数据库SELECT语句
文章目录
一、检索数据
SELECT语句
- 检索单个列
SELECT prod_name FROM products; - 检索多个列
SELECT prod_id, prod_name, prod_price FROM products; - 检索所有列
SELECT * FROM products; - 检索不同的行
DISTINCT
SELECT DISTINCT vend_id FROM products; - 限制结果 LIMIT
SELECT prod_name
FROM products
LIMIT 5,5;
带一个值的LIMIT总是从第一行开始,给出的数为返回的行数。
带两个值的LIMIT可以指定从行号为第一个值的位置开始。
- 使用完全限定的表名
SELECT products.prod_name
FROM products;
二、排序检索
ORDER BY子句,根据需要排序检索出的数据。
- 排序数据
SELECT prod_name
FROM products
ORDER BY prod_name;
通过非选择列进行排序:通常,ORDER BY子句中使用的列将是为显示所选择的列。但是,实际上并不一定要这样,用非检索的列排序数据是完全合法的。
- 按多个列排序
SELECT prod_id, prod_price, prod_name
FROM products
ORDER BY prod_price, prod_name;
在按多个列排序时,排序完全按所规定的顺序进行。
换句话说,对于上述例子中的输出,仅在多个行具有相同的prod_price
值时才对产品按prod_name进行排序。如果prod_price列中所有的值都是唯一的,则不会按prod_name排序
- 指定排序方向
SELECT prod_id, prod_price, prod_name
FROM products
ORDER BY prod_price DESC, prod_name;
DESC关键字只应用到直接位于其前面的列名。
在上例中,只对prod_price列指定DESC,对prod_name列不指定。因此,prod_price列以降序排序,而prod_name列(在每个价格内)仍然按标准的升序排序。
与DESC相反的关键字是ASC(ASCENDING),在升序排序时可以指定它。但实际上,ASC没有多大用处,因为升序是默认的(如果既不指定ASC也不指定DESC,则假定为ASC)。
- ORDER BY和LIMIT的组合
SELECT prod_price
FROM products
ORDER BY prod_price DESC
LIMIT 1;
三、过滤数据
- 使用WHERE子句
SELECT prod_name, prod_price
FROM products
WHERE prod_price = 2.50;
这条语句从products表中检索两个列,但不返回所有行,只返
回prod_price值为2.50的行
WHERE子句的位置:在同时使用ORDER BY和WHERE子句时,应
该让ORDER BY位于WHERE之后,否则将会产生错误
- WHERE子句操作符
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 | |
| >= | 大于等于 |
| BETWEEN | 在指定两个值之间 |
- 单个值检查
SELECT prod_name, prod_price
FROM products
WHERE prod_price < 10;
- 范围值检查
SELECT prod_name, prod_price
FROM products
WHERE prod_price BETWEEN 5 AND 10;
- 空值检查
SELECT语句有一个特殊的WHERE子句,可用来检查具有NULL值的列。
这个WHERE子句就是IS NULL子句。
SELECT cust_id
FROM customers
WHERE cust_email IS NULL;
四、数据过滤
4.1 组合WHERE子句
为了进行更强的过滤控制,MySQL允许给出多个WHERE子句。这些子
句可以两种方式使用:以AND子句的方式或OR子句的方式使用。
1. AND操作符
SELECT prod_id, prod_price, prod_name
FROM products
WHERE vend_id = 1003 AND prod_price <= 10;
AND:用在WHERE子句中的关键字,用来指示检索满足所有给定条件的行。
2. OR操作符
SELECT prod_id, prod_price, prod_name
FROM products
WHERE vend_id = 1003 OR vend_id = 1002;
OR:WHERE子句中使用的关键字,用来表示检索匹配任一给定
条件的行。
3. 计算次序
同时使用 OR和 AND 操作符
SELECT prod_id, prod_price, prod_name
FROM products
WHERE vend_id = 1003 OR vend_id = 1002 AND prod_price >= 10;
结果
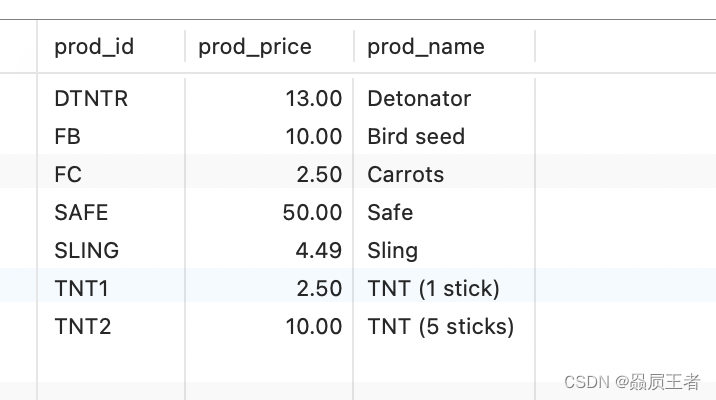
SQL(像多数语言一样)在处理OR操作符前,优先处理AND操作符。当SQL看到上述WHERE子句时,它理解为由供应商1002制造的任何价格为10美元(含)以上的产品,或者由供应商1003制造的任何产品,而不管其价格如何。
换句话说,由于AND在计算次序中优先级更高,操作符被错误地组合了。
此问题的解决方法是使用圆括号明确地分组相应的操作符。
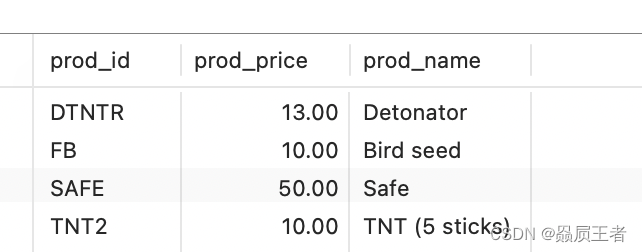
SELECT prod_id, prod_price, prod_name
FROM products
WHERE (vend_id = 1003 OR vend_id = 1002) AND prod_price >= 10;
结果
4.2 IN操作符
IN操作符用来指定条件范围,范围中的每个条件都可以进行匹配。
IN取合法值的由逗号分隔的清单,全都括在圆括号中。
WHERE子句中用来指定要匹配值的清单的关键字,功能与OR相当。
SELECT prod_id, prod_name, prod_price
FROM products
WHERE vend_id IN (1002,1003)
ORDER BY prod_name;
IN操作符优点具体如下。
- 在使用长的合法选项清单时,IN操作符的语法更清楚且更直观。
- 在使用IN时,计算的次序更容易管理(因为使用的操作符更少)。
- IN操作符一般比OR操作符清单执行更快。
- IN的最大优点是可以包含其他SELECT语句,使得能够更动态地建
立WHERE子句。
4.3 NOT操作符
WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所
跟的任何条件。
SELECT prod_id, prod_name, prod_price
FROM products
WHERE vend_id NOT IN (1002,1003)
ORDER BY prod_name;
MySQL中的NOT MySQL支持使用NOT对 IN、BETWEEN 和 EXISTS 子句取反,这与多数其他DBMS允许使用NOT对各种条件取反有很大的差别。
五、用通配符过滤
通配符(wildcard) 用来匹配值的一部分的特殊字符。
搜索模式(search pattern) 由字面值、通配符或两者组合构
成的搜索条件。
LIKE操作符
为在搜索子句中使用通配符,必须使用LIKE操作符。LIKE指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
1. 百分号(%)通配符
在搜索串中,%表示任何字符出现任意次数。
SELECT prod_id, prod_name, prod_price
FROM products
WHERE prod_name LIKE 'jet%';
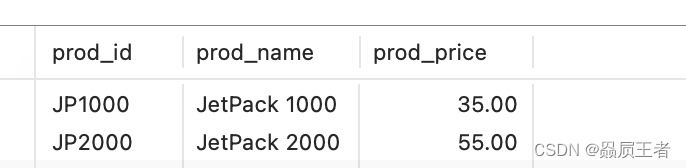
注意尾空格:尾空格可能会干扰通配符匹配。
注意NULL:虽然似乎%通配符可以匹配任何东西,但有一个例外,即NULL。即使是WHERE prod_name LIKE '%'也不能匹配用值NULL作为产品名的行。
2. 下划线(_)通配符
下划线的用途与%一样,但下划线只匹配单个字符而不是多个字符。
SELECT prod_id, prod_name, prod_price
FROM products
WHERE prod_name LIKE '_ ton anvil';
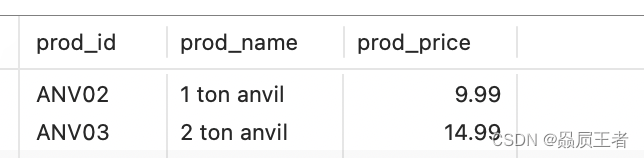
使用通配符的技巧
- 不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
- 在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
- 仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
六、正则表达式搜索
使用 REGEXP 后跟正则表达式
- 基本字符匹配
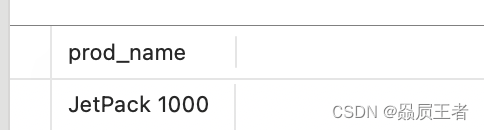
SELECT prod_name
FROM products
WHERE prod_name REGEXP '1000'
ORDER BY prod_name
匹配不区分大小写: MySQL中的正则表达式匹配(自版本
3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大
小写,可使用BINARY关键字,如WHERE prod_name REGEXP
BINARY ‘JetPack .000’。
- 进行OR 匹配
为搜索两个串之一(或者为这个串,或者为另一个串),使用|
SELECT prod_name
FROM products
WHERE prod_name REGEXP '1000|2000'
ORDER BY prod_name

- 匹配几个字符之一
用[和]括起来的字符来完成字符匹配,[]是另一种形式的OR语句
SELECT prod_name
FROM products
WHERE prod_name REGEXP '[123] Ton'
ORDER BY prod_name
正则表达式[123] Ton。[123]定义一组字符,它的意思是匹配1或2或3
- 匹配范围
集合可用来定义要匹配的一个或多个字符。
例如:[0123456789]
下面的式子功能上等同于上述数字列表:
[0-9]
SELECT prod_name
FROM products
WHERE prod_name REGEXP '[1-5] Ton'
ORDER BY prod_name
- 匹配特殊字符
为了匹配特殊字符,必须用\为前导。\-表示查找-,\.表示查找.。
SELECT vend_name
FROM vendors
WHERE vend_name REGEXP '\\.'
ORDER BY vend_name;
\也用来引用元字符(具有特殊含义的字符)
| 元字符 | 说明 |
|---|---|
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 制表 |
| \v | 纵向制表 |
\或\?:多数正则表达式实现使用单个反斜杠转义特殊字符,以便能使用这些字符本身。但MySQL要求两个反斜杠(MySQL自己解释一个,正则表达式库解释另一个)。
- 匹配字符类
| 类 | 说明 |
|---|---|
| [:alnum:] | 任意字母和数字(同[a-zA-Z0-9]) |
| [:alpha:] | 任意字符(同[a-zA-z]) |
| [:blank:] | 空格和制表(同[\t]) |
| [:cntrl:] | ASCII控制字符(ASCII 0到31和127) |
| [:digit:] | 任意数字(同[0-9]) |
| [:graph:] | 与[:print:]相同,但不包括空格 |
| [:lower:] | 任意小写字母(同[a-z]) |
| [:upper:] | 任意大些字母(同[A-Z]) |
| [:print:] | 任意可打印字符 |
| [:punct:] | 既不在[:alnum:]又不在[:cntrl:]中的任意字符 |
| [:space:] | 包括空格在内的任意空白字符(同[\f \n \r \t \v]) |
| [:xdigit:] | 任意十六进制数字(同[a-fA-F0-9]) |
- 匹配多个实例
| 元字符 | 说明 |
|---|---|
| * | 0个或多个匹配 |
| + | 1个或多个匹配(等于{1,}) |
| ? | 0个或1个匹配(等于{0,1}) |
| {n} | 指定数目的匹配 |
| {n,} | 不少于指定数目的匹配 |
| {n,m} | 匹配数目的范围(m不超过255) |
- 定位符
| 元字符 | 说明 |
|---|---|
| ^ | 文本的开始 |
| $ | 文本的结尾 |
| [[:<:]] | 词的开始 |
| [[:>:]] | 词的结尾 |
七、创建计算字段
1. 计算字段
计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT语句内创建的。
2. 拼接字段
在MySQL的SELECT语句中,可使用 Concat()函数来拼接两个列。
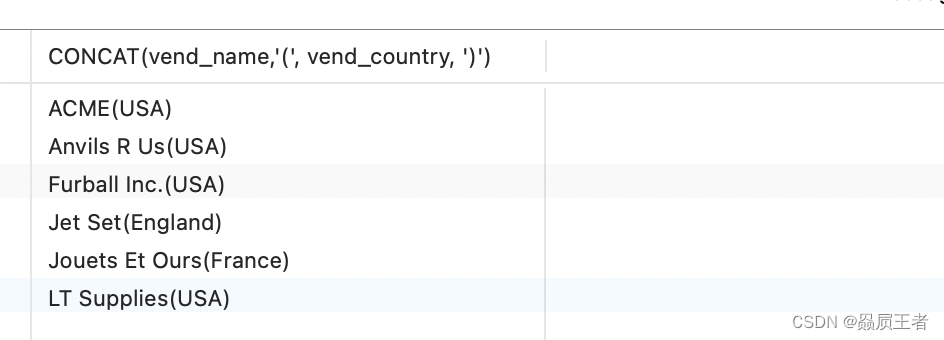
SELECT CONCAT(vend_name,'(', vend_country, ')')
FROM vendors
ORDER BY vend_name;
Trim函数:MySQL除了支持RTrim()(正如刚才所见,它去掉串右边的空格),还支持LTrim()(去掉串左边的空格)以及 Trim()(去掉串左右两边的空格)。
使用别名
别名(alias)是一个字段或值的替换名。别名用AS关键字赋予。
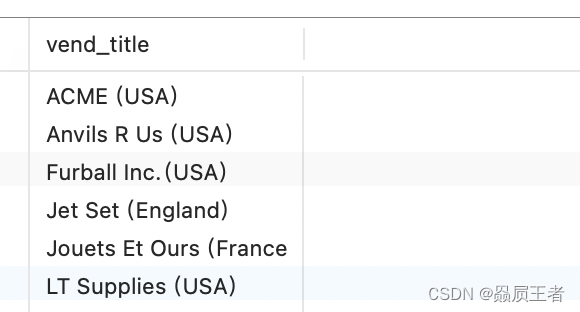
SELECT CONCAT(RTRIM(vend_name),'(', RTRIM(vend_country), ')') AS vend_title
FROM vendors
ORDER BY vend_name;
3. 执行算术计算
计算字段的另一常见用途是对检索出的数据进行算术计算。
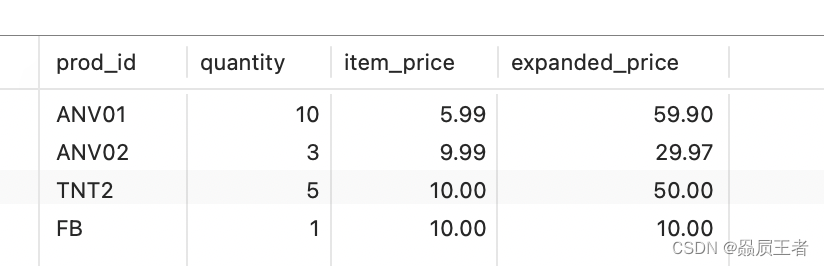
SELECT prod_id, quantity, item_price,
quantity*item_price AS expanded_price
FROM orderitems
WHERE order_num = 20005;
MySQL算术操作符
| 操作符 | 说明 |
|---|---|
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
八、使用数据处理函数
与其他大多数计算机语言一样,SQL支持利用函数来处理数据。函数一般是在数据上执行的,它给数据的转换和处理提供了方便。
1. 使用函数
大多数SQL实现支持以下类型的函数。
- 用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数。
- 用于处理日期和时间值并从这些值中提取特定成分(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数。
- 返回DBMS正使用的特殊信息(如返回用户登录信息,检查版本细节)的系统函数。
2. 处理函数
- 文本处理函数
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Right() | 返回串右边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转换为小写 |
| Upper() | 将串转换为大写 |
| LTrim() | 去掉串左边的空格 |
| RTrim() | 去掉串右边的空格 |
| Soundex() | 返回串的SOUNDEX值 |
| SubString() | 返回子串的字符 |
SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。
- 日期时间处理函数
日期和时间采用相应的数据类型和特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间。
| 函数 | 说明 |
|---|---|
| AddDate() | 增加一个日期(天、周等) |
| AddTime() | 增加一个时间(时、分等) |
| CurDate() | 返回当前日期 |
| CurTime() | 返回当前时间 |
| Now() | 返回当前日期和时间 |
| Date() | 返回日期时间的日期部分 |
| Time() | 返回一个日期时间的时间部分 |
| DateDiff() | 计算两个日期之差 |
| Date_Add() | 高度灵活的日期运算函数 |
| Date_Format() | 返回一个格式化的日期或时间串 |
| Year() | 返回一个日期的年份部分 |
| Month() | 返回一个日期的月份部分 |
| Day() | 返回一个日期的天数部分 |
| DayOfWeek() | 对于一个日期,返回对应的星期几 |
| Hour() | 返回一个时间的小时部分 |
| Minute() | 返回一个时间的分钟部分 |
| Second() | 返回一个时间的秒部分 |
| 示例 |
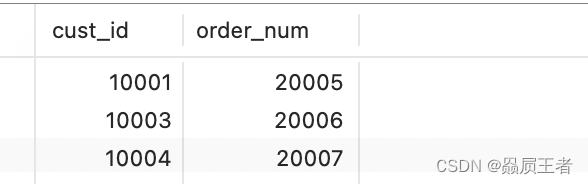
SELECT cust_id, order_num
FROM orders
WHERE DATE(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
- 数值处理函数
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角
或几何运算,因此没有串或日期—时间处理函数的使用那么频繁。
| 函数 | 说明 |
|---|---|
| Abs() | 返回一个数的绝对值 |
| Rand() | 返回一个随机数 |
| Sqrt() | 返回一个数的平方根 |
| Pi() | 返回圆周率 |
| Sin() | 返回一个角度的正弦 |
| Cos() | 返回一个角度的余弦 |
| Tan | 返回一个角度的正切 |
| Exp() | 返回一个数的指数值 |
| Mod() | 返回除操作的余数 |
九、汇总数据
1. 聚集数据
聚集函数:(aggregate function)运行在行组上,计算和返回单个值的函数。
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
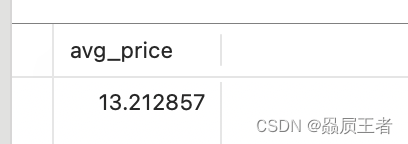
- AVG() 函数
AVG()通过对表中行数计数并计算特定列值之和,求得该列的平均值。AVG()可用来返回所有列的平均值,也可以用来返回特定列或行的平均值。
SELECT AVG(prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
- COUNT() 函数
COUNT()函数进行计数。可利用COUNT()确定表中行的数目或符合特定条件的行的数目。
COUNT()函数有两种使用方式。
- 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
*‰ 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值
- MAX() 函数
MAX()返回指定列中的最大值。MAX()要求指定列名 - MIN() 函数
MIN()的功能正好与MAX()功能相反,它返回指定列的最小值。与MAX()一样,MIN()要求指定列名 - SUM() 函数
SUM()用来返回指定列值的和(总计)。
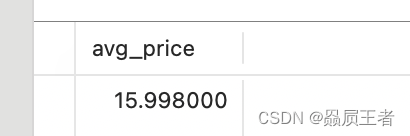
2. 聚集不同值
以上5个聚集函数都可以如下使用:
- 对所有的行执行计算,指定ALL参数或不给参数(因为ALL是默认行为)
- 只包含不同的值,指定DISTINCT参数
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM products
WHERE vend_id = 1003;
3. 组合聚集函数
SELECT COUNT(*) AS num_items,
MIN(prod_price) AS price_min,
MAX(prod_price) AS price_max,
AVG(prod_price) AS price_avg
FROM products;

十、分组数据
1. 数据分组
分组允许把数据分为多个逻辑组,以便能对每个组进行聚集计算。
2. 创建分组
分组是在SELECT语句的GROUP BY子句中建立的。
SELECT vend_id, COUNT(*) AS num_prods
FROM products
GROUP BY vend_id
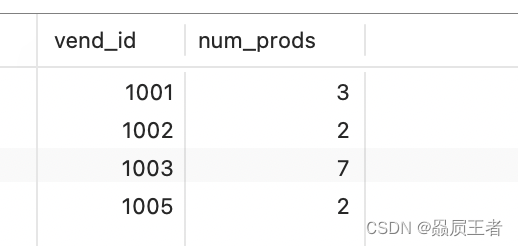
GROUP BY子句指示MySQL分组数据,然后对每个组而不是整个结果集进行聚集。
使用GROUP BY子句前,需要知道一些重要的规定:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。
- 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
3. 过滤分组
除了能用GROUP BY分组数据外,MySQL还允许过滤分组,规定包括
哪些分组,排除哪些分组。
HAVING非常类似于WHERE。事实上,目前为止所
学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是
WHERE过滤行,而HAVING过滤分组。
HAVING和WHERE的差别:
这里有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
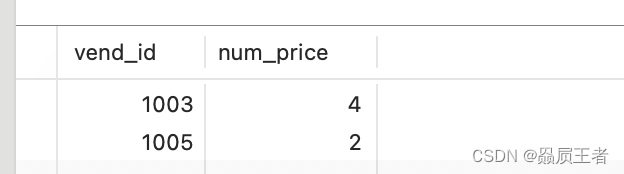
SELECT vend_id, COUNT(*) AS num_price
FROM products
WHERE prod_price >= 10
GROUP BY vend_id
HAVING COUNT(*) >= 2;
4. 分组和排序
GROUP BY和ORDER BY之间的差别
| ORDER BY | GROUP BY |
|---|---|
| 排序产生的输出 | 分组行。但输出可能不是分组的顺序 |
| 任意列都可以使用(甚至非选择的列也可以使用) | 只可能使用选择列或表达式列,而且必须使用每个选择列表达式 |
| 不一定需要 | 如果与聚集函数一起使用列(或表达式),则必须使用 |
| 示例 |
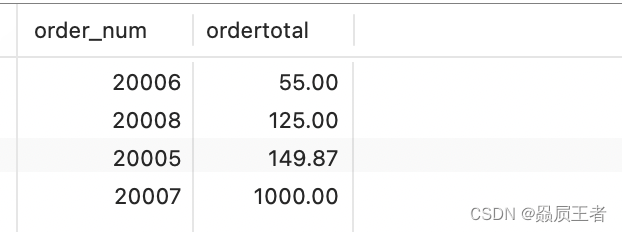
SELECT order_num, SUM(quantity * item_price) AS ordertotal
FROM orderitems
GROUP BY order_num
HAVING SUM(quantity*item_price) >= 50
ORDER BY ordertotal;
5. SELECT子句顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
十一、使用子查询
1. 子查询
子查询:(subquery)即嵌套在其他查询中的查询。
2. 利用子查询进行过滤
格式化SQL:包含子查询的SELECT语句难以阅读和调试,特别是它们较为复杂时更是如此。如上所示把子查询分解为多行并且适当地进行缩进,能极大地简化子查询的使用
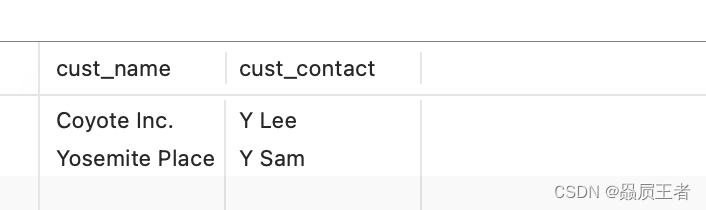
SELECT cust_name, cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2'));
在WHERE子句中使用子查询能够编写出功能很强并且很灵活的
SQL语句。对于能嵌套的子查询的数目没有限制,不过在实际使用时由于
性能的限制,不能嵌套太多的子查询。
3. 作为计算字段使用子查询
相关子查询:(correlated subquery) 涉及外部查询的子查询
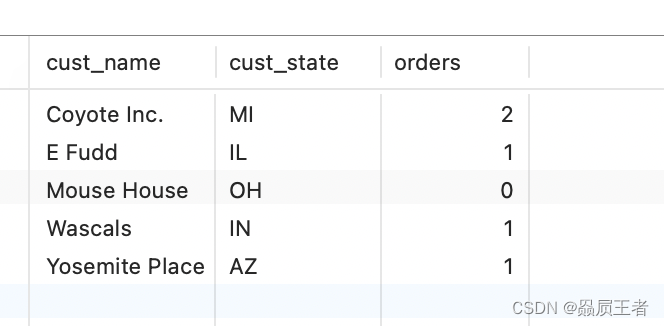
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;
逐渐增加子查询来建立查询: 用子查询测试和调试查询很有技巧性,特别是在这些语句的复杂性不断增加的情况下更是如此。
用子查询建立(和测试)查询的最可靠的方法是逐渐进行,这与MySQL处理它们的方法非常相同。首先,建立和测试最内层的查询。然后,用硬编码数据建立和测试外层查询,并且仅在确认它正常后才嵌入子查询。这时,再次测试它。对于要增加的每个查询,重复这些步骤。这样做仅给构造查询增加了一点点时间,但节省了以后(找出查询为什么不正常)的大量时间,并且极大地提高了查询一开始就正常工作的可能性。
十二、联结表
1. 联结
联结是利用SQL的SELECT能执行的最重要的操作,很好地理解联结及其语法是学习SQL的一个极为重要的组成部分。
1.1 关系表
关系表的设计就是要保证把信息分解成多个表,一类数据一个表。各表通过某些常用的值(即关系设计中的关系(relational))互相关联。
外键:(foreign key) 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系。
可伸缩性:(scale) 能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称之为可伸缩性好(scale well)。
1.2 为什么要使用联结
联结是一种机制,用来在一条SELECT语句中关联表,因此称之为联结。使用特殊的语法,可以联结多个表返回一组输出,联结在运行时关联表中正确的行。
2. 创建联结
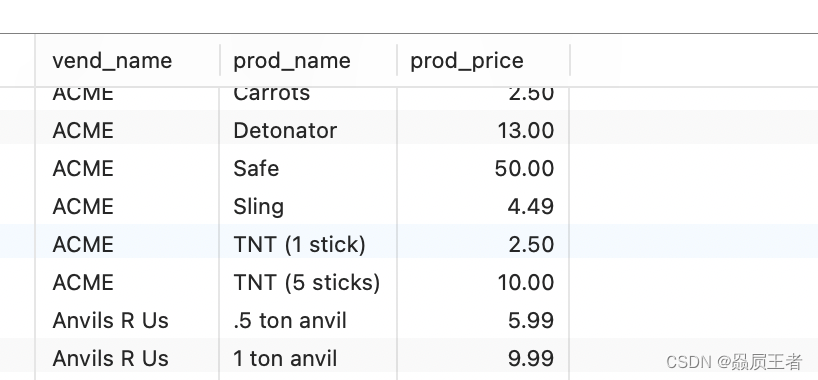
SELECT vend_name, prod_name, prod_price
FROM vendors, products
WHERE vendors.vend_id = products.vend_id
ORDER BY vend_name, prod_name;
2.1 WHERE子句的重要性
WHERE子句作为过滤条件,它只包含那些匹配给定条件(这里是联结条件)的行。没有WHERE子句,第一个表中的每个行将与第二个表中的每个行配对,而不管它们逻辑上是否可以配在一起。
2.2 内部联结
目前为止所用的联结称为等值联结(equijoin),它基于两个表之间的相等测试。这种联结也称为内部联结。
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id
与前面的返回完全相同。
2.3 联结多个表
SQL对一条SELECT语句中可以联结的表的数目没有限制。创建联结的基本规则也相同。
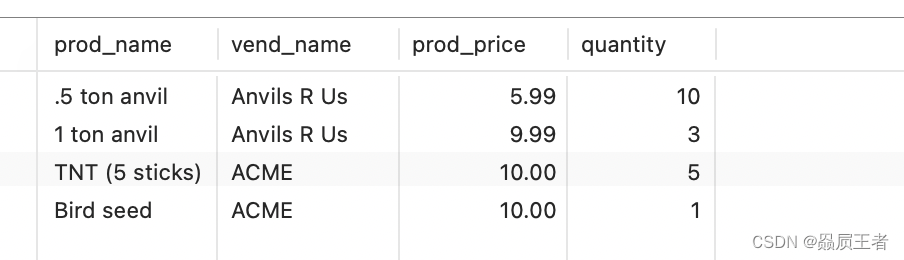
SELECT prod_name, vend_name, prod_price, quantity
FROM orderitems, products, vendors
WHERE products.vend_id = vendors.vend_id
AND orderitems.prod_id = products.prod_id
AND order_num = 20005;
性能考虑: MySQL在运行时关联指定的每个表以处理联结。这种处理可能是非常耗费资源的,因此应该仔细,不要联结不必要的表。联结的表越多,性能下降越厉害。
十三、创建高级联结
1. 使用表别名
给表名起别名的理由:
- 缩短SQL语句
- 允许在单条SELECT语句中多次使用相同的表
SELECT cust_name, cust_contact
FROM customers AS c, orders AS o, orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'TNT2';
注意:表别名只在查询执行中使用。与列别名不一样,表别名不返回到客户机。
2. 使用不同类型的联结
2.1 自联结
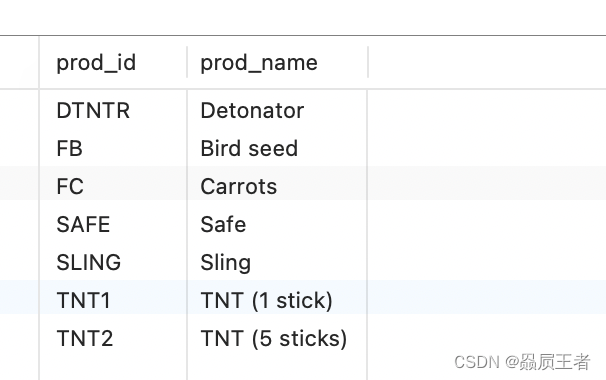
SELECT p1.prod_id, p1.prod_name
FROM products AS p1, products AS p2
WHERE p1.vend_id = p2.vend_id
AND p2.prod_id = 'DTNTR';
自联结通常作为外部语句用来替代从相同表中检索数据时使用的子查询语句。虽然最终的结果是相同的,但有时候处理联结远比处理子查询快得多。应该试一下两种方法,以确定哪一种的性能更好。
2.2 自然联结
自然联结排除多次出现,使每个列只返回一次。
自然联结是这样一种联结,其中你只能选择那些唯一的列。这一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成的。
SELECT c.*, o.order_num, o.order_date, oi.prod_id, oi.quantity, oi.item_price
FROM customers AS c, orders AS o, orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'FB';
2.3 外部联结
联结包含了那些在相关表中没有关联行的行。这种类型的联结称为外部联结。
SELECT customers.cust_id, orders.order_num
FROM customers LEFT OUTER JOIN orders
ON customers.cust_id = orders.cust_id;
在使用OUTER JOIN语法时,必须使用RIGHT或LEFT关键字指定包括其所有行的表(RIGHT指出的是OUTER JOIN右边的表,而LEFT指出的是OUTER JOIN左边的表)。
3. 使用带聚集函数的联结
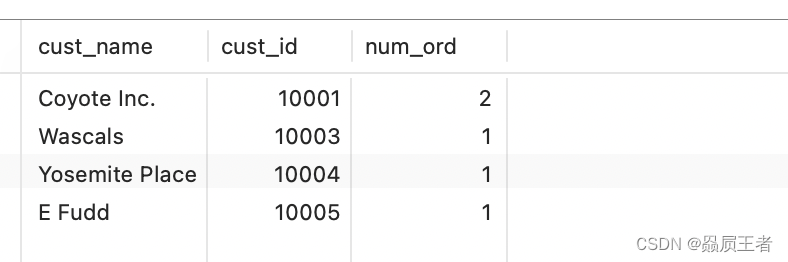
SELECT customers.cust_name, customers.cust_id, COUNT(orders.order_num) AS num_ord
FROM customers INNER JOIN orders
ON customers.cust_id = orders.cust_id
GROUP BY customers.cust_id;
4. 使用联结和联结的条件
- 注意所使用的联结类型。一般我们使用内部联结,但使用外部联结也是有效的。
- 保证使用正确的联结条件,否则将返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡儿积。
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前,分别测试每个联结。这将使故障排除更为简单。
十四、组合查询
1. 组合查询
多数SQL查询都只包含从一个或多个表中返回数据的单条SELECT语句。MySQL也允许执行多个查询(多条SELECT语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)
有两种基本情况,其中需要使用组合查询:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
组合查询和多个WHERE条件:多数情况下,组合相同表的两个查询完成的工作与具有多个WHERE子句条件的单条查询完成的工作相同。换句话说,任何具有多个WHERE子句的SELECT语句都可以作为一个组合查询给出。
这两种技术在不同的查询中性能也不同。因此,应该试一下这两种技术,以确定对特定的查询哪一种性能更好。
2. 创建组合查询
2.1 使用UNION
UNION的使用很简单。所需做的只是给出每条SELECT语句,在各条语句之间放上关键字UNION。
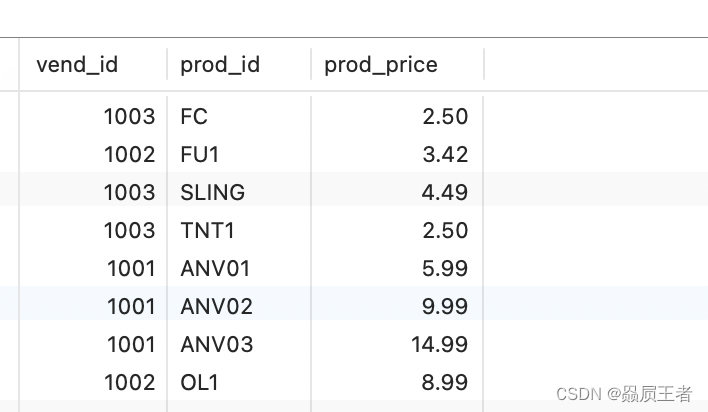
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
OR vend_id IN (1001, 1002);
2.2 UNION规则
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
2.3 包含或取消重复的行
UNION从查询结果集中自动去除了重复的行(换句话说,它的行为与单条SELECT语句中使用多个WHERE子句条件一样)。
如果想返回所有匹配行,可使用UNION ALL而不是UNION。
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION ALL
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002);

2.4 对组合查询结果排序
在用UNION组合查询时,只能使用一条ORDER BY子句,它必须出现在最后一条SELECT语句之后。对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条ORDER BY子句。
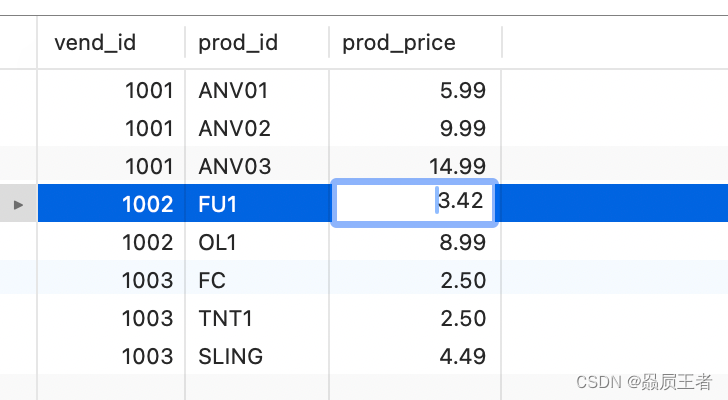
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002)
ORDER BY vend_id, prod_price;
十五、全文本搜索
1. 理解全文本搜索
并非所有引擎都支持全文本搜索
通配操作符和正则表达式搜索机制限制:
- 性能 —— 通配符和正则表达式匹配通常要求MySQL尝试匹配表中所有行(而且这些搜索极少使用表索引)。因此,由于被搜索行数不断增加,这些搜索可能非常耗时。
- 明确控制 —— 使用通配符和正则表达式匹配,很难(而且并不总是能)明确地控制匹配什么和不匹配什么。例如,指定一个词必须匹配,一个词必须不匹配,而一个词仅在第一个词确实匹配的情况下才可以匹配或者才可以不匹配。
- 智能化的结果 —— 虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索,但它们都不能提供一种智能化的选择结果的方法。例如,一个特殊词的搜索将会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行(按照可能是更好的匹配来排列它们)。类似,一个特殊词的搜索将不会找出不包含该词但包含其他相关词的行。
在使用全文本搜索时,MySQL不需要分别查看每个行,不需要分别分析和处理每个词。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。这样,MySQL可以快速有效地决定哪些词匹配(哪些行包含它们),哪些词不匹配,它们匹配的频率,等等。
2. 使用全文本搜索
为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。
2.1 启用全文本搜索支持
一般在创建表时启用全文本搜索。CREATE TABLE语句(第21章中介绍)接受FULLTEXT子句,它给出被索引列的一个逗号分隔的列表。
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MyISAM;
不要在导入数据时使用FULLTEXT:更新索引要花时间,虽然不是很多,但毕竟要花时间。如果正在导入数据到一个新表,此时不应该启用FULLTEXT索引。应该首先导入所有数据,然
后再修改表,定义FULLTEXT。这样有助于更快地导入数据(而且使索引数据的总时间小于在导入每行时分别进行索引所需的总时间)。
2.2 进行全文本搜索
在索引之后,使用两个函数Match()和Against()执行全文本搜索,其中Match()指定被搜索的列,Against()指定要使用的搜索表达式。
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('rabbit');

全文本搜索的一
个重要部分就是对结果排序。具有较高等级的行先返回(因为这些行很
可能是你真正想要的行)。
排序多个搜索项: 如果指定多个搜索项,则包含多数匹配词的那些行将具有比包含较少词(或仅有一个匹配)的那些行高的等级值。
2.3 使用查询扩展
查询扩展用来设法放宽所返回的全文本搜索结果的范围。
你想找出所有提到anvils的注释。只有一个注释包含词anvils,但你还想找出可能与你的搜索有关的所有其他行,即使它们不包含词anvils。
这也是查询扩展的一项任务。在使用查询扩展时,MySQL对数据和索引进行两遍扫描来完成搜索:
- 首先,进行一个基本的全文本搜索,找出与搜索条件匹配的所有行;
- 其次,MySQL检查这些匹配行并选择所有有用的词(我们将会简要地解释MySQL如何断定什么有用,什么无用)。
- 再其次,MySQL再次进行全文本搜索,这次不仅使用原来的条件,而且还使用所有有用的词。
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against('anvils' WITH QUERY EXPANSION);

第一行包含词anvils,因此等级最高。第二行与anvils无关,但因为它包含第一行中的两个词(customer和recommend),所以也被检索出来。第3行也包含这两个相同的词,但它们在文本中的位置更靠后且分开得更远,因此也包含这一行,但等级为第三。第三行确实也没有涉及anvils(按它们的产品名)。
2.4 布尔文本搜索
MySQL支持全文本搜索的另外一种形式,称为布尔方式(boolean mode)。
以布尔方式,可以提供关于如下内容的细节:
- 要匹配的词;
- 要排斥的词(如果某行包含这个词,则不返回该行,即使它包含其他指定的词也是如此);
- 排列提示(指定某些词比其他词更重要,更重要的词等级更高);
- 表达式分组;
- 另外一些内容。
即使没有FULLTEXT索引也可以使用:布尔方式不同于迄今为止使用的全文本搜索语法的地方在于,即使没有定义FULLTEXT索引,也可以使用它。但这是一种非常缓慢的操作(其性能将随着数据量的增加而降低)。
SELECT note_text
FROM productnotes
WHERE Match(note_text) Against(' heavy -rope*' IN BOOLEAN MODE);
包含“heavy”但不包含“rope”
全文本布尔操作符:
| 布尔操作符 | 说明 |
|---|---|
| + | 包含,词必须存在 |
| - | 排除,词必须不出现 |
| > | 包含,而且增加等级值 |
| < | 包含,且减少等级值 |
| () | 把词组成子表达式(允许这些子表达式作为一个组被包含、排除、排列等) |
| ~ | 取消一个词的排序值 |
| * | 词尾的通配符 |
| “” | 定义一个短语(与单个词的列表不一样,它匹配整个短语以便包含或排除这个短语) |
2.5 全文本搜索的使用说明
- 在索引全文本数据时,短词被忽略且从索引中排除。短词定义为那些具有3个或3个以下字符的词(如果需要,这个数目可以更改)。
- MySQL带有一个内建的非用词(stopword)列表,这些词在索引全文本数据时总是被忽略。如果需要,可以覆盖这个列表(请参阅MySQL文档以了解如何完成此工作)。
- 许多词出现的频率很高,搜索它们没有用处(返回太多的结果)。因此,MySQL规定了一条50%规则,如果一个词出现在50%以上的行中,则将它作为一个非用词忽略。50%规则不用于IN BOOLEAN MODE。
- 如果表中的行数少于3行,则全文本搜索不返回结果(因为每个词或者不出现,或者至少出现在50%的行中)。
- 忽略词中的单引号。例如,don’t索引为dont。
- 不具有词分隔符(包括日语和汉语)的语言不能恰当地返回全文本搜索结果。
- 如前所述,仅在MyISAM数据库引擎中支持全文本搜索。
学习书籍:
MySQL必知必会第2版
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- S32K144-11.can
- 小程序商城免费搭建之java商城 电子商务Spring Cloud+Spring Boot+二次开发+mybatis+MQ+VR全景+b2b2c bbc
- 记录菜鸟图片抓取代码
- 用可视化案例讲Rust编程4. 用泛型和特性实现自适配shapefile的读取
- 数据挖掘在制造业中的预测与优化应用
- 奇数魔方阵
- 70K star! 0代码 30 秒创建 REST API 服务 : json-server
- 变电站综合自动化监控系统在某物流园35kV变电站中应用
- Android Activity收不到bundle消息(singleInstance,singletop模式)
- UILabel布局解决文本右边对不齐的问题