Flink实时电商数仓之DWS层
发布时间:2023年12月28日
需求分析
- 关键词
- 统计关键词出现的频率
IK分词
进行分词需要引入IK分词器,使用它时需要引入相关的依赖。它能够将搜索的关键字按照日常的使用习惯进行拆分。比如将苹果iphone 手机,拆分为苹果,iphone, 手机。
<dependency>
<groupId>org.apache.doris</groupId>
<artifactId>flink-doris-connector-1.17</artifactId>
</dependency>
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
</dependency>
测试代码如下:
public class IkUtil {
public static void main(String[] args) throws IOException {
String s = "Apple 苹果15 5G手机";
StringReader stringReader = new StringReader(s);
IKSegmenter ikSegmenter = new IKSegmenter(stringReader, true);//第二个参数表示是否再对拆分后的单词再进行拆分,true时表示不在继续拆分
Lexeme next = ikSegmenter.next();
while (next!= null) {
System.out.println(next.getLexemeText());
next = ikSegmenter.next();
}
}
}
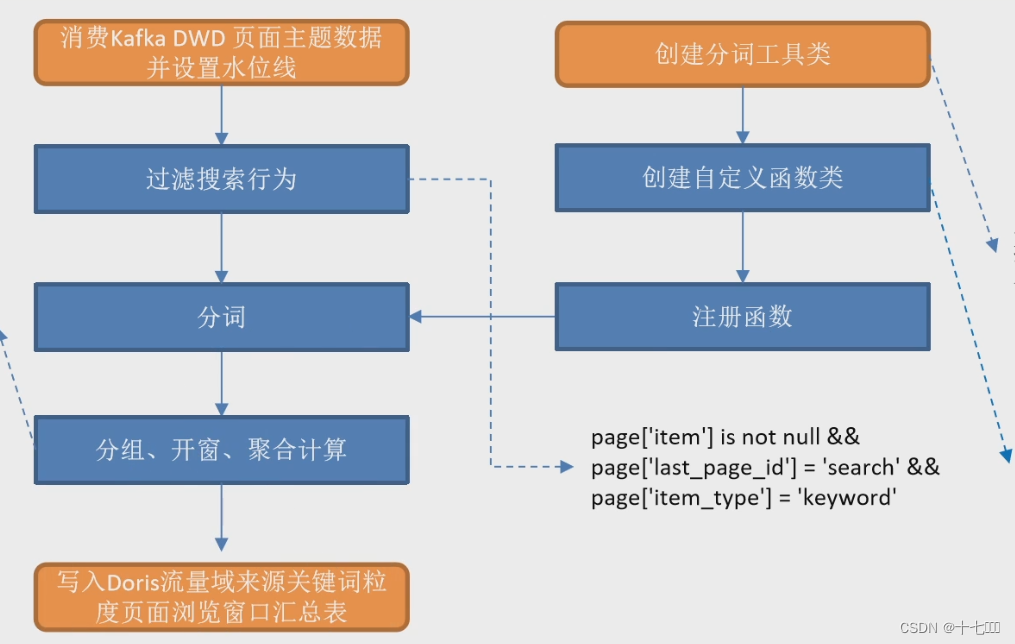
整体流程
- 创建自定义分词工具类IKUtil,IK是一个分词工具依赖
- 创建自定义函数类
- 注册函数
- 消费kafka DWD页面主题数据并设置水位线
- 从主流中过滤搜索行为
- page[‘item’] is not null
- item_type : “keyword”
- last_page_id: “search”
- 使用分词函数对keyword进行拆分
- 对keyword进行分组开窗聚合
- 写出到doris
- 创建doris sink
- flink需要打开检查点才能将数据写出到doris
具体实现
public void handle(StreamTableEnvironment tableEnv, StreamExecutionEnvironment env, String groupId) {
// 核心业务处理
// 1. 读取主流DWD页面主题数据
createPageInfo(tableEnv, groupId);
// 2. 筛选出关键字keywords
filterKeywords(tableEnv);
// 3. 自定义UDTF分词函数 并注册
tableEnv.createTemporarySystemFunction("KwSplit", KwSplit.class);
// 4. 调用分词函数对keywords进行拆分
KwSplit(tableEnv);
// 5. 对keyword进行分组开窗聚合
Table windowAggTable = getWindowAggTable(tableEnv);
// 6. 写出到doris
// flink需要打开检查点才能将数据写出到doris
createDorisSink(tableEnv);
windowAggTable.insertInto("doris_sink").execute();
}
文章来源:https://blog.csdn.net/qq_44273739/article/details/135236762
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Jan AI本地运行揭秘:首次体验,尝鲜科技前沿
- 基于redis的分布式锁实现方案
- Linux C语言 52-IO复用之select
- Java多线程&并发篇----第二十三篇
- NPDP产品经理必备证书!主要考什么?怎么考?
- 《MetaGPT智能体开发入门》学习笔记 第三章 MetaGPT框架组件介绍
- 03 MyBatisPlus之条件构造器Wrapper+核心注解
- 【工具与中间件】Git&GitHub相关知识与一些问题解决、工具推荐
- 【ASP.NET Core 基础知识】--MVC框架--Views和Razor语法
- GZ015 机器人系统集成应用技术样题6-学生赛