Kafka-消费者-KafkaConsumer分析-offset操作
提交offset
在进行消费者正常消费过程中以及Rebalance操作开始之前,都会提交一次offset记录Consumer当前的消费位置。提交offset的功能也是由ConsumerCoordinator实现的。
先来了解OffsetCommitRequest和OffsetCommitResponse的消息体格式,如图所示。
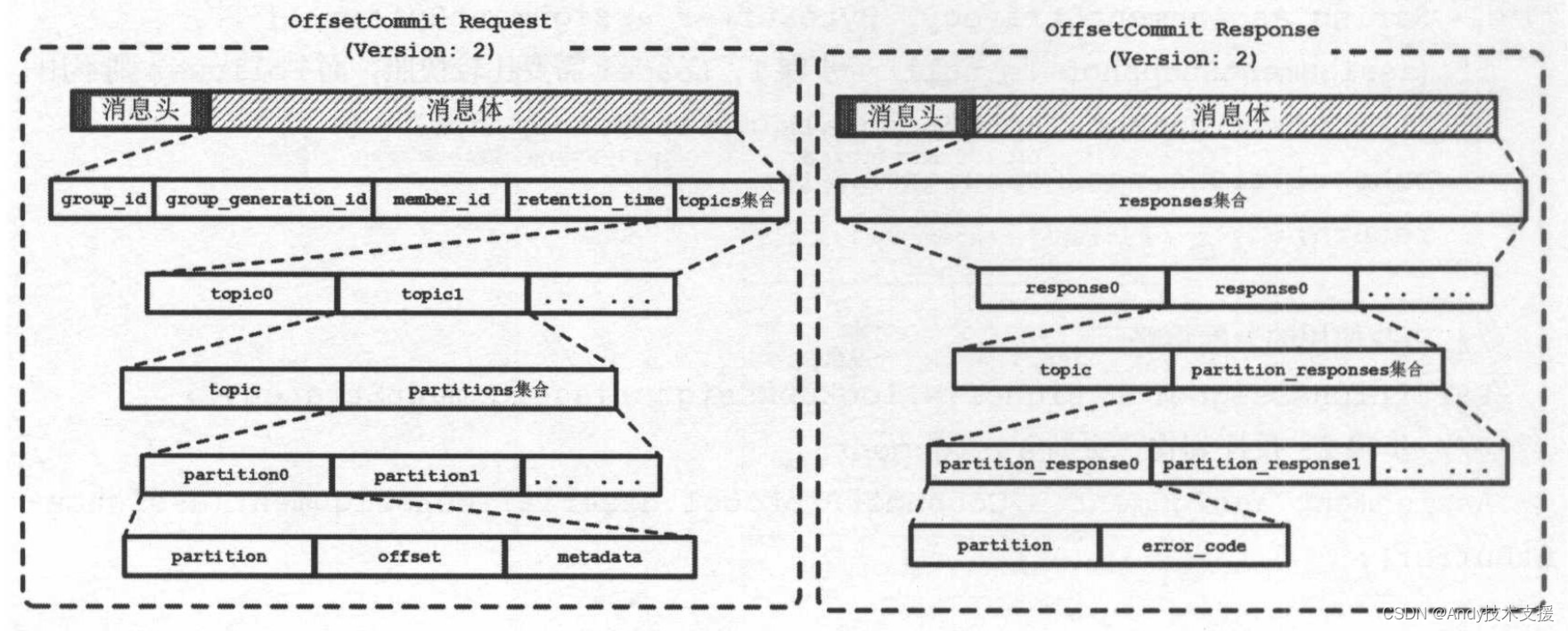
OffsetCommitRequest中各个字段的含义如表所示。
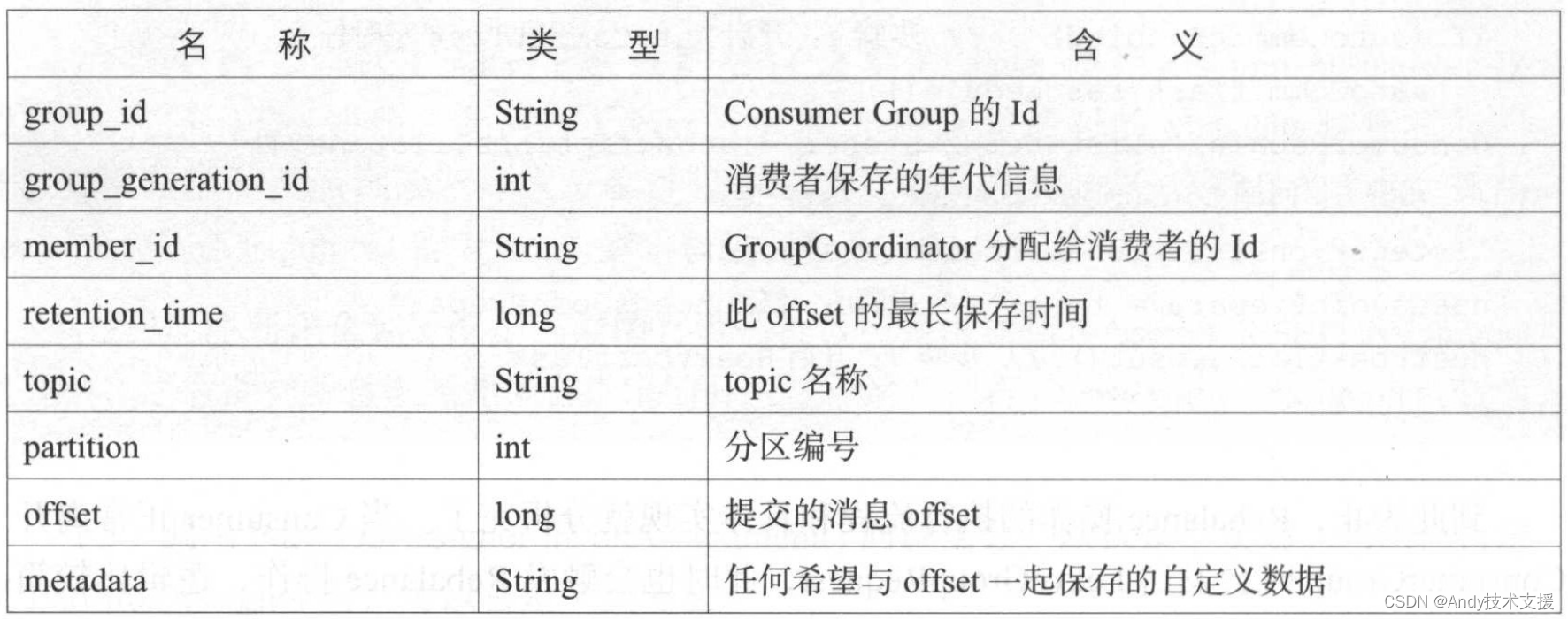
OffsetCommitResponse中各个字段的含义如表所示。

图展示了ConsumerCoordinator中与提交offset相关的四个方法以及它们之间的调用关系。

在SubscriptionState中使用TopicPartitionState记录了每个TopicPartition的消费状况,TopicPartitionState.position字段则记录了消费者下次要从服务端获取的消息的offset。
当没有明确指定待提交的offset值时,则将TopicPartitionState.position作为待提交offset,组织成集合,形成ConsumerCoordinator.commitOffset*()方法的第一个参数。
commitOffsetsSync()方法与commitOffsetsAsync()方法的实现类似,也是调用sendOffsetCommitRequest()方法创建并缓存OffsetCommitRequest,使用OffsetCommitResponseHandler处理OffsetCommitResponse。
但是有两点不同:
一是commitOffsetsSync()方法在发送OffsetCommitRequest时使用了ConsumerCoordinator.poll(future)阻塞等待OffsetCommitResponse处理完成,这样才实现了同步提交的功能;
二是commitOffsetsSync()方法在检测到RetriableException异常时会进行重试。commitOffsetsSync()方法的具体代码就不贴出来了。maybeAutoCommitOffsetsSync()方法会根据enable.auto.commit配置项的值决定是否调用commitOffsetsAsync()方法。
AutoCommitTask是一个定时任务,它周期性地调用commitOffsetsAsync()方法,实现了自动提交offset的功能。开启自动提交offset功能后,业务逻辑中就可以不用手动调用commitOffsets*()方法提交offset了。AutoCommitTask的代码比较简单。
OffsetCommitResponseHandler.handle方法是处理OffsetCommitResponse的入口。
fetch offset
在Rebalance操作结束之后,每个消费者都确定了其需要消费的分区。在开始消费之前,消费者需要确定拉取消息的起始位置。假设之前已经将最后的消费位置提交到了GroupCoordinator,GropeCoordinator将其保存到了Kafka内部的Offsets Topic中,此时消费者可以通过OffsetFetchRequest请求获取上次提交offset并从此处继续消费。
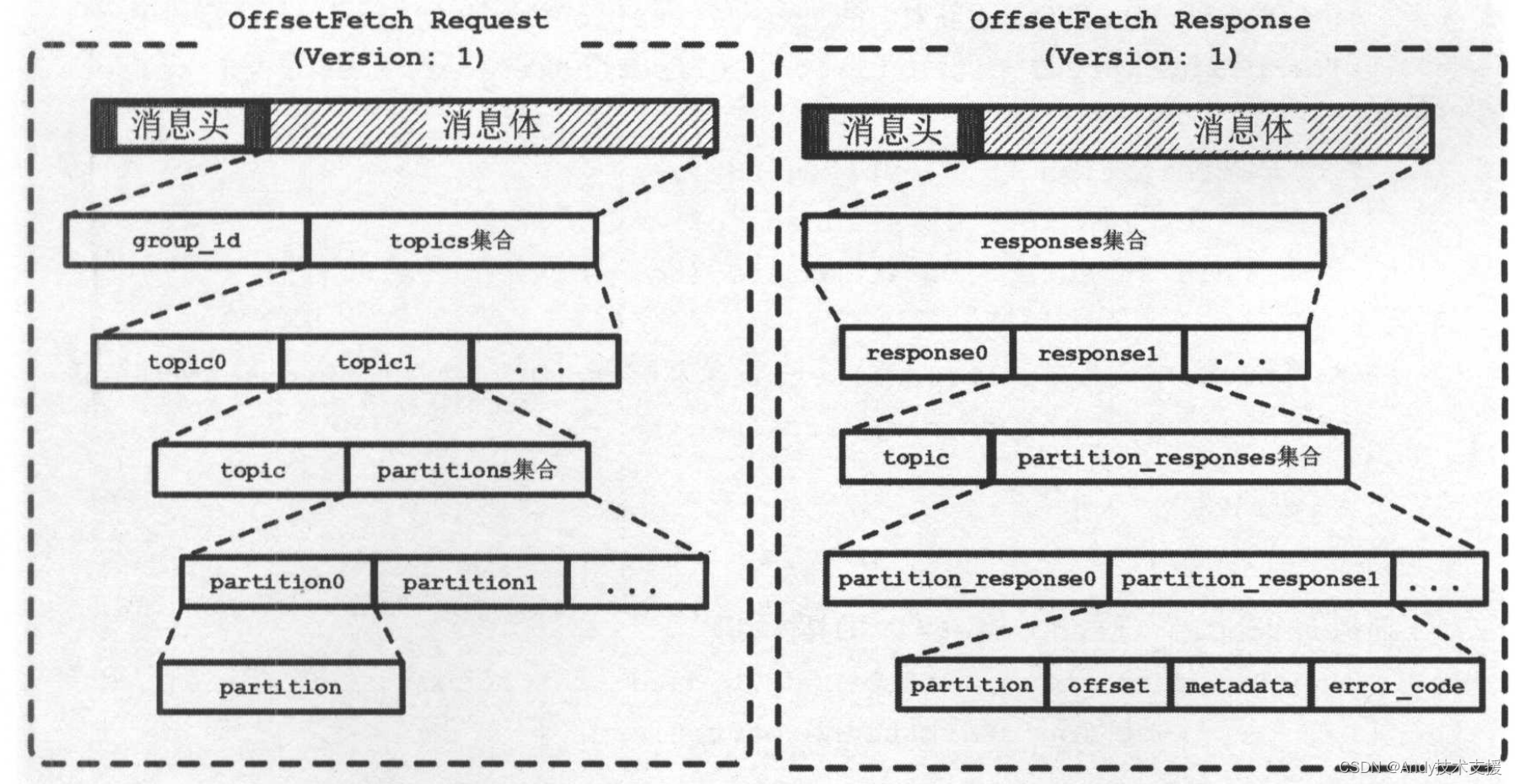

refreshCommittedOffsetsIfNeeded方法的主要功能是发送OffsetFetchRequest请求,从服务端拉取最近提交的offset集合,并更新到Subscriptions集合中。
Fetcher
Fetcher类的主要功能是发送FetchRequest请求,获取指定的消息集合,处理FetchResponse,更新消费位置。图是Fetcher类依赖的组件。
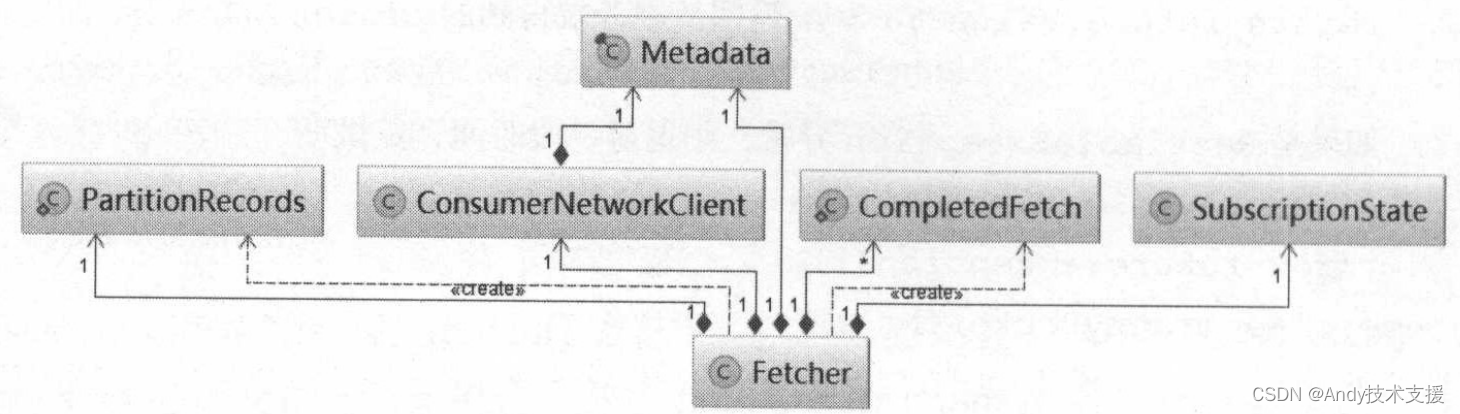
先来了解Fetcher的核心字段。
- client:ConsumerNetworkClient,负责网络通信。
- minBytes:在服务端收到FetchRequest之后并不是立即响应,而是当可返回的消息数据积累到至少minBytes个字节时才进行响应。这样每个FetchResponse中就包含多条消息,提高网络的有效负载。
- maxWaitMs:等待FetchResponse的最长时间,服务端根据此时间决定何时进行响应。
- fetchSize:每次fetch操作的最大字节数。
- maxPollRecords:每次获取Record的最大数量。
- metadata:记录了Kafka集群的元数据。
- subscriptions:记录每个TopicPartition的消费情况。
- completedFetches:List类型,每个FetchResponse首先会转换成CompletedFetch对象进入此队列缓存,此时并未解析消息。
- keyDeserializer、valueDeserializer:key和value的反序列化器。
- nextInLineRecords:PartitionRecords类型。PartitionRecords保存了CompletedFetch解析后的结果集合,其中有三个字段:records是消息集合,fetchOffset记录了。
records中第一个消息的offset,partition记录了消息对应的TopicPartition。
Fetcher的核心方法可以分为三类:fetch消息的相关方法,用于从Kafka获取消息;更新offset相关的方法,用于更新TopicPartitionState中的position字段;获取Metadata信息的方法,用于获取指定Topic的元信息。
Fetch消息
首先来了解FetchRequest和FetchResponse的消息体的格式,如图所示。
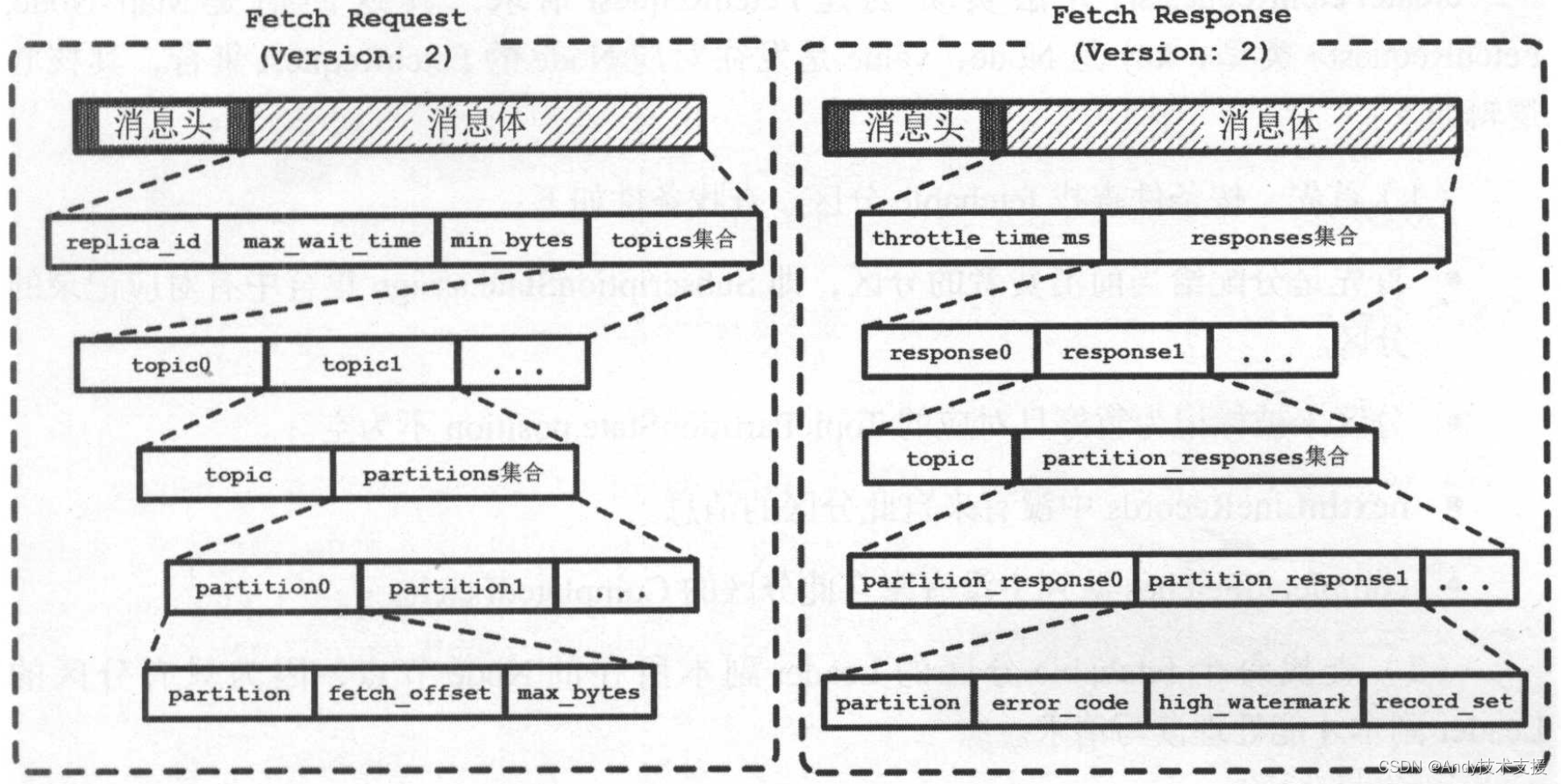
FetchRequest中的字段如表所示。

FetchResponse中的字段如表所示。

createFetchRequests()方法负责创建FetchRequest请求,其返回值是Map<Node,FetchRequest>类型,key是Node,value是发往对应Node的FetchRequest集合,其核心逻辑如下:
- 首先,按条件查找fetchable分区。查找条件如下:
- 首先是分配给当前消费者的分区,即SubscriptionState.assign集合中有对应记录的分区。
- 分区未被标记为暂停且对应的TopicPartitionState.position不为空。
- nextInLineRecords中没有来自此分区的消息。
- completedFetches队列中没有来自此分区的CompletedFetch。
- 查找每个fetchable分区的Leader副本所在的Node节点,因为只有分区的Leader副本才能处理读写请求。
- 检查步骤2中找到的Node节点,如果其在unsent集合或InFightRequest中的对应请求队列不为空,则不对此Node发送FetchRequest请求。
- 通过SubscriptionState查找每个分区对应的position,并封装成PartitionData对象。
- 最后,按照Node进行分类,将发往同一Node节点的所有TopicPartition封装成一个FetchRequest对象。
sendFetches方法的主要功能是将FetchRequest添加到unsent集合中等待发送,并注册FetchResponse处理函数。
FetchResponse的处理主要是解析FetchResponse后按照TopicPartition分类,将获取到的消息数据(未解析的byte数组)和offset组装成CompletedFetch对象并添加到completedFetches。
存储在completedFetches队列中的消息数据还是未解析的FetchResponse.PartitionData对象。
在fetchedRecords方法中会将CompletedFetch中的消息数据进行解析,得到Record集合并返回,同时还会修改对应TopicPartitionState的position,为下次fetch操作做好准备。
更新position
在有些场景下,例如第一次消费某个Topic的分区,服务端的内部Offsets Topic中并没有记录当前消费者在此分区上的消费位置,所以消费者无法从服务端获取最近提交的offset。
此时如果用户手动指定消费的起始offset,则可以从指定offset开始消费,否则就需要重置TopicPartitionState.position字段。
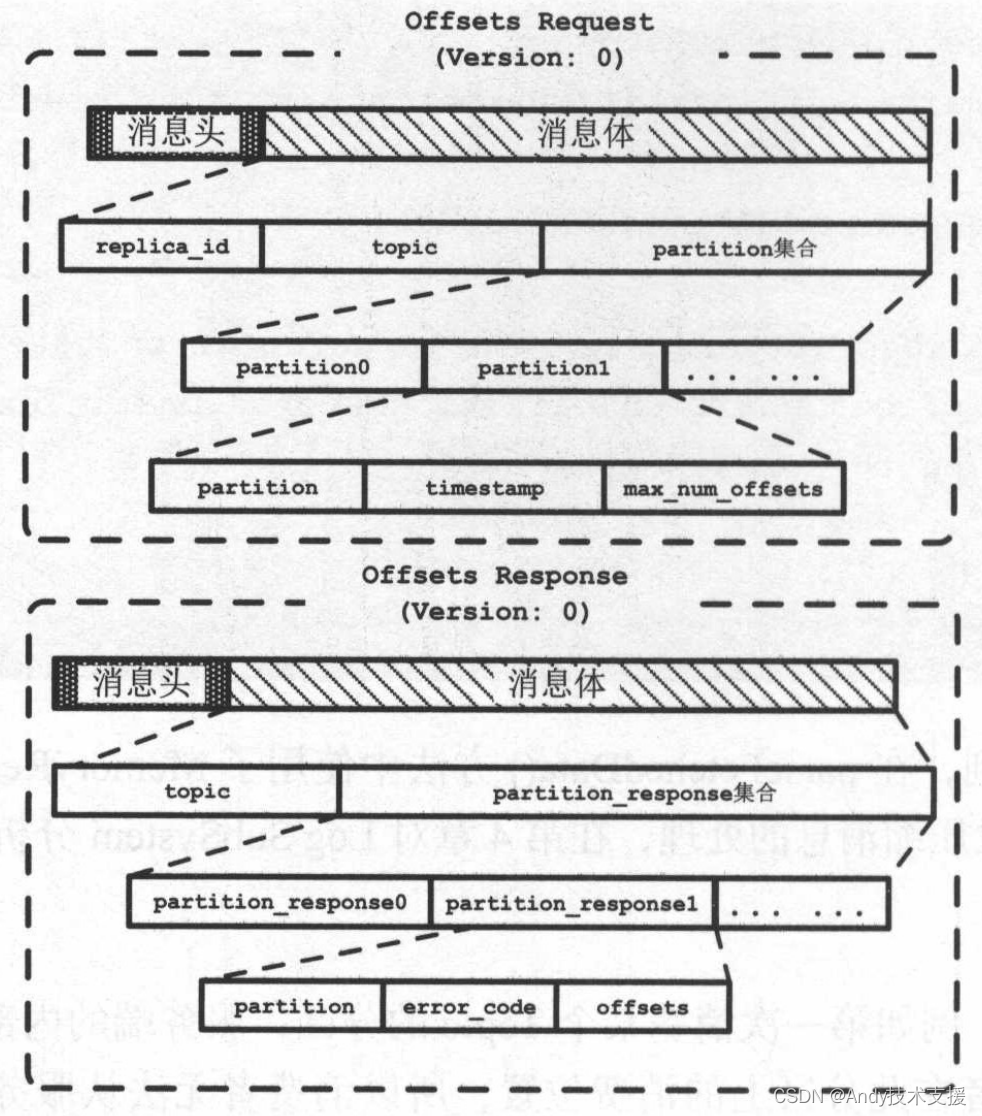
重置TopicPartitionState.position字段的过程中涉及OffsetsRequest和OffsetsResponse,先来介绍其格式,如图所示。
在OffsetsRequest中需要说明的字段是timestamp,取值为-1或-2,分别表示LATEST、EARLIEST两种重置策略。
在OffsetsResponse中需要说明的字段是offsets,它是服务端返回的offset集合。
Fetcher.updateFetchPositions方法中实现了重置TopicPartitionState.position字段的功能,其具体逻辑如下:
- 检测position是否为空,如果非空则不需要重置操作。
- 如果设置了resetStrategy,则按照指定的重置策略进行重置操作。
- 有EARLIEST、LATEST两种策略:EARLIEST策略是将position重置为当前最小的offset;而LATEST则是将position重置为当前最大的offset。
- 上面的两种策略都会向GroupCoordinator发送OffsetsRequest,请求指定的offset。OffsetsRequest的发送逻辑和OffsetsResponse的处理逻辑与前面介绍的类似。
- 如果没有指定重置策略,则将position重置为committed。
- 如果committed为空,则使用默认的重置策略。默认重置策略是LATEST策略。
获取集群元数据
在Fetcher中还提供了获取Metadata信息的相关方法。涉及sendMetadataRequest、getTopicMetadata、getAllTopicMetadata三个方法,其调用关系如图所示。
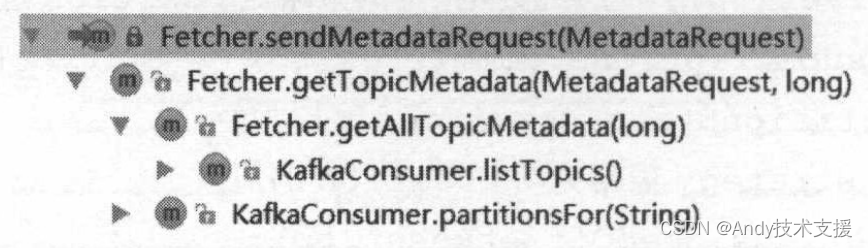
基本逻辑是发送MetadataRequest请求到负载最小的Node节点,并阻塞等待MetadataResponse,正常收到响应后对其解析,得到需要的集群元数据。
需要注意的是,Fetcher提供的这三个获取集群元数据的相关方法并不会更新Fetcher.metadata字段中保存的集群元数据。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!