【Kaggle】泰坦尼克号生存预测 Titanic
发布时间:2024年01月22日
文章目录
前言
官网链接:Titanic - Machine Learning from Disaster | Kaggle
Notebook 链接:Titanic Analysis Predictions | LR, DT, RF, GBT | Kaggle
(其中 Version 1-3 含有分析过程,文末仅贴有逻辑回归模型的完整 python 代码)
案例背景
泰坦尼克号的沉没是历史上最臭名昭著的沉船事故之一。
1912 年 4 月 15 日,在她的处女航中,被广泛认为“不沉”的泰坦尼克号与冰山相撞后沉没。不幸的是,船上没有足够的救生艇,导致 2224 名乘客和机组人员中有 1502 人死亡。
虽然生存有一定的运气成分,但似乎某些群体比其他群体更有可能生存。
在本次挑战中,我们要求建立一个预测模型来回答以下问题:“什么样的人更有可能生存?”使用乘客数据(即姓名、年龄、性别、社会经济阶层等)。
数据集介绍
数据分为两组:
- 训练集(train.csv)
- 测试集(test.csv)
训练集:包含机上部分乘客(确切地说是 891 名)的详细信息,重要的是,将揭示他们是否幸存,也称为“基本事实”。
测试集:包含类似的信息,但没有披露每位乘客的“基本事实”。预测这些结果是你的工作。
| 列名 | 含义 |
|---|---|
| PassengerId | 乘客编号 |
| Survived | 生存情况(0:死亡,1:存活) |
| Pclass | 客舱等级 |
| Name | 姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 同代直系亲属数 |
| Parch | 不同代直系亲属数 |
| Ticket | 船票编号 |
| Fare | 船票价格 |
| Cabin | 客舱号 |
| Embarked | 登船港口 |
加载数据集
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
# 加载数据集
df = pd.read_csv("./titanic/train.csv")
df.sample(5, random_state=0)

探索性数据分析(EDA)
df.info()

可视化特征和目标值之间关系
from matplotlib import pyplot as plt
import seaborn as sns
features = ["Pclass", "Age", "SibSp", "Parch", "Fare"]
fig, axes = plt.subplots(1, 5, figsize=(15, 3), tight_layout=True)
for feature, ax in zip(features, axes):
plt.sca(ax)
sns.kdeplot(df.loc[df["Survived"] == 1, feature], label="1", fill=True)
sns.kdeplot(df.loc[df["Survived"] == 0, feature], label="0", fill=True)
plt.legend(title="Survived")
plt.show()

缺失值分析
df.isnull().sum()

# 删除缺失值
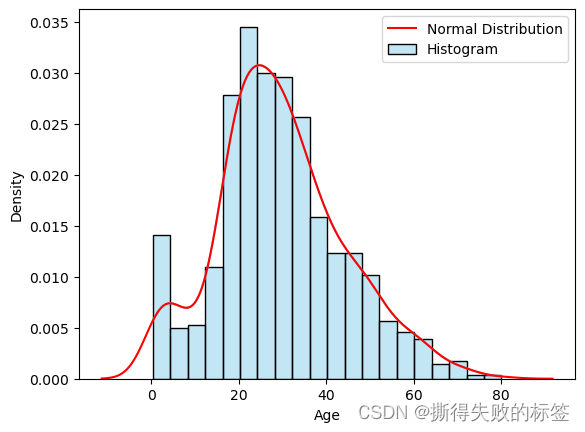
data = df['Age'].dropna()
# 绘制直方图
sns.histplot(data, kde=True, color='skyblue', label='Histogram', stat='density')
# 绘制正态分布曲线
sns.kdeplot(data, color='r', label='Normal Distribution')
plt.legend()
plt.show()
sum(df['Cabin'].isnull()) / len(df)

plt.pie(x=df['Embarked'].value_counts().values, labels=df['Embarked'].value_counts().index, autopct='%1.1f%%')
plt.show()

- 处理缺失值的策略
- Age 趋近于正态分布,根据 Name 中的称呼给 Age 赋其对于均值
- Cabin 中缺失值占比 77%,缺失过多,删除该列
- Embarked 中有 2 个缺失值使用占比最大的 S 填充
数据预处理
数据清洗
缺失值处理
import re
def name_title(x):
return x.split('.')[0].split(' ')[-1]
df['Name'].apply(remove_noise).value_counts()

def remove_noise(x):
return re.sub(r'[".,()]+', '', x)
df['NameTitle'] = df['Name'].apply(name_title)
df.sample(5, random_state=0)

# 根据分组计算平均值
group_means = df.groupby('NameTitle')['Age'].mean()
# 填充缺失值
df['Age'] = df['Age'].fillna(df['NameTitle'].map(group_means))
df.sample(5, random_state=0)
df = df.drop('Cabin', axis=1)
df['Embarked'].fillna('S', inplace=True)
df.head()

# 提取每个单元格中包含的非字母字符
symbols_per_cell = df['Name'].apply(lambda x: ''.join([char for char in x if not char.isalpha()]))
# 获取所有不同的符号
unique_symbols = set(''.join(symbols_per_cell))
unique_symbols

去除噪声并且规范化文本内容
def ticket_pref(x):
if len(x.split(' ')) == 1:
return 'nan'
else:
x = ".".join(x.split(' ')[:-1])
return re.sub(r'[./]+', '', x).lower()
def ticket_ID(x):
x = x.split(' ')[-1]
return int(x) if x.isdigit() else 0
df['Name'] = df['Name'].apply(remove_noise)
df['TicketPref'] = df['Ticket'].apply(ticket_pref)
df['TicketID'] = df['Ticket'].apply(ticket_ID)
df.sample(5, random_state=0)
y = df['Survived']
X = df.drop(['PassengerId', 'Survived', 'Ticket', 'NameTitle'], axis=1)
X.sample(5, random_state=0)

数据转换
- 处理文本数据
- Name 使用 TF-IDF(Term Frequency-Inverse Document Frequency)进行特征提取(Feature Extraction)
- Sex、Embarked、TicketPref 使用独热编码(One-Hot Encoding)进行特征编码(Feature Encoding)
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.impute import SimpleImputer
from sklearn.compose import make_column_selector as selector
# 提取数值类型的特征列
numeric_columns = selector(dtype_include='number')
# 定义 Pipeline 中每个步骤
text_transformer = Pipeline(steps=[
('tfidf', TfidfVectorizer())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler())
])
# 使用 ColumnTransformer 指定每列的处理方式
preprocessor = ColumnTransformer(
transformers=[
('text', text_transformer, 'Name'),
('categorical', categorical_transformer, ['Sex', 'Embarked', 'TicketPref']),
('numeric', numeric_transformer, numeric_columns)
])
# 创建完整的 Pipeline
pipeline = Pipeline(steps=[('preprocessor', preprocessor)])
# 在你的数据上使用 Pipeline 进行处理
X_processed = pipeline.fit_transform(X)
数据划分
from sklearn.model_selection import train_test_split
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.2, random_state=0)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
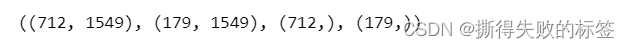
建模
逻辑回归模型
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, accuracy_score, classification_report
import numpy as np
# 创建逻辑回归模型
lr = LogisticRegression()
# 定义参数网格
param_grid = {
'C': np.logspace(-3, 3, 7),
'max_iter': list(range(5, 40, 5)),
}
# 设置多类分类评估器
scorer = make_scorer(accuracy_score)
# 创建 GridSearchCV 对象
grid_search = GridSearchCV(
estimator=lr,
param_grid=param_grid,
scoring=scorer,
cv=5 # 使用交叉验证
)
# 运行网格搜索
grid_search.fit(X_train, y_train)
# 输出最佳参数
print("Best Parameters: ", grid_search.best_params_)
# 在验证集上评估模型
lr_model = grid_search.best_estimator_
y_pred = lr_model.predict(X_test)
# 评估(Evaluation)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))

决策分类树模型
from sklearn.tree import DecisionTreeClassifier
# Create Decision Tree classifier
dt_classifier = DecisionTreeClassifier()
# Define parameter grid
param_grid = {
'criterion': ['gini', 'entropy'],
'max_depth': list(range(5, 25, 5)),
'min_samples_split': [3, 7, 12],
'min_samples_leaf': [2, 4, 6],
}
# Set the scoring metric
scorer = make_scorer(accuracy_score)
# Create GridSearchCV object
grid_search = GridSearchCV(
estimator=dt_classifier,
param_grid=param_grid,
scoring=scorer,
cv=5 # Using 5-fold cross-validation
)
# Run grid search
grid_search.fit(X_train, y_train)
# Output the best parameters
print("Best Parameters: ", grid_search.best_params_)
# Evaluate the model on the test set
dt_model = grid_search.best_estimator_
y_pred = dt_model.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))

随机森林模型
from sklearn.ensemble import RandomForestClassifier
# Create Random Forest classifier
rf_classifier = RandomForestClassifier()
# Define parameter grid
param_grid = {
'n_estimators': [50, 100, 150],
'criterion': ['gini', 'entropy'],
'max_depth': [5, 10, 15],
'min_samples_split': [3, 7, 12],
'min_samples_leaf': [2, 4, 6],
}
# Set the scoring metric
scorer = make_scorer(accuracy_score)
# Create GridSearchCV object
grid_search = GridSearchCV(
estimator=rf_classifier,
param_grid=param_grid,
scoring=scorer,
cv=5 # Using 5-fold cross-validation
)
# Run grid search
grid_search.fit(X_train, y_train)
# Output the best parameters
print("Best Parameters: ", grid_search.best_params_)
# Evaluate the model on the test set
rf_model = grid_search.best_estimator_
y_pred = rf_model.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))

梯度提升树模型
from sklearn.ensemble import GradientBoostingClassifier
# Create Gradient Boosting classifier
gb_classifier = GradientBoostingClassifier()
# Define parameter grid
param_grid = {
'n_estimators': [50, 100, 150],
'learning_rate': [0.01, 0.1, 0.2],
'max_depth': [3, 4, 5],
'min_samples_split': [3, 7, 12],
'min_samples_leaf': [2, 4, 6],
}
# Set the scoring metric
scorer = make_scorer(accuracy_score)
# Create GridSearchCV object
grid_search = GridSearchCV(
estimator=gb_classifier,
param_grid=param_grid,
scoring=scorer,
cv=5 # Using 5-fold cross-validation
)
# Run grid search
grid_search.fit(X_train, y_train)
# Output the best parameters
print("Best Parameters: ", grid_search.best_params_)
# Evaluate the model on the test set
gb_model = grid_search.best_estimator_
y_pred = gb_model.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))

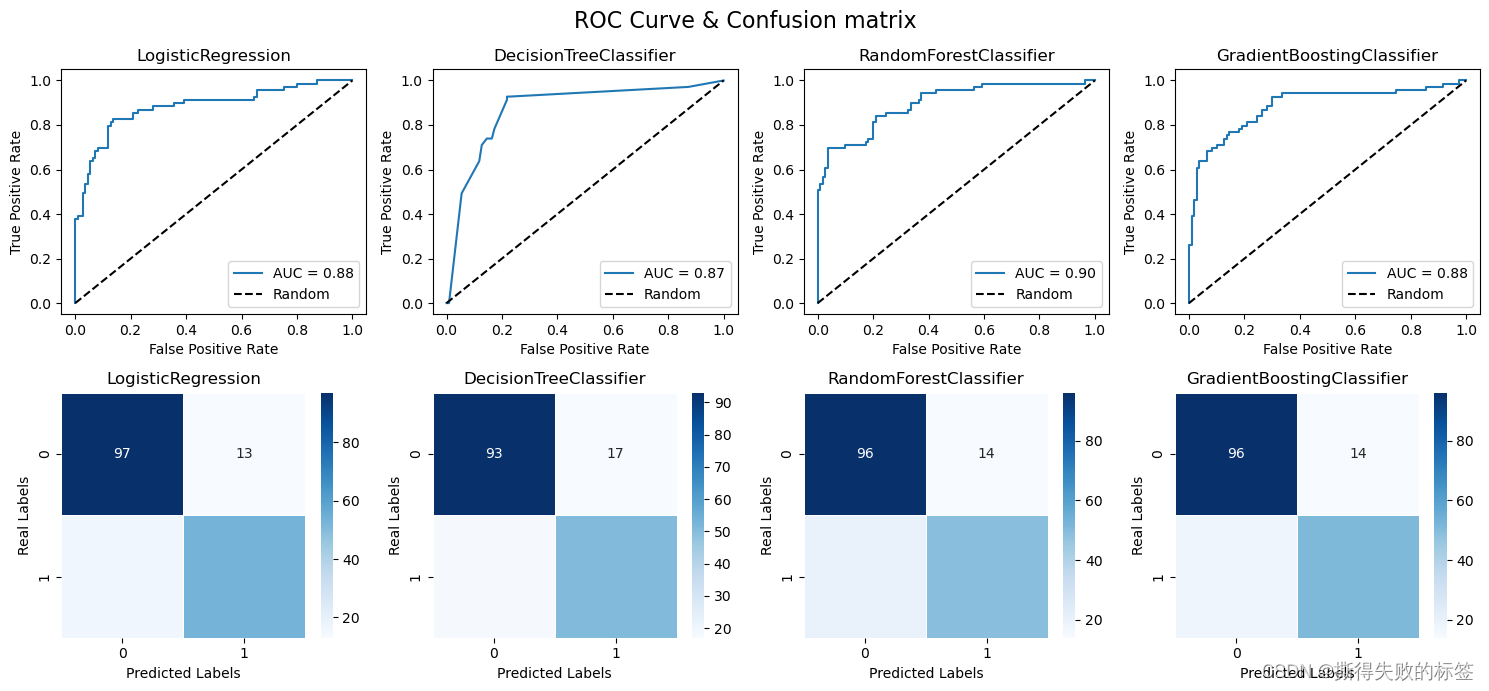
from sklearn.metrics import roc_curve, roc_auc_score
from sklearn.metrics import confusion_matrix
# 假设 y_test 是真实标签,y_scores 是预测的概率得分
models = [lr_model, dt_model, rf_model, gb_model]
y_scores = [model.predict_proba(X_test)[:, 1] for model in models]
fig, axes = plt.subplots(2, 4, figsize=(15, 7), tight_layout=True)
fig.suptitle('ROC Curve & Confusion matrix', size=16)
for i in range(4):
# 计算 ROC 曲线的值
fpr, tpr, thresholds = roc_curve(y_test, y_scores[i])
# 计算 AUC(Area Under the Curve)
auc = roc_auc_score(y_test, y_scores[i])
plt.sca(axes[0][i])
plt.plot(fpr, tpr, label=f'AUC = {auc:.2f}')
plt.plot([0, 1], [0, 1], 'k--', label='Random')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title(models[i].__class__.__name__)
plt.legend()
plt.sca(axes[1][i])
y_pred = models[i].predict(X_test)
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, cmap='Blues', fmt='g', linewidths=.5)
plt.title(models[i].__class__.__name__)
plt.xlabel('Predicted Labels')
plt.ylabel('Real Labels')
plt.show()
预测
# 导入数据集
test_data = pd.read_csv("./titanic/test.csv")
# 数据预处理
test_data['NameTitle'] = test_data['Name'].apply(name_title)
group_means = test_data.groupby('NameTitle')['Age'].mean()
test_data['Age'].fillna(df['NameTitle'].map(group_means), inplace=True)
test_data['Fare'].fillna(test_data['Fare'].mean(), inplace=True)
test_data['Name'] = test_data['Name'].apply(remove_noise)
test_data['TicketPref'] = test_data['Ticket'].apply(ticket_pref)
test_data['TicketID'] = test_data['Ticket'].apply(ticket_ID)
test = test_data.drop(['PassengerId', 'Ticket', 'Cabin', 'NameTitle'], axis=1)
test.sample(5, random_state=0)

# 数据转化
X_test_processed = pipeline.transform(test)
X_test_processed.shape

# 模型预测
val = lr_model.predict(X_test_processed)
sub = pd.read_csv("./titanic/gender_submission.csv")
sub['Survived'] = val
sub.to_csv('./titanic/submission.csv', index=False)
print("Your submission was successfully saved!")

LR 完整的 python 代码
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import make_column_selector as selector
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import make_scorer, accuracy_score, classification_report
import numpy as np
import re
import warnings
warnings.filterwarnings("ignore")
'''Setp 1: Load dataset'''
df = pd.read_csv("titanic/train.csv")
'''Setp 2: Data Preprocessing'''
def name_title(x):
return x.split('.')[0].split(' ')[-1]
def remove_noise(x):
return re.sub(r'[".,()]+', '', x)
def ticket_pref(x):
if len(x.split(' ')) == 1:
return 'nan'
else:
x = ".".join(x.split(' ')[:-1])
return re.sub(r'[./]+', '', x).lower()
def ticket_ID(x):
x = x.split(' ')[-1]
return int(x) if x.isdigit() else 0
# data preprocessing
def preprocessing(df):
df = df.copy()
# Missing Data Handling
df['NameTitle'] = df['Name'].apply(name_title)
# Fill in missing values
df['Age'].fillna(df['NameTitle'].map(df.groupby('NameTitle')['Age'].mean()), inplace=True)
df['Embarked'].fillna('S', inplace=True)
# Remove Noise
df['Name'] = df['Name'].apply(remove_noise)
# Standardize Text Content
df['TicketPref'] = df['Ticket'].apply(ticket_pref)
df['TicketID'] = df['Ticket'].apply(ticket_ID)
return df
train_df = preprocessing(df)
y = train_df['Survived']
X = train_df.drop(['PassengerId', 'Survived', 'Ticket', 'NameTitle', 'Cabin'], axis=1)
'''Setp 3: Data Transformation'''
# Extracting columns with numerical features
numeric_columns = selector(dtype_include='number')
# Define each step in the pipeline
text_transformer = Pipeline(steps=[
('tfidf', TfidfVectorizer())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
numeric_transformer = Pipeline(steps=[
('scaler', StandardScaler())
])
# Use ColumnTransformer to specify the processing method for each column
preprocessor = ColumnTransformer(
transformers=[
('text', text_transformer, 'Name'),
('categorical', categorical_transformer, ['Sex', 'Embarked', 'TicketPref']),
('numeric', numeric_transformer, numeric_columns)
])
# Create a complete pipeline
pipeline = Pipeline(steps=[('preprocessor', preprocessor)])
# Use a pipeline to process data
X_processed = pipeline.fit_transform(X)
'''Setp 4: Data Splitting'''
# Splitting the training set and test set
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.2, random_state=0)
'''Setp 5: Modeling'''
# Create Logistic Regression
lr = LogisticRegression()
# Define parameter grid
param_grid = {
'C': np.logspace(-3, 3, 7),
'max_iter': list(range(5, 50, 1)),
}
# Set the scoring metric
scorer = make_scorer(accuracy_score)
# Create GridSearchCV object
grid_search = GridSearchCV(
estimator=lr,
param_grid=param_grid,
scoring=scorer,
cv=5 # Using 5-fold cross-validation
)
# Run grid search
grid_search.fit(X_train, y_train)
# Output the best parameters
print("Best Parameters: ", grid_search.best_params_)
# Evaluate the model on the test set
lr_model = grid_search.best_estimator_
y_pred = lr_model.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(classification_report(y_test, y_pred))
'''Setp 6: Predicting'''
test_data = pd.read_csv("titanic/test.csv")
test_data.head()
def preprocess_data(df):
df = df.copy()
# Missing Data Handling
df['NameTitle'] = df['Name'].apply(name_title)
# Fill in missing values
df['Age'].fillna(df['NameTitle'].map(train_df.groupby('NameTitle')['Age'].mean()), inplace=True)
df['Fare'].fillna(df['Fare'].mean(), inplace=True)
# Remove Noise
df['Name'] = df['Name'].apply(remove_noise)
# Standardize Text Content
df['TicketPref'] = df['Ticket'].apply(ticket_pref)
df['TicketID'] = df['Ticket'].apply(ticket_ID)
df = df.drop(['PassengerId', 'Ticket', 'NameTitle', 'Cabin'], axis=1)
return df
# Data preprocessing
test = preprocess_data(test_data)
# Data Transformation
X_test_processed = pipeline.transform(test)
# Predicting
val = lr_model.predict(X_test_processed)
sub = pd.read_csv("titanic/gender_submission.csv")
sub['Survived'] = val
sub.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
文章来源:https://blog.csdn.net/qq_61828116/article/details/135724011
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 本地静态资源打包出来,本地配置ng访问服务器(uniapp打包成h5后,使用打包资源连接测试环境测试)
- JVM如何执行synchronized修饰的方法
- CAD 审图意见的导出
- cfa一级考生复习经验分享系列(十)
- 2014-2020年GDP栅格数据集
- centos 安装 zlib 库
- FL Studio(水果软件)2024支持电脑系统Win11仅限64位
- DAMA-描述性、诊断性、预测性和规定性分析
- “盲盒+互联网”模式下的盲盒小程序带来了哪些机遇?
- 9-Python 工匠:一个关于模块的小故事