Spark---RDD序列化
发布时间:2024年01月10日
1 什么是序列化
序列化是指 将对象的状态信息转换为可以存储或传输的形式的过程。 在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
2.RDD中的闭包检查
从计算的角度, 算子以外的代码都是在 Driver 端执行, 算子里面的代码都是在 Executor端执行。
那么在 scala 的函数式编程中,就会导致算子内经常会用到算子外的数据,这样就形成了闭包的效果,如果使用的算子外的数据无法序列化,就意味着无法传值给 Executor端执行,就会发生错误,所以需要在执行任务计算前,检测闭包内的对象是否可以进行序列化,这个操作我们称之为闭包检测。Scala2.12 版本后闭包编译方式发生了改变。
package bigdata.wordcount.xuliehua
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object SerializableDemo01 {
def main(args: Array[String]): Unit = {
//1.创建 SparkConf 并设置 App 名称
val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
//3.创建一个 RDD
val rdd: RDD[String] = sc.makeRDD(Array("hello world", "hello spark", "Scala", "Java"))
//3.1 创建一个 Search 对象
val search = new Search("h")
//筛选出单词首字母为h的单词
search.getMatch1(rdd).collect().foreach(println)
println("=>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
search.getMatch2(rdd).collect().foreach(println)
//4.关闭连接
sc.stop()
}
}
//在类构造器中以val/var修饰的变量为类的实例变量,在类中调用的时候实际是 实例.变量
//此时rdd内要用到次变量的化,需要进行序列化操作
class Search(var query:String) extends Serializable
{
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1(rdd: RDD[String]): RDD[String] = {
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
rdd.filter(x => x.contains(query))
}
}

如果Search类不实现Serializable特质的话,会通不过闭包检查,报出错误如下:
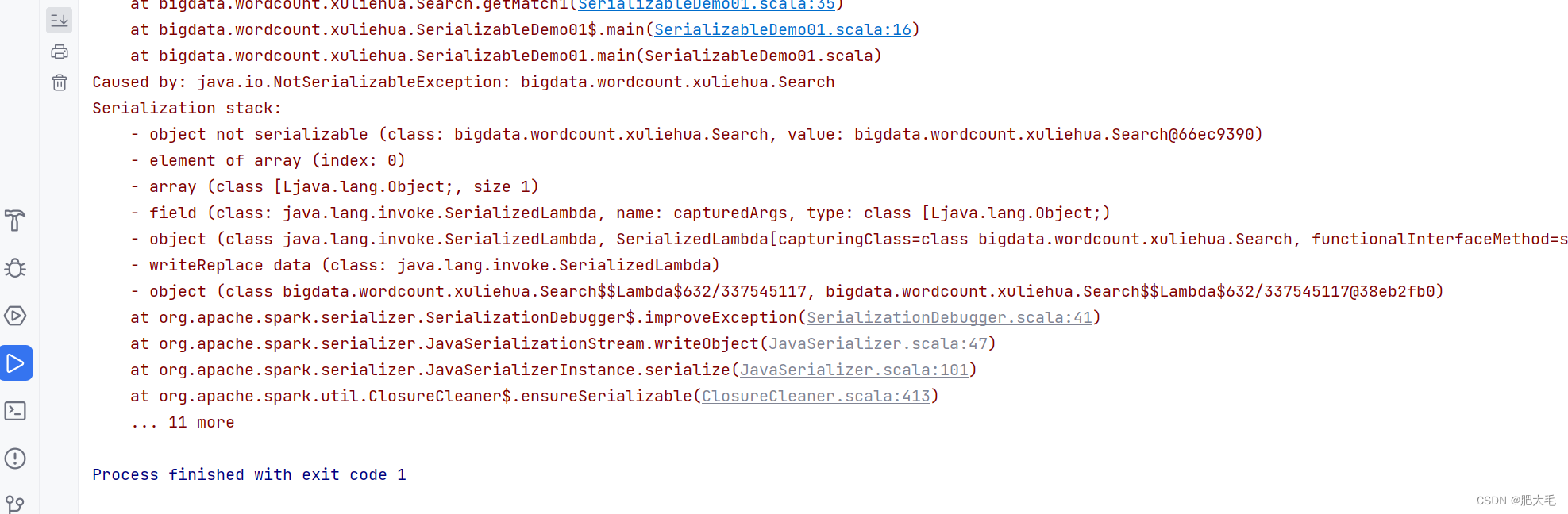
可以直接定义样例类,因为样例类自动继承了序列化特质,这样也可以通过rdd的闭包检查
case class Search(var query:String)
{
def isMatch(s: String): Boolean = {
s.contains(query)
}
// 函数序列化案例
def getMatch1(rdd: RDD[String]): RDD[String] = {
//rdd.filter(this.isMatch)
rdd.filter(isMatch)
}
// 属性序列化案例
def getMatch2(rdd: RDD[String]): RDD[String] = {
//rdd.filter(x => x.contains(this.query))
rdd.filter(x => x.contains(query))
//val q = query
//rdd.filter(x => x.contains(q))
}
}
3.Kryo 序列化框架
Java 的序列化能够序列化任何的类。但是比较重(字节多),序列化后,对象的提交也比较大。Spark 出于性能的考虑,Spark2.0 开始支持另外一种 Kryo 序列化机制。Kryo 速度是 Serializable 的 10 倍。当 RDD 在 Shuffle 数据的时候,简单数据类型、数组和字符串类型已经在 Spark 内部使用 Kryo 来序列化。
在使用Kryo序列化框架的时候,也需要继承序列化特质。
文章来源:https://blog.csdn.net/weixin_47109902/article/details/135503364
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 妙手ERP功能优化:Shopee新增关注礼、Ozon采集箱支持修改货源价格、全平台新增物流追踪功能等
- 电脑文件msvcp140.dll丢失该怎么解决?靠谱的msvcp140.dll修复方法
- 微电网优化MATLAB:蚁群算法(Ant Colony Optimization,ACO)求解微电网优化(提供MATLAB代码)
- 如何在 Ubuntu 20.04 上安装 Apache Kafka
- vue本地缓存搜索记录(最多4条)
- Spring学习 Spring IOC
- 优优聚美团外卖代运营,提升销量的秘密武器
- 提高编程效率涉及web开发,JavaScript开发,python开发的30个VScode插件
- 数组归约运算
- 游戏后端如何实现服务器之间的负载均衡?