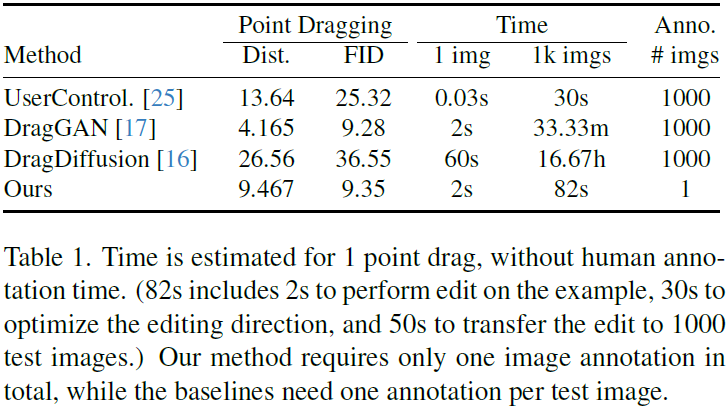
DragGAN、DragDiffusion、Edit One for All、RPG(写论文 ing,略读几篇最新及相关论文)
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)
目录
1. (2023|SIGGRAPH,DragGAN,基于交互式拖动的图像编辑,特征空间,运动监督,点追踪)拖动您的 GAN:生成式图像流形上基于点的交互式操作
2.(2023,DragGAN,DragDiffusion,保持身份的微调,参考潜在控制,DragBench)DragDiffusion:利用扩散模型进行交互式基于点的图像编辑
3.(2024,StyleGAN 潜在空间,交互式图像编辑,编辑迁移)Edit One for All:交互式批量图像编辑
4.(2024,RPG-DiffusionMaster,思维链,按区域图象生成和编辑)掌握文本到图像的扩散:使用多模态 LLM 进行重新标注、规划和生成
1. (2023|SIGGRAPH,DragGAN,基于交互式拖动的图像编辑,特征空间,运动监督,点追踪)拖动您的 GAN:生成式图像流形上基于点的交互式操作
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
1.1 摘要
本文研究用户以交互方式 “拖动” 图像的任意点来给与编辑指令,如图 1 所示。为此,本文提出了 DragGAN,它由两个主要组件组成:1)基于特征的运动监督,驱动控制点向目标位置移动,以及2)一种新的点追踪方法,利用判别生成器特征来持续定位控制点的位置。通过 DragGAN,任何人都可以以精确控制像素位置的方式改变图像,从而操纵各种类别的姿势、形状、表情和布局,如动物、汽车、人类、风景等。
由于这些操作是在 GAN 的学习生成图像流形上执行的,它们往往能够产生逼真的输出,即使在挑战性场景下,如产生幻觉的遮挡内容和变形形状,这些变形也始终遵循对象的刚性。定性和定量比较都证明了DragGAN在图像操作和点追踪任务上相对于先前方法的优势。
项目页面:https://vcai.mpi-inf.mpg.de/projects/DragGAN/


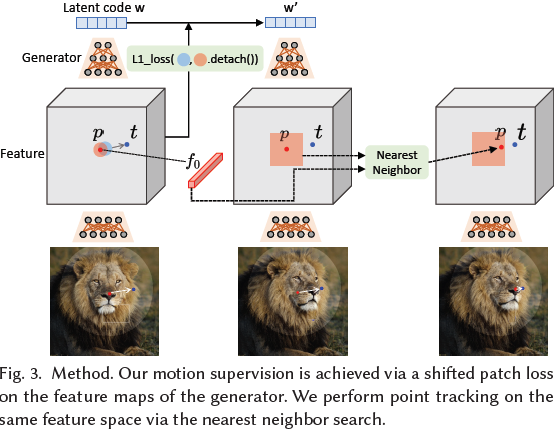
1.2 方法
我们使用 Ω1(𝒑𝑖, 𝑟1)来表示到 𝒑𝑖 的距离小于 𝑟1 的像素,然后我们的运动监督损失是:?

F 是来自 StyleGAN2 第 6 个块之后的特征图,F0 是对应于初始图像的特征图,F(q) 表示像素 q 处的特征值,d 是与像素 q 和拖动 drag 有关的归一化指示向量,M 是二进制掩码。?在每个运动监督步骤中,此损失用于优化潜在代码 𝒘 一步。?
先前的运动监控导致新的潜在代码 𝒘′,新的特征图 F′,和新的图像 I′。由于运动监控步骤并未直接提供处理点的精确新位置,因此我们的目标是更新每个处理点 𝒑𝑖,使其跟踪物体上相应的点。我们将初始处理点的特征表示为 𝒇𝑖 = F0(𝒑𝑖)。我们将围绕 𝒑𝑖 的 patch 表示为 Ω2(𝒑𝑖, 𝑟2) = {(𝑥,𝑦) | |𝑥 ? 𝑥𝑝,𝑖 | < 𝑟2, |𝑦 ? 𝑦𝑝,𝑖 | < 𝑟2}。然后,通过在 Ω2(𝒑𝑖, 𝑟2) 中搜索 𝑓𝑖 的最近邻来获得跟踪点:?
![]()
1.3 结果?



2.(2023,DragGAN,DragDiffusion,保持身份的微调,参考潜在控制,DragBench)DragDiffusion:利用扩散模型进行交互式基于点的图像编辑
DragDiffusion: Harnessing Diffusion Models for Interactive Point-based Image Editing
2.1 摘要
准确且可控的图像编辑是一项具有挑战性的任务,近期引起了极大关注。值得注意的是,Pan 等人(2023)[31] 开发的 DragGAN 是一种交互式基于点的图像编辑框架,以像素级精度实现了令人印象深刻的编辑结果。然而,由于其依赖生成对抗网络(GANs),其通用性受到预训练 GAN 模型容量的限制。在这项工作中,我们将这一编辑框架扩展到扩散模型,并提出了一种新方法DragDiffusion。通过利用大规模预训练的扩散模型,我们极大地增强了交互式基于点的编辑在真实图像和扩散生成图像上的适用性。与其他基于扩散的编辑方法不同,它们提供多个时间步的扩散潜在的指导,我们的方法通过仅优化一个时间步的潜在来实现高效而准确的空间控制。这种新颖的设计是由我们观察到的 UNet 特征在特定时间步提供足够的语义和几何信息以支持基于拖拽的编辑的启发。此外,我们引入了两种附加技术,即保持身份的微调和参考潜在控制,以进一步保留原始图像的身份。最后,我们提出了一个具有挑战性的基准数据集,名为 DragBench——这是第一个评估交互式基于点的图像编辑方法性能的基准。在广泛范围的挑战性案例(例如,具有多个对象的图像,各种对象类别,不同风格等)的实验证明了 DragDiffusion?的多功能性和通用性。
代码和 DRAGBENCH 数据集:https://github.com/Yujun-Shi/DragDiffusion

2.2 方法
我们的方法包括三个步骤:
- 首先,在给定输入图像的扩散模型的 UNet 上进行保持身份的微调。该阶段旨在确保扩散 UNet 更准确地编码输入图像的特征(相对于没有此过程的情况),从而促进在整个编辑过程中图像身份的一致性。这个微调过程使用 LoRA 实现。
- 其次,根据用户的拖拽指令,我们优化从输入图像 DDIM 反演中获得的潜在。首先,在给定的真实图像上应用 DDIM 反演,以获得在特定步骤 t(即 zt)时的扩散潜在。这个扩散潜在作为我们潜在优化过程的初始值。然后,遵循 DragGAN,重复执行运动监控和点追踪以优化潜在,直到所有处理点都移动到目标位置或达到最大迭代次数。
- 第三,我们应用 DDIM 去噪,由我们的参考潜在控制引导,对 ?zt 进行处理以获得最终的编辑结果?z0。我们发现简单地在优化后的潜在上应用 DDIM 去噪有时仍会导致与原始图像相比的不良身份转移或质量下降。我们认为这个问题是由于在去噪过程中缺乏来自原始图像的足够引导所致。为了缓解这个问题,我们利用自注意力模块的特性来引导去噪过程:在去噪过程中 UNet 的自注意力模块的前向传播期间,我们用从原始图像潜在 zt 生成的键和值向量替换从 优化的潜在 ?zt 生成的键和值向量。通过这种方式,参考潜在控制(reference-latent-control)显著提高了原始图像与编辑后图像之间的一致性。
2.3 结果


3.(2024,StyleGAN 潜在空间,交互式图像编辑,编辑迁移)Edit One for All:交互式批量图像编辑
Edit One for All: Interactive Batch Image Editing
3.1 摘要
在近年来,图像编辑取得了显著的进步。通过增加人类控制,现在可以以多种方式编辑图像;从以文本指定想要更改的内容,到直接以交互式基于点的方式拖动图像的内容。然而,大部分关注仍然集中在一次编辑单个图像上。关于如何同时编辑大批量图像以及如何进行这种编辑的问题仍然未受到深入研究。为了在编辑过程中最小化人工监督的目标,本文提出了一种使用 StyleGAN 作为媒介进行批量交互式图像编辑的新方法。在用户在示例图像中指定编辑的情况下(例如,使脸部正面),我们的方法可以自动将该编辑迁移到其他测试图像,使它们不管初始状态如何(姿势),最终都达到相同的状态(例如,全部面向前方)。大量实验证明,使用我们的方法执行的编辑在视觉质量上与现有的单图像编辑方法相似,同时具有更多的视觉一致性并节省了大量时间和人力。
代码:https://thaoshibe.github.io/edit-one-for-all

3.2 方法
我们的重点是在图像编辑过程中,编辑一个图像的属性,使得该属性的值达到期望的状态;例如,将一个侧脸的姿态旋转,使其正面朝向(属性=脸部姿态,值=正面)。
我们的批量图像编辑框架,可以分为两个阶段:
用户编辑图像 I_0(例如,使用 DragGAN 或 InstructPix2Pix)以获得编辑后的图像 I′_0。
对任何新图像应用建模的编辑(编辑迁移):通过自动调整其强度,使得这个新图像中的属性值与 I′_0 的匹配(例如,任何脸部,无论其初始姿态如何,在编辑后都正面朝向)。?
- 根据 StyleGAN、Image2StyleGAN 和 Improved Image2StyleGAN 等文章(均可在历史文章中找到),在属性解耦的潜在空间 W 空间中,我们可以发现这些属性的方向(使用监督和无监督方法),如图 3(b) 所示。
- 因此,我们的目标是通过一个 W 空间方向来表示 I_0 → I′_0 的编辑,这个方向可以更好地满足全局一致性方向的属性。
3.3 结果


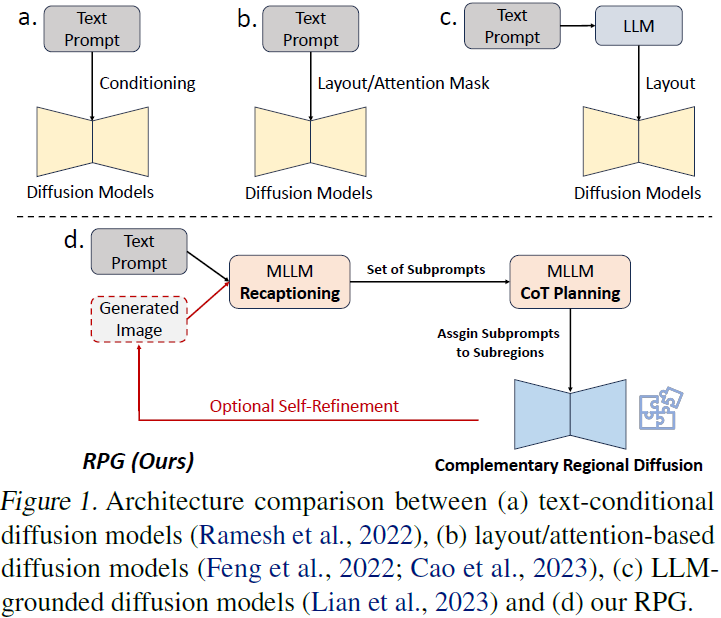
4.(2024,RPG-DiffusionMaster,思维链,按区域图象生成和编辑)掌握文本到图像的扩散:使用多模态 LLM 进行重新标注、规划和生成
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
4.1 摘要
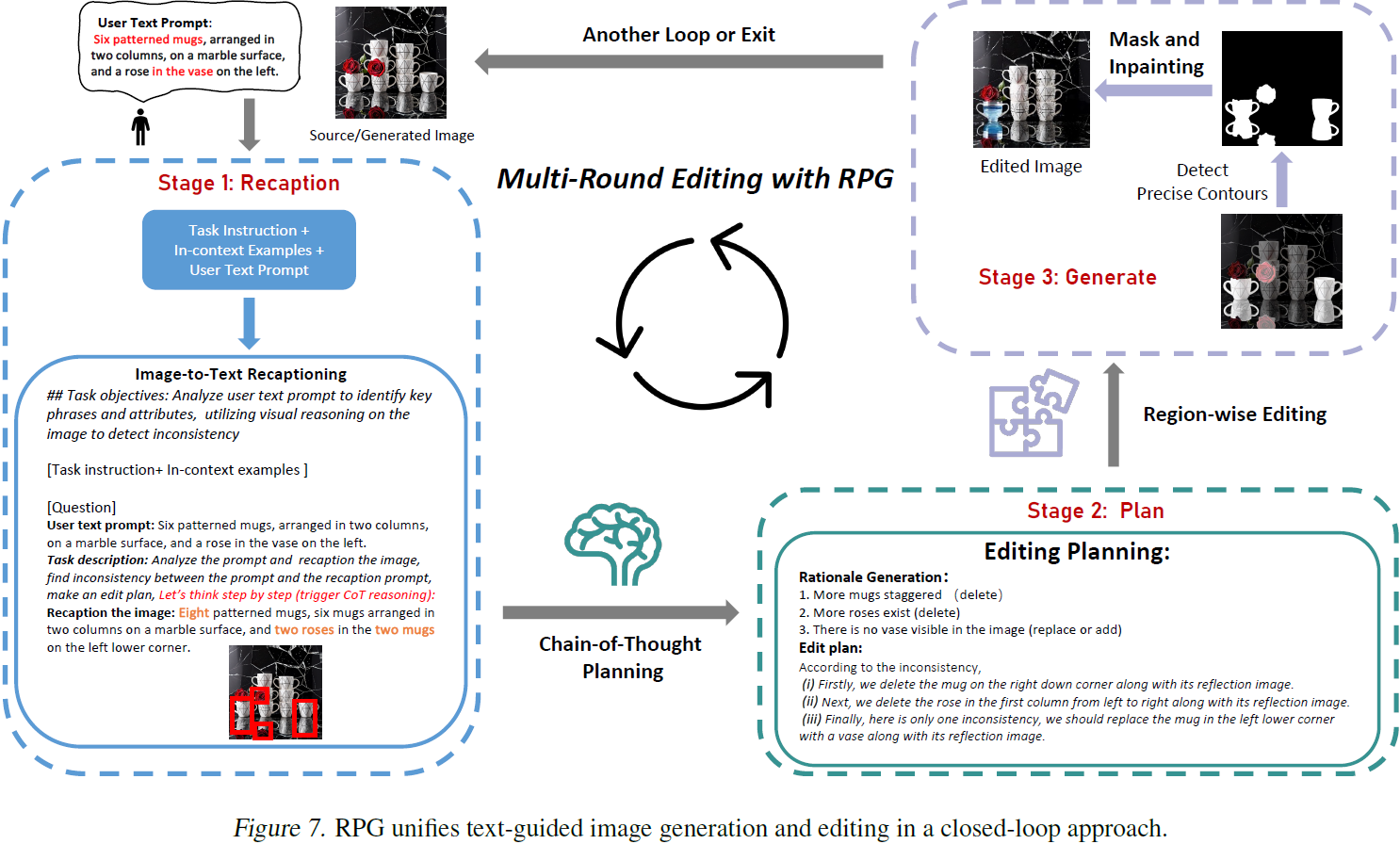
扩散模型在文本到图像生成和编辑方面表现出卓越的性能。然而,现有方法在处理涉及多个对象、多个属性和关系的复杂文本提示时通常面临挑战。在本文中,我们提出了一种全新的无训练文本到图像生成/编辑框架,即重新标注、规划和生成 ???????( Recaption,Plan and Generate,RPG),利用多模态 LLM?强大的思维链推理能力,以增强文本到图像扩散模型的组合性。我们的方法将 MLLM 作为全局规划器(global planner),将生成复杂图像的过程分解为在子区域内执行多个简单生成任务。我们提出了互补的区域扩散(complementary regional diffusion),以实现按区域组合生成。此外,我们在提出的 RPG 中以闭环方式集成了文本引导的图像生成和编辑,从而增强了泛化能力。大量实验证明,我们的 RPG 在多类别对象组合和文本-图像语义对齐方面优于最先进的文本到图像扩散模型,包括 DALL-E 3 和 SDXL。值得注意的是,我们的 RPG 框架在各种 MLLM 架构(例如 MiniGPT-4)和扩散骨干(例如 ControlNet)上表现出很强的兼容性。
代码:https://github.com/YangLing0818/RPG-DiffusionMaster
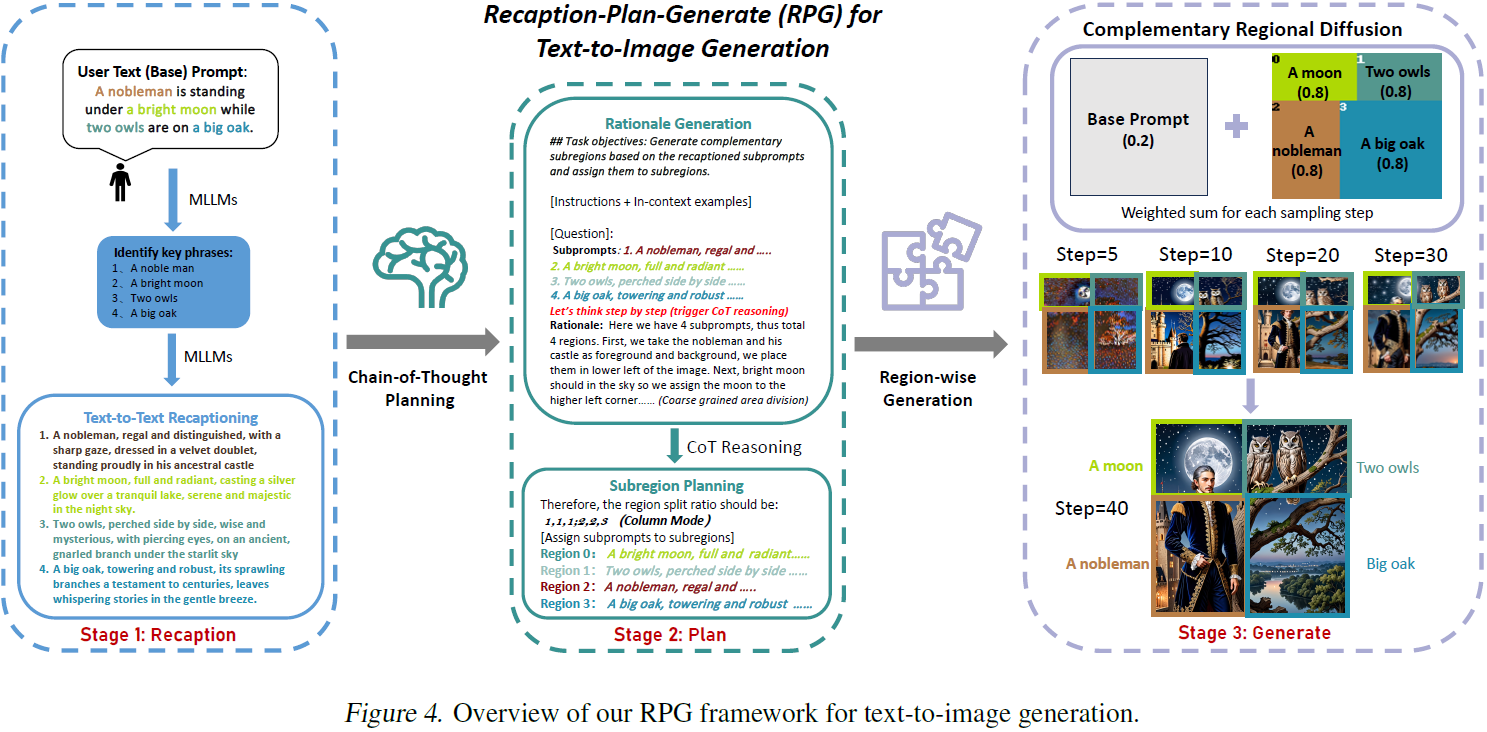
4.2 方法
RPG 提出了三个核心策略:
多模态重新标注(Multimodal Recaptioning): 我们专注于将文本提示转化为高度描述性的提示,提供信息丰富的提示理解和在扩散模型中的语义对齐。我们使用 LLM 将文本提示分解为不同的子提示,并用更详细的描述重新说明它们。我们使用 MLLM 自动重新描述输入图像,以识别生成图像和目标提示之间的语义差异。
思维链规划(Chain-of-Thought Planning): 在一种开创性的方法中,我们将图像空间划分为互补的子区域,并为每个子区域分配不同的子提示,将组合生成任务分解为多个更简单的子任务。通过精心制定任务说明和上下文示例,我们利用 MLLM 的强大思维链推理能力进行高效的区域划分。通过分析重新描述的中间结果,我们生成详细的解释和准确的指导,用于后续图像组合。
互补的区域扩散(Complementary Regional Diffusion): 基于计划的不重叠子区域及其相应的提示,我们提出了互补的区域扩散,以增强组合文本到图像生成的灵活性和精度。具体而言,我们在指定的矩形子区域内由子提示引导独立生成图像内容,然后用一个调整大小和连接的方法,在空间上合并它们。这个区域特定的扩散有效地解决了重叠图像内容冲突的挑战。此外,我们通过采用基于轮廓的区域扩散将该框架扩展到适应编辑任务,从而实现对待修改的不一致区域的精确操作。




4.3 结果




本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 书店网站(JSP+java+springmvc+mysql+MyBatis)
- 集合高级面试题
- 一篇博客读懂排序
- windows11新装机,简单评测系统自带软件(基本涵盖日常所需应用)
- CSC8012_Software Development Techniques and Tools
- 线程的同步和互斥学习笔记
- OpenCV与YOLO学习与研究指南
- PHP常用符号和函数
- C语言中的变量与scanf介绍(干货)
- 不同协议间通信(重发布)