C++继承
目录
木叶飞舞之处,火亦生生不息?

一、继承的概念及定义
1.继承概念
1.
继承是面向对象语言进行代码复用的一种手段,以前我们所接触的代码复用都是函数复用,譬如模拟实现vector的时候,尾插尾删都是复用了insert和erase接口。而继承提供的是一种类设计层次的代码复用,在原有类中增加扩展并实现新的功能,这样所产生的类叫做派生类或子类,原有类被称为基类或父类。
2.
例如下面代码中的student和teacher都可以继承person类,老师和学生不同的是学生是学号_stuid,老师是工号_jobid,但是相同的是老师和学生都有年龄和姓名,所以可以在原有person类的基础上增加新特性继承person类。
3.
继承过后,基类的成员函数和变量都变为子类的一部分,在子类中可以访问到基类的成员函数或变量。
?
#include <iostream>
#include <string>
using namespace std;
class Person
{
public:
void Print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
protected:
string _name = "peter"; // 姓名
int _age = 18; // 年龄
};
// 继承后父类的Person的成员(成员函数+成员变量)都会变成子类的一部分。这里体现出了Student和Teacher复用了Person的成员。
//下面我们使用监视窗口查看Student和Teacher对象,可以看到变量的复用。调用Print可以看到成员函数的复用。
class Student : public Person
{
protected:
int _stuid; // 学号
};
class Teacher :public Person
{
protected:
int _jobid; // 工号
};
int main()
{
//Person叫做父类或基类,Student和Teacher叫做子类或派生类
Student s;
Teacher t;
s.Print();
t.Print();
return 0;
}

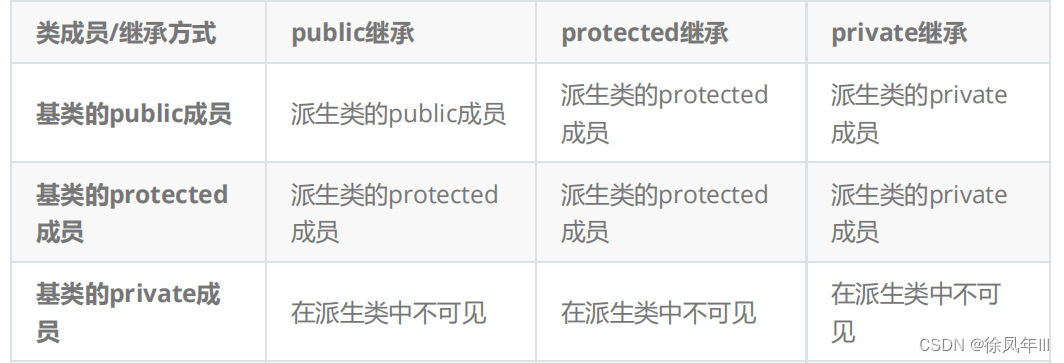
?2.继承关系和访问限定符
继承定义

继承关系和访问限定符?

继承基类成员访问方式的变化?
1.
基类的private成员无论以任何方式继承到子类,子类都是无法访问到基类的private成员的,能够访问到基类的private成员的只有基类内部才可以。
如果基类的某些成员不想被类外面访问到,但是允许子类访问,那就将基类成员设置为protected。从这里就可以看出protected限定符是为了继承的特性才被设计出的,否则如果没有继承这种特性,公有和私有两种其实就已经够用了。
除基类的私有成员无论以任何方式被继承都无法被访问外,其他成员和继承方式都遵循最小权限的原则,公有>保护>私有,在两种权限中找出最小权限,则基类的成员访问限定符被继承到子类后的访问限定符为此最小权限。
2.
如果不显示写出继承方式,则class定义的类默认是私有继承,struct定义的类默认是公有继承,不过最好还是显示的写出继承方式。
3.
实际运用中,公有继承最为常见,私有继承和保护继承并不常见,因为你继承的目的就是想让子类能够访问到基类的某些成员,并且保护继承下来的成员只能在派生类中进行使用,派生类外都无法访问到基类的公有成员函数,所以实际中扩展维护性不强,采用公有继承最为常见,几乎很少使用私有和保护继承。
二.基类和派生类对象赋值转换

class Person
{
protected :
string _name; // 姓名
? ?string _sex; ?// 性别
? ?int _age; // 年龄
};
class Student : public Person
{
public :
int _No ; // 学号
};
void Test ()
{
Student sobj ;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj ;
Person* pp = &sobj;
Person& rp = sobj;
? ?
//2.基类对象不能赋值给派生类对象
? ?sobj = pobj;
}三、继承中的作用域
class Person
{
protected:
string _name = "小李子"; // 姓名
int _num = 111; // 身份证号
};
class Student : public Person
{
public:
void Print()
{
cout << " 姓名:" << _name << endl;
cout << " 身份证号:" << Person::_num << endl;//可以指定类域访问Person类里面的_num成员变量。
cout << " 学号:" << _num << endl;
//这里默认访问的是子类的成员,未指定作用域访问限定符时,编译器采用就近原则,如果自己的所在作用域有,则直接使用。
//如果局部有,就直接用局部。局部没有,编译器才会去全局找。
}
protected:
int _num = 999; // 学号:同名成员变量
};
void Test1()
{
Student s1;
s1.Print();
};
int main()
{
Test1();
return 0;
}

1.
上面所说的隐藏是针对于成员变量名相同时的隐藏,下面这种隐藏是对于成员函数名的隐藏,只要函数名相同,无论参数列表是否相同都会构成隐藏,如果不显示指定基类的域访问限定符,则调用同名函数时,编译器优先会调用派生类的隐藏函数。这叫就近原则。
2.
需要额外注意一点,有的人可能会以为当参数列表不同,函数名相同时,两个函数不是正好构成重载函数了吗?答案是错误,因为构成重载函数的前提是必须在同一作用域,基类和派生类是两个不同的域,所以并不构成重载,而是构成隐藏。?
?四、派生类的默认成员函数
1.
派生类的构造函数只能调用基类的构造函数来初始化基类的那部分成员,不能在自己的构造函数里面初始化基类成员,值得注意的是,如果基类有默认构造函数,那我们不需要管基类成员的初始化工作,只要把派生类自己的成员在构造函数里面初始化即可,因为编译器会自动调用基类成员的默认构造。
但如果基类没有合适的默认构造,那则必须在派生类的初始化列表显示调用基类的有参构造函数进行基类成员的初始化。
2.
拷贝构造函数与构造不同,必须在派生类的拷贝构造的初始化列表处显示调用基类的拷贝构造,完成基类成员的复制。在传参时有人可能会有疑问,调用基类的拷贝构造该如何将子类中基类成员提取出来呢?这里就用到上面所说的切割向上赋值,正好可以完成基类成员的复制工作。
3.
复制重载和拷贝构造有一点不一样,由于复制重载函数名在基类和子类中函数名相同,所以在调用基类的复制重载时必须指定基类域,否则会导致死循环调用子类复制重载,最终导致堆栈溢出。但和复制重载相同的是,在调用基类赋值函数进行传参时,所采取的策略依旧是向上切割赋值。
4.
派生类对象初始化时,先调用基类构造再调用子类构造,在析构时与栈结构相同,先调用子类的析构函数,在子类析构函数调用完毕时,编译器会自动调用基类的析构函数。所以说,派生类中其他的三个默认成员函数都必须我们自己手动调用基类的对应默认成员函数,但是析构函数不需要我们自己调用,编译器在子类析构调用结束后会自动调用基类析构。
5.
额外多说一点的是,如果我们自己调用父类析构函数的话,则必须指明父类域,因为编译器会把析构函数名特殊处理成destructor(),所以如果不指定类域就会出现派生类的析构函数内部调用自己的析构函数,则编译器会报错。
6.
最后归纳一下,将派生类分为三部分,内置类型,自定义类型,基类成员,
基类成员统一调用基类成员函数进行处理,除析构不需要显式调用外,其他都需要显示调用。
对于内置类型则构造析构不处理,赋值和拷贝进行浅拷贝。
自定义类型成员会被自定义类型对应的默认成员函数来处理。
?
class Person
{
public:
Person(const char* name )
: _name(name)
{
cout << "Person()" << endl;
}
Person(const Person& p)
: _name(p._name)
{
cout << "Person(const Person& p)" << endl;
}
Person& operator=(const Person & p)
{
cout << "Person operator=(const Person& p)" << endl;
if (this != &p)
_name = p._name;
return *this;
}
~Person()
{
cout << "~Person()" << endl;
}
protected:
string _name; // 姓名
};
//派生类中:
// 1、构造函数,父类成员会默认调用父类的构造函数完成初始化。
class Student : public Person
{
public:
Student(const char* name, int num)
//:_name(name)//规定死了,如果要初始化基类成员,必须调用基类的构造函数。
//如果父类没有合适的默认构造,则必须在子类中调用有参的基类构造完成基类成员的初始化。
:Person(name)
,_num(num)
{}
Student(const Student& s)
:Person(s)//基类成员要拷贝,直接传派生类对象过去,会发生向上切割赋值。
,_num(s._num)
{}
Student& operator=(const Student& s)
{
if (this != &s)//不要自己给自己赋值
{
Person::operator=(s);//发生切割或切片,将子类中的父类成员进行赋值,父子类的赋值重载构成隐藏,会默认调就近的类
_num = s._num;
}
return *this;
}
~Student()
{
//Person::~Person();//编译器当作调用基类的destructor
//1.子类析构和父类析构构成隐藏关系(由于多态的关系需求,所有的析构函数都会特殊处理成destructor函数名)
//2.调用了一次Person的构造,两次析构,其实是因为我们显示调用了Person的析构,编译器自己会自动调用析构,所以调2次
// 子类先析构,父类后析构。可得结论:子类析构函数不需要显示调用父类析构,依靠编译器之后的自动调用即可。
cout << "~Student()" << endl;
//在子类对象析构函数调用之后,编译器又会自动调用父类析构,这是编译器的默认行为。
//构造顺序和析构顺序相反,基类成员先构造,则析构时基类就后析构。
}
protected:
int _num; //内置类型不处理
string _address;//调用string自己的无参构造进行处理
//继承下来的基类成员调用基类对应函数进行处理
};
int main()
{
//Student s1;//如果子类s1里面什么都没有,则这里会调用父类的析构和无参构造。
//Student s1("小李子", 18);
//Student s2(s1);//子类中父类成员会调用父类的拷贝构造。
把子类分为三个部分,内置类型,自定义类型,父类的那一部分,父类那一部分规定死只能调用父类的成员函数。
//Student s3("张三", 20);
//s1 = s3;
//Person p = s1;//调用拷贝构造,发生切片赋值
//Person& rp = s1;//不需要用const引用,这里是天然的赋值过程。
Student s("张三",18);
}
五.继承与友元
1.
父类和某个函数的友元关系不能继承到子类上去,比如下面代码中Display是父类Person的友元函数,可以访问父类的保护成员,但是继承到子类后Display并不可以访问子类的保护成员。
所以基类的友元不能访问子类的私有和保护成员。
class Student;
class Person
{
public:
friend void Display(const Person& p, const Student& s);
protected:
string _name; // 姓名
};
class Student : public Person
{
protected:
int _stuNum; // 学号
};
void Display(const Person& p, const Student& s)
{
cout << p._name << endl;//Display是Person的友元函数,但不是Student的友元函数。
//cout << s._stuNum << endl;//所以可以访问_name但不能访问_stuNum
}
int main()
{
Person p;
Student s;
Display(p, s);
}

基类的友元访问子类的函数会报错?
?六、继承与静态成员
基类定义了static静态成员,则整个继承体系里面只有一个这样的成员。无论派生出多少个子类,都只有一个static成员实例
#include <iostream>
using namespace std;
class Person
{
public:
Person() { ++_count; }
protected:
string _name; // 姓名
public:
static int _count; // 统计人的个数。
};
int Person::_count = 0;
class Student : public Person
{
protected:
int _stuNum; // 学号
};
class Graduate : public Student
{
protected:
string _seminarCourse; // 研究科目
};
void TestPerson()
{
Student s1;
Student s2;
Student s3;
Graduate s4;
cout << " 人数 :" << Person::_count << endl;
Student::_count = 0;
cout << " 人数 :" << Person::_count << endl;
}
在以上创建对象的过程中,Person 类的构造函数会被调用,每次创建一个对象,_count 会增加一次。由于 Student 和 Graduate 都是 Person 的派生类,因此它们的构造函数也会自动调用基类 Person 的构造函数,导致 _count 增加。
然后,通过 Student::_count = 0; 将 Student 类的 _count 设置为零。这不会影响 Person::_count,因为 _count 是静态成员变量,它在整个类层次结构中是共享的。
?
七.复杂的菱形继承
了解一下即可
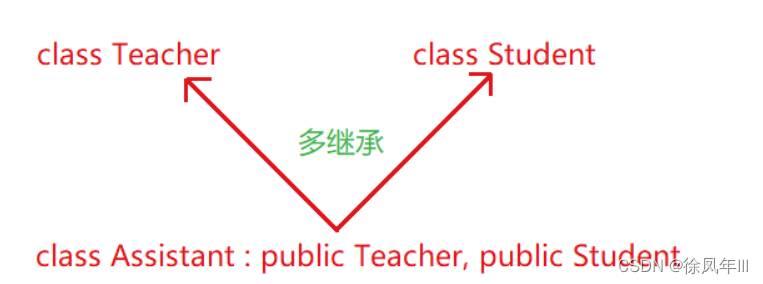
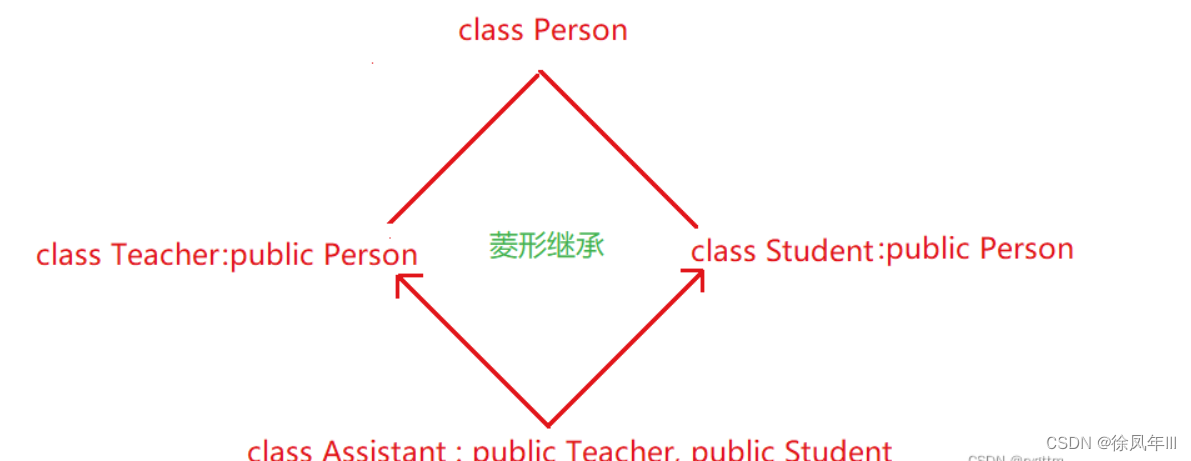 ?
?
_name被继承到Teacher和Student之后,再被菱形继承到Assisant,则Assisant中会存在两份_name,则Assisant在访问_name成员变量时就会出现二义性,因为Teacher和Student都有_name,所以如果从访问角度来讲,避免二义性就必须通过指定类域来解决,但即使二义性问题被解决之后,数据冗余的问题依旧无法得到处理,因为Assisant的名字不能有两个吧?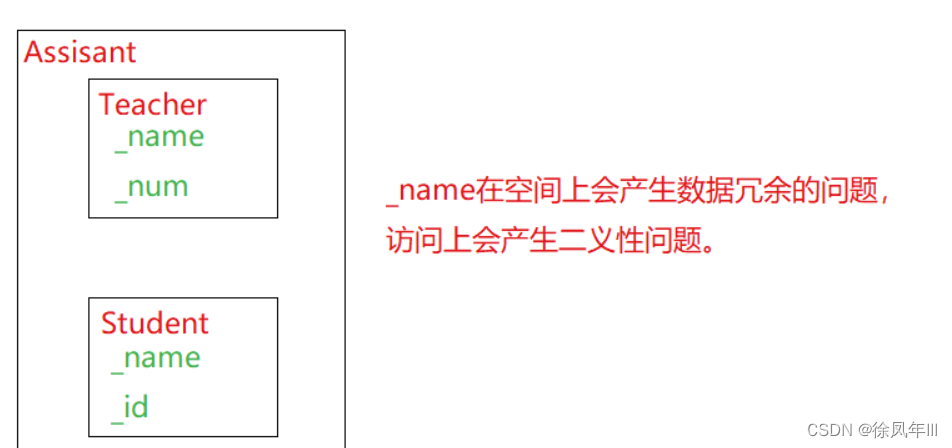
C++为了解决菱形继承带来的问题采用了虚拟继承的方式来进行解决,即在菱形继承的腰部位置采用virtual继承来解决菱形继承的大坑。
???????
?
//有多继承本身没什么问题,但有多继承可能就会有菱形继承,菱形继承会引发数据冗余和二义性。
class Person
{
public:
string _name; // 姓名
};
class Student : virtual public Person
{
protected:
int _num; //学号
};
class Teacher : virtual public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Student, public Teacher
{
protected:
string _majorCourse; // 主修课程
};
// 空间角度来讲是数据冗余,访问角度来讲是二义性。数据冗余会导致空间浪费
int main()
{
Assistant a;
a._name = "小张";//这里就会出现二义性,访问的_name是属于Person的哪个派生类的,是Student还是Teacher呢?
a.Teacher::_name = "张老师";
a.Student::_name = "张三";//指定访问类域也只是解决了二义性,还没有解决数据冗余的问题。
cout << a._name << endl;//虚拟继承之后,_name就只有一份了。
}
八、继承和组合(继承是is-a,组合是has-a)
1.
如果组合和继承都可以用的话,则优先使用组合而不是继承。
public继承可以认为是is-a的关系,即每一个派生类对象都是一个基类对象,因为基类成员都在派生类里面。而组合可以认为是has-a的关系,如果B里面组合了A对象,则每一个B对象中都会有一个A对象。
2.
继承允许你根据基类的实现来定义派生类的实现。这种通过生成派生类的复用通常被称为白箱复用(white-box reuse)。术语“白箱”是相对可视性而言:在继承方式中,基类的内部细节对子类可见 。继承在一定程度上破坏了基类的封装,基类的改变,对派生类有很大的影响。派生类和基类间的依赖关系很强,耦合度高。
3.
对象组合是类继承之外的另一种代码复用选择。新的更复杂的功能可以通过组装或组合对象来获得。对象组合要求被组合的对象具有良好定义的接口。这种复用风格被称为黑箱复用(black-box reuse),因为对象的内部细节是不可见的。对象只以“黑箱”的形式出现。组合类之间没有很强的依赖关系,组合对象的改变对类本身的影响是比较小的,所以组合的耦合度低。优先使用对象组合有助于保持每个类都被良好的封装。
4.
实际中尽量多去用组合。组合的耦合度低,代码维护性好。不过继承也有用武之地的,有些关系就适合继承那就用继承,另外要实现多态,也必须要继承。
组合就是把一个类的对象放到另一个类中,作为该类的一个成员变量,继承就是子类继承父类,拿到父类的所有成员函数和成员变量的值,子类还可以继续添加其他成员变量或成员函数。
?九、经典笔试面试题
1.什么是菱形继承?菱形继承的问题是什么?
菱形继承就是在多继承的基础上,多继承的父类还有一个共同的父类,这就会导致菱形继承的出现,基类中的成员在多继承的子类中会出现多份数据占用内存的情况,即数据冗余问题的出现,并且在访问多继承子类的基类成员时,如果不指定基类的派生类类域,则还会出现二义性的问题。
?2.什么是菱形虚拟继承?如何解决数据冗余和二义性的
菱形虚拟继承即在原有菱形继承上,对腰部类采用virtual继承的方式来解决菱形继承所产生的问题,在内存空间中,腰部类的派生类不再存储两份冗余的数据,而是仅仅只存储虚基表指针,如果腰部类想要找到这份冗余的数据,则可以通过虚基表指针所指向的虚基表中虚基类成员的地址偏移量来寻找虚基类成员。
内存空间中只有一份数据时,无论是否指定腰部类类域,访问的都是这一份虚基类成员数据。
?
3.继承和组合的区别?什么时候用继承?什么时候用组合??
继承是子类继承父类,组合是一个类的成员变量是另一个类实例化出来的对象。
继承可以看作是白箱复用,即父类内部细节在子类全部都是可视化的,破坏了父类的封装性,一旦父类发生某种改变则子类大概率需要跟着修改,父类和子类的依赖关系较强,耦合度较高,代码维护性较低。
组合可以看作是黑箱复用,组合对象的内部实现细节并不暴露给组合对象的所在类,而只能通过对象提供的public接口进行对象内部数据的访问,两个类的耦合度更低一些,代码维护性较高。
继承和组合都可以使用时优先使用组合,如果只能用继承或继承更加合适的时候我们才会用继承,譬如要实现多态,则必须使用继承,另外如果某些情景下,真的较为适合使用继承,那我们就选继承不选组合。
————————————————
参照了下面大佬的文章,谢谢大家观看
原文链接:https://blog.csdn.net/erridjsis/article/details/129477726
?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ssm/php/node/python大学生心理咨询系统【计算机毕设】
- 威士忌的起源与历史:从古代酿酒工艺到现代产业的发展
- 循环神经网络中的梯度消失或梯度爆炸问题产生原因分析
- 什么情况下不应该使用 LockWindowUpdate ?
- QEMU源码全解析 —— virtio(1)
- Java中的装箱和拆箱
- 09- OpenCV:图像上采样和降采样
- Linux内存管理:(八)页面迁移
- 【工作技术栈】基于注解的redis缓存清除工具(无业务入侵)和基于注解的redis分布式锁(支持SPEL细粒度)
- 广东韶关一木材屋棚凌晨突发大火 富维烟火识别避免财产损失