从hugging face下载数据集,将.parquet类型数据中提取图片和标签
发布时间:2024年01月20日
时间:2024.1.19
1.hugging face数据集下载地址
https://huggingface.co/datasets?sort=downloads
2.下载.paraquet类型数据
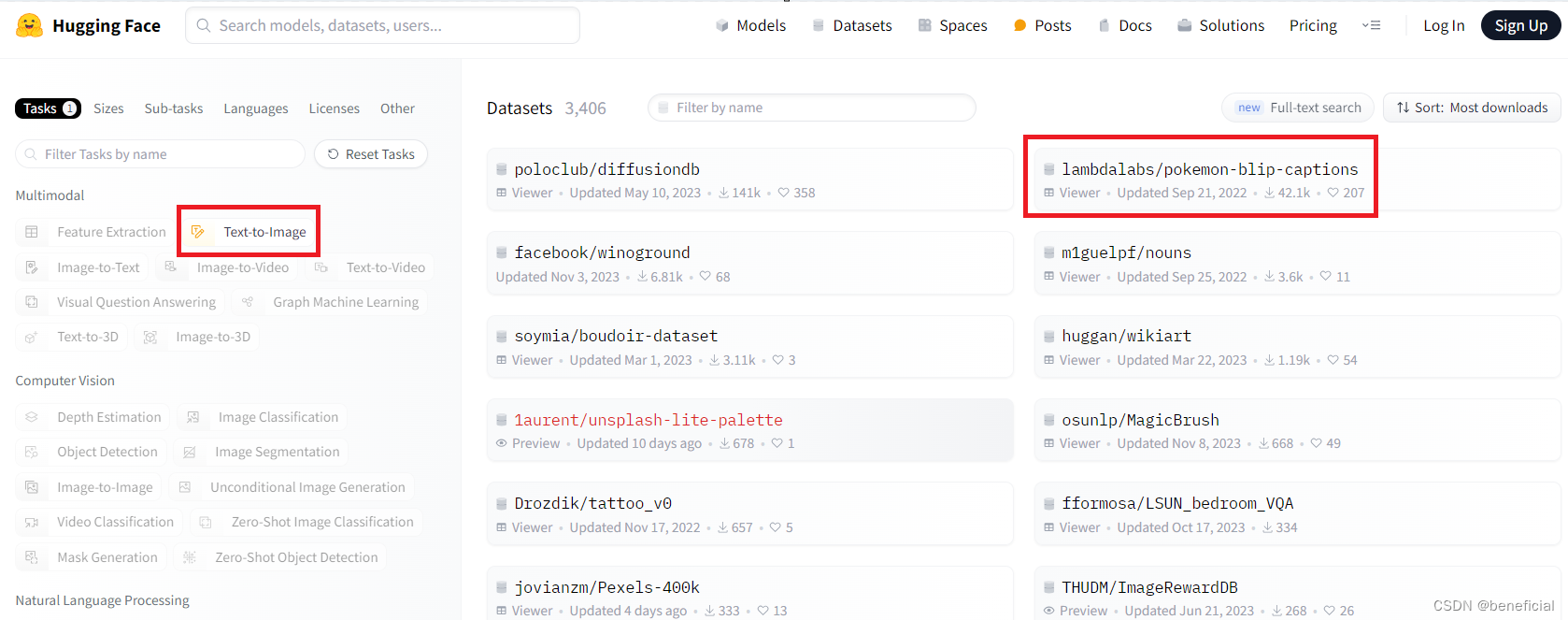
(1)这里以图像文本对数据集pokeman为例。先点击下图中左侧的text-to-image,再点击pokeman-blip-captions。
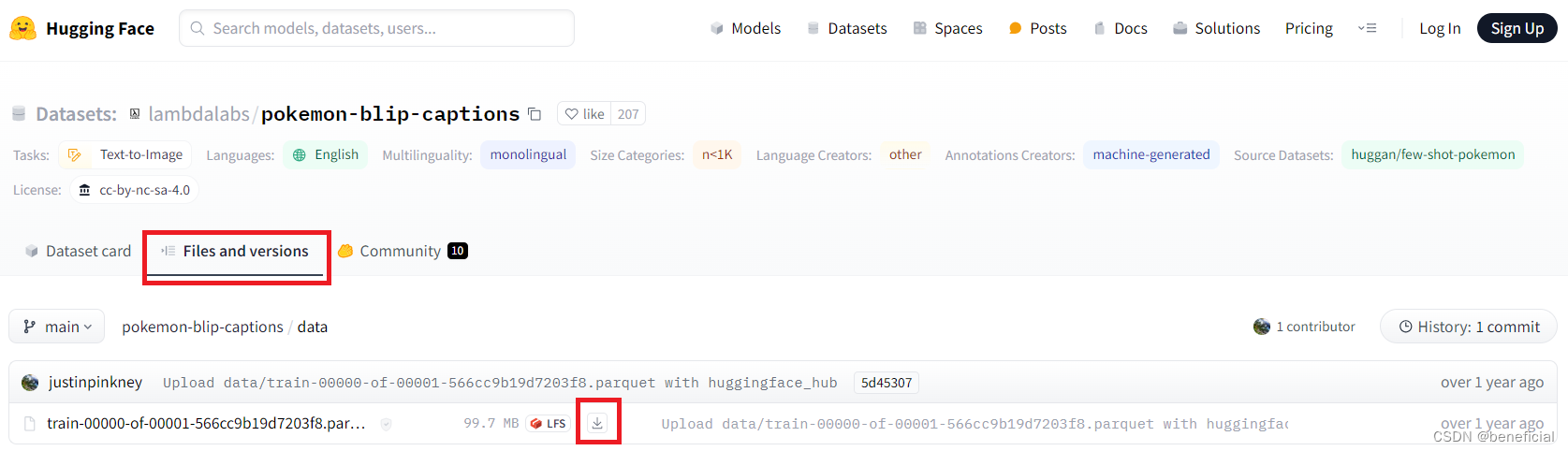
(2)再点击下图中的File and version,再点击下载按钮。
3.打印.parquet类型数据
import pandas as pd
pokeman = pd.read_parquet('/root/train-00000-of-00001-566cc9b19d7203f8.parquet')
print(pokeman)
.parquet类型数据如下:
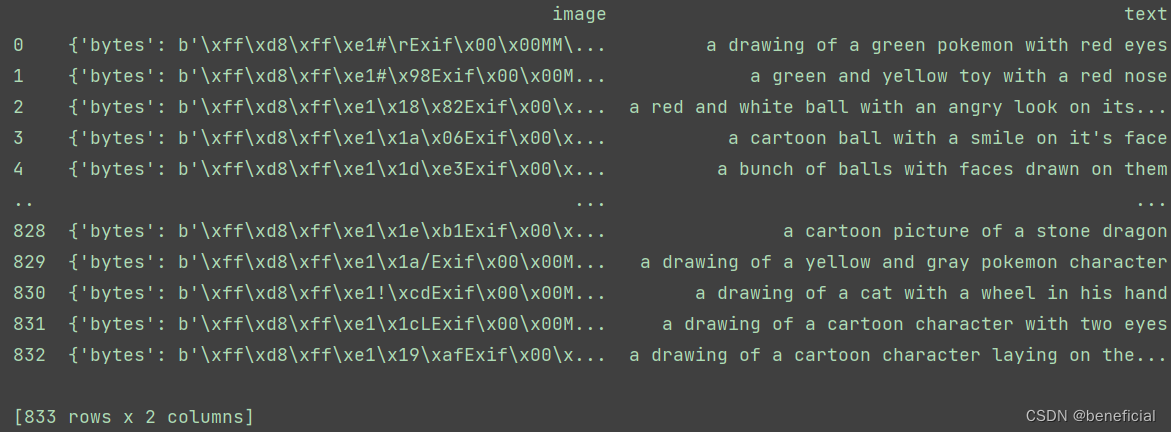
可以看到有833条数据,每一个数据都包含1张图片和1条文本。
4将.parquet类型数据中提取图片和标签
注意:代码中的路径要根据实际路径进行修改!!
import pandas as pd
import cv2
import numpy as np
pokeman = pd.read_parquet('/root/train-00000-of-00001-566cc9b19d7203f8.parquet')
print(pokeman)
path_prefix = '/root/pokeman/'
print('Processing images : ')
for index, img in enumerate(pokeman['image']):
image_bytes = img['bytes']
# 将bytes数据转换为numpy矩阵
image_np = cv2.imdecode(np.frombuffer(image_bytes, dtype=np.uint8), cv2.IMREAD_COLOR)
# 将numpy矩阵保存为jpg格式的图片文件
cv2.imwrite(path_prefix + f"/image/{index}.jpg", image_np)
print('finish')
print('Processing text : ')
for index, text in enumerate(pokeman['text']):
with open(path_prefix + f'/text/{index}.txt', 'w') as f:
f.write(text)
print('finish')
5.任务
这个pokeman是一个图像文本对数据集,听说能训练stable diffusion,后续试一试。
文章来源:https://blog.csdn.net/beneficial/article/details/135706499
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 《绝地求生大逃杀》画面声音设置与单排技巧
- PyTorch实战:基于Seq2seq模型处理机器翻译任务(模型预测)
- Android安卓开发大作业---模拟电影票小程序APP
- 【Redis-09】Redis哨兵机制的实现原理-Sentinel
- nvm, node.js, npm, yarn 安装配置
- Unity报错:InvalidOperationException: Insecure connection not allowed的解决方法
- OSPF基本概念与配置(完整版)
- 基于Redis在定时任务里判断其他定时任务是否已经正常执行完的方案
- 前端(二十)——Vite和Webpack:前端开发中常用的构建工具
- 工业5G路由器助力AGV工厂建设,确保自动流水线高效运转