KG+LLM(一)KnowGPT: Black-Box Knowledge Injection for Large Language Models

论文链接:2023.12-https://arxiv.org/pdf/2312.06185.pdf
1.Background & Motivation
目前生成式的语言模型,如ChatGPT等在通用领域获得了巨大的成功,但在专业领域,由于缺乏相关事实性知识,LLM往往会产生不准确的回复(即幻觉)。许多研究人员企图通过外部知识注入提高LLM在专业领域的表现,但许多最先进的llm都不是开源的,这使得仅向模型api注入知识具有挑战性。
研究发现KGs中存储的大量事实知识有可能显著提高LLM反应的准确性,所以解决上述问题的一个可行方法是将知识图(KGs)集成到LLM中。在此基础上本文提出了一个向LLM的进行黑盒知识注入框架KnowGPT。KnowGPT包括两部分:①利用深度强化学习(RL)从知识图(KGs)中提取相关知识;②并使用多臂赌博机(MAB)为每个问题选择最合适的路径抽取策略和提示。
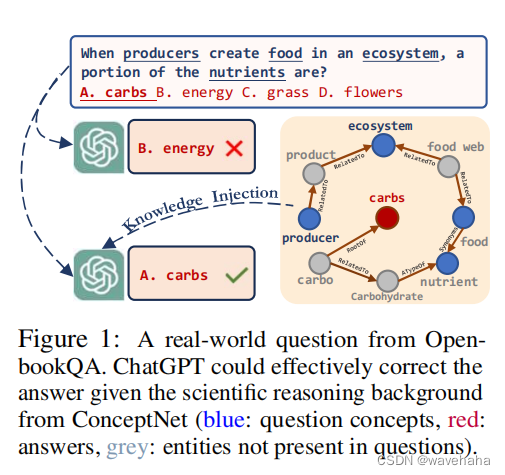
现有的KG+LMs的方法有很多:
但许多最先进的LLM只能通过黑盒调用,即只能通过提交文本输入来检索模型响应,而无法访问模型细节。因而无法使用上述的白盒知识注入技术。(尽管白盒方法可以应用于开源LLMs,如BLOOM和LLaMA,但由于更新模型权重,往往会产生显著的计算成本。)因此,本文关注:能否开发一个黑盒知识注入框架,能够有效地将KG集成到仅使用API的LLM中?
在解决该问题时需要关注两个挑战:①如何检索KG;②如何编码、利用检索到的信息。
2.问题定义
给定一个问题上下文 Q = { Q s , Q t } Q=\{Q_s,Q_t\} Q={Qs?,Qt?}( Q s = { e 1 , . . . , e m } Q_s=\{e_1,...,e_m\} Qs?={e1?,...,em?}为问题实体集合, Q t = { e 1 , . . . , e n } Q_t=\{e_1,...,e_n\} Qt?={e1?,...,en?}为答案实体集合),一个LLM f f f ,和一个知识图谱 G G G, G G G包含三元组(头实体,关系,尾实体),表示为 ( h , r , t ) (?,r,t) (h,r,t),目标是学习一个提示函数 f p r o m p t ( Q , G ) f_{prompt}(Q,G) fprompt?(Q,G),生成一个提示 x x x,将 Q Q Q的上下文和 G G G中的事实知识结合起来,使得LLM的预测能够输出 Q Q Q的正确答案。
3.KnowGPT Framework
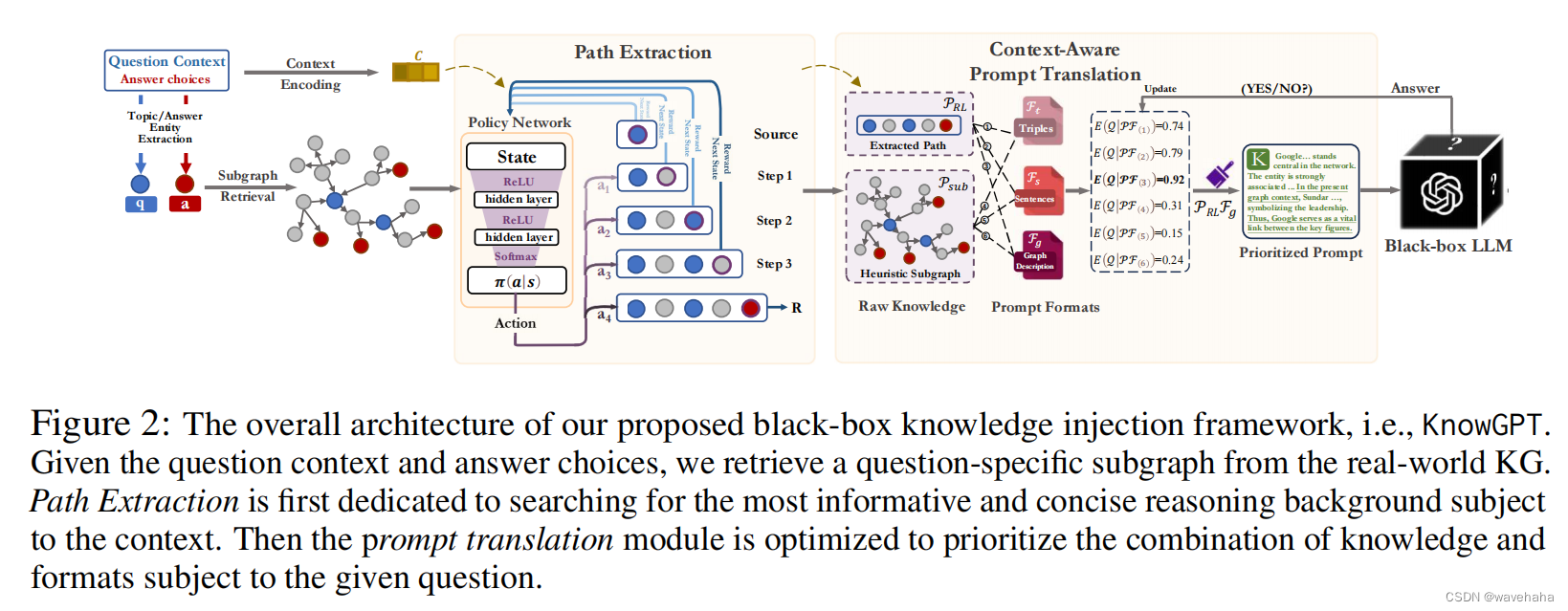
KnowGPT根据问题背景和答案选项,从现实世界的知识图谱中检索出一个问题特定的子图。首先,路径提取模块寻找最具信息量和简洁推理背景来适应上下文。然后,优化提示转换模块,考虑给定问题的知识和格式的最佳组合。
3.1 如何检索KG:强化学习(Reinforcement Learning, RL)
利用奖励函数激励RL提取KG子图中有关问题中提到的源实中到潜在答案中的目标实体的路径 P = { P 1 , . . . , P m } P=\{P_1,...,P_m\} P={P1?,...,Pm?}。且 P i = { ( e 1 , r 1 , t 1 ) , ( t 1 , r 2 , t 2 ) , . . . , ( t ∣ P i ∣ ? 1 , r ∣ P i ∣ , t ∣ P i ∣ ) } P_i=\{(e_1,r_1,t_1),(t_1,r_2,t_2),...,(t_{|P_i|-1},r_{|P_i|},t_{|P_i|})\} Pi?={(e1?,r1?,t1?),(t1?,r2?,t2?),...,(t∣Pi?∣?1?,r∣Pi?∣?,t∣Pi?∣?)}。RL使用策略梯度。其马尔可夫过程定义如下:
-
状态: 表示知识图谱中当前的位置,表示从实体?到t的空间变化。状态向量 s s s定义为 s t = ( e t , e t a r g e t ? e t ) s_t=(e_t,e_target?e_t) st?=(et?,et?arget?et?)。为了获得从背景知识图谱中提取的实体的初始节点嵌入,将知识图谱中的三元组转换为句子,并将其输入预训练语言模型中以获取节点嵌入。
-
动作: 包含当前实体的所有邻近实体。通过采取行动,模型将从当前实体移动到选择的邻近实体。
-
动作转移概率P: 转移模型的形式为 P ( s ’ ∣ s , a ) = 1 P(s’|s,a)=1 P(s’∣s,a)=1,如果通过动作 a a a将 s s s到达 s ’ s’ s’;否则 P ( s ’ ∣ s , a ) = 0 P(s’|s,a)=0 P(s’∣s,a)=0。
-
奖励函数包括: 提取路径的可达性、上下文相关性和简洁性。
- 路径的可达性: 如果在K个行动内达到目标,将获得奖励+1。否则,将获得奖励?1。
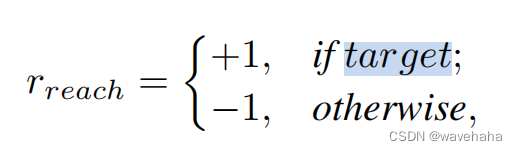
- 上下文相关性: 路径与上下文越相关,越应该被奖励
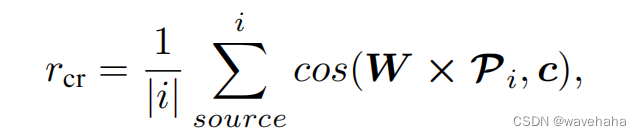
- 简洁性: 基于黑盒LLMs对输入长度的限制和调用成本考虑,引导的提示需在最短的路径长度内找到尽可能多有价值的信息。
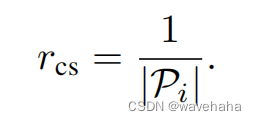
- 路径的可达性: 如果在K个行动内达到目标,将获得奖励+1。否则,将获得奖励?1。
-
最终奖励函数:
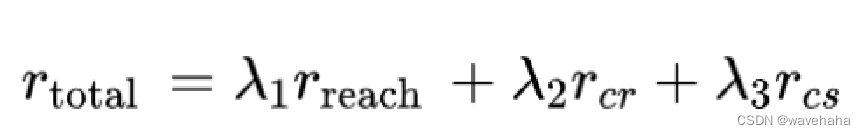
3.2 如何利用检索到的KG: Prompt Construction with Multi-armed Bandit
MAB: 多臂赌博机MAB有许多“臂”,每次选择一个“臂”进行尝试,都会得到一个结果或奖励。一方面,希望“利用”那些之前表现良好的“臂”,可以在短时间内获得最大的奖励。另一方面,也想“探索”那些之前没有尝试过的“臂”,可能发现更好的策略或选择,从而在未来获得更大的奖励。
基于该原理,提示构建就是要想办法选择最有前途的提示。(多种方法组合,有点类似集成学习,但不一样)
假设有几种路径提取策略 P 1 , . . . , P m P_1,...,P_m P1?,...,Pm?和几种候选提示格式 F 1 , . . . , F n F_1,...,F_n F1?,...,Fn?。每个路径提取策略 P i P_i Pi?是一种在给定问题环境下选择子图的方法,每个提示模板 F j F_j Fj?代表一种将子图中的三元组转化为LLM预测的提示机制。
提示构建问题是要确定给定问题的最佳
P
P
P和
F
F
F的组合。本文将选择的整体过程定义为一个奖励最大化问题
m
a
x
∑
r
P
F
max\sum{r_{PF}}
max∑rPF?,其计算如下:
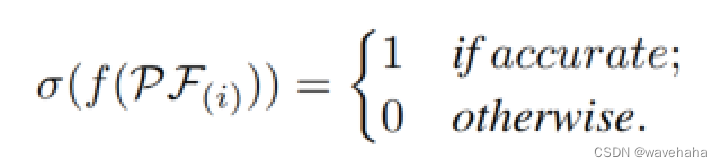
为了捕捉问题与不同知识和提示格式组合间的上下文感知相关性, 文章使用期望函数
E
(
?
)
E(·)
E(?)来确定多臂赌博机的选择机制。它能自适应地衡量不同问题对某个组合的潜在期望。
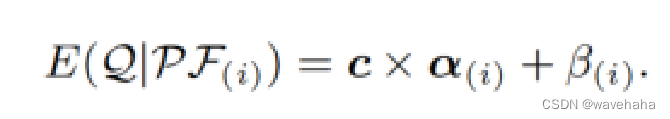
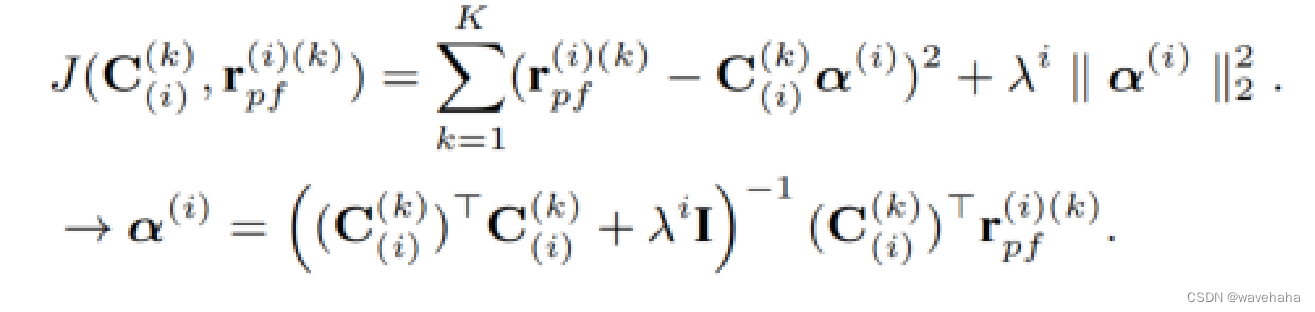

J
J
J表示最小二乘训练LOSS,
β
(
i
)
β^(i)
β(i)通过最大置信上界(UCB)计算。通过最大化期望函数
E
(
?
)
E(·)
E(?),LLM学会了平衡开发和探索,以优先选择最有前途的提示来回答特定的问题背景。
4. Implementation
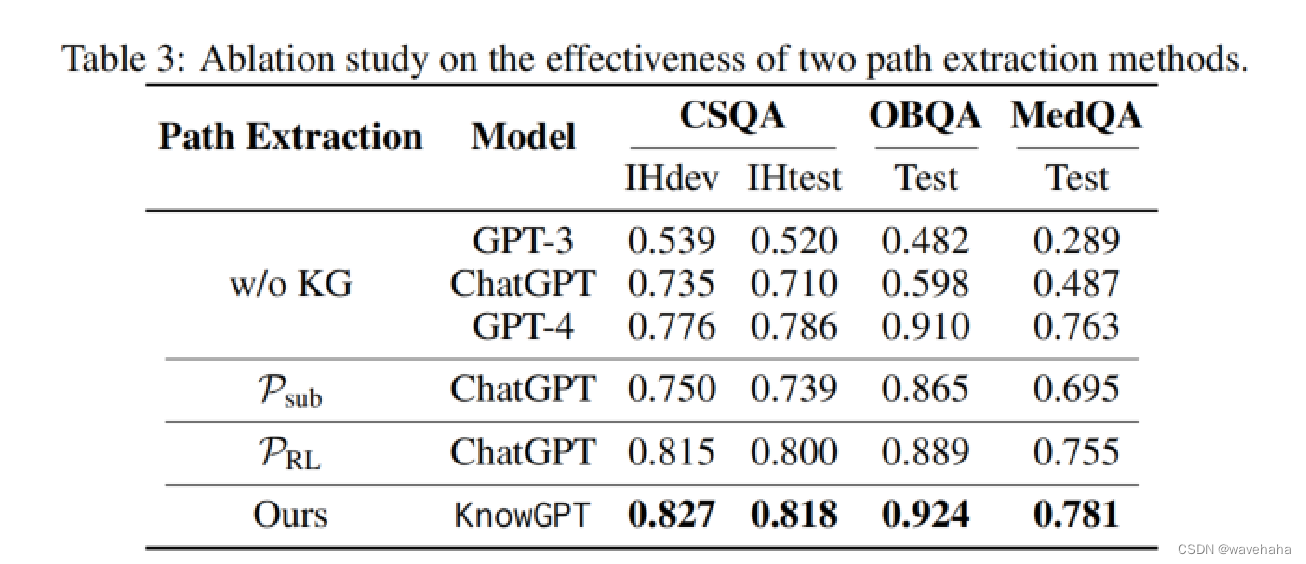
- 路径抽取策略(两种):
- P R L P_{RL} PRL?:基于强化学习的路径提取策略。
- P s u b P_{sub} Psub?:由于强化学习不够稳健,引入 P s u b P_{sub} Psub?作为MAB选择的备选策略。这是一种启发式的子图提取策略,在源实体和目标实体周围提取2跳子图。
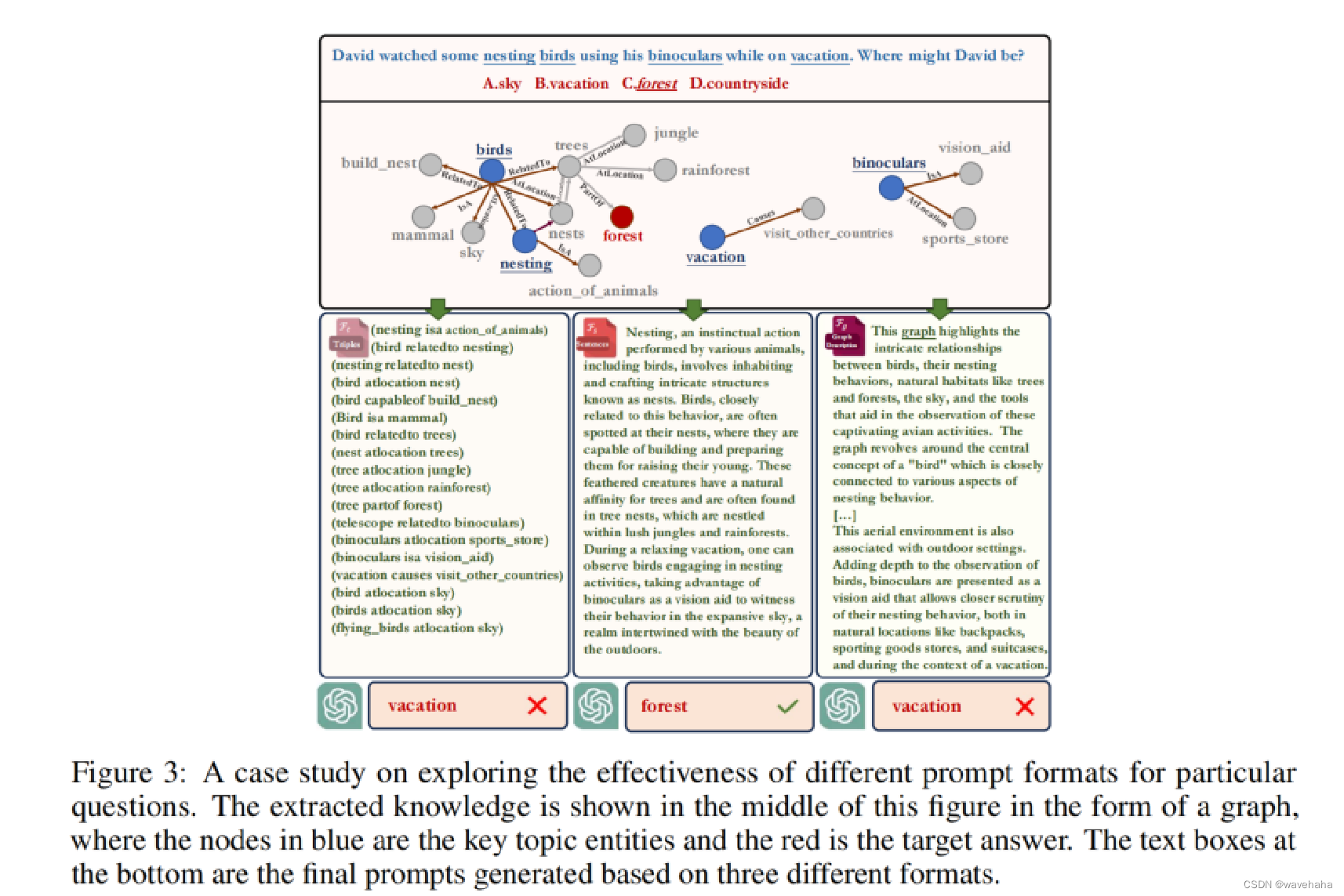
- Prompt(三种):
- 三元组 F t F_t Ft?:例如(Sergey_Brin, founder_of,Google)。
- 句子描述 F s F_s Fs?:将知识转化为口语化句子。
- 图表描述
F
g
F_g
Fg?:将知识视为结构化图表来激活LLM。通过使用黑盒LLM预处理提取的知识,突出中心实体生成描述。
MAB通过来自语言模型的反馈进行训练,以优先选择在不同实际问题背景下最合适的两种提取方法和三种预定义提示格式的组合。
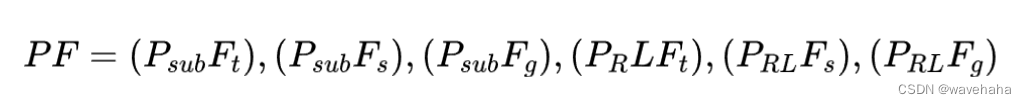
5. Experiments
5.1 实验设置
关注问题:
RQ1: How does KnowGPT perform when compared with the state-of-the-art LLMs and KG_x0002_enhanced QA baselines?
RQ2: Does the proposed MAB-based prompt construction strategy contribute to the performance?
RQ3: Can KnowGPT solve complex reasoning tasks, and is KG helpful in this reasoning process?
数据集: 选用CommonsenseQA(多项选择题问答数据集),OpenBookQA(多项选择题),MedQA-USMLE(医学多项选择题)。
Base: ChatGPT
5.2 对比实验
整体表现:
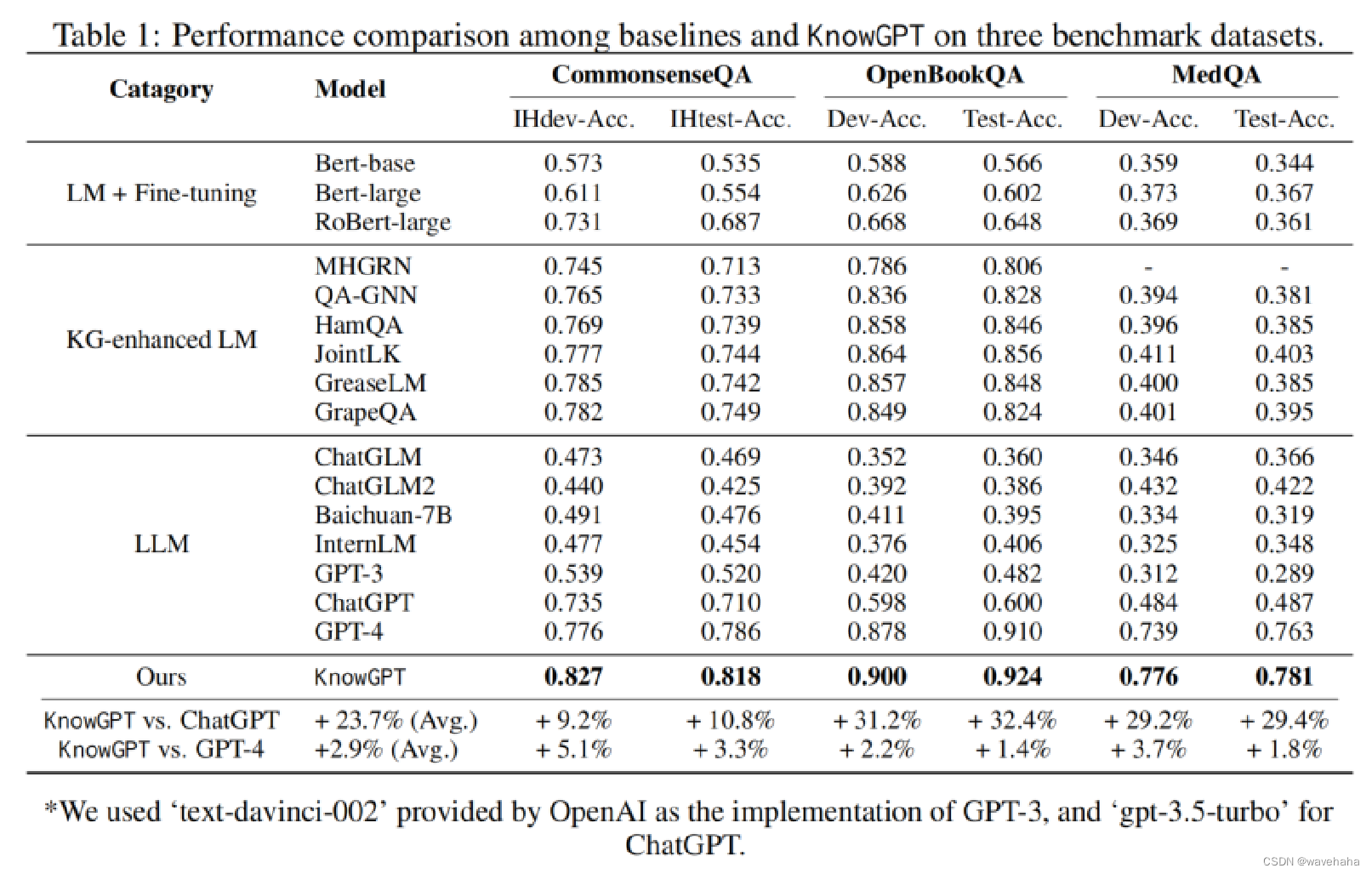
与其他KG+LMs方法对比
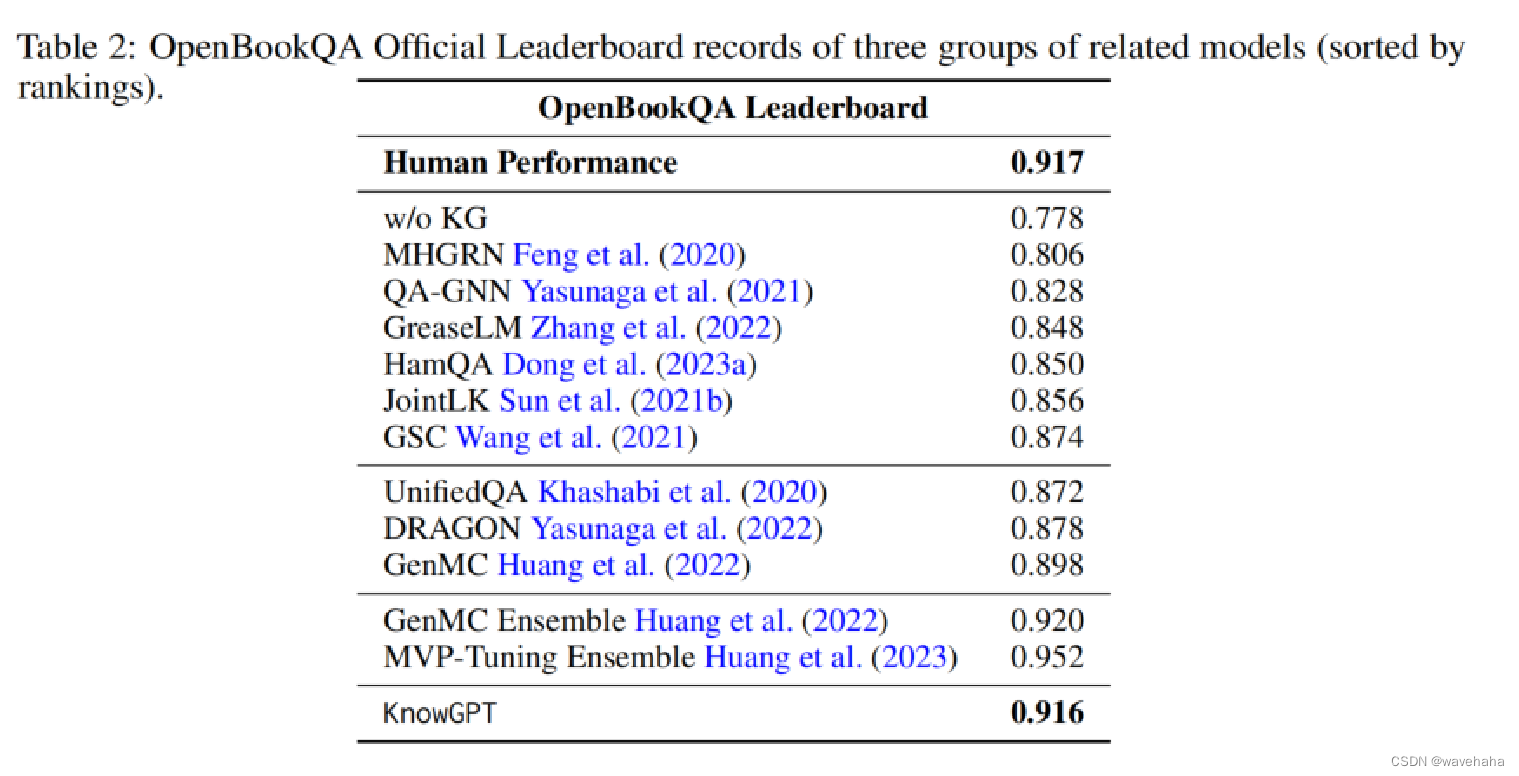
5.3 消融实验
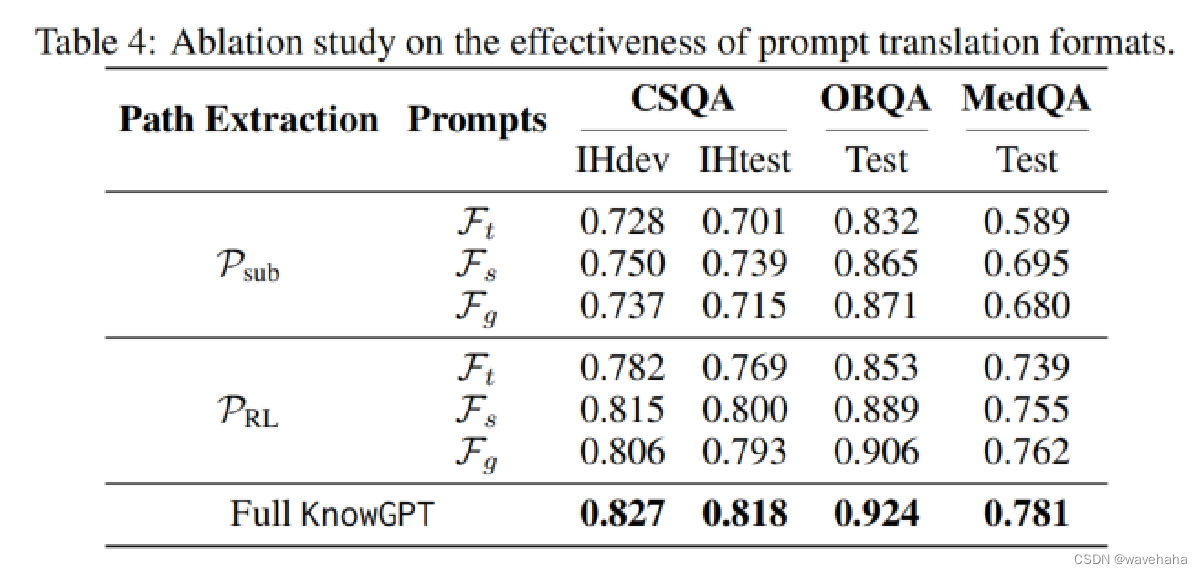
5.4 case study-多提示融合的有效性
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何用CHAT如何设置vuex 和Storage?
- c# OpenCvSharp 轮廓绘制六步骤你学会了吗(六)
- springboot实现用户操作日志记录
- Jmeter 性能测试 —— 评估一个系统TPS与并发数!
- PyTorch实战:基于Seq2seq模型处理机器翻译任务(模型预测)
- Sync and Refresh Project to update the path.
- 【C++11/17】std::map高效插入
- 多边形的裁剪:一种基于有效边表的有效多边形裁剪算法的分析
- go从0到1项目实战体系八:struct结构体
- Universal Approximation Capabilities of Mixture of Weibulls (混合韦布尔分布的万能近似)