不是 ES 用不起,而是 ClickHouse 更具“性价比”?
云原生架构是一种基于云计算、容器化和微服务的架构模式。业内预测,到2025年,预计超过95%的工作负载将迁移到云端,云原生架构成为业务的必需品。
背景介绍
经过十三年的发展,某快递公司目前C端累计注册用户超2.5亿、P端(专业用户)累计注册快递员及网点经营者超130万、B端累计服务电商企业/泛电商企业/品牌企业/政府与公共组织等客户超250万家;每天快递查询调用量超4亿次、寄件下单量超30万单。
公司的业务量和数据量是相对较大且复杂的,因此拥有一个实时性、可扩展性、并拥有强大的搜索与分析功能的日志中心至关重要,它不仅可以记录系统的性能、运行状态,还可以为我们提供很多有价值的业务数据和用户行为分析,这些都将为业务的洞察与决策提供有效支持,从而推动产品的迭代升级和运营策略调整。
同时,日志也是我们线上定位问题的重要手段,我们经常会依赖日志排查解决来自客户的问题,帮助我们提升服务质量,增强客户对公司的产品信赖。
如何构建一套适合我们的日志中心?在业务的发展过程中,日志的架构从原始的文件记录到ELK体系,我们也遇到了一系列的问题,经历实践和研究分析,我们最终构建了新一代的日志系统。下面就给大家分享整个过程。
初期架构
1. 原始架构
把时间回溯到10年前,我们会怎样去记录日志?
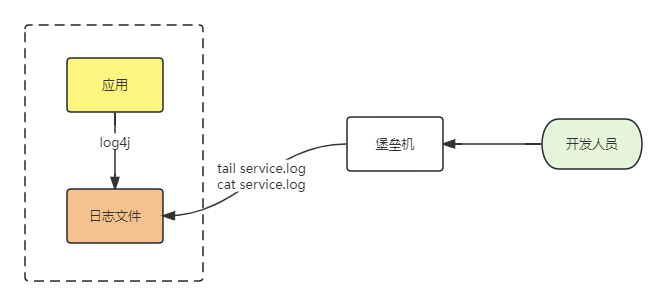
架构比较简单,但问题也比较明显,有几个明显的缺点:
-
每次查看日志文件都需要登录到不同的机器,非常不方便;
-
通过 tail 或者 cat 等命令查看日志,如果对日志文件进行检索、聚合等操作,还会对服务器的 io 造成很大的压力,甚至导致故障的产生;
-
日志文件过大不仅导致查询变得特别慢,还经常带来磁盘告警甚至磁盘空间不足等严重后果;
-
日志格式不规范,日志随意写到文件,可读性和可分析性几乎为零;
-
应用多节点挂载 NFS 性能差,容易产生日志丢失,从而影响问题定位和排障。

1. ELK体系
经历了这些问题之后,2017年,我们把目光转向新一代的基于Elasticsearch的日志体系,恰逢之前快递100订单检索引入了Elasticsearch,侧面又了解到基于Elastic Stack的ELK体系,经过一系列研究,开始意识到日志规范的重要性和采集的好处。
ELK是业界最成熟的日志技术栈,使用JSON格式存储,易于解析,再配合全文检索能力,能够快速从众多的日志信息中搜索到关键信息,加上Kibana的易用性,使得日志体验上升了几个档次,架构大致如下,不具体拆分细讲。
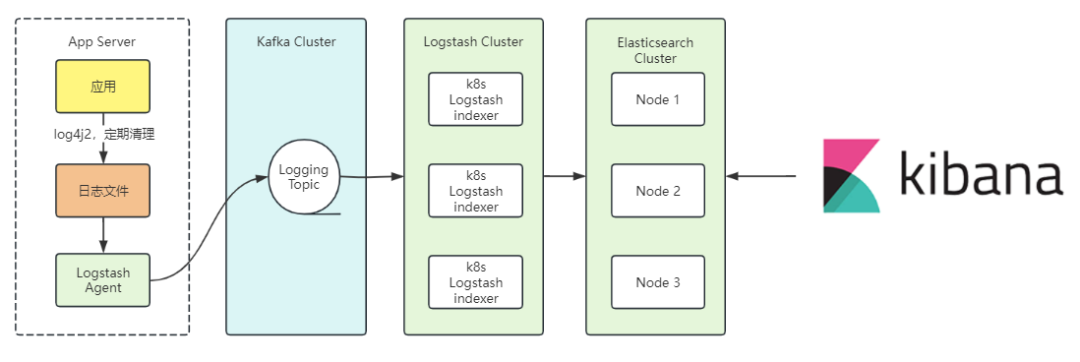
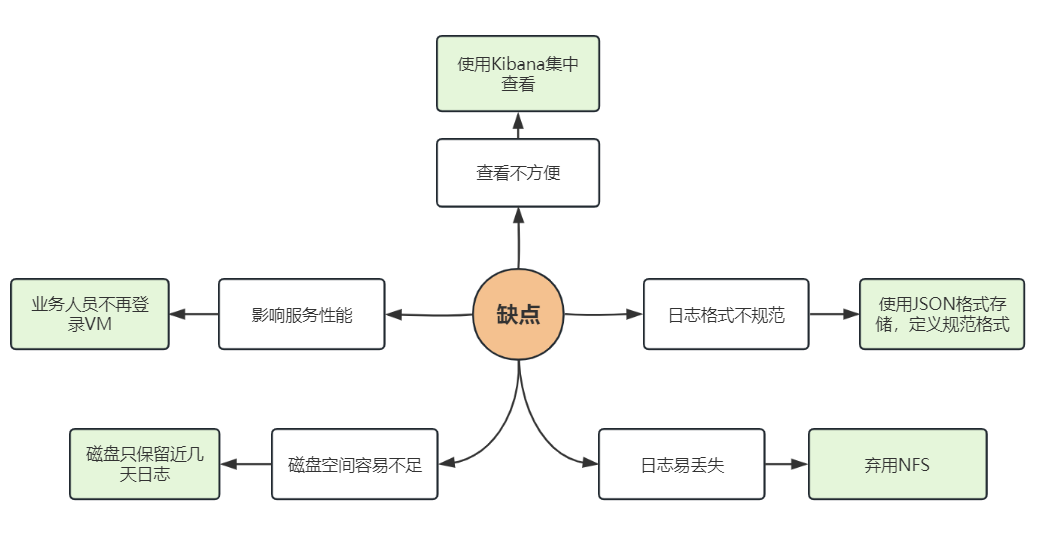
我们再回顾一下之前的挑战和缺点,可以看到基本解决了之前遇到的问题:
实践中的挑战
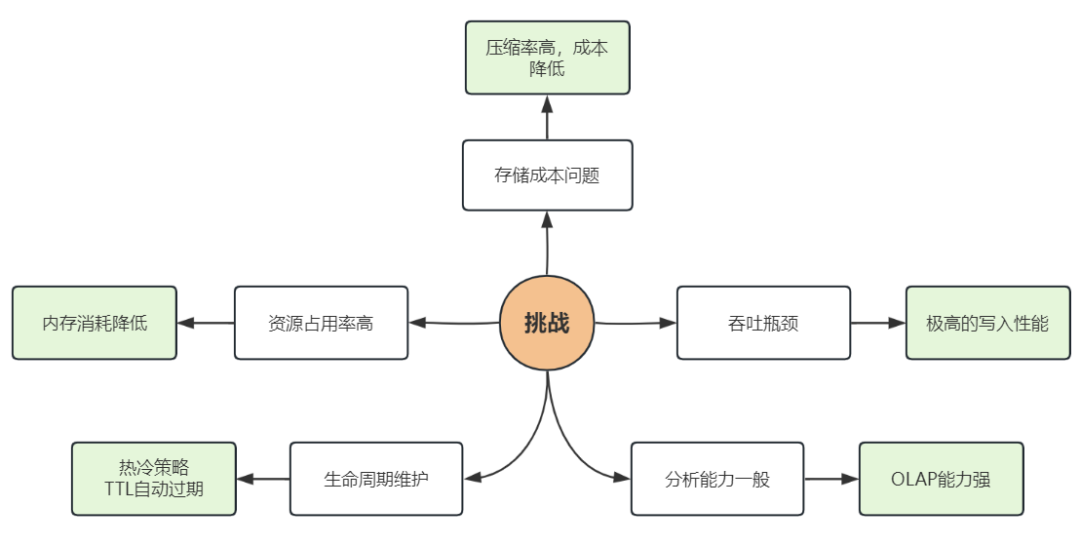
使用ELK一段时间之后,我们解决了从无到有的问题。但随着一系列基于日志进行分析和告警的工作逐步开展,新的问题也开始浮现。我们尝试进行优化后,效果并不明显,这促使我们重新考量架构的升级,主要的问题体现在:
-
成本问题:ES压缩率不高,基于目前的日志量,合规性要求需要保留6个月,需要耗费巨大的存储成本;
-
吞吐瓶颈:ES分词特性写入吞吐瓶颈问题,容易导致日志写入发生延迟;
-
资源占用率高:ES在内存使用上的消耗过高;
-
生命周期维护:ES旧版本TTL问题,需要手工介入数据过期,维护成本高;
-
分析能力一般:由于更多的分析需求出现,ES的聚合能力受到了挑战。
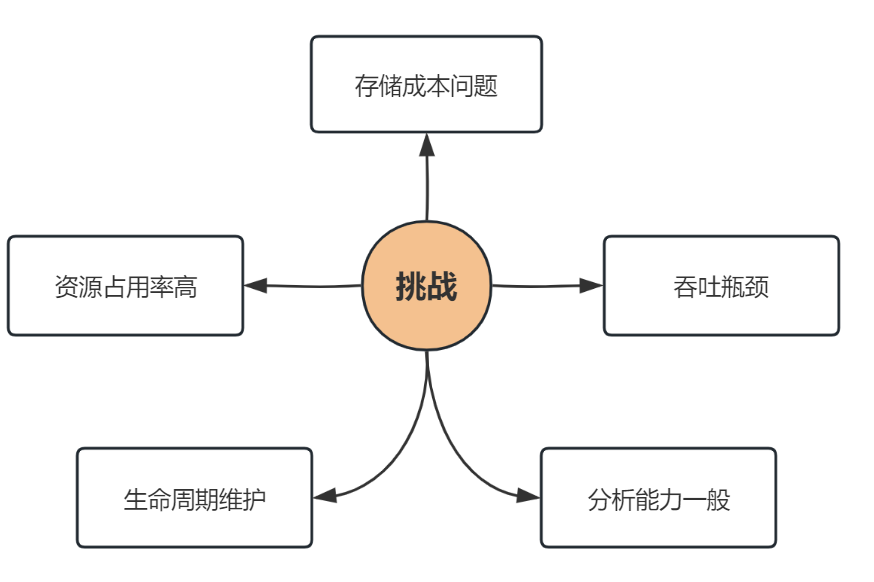
针对上述的一些问题,在2020年开始了解到Clickhouse的存在,我们对ES和Clickhouse做了一个选型对比。基于对比得出的结论,最终决定选用 Clickhouse 做为下一代日志存储数据库。
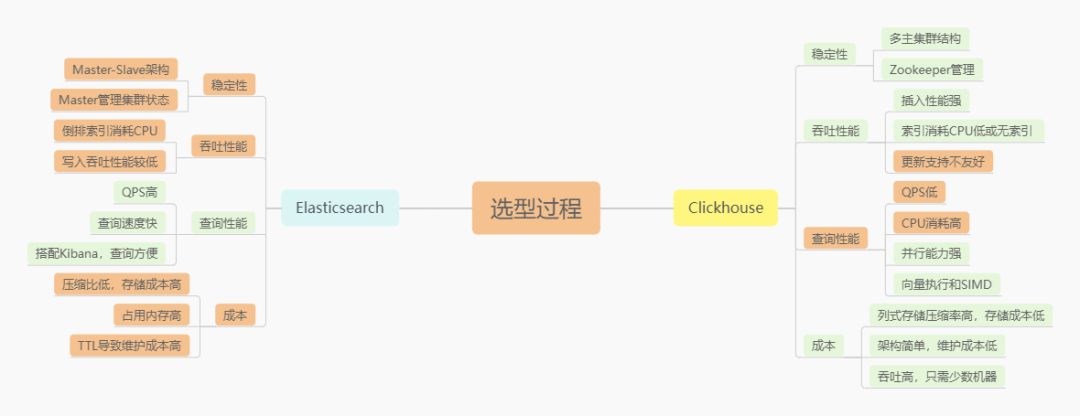
新的架构体系
ELK体系经过多年的发展,生态已经非常强大,Clickhouse想达到同样的生态,需要更长的时间去发展,因此这个过程也需要投入一些研究或者开发量才能达到更好的效果,幸好 Clickhouse 本身的学习曲线较低,经过短时间的研究,我们制定了新的日志架构。
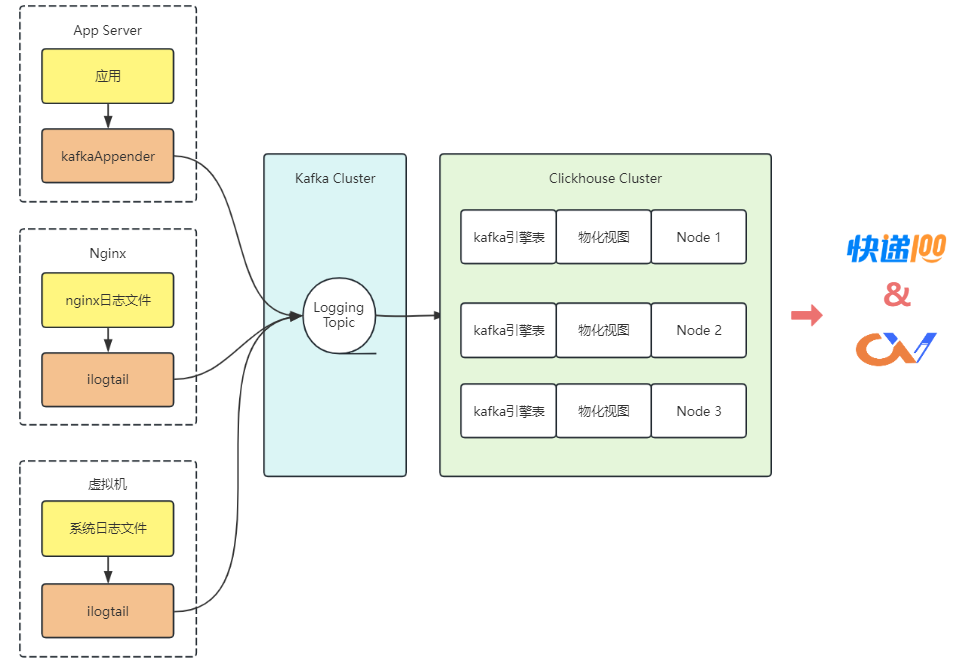
可以从几个组件的构成来看这个架构图,对比ELK体系与新的体系的不同:
-
采集层:从Logstash到ilogtail,ilogtail性能更强,资源消耗更低;
-
处理层:从Logstash到ilogtail,ilogtail还支持数据脱敏,多行拆分等实用功能;
-
存储层:从Elasticsearch改为Clickhouse,选型过程已有对比,这里不再赘述;
-
可视化:从Kibana到Clickvisual,这里有优点也有缺点,所以还是配合了Grafana才达到类似的效果。
Clickvisual的优点:灵活的SQL、日志审计、告警策略;Kibana的优点:Kibana具备一些基础的BI功能,可用于日志分析。
1、新架构的成果
还是回顾一下之前的挑战,问题基本得到了解决:
2、基于Clickhouse的日志存储
基于10亿日志数据进行测试,得出磁盘占用的对比柱状图:

基于10亿数据的测试,在两者集群模式下,消费Kafka的速度对比:

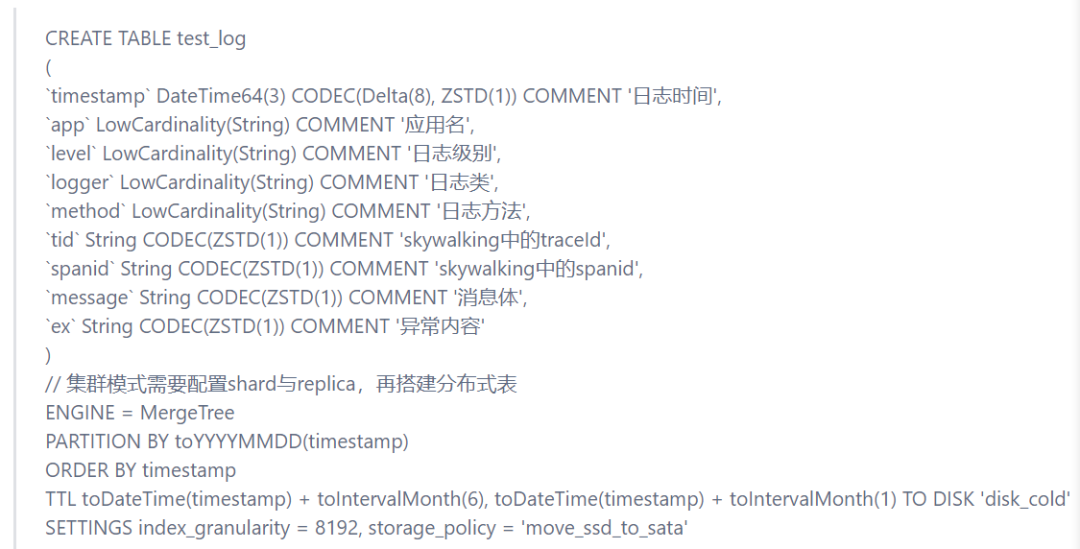
新的架构最核心的改变,就是将ES换成了Clickhouse,看中的就是极高的压缩率,最终的结果是同等存储条件下,原来ES只能保留一个月的数据,现在可以做到保留六个月,这其中少不了很多存储细节的优化,其中包含:
-
大部分字段采用ZSTD压缩模式来提升压缩率;
-
低基数LowCardinality的使用,节省存储的同时还做到性能提升;
-
连续性时间字段的Delta+ZSTD压缩;
-
冷热策略的配置,近一个月保留在SSD盘,一到六个月的数据自动流到HDD盘,六个月前数据自动清理。
建表语句如下:
3、基于Clickvisual的可视化
ClickVisual 是一个轻量级的开源日志查询、分析、报警的可视化平台,致力于提供一站式应用可靠性的可视化的解决方案。既可以独立部署使用,也可作为插件集成到第三方系统。目前是市面上唯一一款支持 ClickHouse 的类 Kibana 的开源业务日志查询平台。
-
它具备的特性,部分符合我们的需求:
-
支持可视化的查询面板,可查询命中条数直方图和原始日志;
-
支持设置日志索引功能,分析不同索引的占比情况;
-
支持 Proxy Auth 功能,能被非常轻松地集成到第三方系统;
-
支持基于 ClickHouse 日志的实时报警功能。
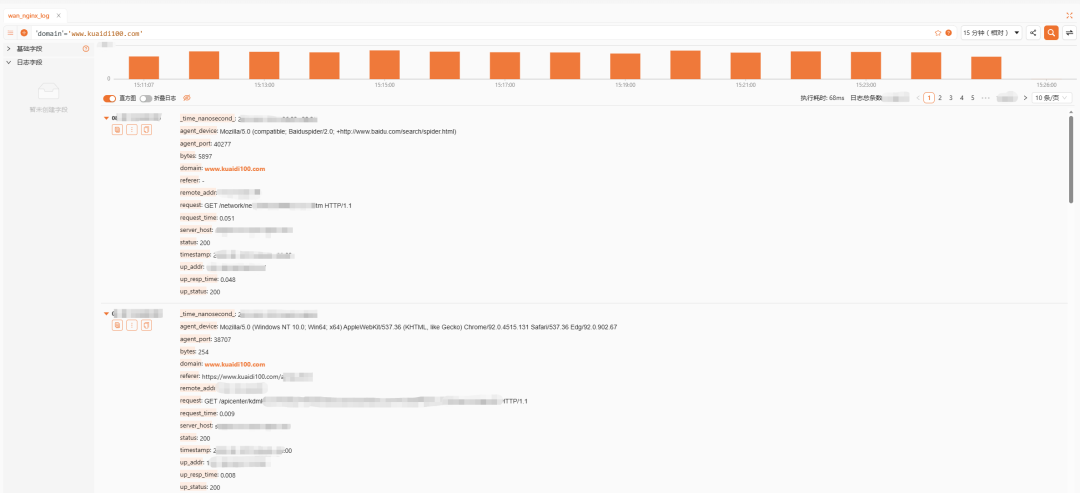
还提供了原始的SQL查询功能,直接输入SQL聚合语句,即时简单地对日志进行聚合分析:
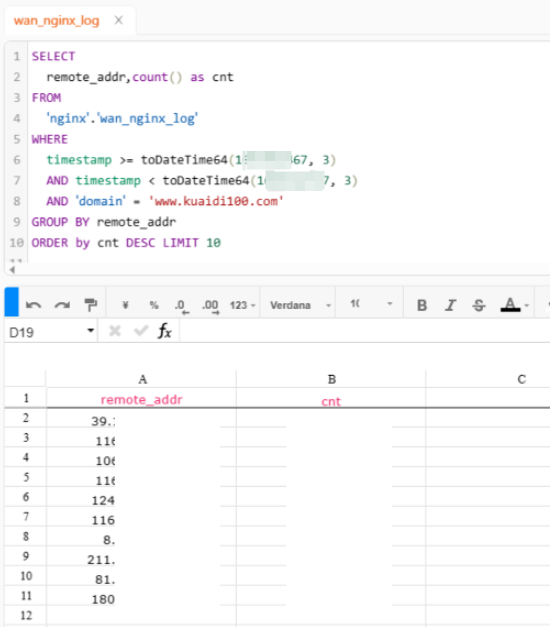
体验总体类似Kibana,细节稍有不足,通过这个查询分析界面作为一个入口,搭配日志告警模块,快速定位问题和故障排除方面的能力得到了大大的提升,基本无缝从Kibana上切换过来,拥有不错的排障体验。
进一步优化
诚然,做到上述的效果还是不足以满足我们的要求。因而在此基础上,我们进行了优化方面的思考 ,其中也踩了一些Clickhouse的坑,使用了一些Clickhouse的新特性,是一个很有意思的过程。
1、日志查询优化探索
得益于Clickhouse的高压缩率和查询性能,小日志量的表直接配合时间分区搜索即可,但是当日志量涨到一定程度的时候,查询缓慢总是一个难受的事,我们对一些场景进行了总结:
-
traceid场景:在 Skywalking 中根据 traceid 查询链路日志时,使用 tokenbf_v1索引,并通过 hasToken 查询,由于跳过大部分无效 parts,可快速命中返回;
-
无结构化日志:对于这种无结构化日志,用 like 性能会非常慢且消耗 CPU 甚至内存,新版本的 Clickhouse 已经支持了倒排索引,也开始基于倒排— 索引优化,可大大提高响应速度;
-
聚合场景:一些常规的聚合需求,可通过Clickhouse的Projection功能来满足。
2、本地表还是分布式表
本地表是Clickhouse的存储表,分布式表只是逻辑表,本身并不存储数据,在日志高频写入的场景,还是推荐写本地表,原因有这么几点:
-
当我们大批量写入日志时,可以直接往分布式表写,但数据会先拆分成不同parts,再通过Zookeeper进行分发,增加了集群间网络的负载,导致- 写入变慢,甚至出现Too many parts问题;
-
写分布式表更容易出现数据一致性问题;
-
Zookeeper压力变大。
3、Clickhouse的限制策略
随着日志中心的建设,日志体量越来越大,开始暴露一些配置层面的问题,我们开始对 Clickhouse 增加一些限制,以免错误的 SQL 导致集群缓慢甚至 OOM 的问题,对于日志查询用户,单独做了 SQL 复杂度的限制,users.xml 中有几个参数:
-
max_memory_usage:单个服务器上运行查询的最大内存;
-
max_memory_usage_for_user:单个服务器上运行用户查询的最大内存;
-
max_memory_usage_for_all_queries:单个服务器上运行所有查询的最大内存;
-
max_rows_to_read:运行查询时可从表中读取的最大行数;
-
max_result_rows:限制结果中的行数;
-
max_bytes_to_read:运行查询时可以从表中读取的最大字节数(未压缩数据)。
结 语
在这篇文章中,我们分享了快递100在云原生技术方面的实践、思考和应用,特别是在日志中心建设方面的实践。日志中心的上线应用,让我们在问题定位方面的效率得到了极大的提升,系统更加稳定和可靠;同时,通过对日志的收集、分析和挖掘,我们也更好地了解了用户需求和行为,优化了产品设计和运营策略,促进业务高速增长。
来源:本文转自公众号百递云,文章略有精简。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Java开发工具IDEA
- 西南科技大学数据库实验四(SELECT查询操作—简单查询)
- 【MATLAB基础绘图第20棒】云雨图
- 未来的城堡世界
- 20240122在WIN10下给GTX1080配置CUDA驱动
- 网络安全(黑客)技术——自学2024
- Jmeter接口自动化测试 —— Jmeter变量的使用
- 三端负电源电压调节器79LXX,具有一系列固定电压输出,适用于小于100mA电源供给的场合
- Gitlab集成openLDAP统一认证登录
- Android简单控件