型-时间日期数据类型
- CDH 6.3.2集成flink 1.18 zookeeper版本不匹配Flink-yarn启动失败
- 4.2V锂电线性1.2A充电芯片WT4056
- Java多线程&并发篇----第十八篇