AAAI 2024 | TEx-Face,5秒内按需生成照片级3D人脸
本文介绍一篇来自浙江大学ReLER实验室的工作,"Controllable 3D Face Generation with Conditional Style Code Diffusion",目前该文已被AAAI 2024录用。


论文题目: Controllable 3D Face Generation with Conditional Style Code Diffusion
论文链接:https://arxiv.org/abs/2312.13941?
代码链接:?https://github.com/sxl142/TEx-Face?
项目主页:TEx-Face
01. 研究动机
本文的核心出发点是,探索一种只需要单次优化的多条件控制的3D人脸生成模型。
目前的一些经典的Text-to-3D的工作,他们往往针对一个特定的物体(由文本描述的)优化一个随机初始化的3D表征,例如Nerf,从而导致耗费较长的优化时间以及只限于单个物体,无法泛化。此外,目前的这类方法还是没有办法做到真实照片级的效果。对于人脸领域,由于处于一个相似的分布,所以完全可以使用一种只需要训练一次的模型而非依赖单个人脸优化的模式来寻求推理时间的减少以及具有一定的泛化性。
另外,虽然目前的无条件3D人脸生成模型已经能够达到照片级的效果了,但是带条件的控制模型还有待探索。考虑到人脸主要由静态的外貌以及动态的表情构成,所以我们以这样的角度切入来设计一种能够受这两种条件控制的3D人脸生成模型。这里我们使用了文本来描述人脸的外貌属性,用3D人脸参数模型FLAME的expression codes来表征动态的表情。
02. 技术构成
基于此,我们将这样的模型解耦成三个部分, 如下图所示,
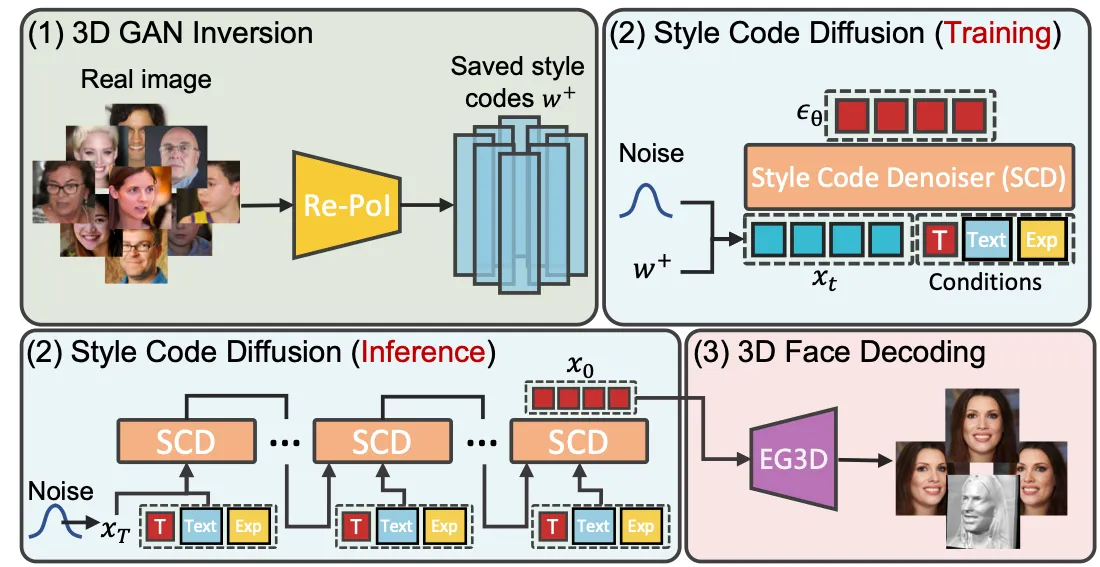
2.1 3D GAN Inversion.
GAN Inversion是一种存在已久的技术。在2D领域,依托于StyleGAN,广泛地被用于图像重构和图像编辑中。它是指在训练完成的GAN中,寻找接近于输入图像所对应的style codes的一种技术,即能够用寻找到的style codes还原真实图像,也就是我们能利用这样一组style codes来表征图像。
目前主要分为两种体系:
-
基于单个优化的方法,
-
基于整体一次优化的方法。
单个优化的方法视觉效果更好,但是需要更长的优化时间,且无法泛化。整体一次优化的方法只消耗很少的推理时间,具有一定的泛化性,适合大量获取style codes。
在3D领域,大多数的Inversion方法是基于单个优化的。由于需要大量地获取style codes为这套框架的下一步的扩散模型提供数据,所以我们需要设计一种整体一次优化的方法。然而,简单地扩展2D的整体优化的方法到3D领域,如Style transformer,会出现槽糕的新视角的合成,尤其是当输入图片的视角不是正面的时候。如下图所示,
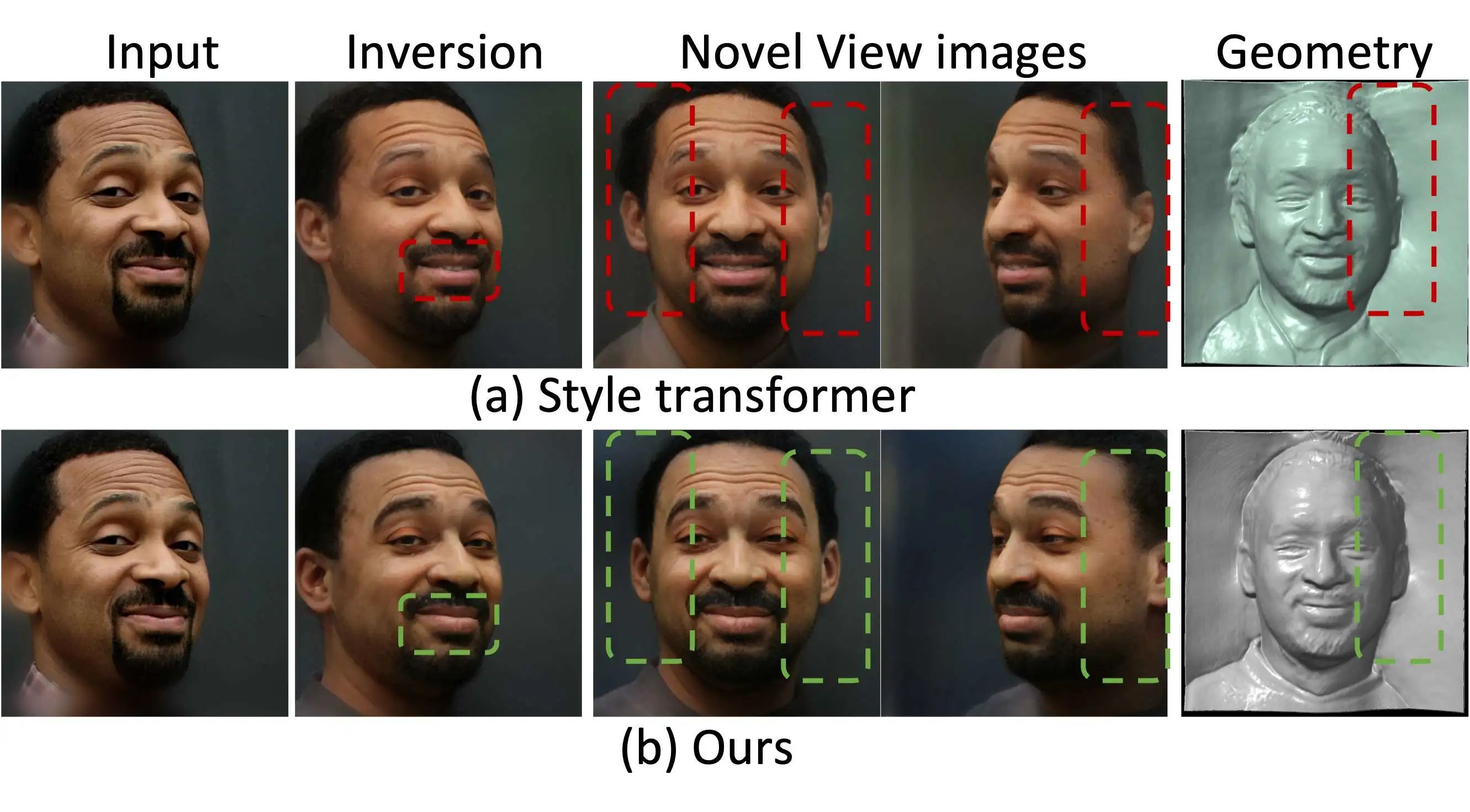
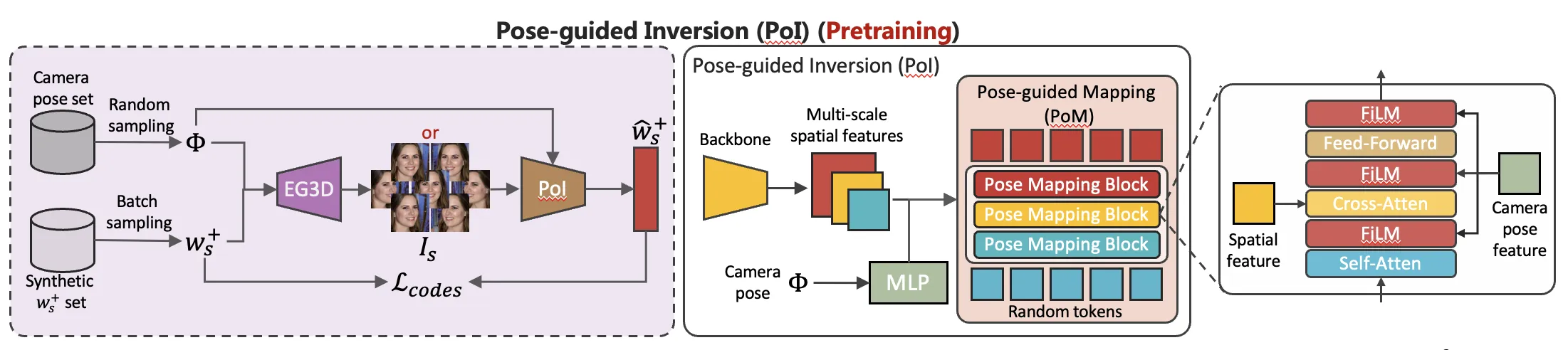
这促使我们去设计一种算法能够避免这样的情况出现。设计主要思想来源于我们希望同一个人的不同视角下的图片经过编码得到的style codes应该具有一致性,是尽量相同的。基于此,我们选取了正面视角下的style codes作为基准,设计了一个由相机参数引导的Inversion模型,能够将不同的视角下的图片特征经过相机参数引导后变换到与正面图像相似的特征进而得到尽量一致的style codes。然而由于缺少大量的多视角的数据集,我们通过训练好的3D人脸生成网络来制造这样的数据用于训练,如下图所示。
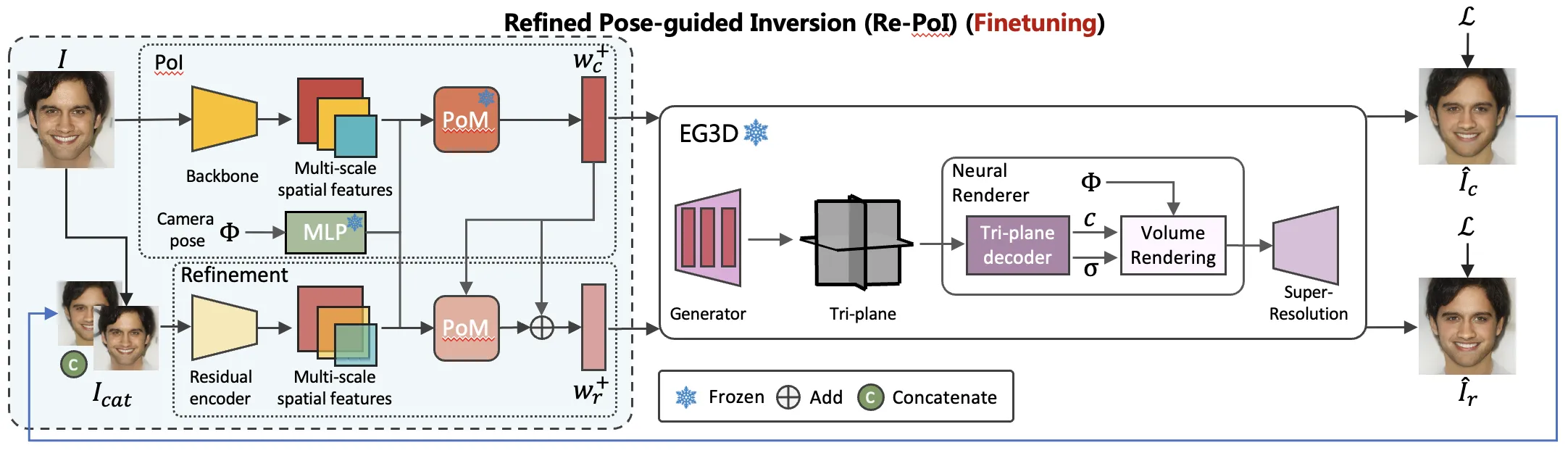
此外,在这样合成的数据集上学习与真实数据集有所差异,所以我们需要进一步在真实数据上finetune模型。这里我们固定住了相机引导模块所学的参数以保留它继续拥有特征映射的能力,只学习调整backbone的参数。最后,我们还设计了提纯模块,将第一阶段的输出与真实图像的差值作为输入,以提高最终的style codes的表征能力。如下图所示。
2.2 Style Code Diffusion.
目前,扩散模型在各个领域都被证明了其强大的生成能力。鉴于此,我们希望能够利用这样的模型将我们所需的条件即静态的外貌和动态的表情有效地注入上一步所得的style codes中,以此得到一个可控的多条件的生成模型。为此我们设计了style code denoiser,来解耦地注入对应的条件,如下图所示。
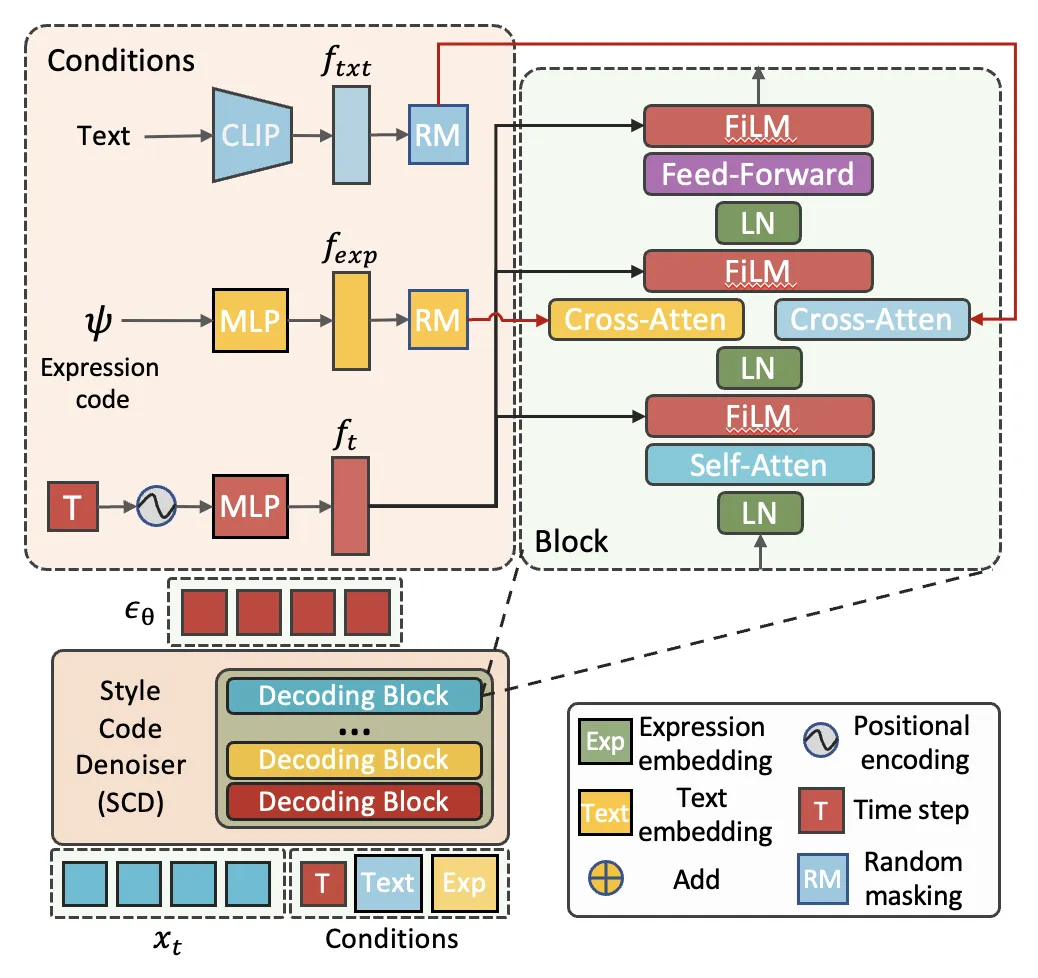
2.3 3D Face Decoding.
这一步,我们需要将注入了条件的style codes解码成3D人脸。这需要用到预训练的无条件的3D人脸模型,由于这套框架的生成能力很大程度上依赖于此,所以选用一种更为强大的模型尤为重要,这里我们选择了EG3D,它拥有和StyleGAN相似的架构,有解耦地更好的表征空间。
03. 实验结果
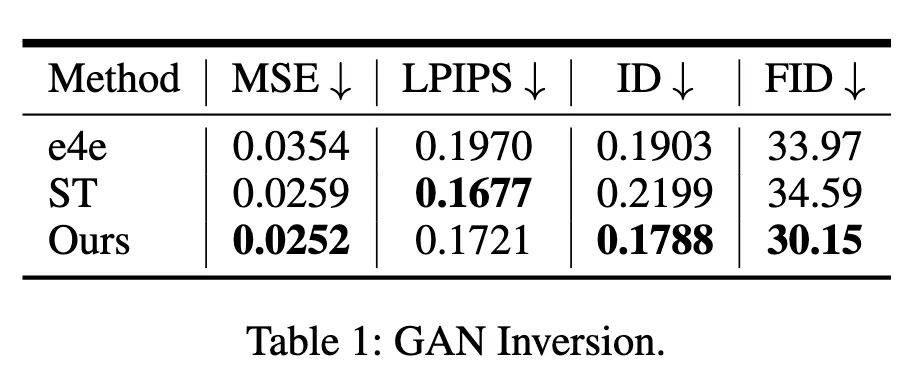
3.1 在GAN Inversion上的定量结果
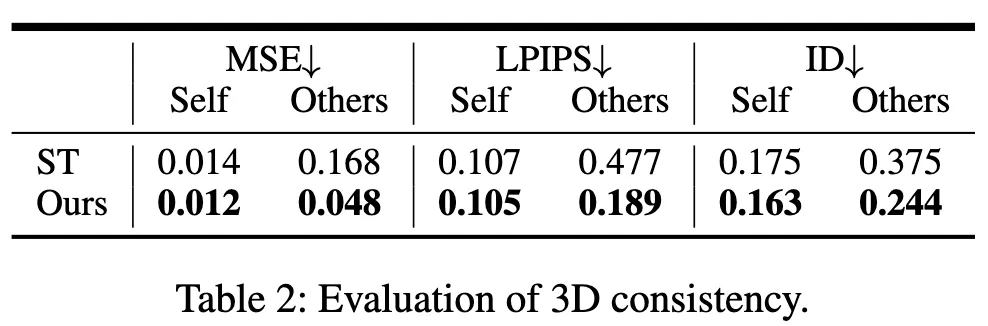
如下图所示,我们的方法都取得了更好的性能。Table2的Others,衡量的是新视角生成的效果,结果显示我们的设计能显著地提升性能与简单地扩展2D方法到3D相比。
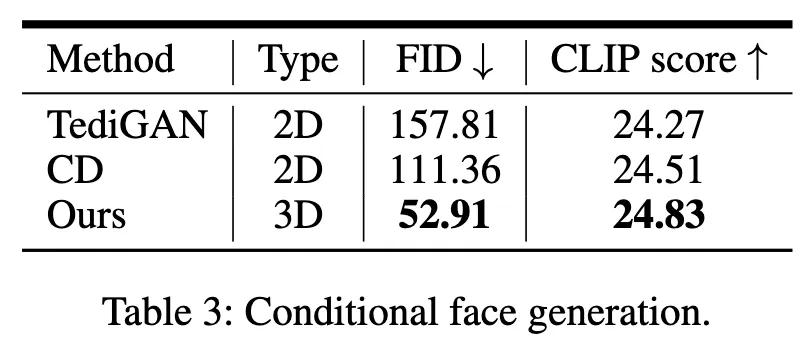
3.2 在有条件生成上的定量结果
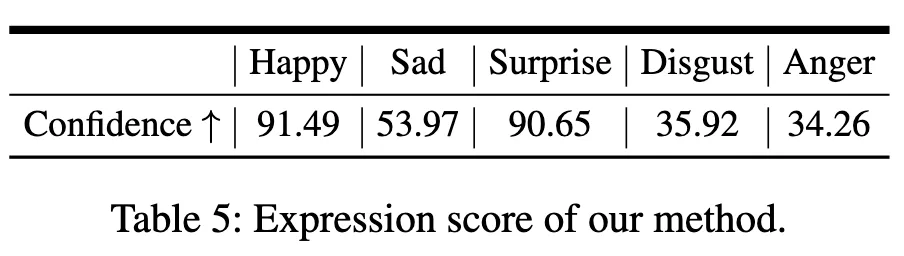
如下图所示,我们的模型在FID,和衡量图文匹配的CLIP score上都取得了最优的性能。此外,生成对应表情的分数是由一个表情识别的模型进行打分的,如Table 4所示,结果显示我们能实现一定程度上的表情控制。
3.3 可视化结果
由下图所示,我们的效果更接近照片级,并能有效地受到文本的控制。

04. 结语
我们提出了一种合理可行的框架TEx-Face, 能够多条件地控制生成3D人脸并只需要几秒的时间。从可视化上,能够生成与文本和给定表情相一致的3D人脸。但这里还有许多存在的问题,如如何设计更好的模型获取style codes。更多的细节与结果请阅读我们的论文,感谢阅读。
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区?
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- AI 绘画Stable Diffusion 研究(十一)sd图生图功能详解-美女换装
- 福音!Selenium使用WebDriverManager以后,再也不用被浏览器driver与浏览器版本不匹配的问题折磨了!
- 深度学习优化器Optimizer-SGD、mSGD、AdaGrad、RMSProp、Adam、AdamW
- 库架合一立体仓库|海格里斯HEGERLS智能冷链冷库四向穿梭车仓储解决方案
- 【C++项目报错】Cannot combine with previous ‘void‘ declaration specifier 【及解决方法】
- react-native生命周期函数
- Spring5-单独学习Spring5
- 基于Django框架的旅游推荐系统构建-计算机毕业设计源码82884
- (每日持续更新)jdk api之ByteArrayInputStream基础、应用、实战
- Python3 range() 函数