Kafka集群架构原理(待完善)
发布时间:2023年12月22日
kafka在zookeeper数据结构
controller选举
客户端同时往zookeeper写入, 第一个写入成功(临时节点), 成为leader, 当leader挂掉, 临时节点被移除, 监听机制监听下线,重新竞争leader, 客户端也能监听最新leader
leader partition自平衡
leader不均匀时, 造成某个节点压力过大, 达到阈值时, 会触发自平衡, 均匀分配leader, 默认头节点
partition故障恢复机制
Leo:?每个Partition的最后一个Offset
HW:?一组Partiton中最小的LEO
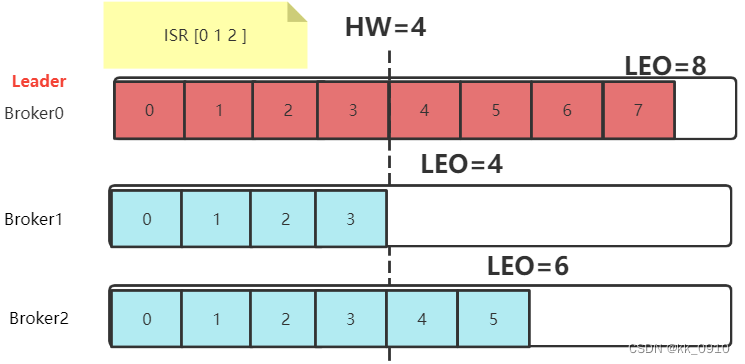
HW一致性保障
当Leader切换时, 可能产生HW不一致 ,Kafka设计Epoch保证HW一致性
文章来源:https://blog.csdn.net/weixin_64027360/article/details/135142854
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 谁知道try里面放return,finally还会执行吗?
- Android 车联网——CarDiagnosticService介绍(十八)
- 电商数据api接口商品详情API接口及代码展示案例
- 【后端】深入浅出Node.js
- 用全志R128复刻自平衡赛车机器人,还实现了三种不同的操控方式
- GLOBALCHIP GC3909替代A3909/allegro电机驱动芯片产品参数分析,应用于摇头机,舞台灯,打印机,白色家电等
- 《剑指 Offer》专项突破版 - 面试题 15 : 字符串中的所有变位词(C++ 实现)
- 一万六千字大章:Chrome 浏览器插件 V3 版本 Manifest.json 文件全字段解析
- 深度学习美化图片,绝对可行,美化效果挺好 DPED
- 绝地求生:天使与恶魔套装评测: 面具名片均可单买!