第9章:深度探讨知识问答系统评测:智能背后的挑战与技术方案
💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

作者参考了百分点认知实验室在 CCKS 2020 评测任务“知识图谱的自然语言问答”中的技术方案。
🍋知识问答系统概述
在当今数字化信息爆炸的时代,知识问答系统以其高效解决用户问题的能力逐渐成为人工智能领域的热门话题。这种系统通过自然语言处理和机器学习技术,使计算机能够理解和回答用户提出的问题,为用户提供更智能化的服务。
🍋知识问答系统定义
知识问答系统是一种基于人工智能技术的应用,旨在通过处理自然语言,从结构化和非结构化的数据中提取信息,以回答用户提出的问题。与传统搜索引擎相比,知识问答系统更注重精准、直接的回答,为用户提供更加智能、便捷的信息服务。
🍋知识问答问题分类
- 事实型问题
这类问题通常要求系统提供特定的事实性信息,如“地球的直径是多少?”或“谁是美国第一位总统?”
- 推理型问题
推理型问题需要系统具备一定的逻辑推理能力,能够根据已有知识得出结论,例如“如果今天是星期五,那么后天是星期几?”
- 开放性问题
开放性问题通常较为复杂,要求系统从大量信息中综合考虑并给出合理的回答,如“讲解一下人工智能的发展历史与未来趋势。”
🍋 知识问答评测技术方案
- 人工评测
通过人工评测,专家评估系统在特定问题上的表现。这种方法能够提供高质量的评估结果,但成本较高,且可能受到评估者主观因素的影响。
- 自动评测
利用自动化指标和度量标准,如准确率、召回率、F1值等,对系统性能进行客观评估。自动评测具有高效、成本低等优势,但对于一些复杂任务可能无法全面覆盖系统表现。
- 基准测试集
构建丰富多样的基准测试集,涵盖不同类型的问题和知识领域,以确保系统在多样性场景下的性能稳定性。
- 用户反馈
通过用户使用反馈,收集真实场景下系统表现的数据,了解用户需求和期望,为系统优化提供有力支持。
🍋自然语言知识问答评测
书中分别从自然语言、生活服务、开放知识问答评测进行讲解,时间问题本篇博客主要以自然语言知识问答评测为主要介绍点
🍋任务背景
随着知识图谱技术的进一步发展,问题理解和问题到知识图谱的语义关联都得到了较好的解决,这使得基于知识图谱的知识问答工程应用成为现实。为了进一步推动知识图谱技术的发展以及知识问答在具体行业的应用落地,CCKS 2020 以行业知识为核心构建了多个高质量的数据集(http://openkg.cn/group/coronavirus),并将这些数据集整合到一起,同开放领域知识库 PKUBAS一起作为问答任务的依据,开展本次评测任务。
这里面的数据集还算十分丰富的
🍋数据分析
此次知识问答评测需要使用NLP 技术理解问并进行查询构造,数据集由自然语言问句和对应的SPAROL查询语句标记组成。
下面以数据集中的典型问题(一跳、夹式、夹式+多跳)为例进行介绍
问题 1:凯文·杜兰特得过哪些奖?
查询语句:select ?x where {<凯文·兰特><主要奖项>?x.}
答案:“7次全明星(2010-2016”“5次NBA最佳阵容一阵(2010-2014”“NBA得分王(2010-2012;2014“NBA全明星赛MVP (2012”“NBA 常规赛MVP(2014)
以上就是一跳问题“凯文·杜兰特得过哪些奖?”的具体示例。该问题的查询路径如图9-7所示。

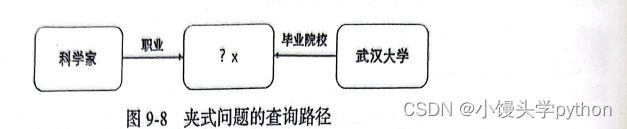
问题2:武汉大学出了哪些科学家?
查询语句:select ?x where {?x<职业><科学家_(从事科学研究的人群)>.?x<毕业院校><武汉大学>.}
答案:“<郭传杰><张贻明><刘西尧><石正丽><王小村>”
以上就是夹式问题"武汉大学出了哪些科学家?"的具体例子如下
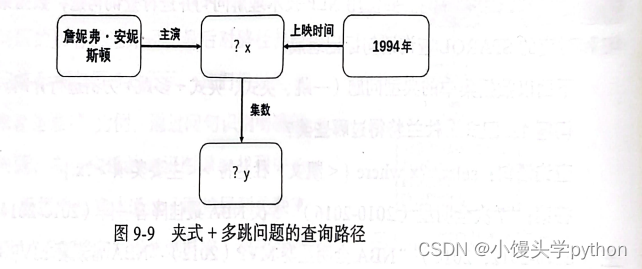
问题3:詹妮弗·安妮斯顿出演了一部 1994 年上映的美国情景剧,这部美剧共有多少集?
查询语句: select?y where {?x<主演><詹妮弗·安妮斯顿>.?x<上映时间>"“1994"”.?x<集数>?y.)
答案:“236”
以上就是夹式+多跳问题“詹妮弗·安妮斯顿出演了一部1994 年上映的美国情景剧这部美剧共有多少集?”的具体示例。
🍋技术方案
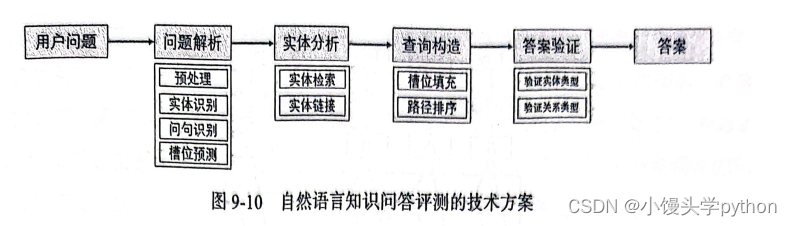
下图展示了一个完整的技术方案的全流程
下面以问题“莫妮卡·贝鲁的代表作是什么?”为例,详说明该技术方案中的步骤
问题解析
预处理:
在这里可以看做分词,在中文分词领域,国内科研机构推出多种分工具(以基于规则和典方为)如,哈工大的LTP、中科院计算所的NLPIR、清华大学的THULAC和Python中文分词组件 Jieba 等。
实体识别:
在命名实体识别过程中,采用预训练模型+长短期记忆网络+条件随机场(BERT+LSTM+CRF)的方法对自然语言问句中的命名实体进行识别。首先通过BERT预训练模型对命名实体进行识别,再使用Bi-LSTM 网络对子中每个词语的实体类型进行预测(不包含实体、实体头、实体中、实体尾),最后利用 CRF 过滤不合理的预测结果,使得最终输出的结果更加“平顺”。
具体结构如下图
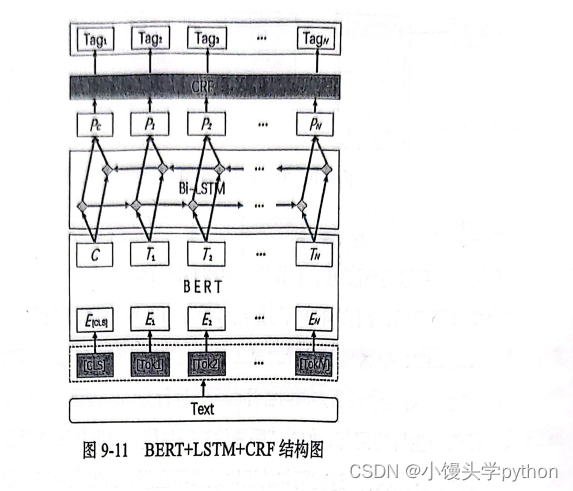
通过命名实体识别得到名为“莫妮卡·贝鲁奇”的实体指称,将该实体指称输入别名词典和分布式搜索分析引擎 Elasticsearch 中,得到备选实体。接下来,将用户问题输人问句结构分类模型中,以进行问句识别,得到该问题属于一跳问题。
在槽位预测过程中:
根据问题的分类,即可得知有哪几个语义槽需要填充。一跳问题“莫妮卡·贝鲁奇的代表作是什么?”对应的查询语句为“select ?x where <莫妮卡·贝鲁奇>代表作品>?x.)”, 括号内的结构**<莫妮卡·贝鲁奇><代表作品><?x.>分别对应主语、谓语、宾语**,还需要填充实体<莫妮卡·贝鲁奇 >、关系<代表作品>、查询宾语 <?x.>。因此,通过槽位预测进一步得知该问题有一个实体槽位和一个关系槽位需要填充。
注意:槽位(Slot)通常指的是一个语义单元,用于填充特定信息或实体。在提到问题“莫妮卡·贝鲁奇的代表作是什么?”时,槽位预测的结果是需要填充一个实体槽位和一个关系槽位。具体地,实体槽位需要填充的是主语(<莫妮卡·贝鲁奇>),而关系槽位需要填充的是谓语(<代表作品>)。
实体分析
对根据实体识别步骤得到的备选实体进行实体检索,并将检索的结果进行实体链接通过语义特征和人工特征进行实体消歧,得到真正的实体为<莫妮卡·贝鲁奇 >。
查询构造
在知识问答过程中,查询构造旨在根据问题的实体和关系槽位填充,构造出问题的候选查询路径,通过路径排序筛选出正确查询路径,根据此路径在知识图谱中查找相应的实体目标,以作为问题的最终答案。
先根据槽位预测步骤预测的槽位进行实体的槽位填充,将实体填充到该查询语句中,得到查询语句“select ?x where 莫妮卡·贝鲁奇>?x.”。然后搜索<莫妮卡·贝鲁奇>的所有关系名称,和原文进行语义匹配并进行路径排序,得到关系<代表作品>。再将代表作品填人槽位预测所预测的关系槽位中,进行关系的槽位填充,得到查询语句“select ?xwhere <莫妮卡·贝鲁奇代表作品?x”,并转化为知识查询语言最后将得到的知识库查询语言在知识库中查询并得到答案:《西西里的美丽传说》《狼族盟约》《不可撤销》《重装上阵》等。
查询构造过程的根本目标是提高查询路径的召回率。这里涉及两种不同类型的问句第一种类型,带约束的单关系问句。例如“谁是美国第一任总统?”,答案实体和实体“美国”之间只有一个“总统”的关系,但是也有“第一”的约需要被满足。针对这类复杂问题,提出了一种分阶段查询图生成方法,首先确定单跳关系路径,然后对其添加约束形成查询图。第二种类型,有多个关系跳跃的问句。例如“谁是又x 公司创给人的妻子?”,答案与“xx公司”有关,问句包含两种关系,即“创始人”和“妻子”。针对这类多跳问题,需要考虑更长的关系路径,以获取正确的答案。这里需要考虑限制搜索空间,即减少需要考虑的多跳关系路径的数量,因为搜索空间随着关系路径的长度呈指数级增长。因此,需要采取集束搜索(Beam Search)算法或根据数据构造特定的剪枝规则,减少产生的查询路径。待候选查询路径产生后,须在候选路径中使用排序模型(如深度模型ESIMBiMPM、Siamese LSTM等)进行评分,选择排序第一的查询路径作为最选择的路径。
接下来,讲解一下基于计算句子相似度的排序方法一一孪生网络(Siamese LSTM)。孪生网络是指网络中包含两个或两个以上完全相同的子网络,多应用于语句相似度计算、人脸匹配、签名鉴别等任务上。孪生网络语义匹配方法的工作流程图如下图。
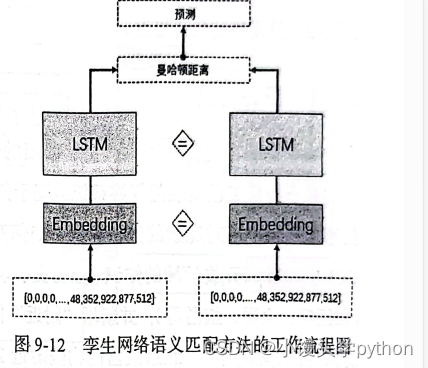
两个句子输入后将其映射为一个向量,这里的词嵌入和编码(LSTM)参数相同,然后使用曼哈顿距离计算两边向量的差距,进而得出预测结果。
通过孪生网络方法,可以计算候选查询路径和查询问题的匹配得分,选出得分第一的查询路径作为最终选择的路径。
答案验证
答案验证模块的主要作用是验证答案的实体类型和关系类型,确定最终问题答案:莫妮卡·贝鲁奇的代表作有《西西里的美丽传说》《狼族盟约《不可撤销《重装上阵》等。
🍋实验结果
识别效果:F1平均值=0.901
识别性能:在NVTDIA 2080Ti GPU上,单词问答平均响应时间约200ms。

挑战与创造都是很痛苦的,但是很充实。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 揭秘跨境电商ERP源码定制化需求及最佳实践
- C++之函数名后面的const
- 前十天猫代运营公司服务商排名???
- 数据截取处理、富文本去除所有标签
- 2024-01-18
- 2023自动化测试框架大对比:哪个更胜一筹?
- 【RabbitMQ】RabbitMQ安装与使用详解以及Spring集成
- CPO-BP回归 基于冠豪猪优化算法[24年新算法]-BP神经网络 (多输入单输出) 多变量回归预测
- Blender:从新手到专家的全方位指南
- 单聊和群聊