Human Perception of Visual Information (4)
Chap4?Computational Emotion Analysis From Images: Recent Advances and Future Directions
1 Introduction
随着twitter和新浪微博等社交网络的快速发展和普及,人们倾向于在网上用文字、图片和视频来表达和分享自己的观点和情感。理解不断增长的数据存储库中包含的信息对行为科学至关重要(Pang & L e e 2008),其目的是预测人类决策并实现广泛应用,如心理健康评估(Guntuku等人2019)、商业推荐(Pan等人2014)、意见挖掘(Tumasjan等人2010)和娱乐协助(Zhao等人2020)。
在情感(情感)层面上分析媒体数据属于情感计算,它被定义为“与情感相关、产生于情感或影响情感的计算”(Picard 2000)。自从明斯基提出智力和情绪之间的关系(明斯基1986)以来,情绪的重要性已经被强调了几十年。
一个著名的说法是:“问题不在于智能机器是否能有任何情绪,而在于机器是否能在没有情绪的情况下变得智能。”
根据媒体数据的类型,情感计算的研究可以分为不同的类别,如文本(Giachanou & Crestani 2016;Zhang et al . 2018)、图像(Zhao et al . 2018)、语音(Schuller 2018)、音乐(yang & Chen 2012)、面部表情(Li & Deng 2020)、视频(Wang & Ji 2015;Zhao et al 2020)、生理信号(Alarcao & Fonseca 2019)和多模态数据(Soleymani et al 2017;Poria等2017;Zhao et al . 2019)。
“一图胜千言”这句谚语表明,图像可以传达丰富的语义。因此,图像被用作表达情感的重要渠道。图像情感分析(IEA)近年来受到广泛关注。相对于分析图像与客观内容相关的认知方面(如对象分类和语义分割)(Hanjalic 2006), IEA侧重于理解图像可以在观众中引起什么样的情绪。情感差距和感知主观性的挑战(Zhao et al . 2018)使IEA成为一项艰巨的任务。
在本章中,我们重点介绍了IEA的最新进展,特别是我们最近从计算角度所做的努力,并提出了未来的研究方向。首先,我们在第二节中简要介绍了一些流行的心理学情感表征模型,定义了相应的关键计算问题,并在第三节中提供了一些具有代表性的监督框架。
其次,我们在第四节介绍了国际能源署面临的主要挑战。第三,我们针对不同的计算分量提出了一些有代表性的方法,例如第5节的情感特征提取和第6节的监督分类器学习以及领域自适应。然后,我们在第7节中介绍了一些用于IEA评估的典型数据集,并在第8节中研究了不同特征和分类器在这些数据集上的性能,因为各种特征可以传达情绪,如图1所示。最后,我们在第9节中讨论了哪些问题仍然是开放的,并对未来的研究提出了一些建议。
2 Emotion Representation Models from Psychology
心理学家提出了不同的理论来解释人类情感背后的内容、方式和原因(Plutchik & Kellerman 2013)。例如,詹姆斯·兰格理论认为,情绪是对事件的生理反应的结果;认知评价理论认为,事件的顺序首先涉及刺激,其次是思想,然后导致同时的生理反应和情感。其他一些情绪理论包括进化论、Cannon-Bard理论、Schachter-Singer理论和面部反馈理论(Plutchik & Kellerman 2013)。
除了情感,其他几个概念(例如,情感,情绪,感觉和心情)也广泛应用于心理学。这些概念的差异或相关性可以在Munezero等人(2014)中找到。在本章中,我们将重点放在计算的角度,并没有明确区分它们,除了积极/消极/中性类别的情绪和更细粒度定义的情绪。
另一个相关的概念是关于预期的、诱导的或感知的情绪。预期情感是图像创作者想要让人们感受到的情感,感知情感是人们感知到的被表达的情感,而诱导/感受情感是观众实际感受到的情感。感兴趣的读者可以参考Juslin和Laukka(2004)了解更多细节。除非特别说明,由于数据集的构建过程,本章关注的情感是关于诱导情感的。
为了定量测量情绪,心理学家主要采用两种情绪表征模型,即分类情绪状态(CES)和维度情绪空间(DES) (Zhao et al . 2018)。对于CES,使用一组预先选择的类别来定义情绪。一些流行的CES模型包括二元情绪(积极和消极,有时包括中性),Ekman的六种基本情绪(快乐,惊讶和消极的愤怒,厌恶,恐惧和悲伤)(Ekman 1992),以及Mikels的八种情绪(娱乐,愤怒,敬畏,满足,厌恶,兴奋,恐惧和悲伤)(Mikels et al 2005)。越来越多的人开始考虑更多样化、更细粒度的情感类别。在Plutchik的情绪模型(Plutchik 1980)中,每个基本的情绪类别(愤怒、期待、厌恶、恐惧、喜悦、悲伤、惊讶和信任)被组织成三种强度。
例如,惊奇从低到高的三个强度是分心-→惊奇-→惊奇。Parrott用三个层次来表示情绪,即初级(积极和消极),次级(愤怒、恐惧、喜悦、爱、悲伤和惊讶)和第三级(25个细粒度的类别)(Parrott 2001)。对于DES,采用二维、三维或高维笛卡尔空间代表情绪,如价-唤醒-支配(vad) (Schlosberg 1954)和活动-温度-重量(Lee & Park 2011)。V AD是应用最广泛的DES模型,其中“V”代表从积极到消极的愉悦程度,“A”代表从兴奋到平静的情绪强度,“D”代表从受控到受控的控制程度。
直观上,CES模型易于用户理解,但有限的情感类别并不能很好地反映情感的复杂性和微妙性。此外,心理学家还没有就应该包括多少类别达成共识。理论上,所有情绪都可以用连续笛卡尔空间中的不同坐标点来度量。然而,这种绝对连续值对于非专家来说很难理解。具体来说,CES可以转换为DES,但并非所有笛卡尔点都可以对应于详细的类别(alarc?& Fonseca 2018)。例如,恐惧通常与负效价、高唤醒和低支配有关。在本章中,使用的CES模型主要包括二元情绪和Mikels’s eight emotions,并采用V AD作为DES模型。

3 Key Computational Problems and Supervised Frameworks
基于不同的情感表征模型,我们可以执行不同的IEA任务:基于CES的分类/检索和基于DES的回归/检索。目前的方法主要是利用已有的标记数据集进行监督。在本节中,我们将定义关键的计算问题并提供代表性的监督框架。
3.1 Emotion Classification and Regression
假设数据集中的所有图像被分成K个情感类别,那么情感预测可以被认为是一个多类分类问题。在给定训练样本上训练的模型的基础上,将最有可能在人类身上唤起的情感类别分配给测试图像。假设我们有N个训练图像{(xi, yi)N i=1},其中yi∈{1,2,···,K}。L et gμ(x)表示图像x的特征提取器,然后我们的目标是学习一些模型hθ (gμ(x)): gμ(x)→y,将图像特征gμ(x)映射到情感标签y,其中μ和θ是参数。通常将学习过程转化为参数优化问题,可定义为


?fω(的地方。, .)是一个带参数ω的函数,用于计算预测标记和基本真值之间的损失函数J (ω, θ, μ), arg min是最小值的参数。一旦我们计算出μ和θ,给定一个测试图像xte,我们就可以得到预测标签hθ (gμ(xte))。
情绪回归假设情绪由连续的维度值表示,而不是离散的情绪标签,即y是连续的。除此之外,情绪回归的学习过程类似于情绪分类。
常用的情感图像分类与回归监督框架如图2所示。首先,对图像进行预处理,使其“归一化”。然后,对每张图像提取不同的特征,这是图像情感分析的核心,我们将对此进行详细的描述。数据集分为训练集和测试集。使用训练集和基于特定学习模型的情感标签来训练分类器或回归器。然后,测试集中的图像由训练好的分类器自动分类或由训练好的回归器进行回归。将指定的情感标签与基础事实进行比较,以评估分类或回归性能。
3.2 Emotion Retrieval
情感图像检索,最初被称为情感语义图像检索(Wang & He 2008),涉及搜索与查询图像表达相似情感的图像。情感图像检索可以形式化为重新排序问题,以确保排名靠前的图像在情感上与查询图像相似。
假设给定查询图像xq的特征和情感标签分别为gμ(xq)和yq,数据集中有n张情感相似的图像,其中第i张图像的特征和标签分别为xxi和yq,其中ys i == yq, i = 1,2,···,n,和Nd情感不同的图像,其中第j张图像的特征和标签为xd j和yd j,其中yd j ?= yq, j = 1,2,···,Nd。
然后,我们的目标是最小化查询图像与n个正图像之间的距离,并最大化查询图像与第Nd张负图像之间的距离:

D(的地方。, .)是计算两个特征向量之间的距离的距离函数,例如Minkowski-form距离和Mahalanobis距离,hθ(.)是一个带参数θ的函数,用于计算查询图像和数据集中图像的代价,form ω(.)。, .)是一个带参数ω的函数,用于计算正代价J (θ, μ)和负代价Jd(θ, μ)之间的总代价J (ω, θ, μ)。一旦我们算出了μ和θ,我们就可以通过对代价排序得到检索结果。
常用的情感图像检索监督框架如图3所示。预处理和特征提取部分类似于情感分类和回归的相关部分。计算查询图像的特征与数据集中每个图像的特征之间的距离或相似度。通过一定的检索模型,对距离或相似度进行排序,得到检索结果,并与地面真值进行比较评价。

?4 Major Challenges
Affective Gap
情感差距是IEA面临的一个主要挑战,它被定义为提取的低水平特征与诱导情绪之间的不一致(Hanjalic 2006;Zhao et al . 2018)。与计算机视觉中的语义差距相比,计算情感分析,即低层次视觉特征的有限描述能力与用户语义的丰富程度之间的差异(Smeulders et al . 2020;刘等人2007),情感差距更具挑战性。弥补语义上的差距并不能保证弥补情感上的差距。例如,包含一只吠叫的狗和一只可爱的狗的图像都是关于狗的,但显然会引起不同的情绪。为了弥补情感上的差距,主要的努力集中在设计和提取有区别的情感特征上,从早期的手工特征到最近的深度特征。基于这些特征,通过传统的基于单标签学习的方法为图像分配一个主导情绪类别(DEC)。
Perception Subjectivity
情绪是一个高度主观和复杂的变量。不同的观众对同一幅图像可能会产生完全不同的情感,这受到文化、教育、个性、环境等诸多因素的影响(Zhao et al . 2018)。例如,对于一场突如其来的大雪,有些人可能会因为看到这样罕见的自然景观而感到兴奋,有些人可能会因为计划的活动不得不取消而感到悲伤,有些人可能会因为可以堆雪人而感到娱乐,等等。对于主观性的挑战,一个直接和直观的解决方案是通过个性化学习模型预测每个观众的情绪(Zhao et al .)2018)。当涉及到大量观众时,我们可以通过多标签学习方法为图像分配多个情感标签。由于不同标签的重要性或程度实际上是不相等的,因此预测情绪的概率分布,要么是离散的(Y ang et al 2017;Zhao et al . 2020)或连续(Zhao et al . 2017)会更有意义。
Label Noise and Absence
最近基于深度学习的IEA方法在大规模标记训练数据的帮助下取得了最先进的性能。
然而,在实际应用中,要获得足够的带有情感标签的数据来训练深度模型是昂贵且耗时的,甚至是不可能的。
如果我们能够处理只有很少甚至没有情感标签的情况,那将是更实际的。我们可以进行无监督/弱监督学习(Wei et al . 2020)和少/零学习(Zhan et al . 2019)。人们可能会考虑利用大量的弱标记网络图像(Wei等人)
2020)。由于相关标签可能包含与情感甚至视觉语义无关的噪声,因此有必要过滤这种自动标签。另一种可能的解决方案是将一个标记源域上学习良好的模型转移到另一个未标记或稀疏标记的目标域。由于域移位的影响,直接迁移往往会导致明显的性能衰减(Zhao等)
2021),即图像和情感标签的联合分布在不同的域。为了克服领域转移的挑战,我们可以采用领域自适应和领域泛化技术(Zhao et al . 2021)。
5 Emotion Features
在本节中,我们总结了为IEA广泛提取的特征,包括手工特征和深度特征。本文首先进行了简要的概述,然后介绍了一些具有代表性的研究成果,特别是我们最近的工作。
5.1 Hand-Crafted Features
Overview
IEA的早期工作主要集中在不同层次的手工制作功能。最早的IEA方法采用的是低层次特征,存在情感缺口大、可解释性低的问题。计算机视觉中的一些通用特征,如Gabor、HOG和GIST,直接用于IEA任务(Y anulevskaya et al . 2008)。一些源自艺术元素的特定特征,包括颜色和纹理,被执行(Machajdik & Hanbury 2010)。
低级色彩特征包括平均饱和度和亮度,基于矢量的平均色调,基于亮度和饱和度的情感坐标(愉悦,兴奋和支配),色彩和颜色名称。低级纹理特征包括Tamura纹理、小波纹理和基于灰度共生矩阵(GLCM)的纹理(Machajdik & Hanbury 2010)。Lu等人设计了线段、角度、连续线和曲线等低级形状特征(2012)。与低级特征相比,中级特征更具可解释性、语义性和情感相关性。人们用来描述场景的不同类型的属性,如材料、表面属性、功能或可视性、空间包络属性和物体存在,都被建模(Y yuan et al . 2013)。从对称、强调、和谐和多样性等艺术原则中获得灵感的特征是特别设计的(Zhao et al . 2014)。高级特征描述了图像中的详细内容,通过这些内容,观众可以很容易地理解语义和唤起的情感。一些具有代表性的高级特征包括SentiBank Borth等人(2013)检测到的形容词名词对和识别的面部表情(Y ang等人2010)。
Mid-level Principles-of-art Based Emotion Features
艺术原则被定义为在艺术作品中安排和编排艺术元素的规则、工具或指导方针。他们考虑各种艺术方面,包括平衡、强调、和谐、变化、渐变、运动、节奏和比例(Zhao et al . 2014)。艺术要素与艺术原则的对比如图4所示。Zhao et al .(2014)在相关艺术理论和多媒体研究的基础上,系统地制定并实施了艺术的六大原则。总的来说,每个图像可以获得一个165维的特征。例如,强调,也被称为对比,用来强调某些元素的差异,这可以通过使用元素的突然和突然的变化来实现。实现了Itten颜色对比,其定义为使用色调的对比特性来协调颜色(赵等人,2014),包括饱和度对比、明暗对比、延伸对比、补色对比、色调对比、暖冷对比和同时对比。研究结果表明,与艺术元素相比,艺术特征的原则与情感的相关性更大(赵等人,2014)。例如,具有高度平衡和和谐价值的图像往往会表达积极的情绪

High-Level Adjective Noun Pairs
形容词名词对(ANPs)由大型检测器库SentiBank (Borth et al . 2013)检测,该库使用GIST、3×256维颜色直方图、53维LBP描述符、使用带有2层空间金字塔和最大池化的1000字字典的Bagof-Words量化描述符以及从Flickr下载的约500k张图像的2000维属性进行训练。采用线性支持向量机(linear support vector machine, SVM) (Fan et al . 2008)作为分类器,采用早期融合。相对于名词和形容词,ANP的优势在于它将中性名词转化为带有强烈情感的ANP,并且使概念更容易被察觉。最后,得到了一个表示anp概率的1200维双向量。
5.2 Deep Features
Overview
随着深度学习,特别是卷积神经网络(cnn)的发展,基于学习的深度特征得到了广泛的应用,其性能优于手工制作的深度特征。全局特征直接从整幅图像中提取。一种直接和直观的方法是使用预训练或微调的CNN模型,将最后几个全连接(FC)层的输出作为深度特征(Xu et al . 2014;Chen et al . 2015;你等人2016)。最后几个FC层对应于高级语义特征,这可能不足以表示情感,特别是对于抽象图像。
因此,一些方法试图提取多层次的深度特征(Rao et al . 2020;Zhu et al . 2017;Y yang et al . 2018)。例如,使用不同级别训练Alexnet、美学CNN和纹理CNN三个并行网络图像补丁作为输入。提取了图像语义、图像美学和底层视觉特征三个层次的深度表征。cnn中来自不同层的特征被提取为多层次表示,并将其馈送到双向门控循环单元模型中,以利用不同层特征之间的依赖性(Zhu et al . 2017)。
上述方法对图像的不同区域一视同仁。基于某些区域可以确定图像的情感,而其他区域没有太大帮助,甚至可能相反的事实,一些最近的方法专注于提取对IEA更具歧视性的局部特征(Y ou等人2017;她等人2020;Zhao et al . 2019;等。2020)。
Weakly Supervised Coupled Networks (WSCNet)
WSCNet包含两个分支,用于联合情绪检测和分类(She et al . 2020)。一个是检测分支,它被设计用来产生唤起情感的区域建议。
通过跨空间池化策略生成软情感图,对每个类别的特征图中包含的所有信息进行汇总。感兴趣的分类信息区域在情感地图中突出显示。
这种设置的优点是网络可以用图像级情感标签进行训练,而不需要耗时的区域级注释。另一个是针对情感分类任务设计的分类分支,它同时考虑了全局表征和局部表征。该方法利用全卷积网络(FCN)提取全局特征,通过将检测分支中生成的情感图与全局特征耦合得到局部特征。
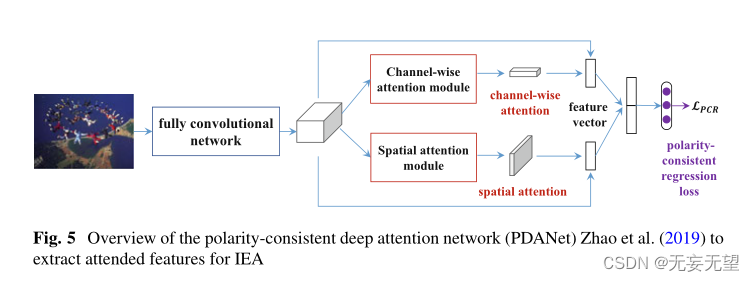
Polarity-Consistent Deep Attention Network (PDANet
将来自FCN的PDANet的特征映射馈送到两个分支(Zhao et al . 2019),如图5所示。每个分支是一个多层神经网络。一种是通过两个1 × 1卷积层和一个双曲正切函数来估计空间注意力,以强调情感语义相关区域。另一种方法是通过一个1 × 1卷积层和一个s型函数来估计通道的注意力,以考虑不同通道之间的相互依赖性。分别捕获全局和局部信息的参与语义向量被连接起来作为IEA任务的最终特征表示。
Attention-Aware Polarity-Sensitive Embedding (APSE)?
APSE利用分层注意机制来学习极性和特定情绪的出席表征(Yao et al . 2020)。基于具体的情感类别依赖于高层次的语义信息和极性与低层次特征(如颜色和纹理)相关的事实,极性特定注意在较低层次建模,情感特定注意在较高层次建模。通过跨层次双线性池将这两类被关注的特征整合起来,促进不同层次信息之间的交互。经过降维和2-归一化,我们可以得到最终的特征表示。
6 Learning Methods for IEA
在本节中,我们首先总结了广泛用于情感分类、回归和检索的监督学习方法。然后介绍了一些领域自适应方法。
6.1 Emotion Classification
Shallow Pipeline
根据建模过程,监督学习可以分为生成式学习和判别式学习。判别学习直接为给定特征gμ(x)的标签y的条件分布建模,或者直接学习从特征gμ(x)到标签y的映射。例如,逻辑回归,一种二分类方法,对条件分布p(y|gμ(x)建模;θ):
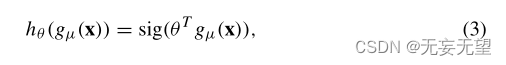
其中sig是sigmoid函数sig(z) = 1/ 1 + e - z, θ是参数向量。将逻辑回归推广到多类分类是softmax回归。感知器学习算法根据阈值函数“强制”逻辑回归的输出值恰好为0或1:

支持向量机(SVM)试图找到一个决策边界,使几何边缘最大化,并且可以用各种非线性核进行扩展。
生成式学习算法尝试对类先验p(y)和似然p(gμ(x)|y)进行建模,然后根据贝叶斯规则推导出p(y|gμ(x))上的后验分布:
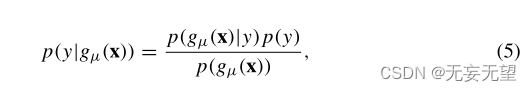
其中p(gμ(x))可以看作是一个归一化因子。高斯判别分析假设p(gμ(x)|y)按多元高斯分布分布,处理连续实值特征。朴素贝叶斯处理gμ(x)的离散值,它基于给定y的离散值是条件独立的假设。当处理多类分类时,它通常被表述为二进制分类的一些扩展。突出的表述包括“一人对众人”和“一人对一人”的分类?
Deep Architecture
最近基于深度学习的情绪分类方法通常采用几个全连接(FC)层来最大限度地减少以下交叉熵损失(She et al 2020):

其中K为情感类的数量,1[K =yi]为二值指标,pi, K为图像i属于K类的预测概率。直接优化交叉熵损失可能会导致一些图像被错误地划分为极性相反的类别。例如,对于带有“娱乐”情绪的图像,一个模型可能会错误地将情绪分类为“悲伤”,这具有相反的极性(消极与积极)。但如果将这种情绪归类为具有相同极性(积极)的“兴奋”,则更容易接受。
基于这一动机,提出了一种新的极性一致交叉熵(PCCE)损失,通过增加与基本事实极性相反的预测的惩罚来考虑极性情感层次(Zhao et al . 2020)。PCCE损耗定义为:

其中λ是罚系数。与指标函数类似,G(.)表示是否加罚,定义为:

其中极性(.)是将情感类别映射到其极性(积极或消极)的函数。?
6.2 Emotion Regression
在早期浅埋管道中,常用的回归方法包括线性回归、支持向量回归(SVR)和流形核回归等来预测管道的平均维数。例如,(Lu et al . 2012)中使用SVR来预测V - A空间中的情绪得分。
与情绪分类类似,基于深度学习的情绪回归方法也采用了几个全连接(FC)层来最小化以下均方误差(MSE):

式中,NE为所采用的情绪模型的维数(NE = 3 f r V AD), yj i为图像xi的第j维情绪标签。与PCCE损失类似,极性一致回归(PCR)损失是基于V AD维度可以被分类为不同极性的假设提出的(Zhao et al . 2019)。PCR损失定义为:?
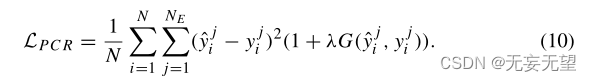
6.3 Emotion Retrieval?
我们介绍了我们在多图学习(MGL) (Zhao et al. 2014)和注意意识极性敏感嵌入(APSE) (Y ao et al. 2020)方面的工作,作为情感检索的浅层和深层方法。作为一种(半)监督学习,MGL被广泛应用于各个领域的重新排序。对于每个特征,我们可以构建一个单独的图,其中顶点表示图像样本,边缘反映样本对之间的相似性。通过在正则化框架中将多个图组合在一起,我们可以学习每个图的优化权值,从而有效地探索不同特征的互补性。
除了极性和特定情绪的出席表征外,APSE还包括极性敏感情绪对(EP)损失,以进一步利用极性情绪层次(Yao et al . 2020)。假设由K个不同类别构造的K对卷积特征表示为?(g1, g+ 1),···,(gK, g+ K)?, 98赵诗等
其中,gk和g+ k分别表示锚点xk和正例x+ k的特征表示,均来自KTH类别。EP损耗是极性间损耗和极性内损耗的组合。具体地说,极性间损耗表示为:

其中Pk和Qk分别代表与第k类锚点相同或相反极性的情感类别集。NPk和NQk为对应类别的编号。可以区分同一极性内相似类别的极性内损失定义为:?

6.4 Emotion Distribution Learning?
情绪分布学习本质上是一个回归问题。我们可以直接使用回归方法来预测每个情绪类别的概率,但忽略了不同情绪类别之间的关系。使用共享稀疏学习(SSL)作为分布同时学习不同情绪类别的概率(Zhao et al . 2020)。SSL是基于两个假设进行的:(1)在视觉特征空间中彼此接近的图像在分类情感空间中具有相似的情感分布;(2)测试图像的分布可以近似地建模为训练图像分布的线性组合。具体来说,在特征空间中学习组合系数并将其转移到情感分布空间中。该方法还扩展到更一般的设置,其中有多个功能可用。每个特征的最优权重被自动学习,以反映不同特征的重要性。
使用深度架构的一种直观方法是用一些基于分布的损失(如KL散度)代替分类的交叉熵损失(Yang et al 2017):
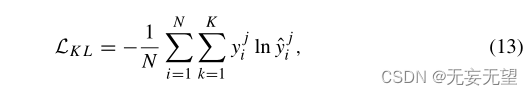
其中yji和yji为图像xi的第JTH情感类别的基本真值和预测概率。?联合分类分布学习(JCDL)同时对情绪分类和分布学习进行建模(Yang et al . 2017)
6.5 Domain Adaptation?
领域自适应旨在从标记的源领域学习可转移模型,该模型可以在另一个稀疏标记或未标记的目标领域上表现良好(Zhao et al . 2021)。最近的方法主要集中在无监督设置上,采用两流深度架构:一个流用于在标记的源域上训练任务模型,另一个流用于对齐源和目标域,如图6所示。现有领域适应方法的主要区别在于对齐策略,包括基于差异的方法、基于对抗性判别的方法、基于对抗性生成的方法和基于自我监督的方法(Zhao et al . 2021)。
cycleemotiongan++ (cegan++) (Zhao et al 2021)是一种最新的IEA领域适应方法。cegan++在像素级和特性级对源域和目标域进行对齐。首先,通过使用多尺度结构化循环一致性损失改进CycleGAN (Zhu et al . 2017),生成一个自适应域来执行像素级对齐。在图像翻译过程中,采用动态情感语义一致性(DESC)来保持源图像的情感标签。其次,在学习任务分类器时进行特征级对齐。最终的目标损失是任务损失、混合CycleGAN损失和DESC损失的组合。

7 Released Datasets?
在本节中,我们将介绍一些广泛用于IEA绩效评估的数据集。为了清晰起见,我们根据不同的情绪标签和IEA任务(即平均维度值、主导情绪类别、概率分布和个性化情绪标签)组织这些数据集。
A verage Dimensional Values?
国际情感图片系统(International Affective Picture System, IAPS) (Lang et al . 1997)是一套心理学上的情感唤起图像集,包含1182张纪录片风格的自然色彩图像,描绘了复杂的场景,如肖像、婴儿、动物、风景等。每张图片都与大约100名大学生(主要是美国人)在9分评定量表中得出的V / AD评分的经验推导的平均值和标准偏差(STD)相关联。Nencki情感图片系统(NAPS) (Marchewka et al . 2014)由1356张真实、高质量的照片组成,分为五类,即人、脸、动物、物体和风景。204名参与者(主要是欧洲人)在VA和接近回避维度上用9点双极性语义滑动量表给这些图像贴上标签。情境情绪数据库(EMOTIC)是一种基于上下文的情感数据库。2017)由18316张关于非受控环境中人的图像组成。有两种情绪标签:26种情绪类别和连续的10尺度V AD维度。
Dominant Emotion Category
IAPSa (Mikels et al . 2005)是IAPS的子集,包含246张图像。摘要数据集(Abstract)包含228幅同行评价的抽象绘画,没有上下文内容(Machajdik & Hanbury 2010)。ArtPhoto是一个艺术数据集,包含从照片共享网站获得的806张艺术照片(Machajdik & Hanbury 2010)。IAPSa、Abstract和ArtPhoto数据集被分为八个独立的类别(Mikels et al 2005):娱乐、愤怒、敬畏、满足、厌恶、兴奋、恐惧和悲伤。情绪类别与维度V A值的关系如图7a所示。日内瓦情感图片数据库(gape)由520张底片(133张蜘蛛、158张蛇、105张人类关切和124张虐待动物),121幅正面(人类和动物婴儿以及自然景观)图像和89幅中性(无生命物体)图像(DanGlauser&Scherer,2011年)组成。此外,这些图像还被评定为效价和唤醒值,范围从0到100分。
效价和唤醒等级(从[0,100]变化到[1,9])如图7b所示。Twitter I (Y ou et al 2015)由1269张由5名Amazon Mechanical Turk (AMT)工人注释的图像组成。

有三个子集,即“五人同意”(Twitter I-5),“至少四人同意”(Twitter I-4)和“至少三人同意”(Twitter I-3)。“5同意”表示所有5名AMT工作人员都为图像贴上了相同的情绪标签。共有882张“五同意”的图片,所有的图片都至少获得三张相同的选票。Twitter II包括470条正面推文和133条负面推文(Borth et al . 2013),从PeopleBrowsr抓取21个标签。EMOd (Fan et al . 2018)由1019张带有眼动追踪数据的情绪图像和不同类型的标签(如物体轮廓和情绪)组成。FI (Y ou et al . 2016)是一个大规模的图像情感数据集,其中有23,308张使用Mikel的情感类别标记的图像。图像以八种情绪为关键词,在Flickr和Instagram中进行搜索,去除噪声数据,得到图像。
Probability Distribution
构建了Flickr_LDL和Twitter_LDL数据集来研究情感歧义(Y ang et al . 2017)。这两个数据集中有10,700张图片和10,045张图片,分别由11名和8名参与者根据Mikel的情绪类别进行标记。基于详细的标注,我们可以很容易地得到不同情绪类别的离散概率分布。
Personalized Emotion Labels
图像-情感-社会网络(IESN) (Zhao et al .2018)是为了研究个性化情绪而构建的。11,347名用户从Flickr上传了超过100万张图片。对于每张图像,上传者的期望情绪和每个观看者的实际情绪都以二元情绪、Mikel的情绪类别和连续的V AD值的形式提供。
8 Experimental Results and Analysis
为了让读者清楚地了解当前计算IEA方法的能力,我们对不同的IEA任务进行了一系列实验。在本节中,我们首先介绍了评估标准,然后报告了不同代表性方法的性能比较。
8.1 Evaluation Criteria
对于情绪分类,最广泛使用的指标是分类准确性,它衡量正确分类图像在所有测试图像中的百分比(She et al 2020)。对于情绪回归,我们可以使用均值平方误差、平均绝对误差和决定系数来评估结果。对于情绪分布学习,我们既可以使用平方差和从回归方面衡量表现(Zhao et al . 2020),也可以使用两个分布之间的距离或相似度量(例如,KL散度、Bhattacharyya系数、Chebyshev距离、Clark距离、堪培拉度量、余弦系数和交叉相似性)来衡量预测分布与真实情况是否相似(Yang et al . 2017;Zhao et al . 2020)。对于图像检索,有几个评价指标:最近邻率、第一层、第二层、精确召回率曲线、F1分数、贴现累积增益(DCG)和平均归一化修正检索秩(ANMRR) (Zhao et al . 2014;yao et al 2020)。
我们采用准确性进行情绪分类,均方误差(MSE)进行情绪回归,ANMRR进行检索,KL散度进行分布学习。就准确性而言,越大越好;而MSE、ANMRR和KL散度值越小,结果越好。
8.2 Supervised Learning Results
对于情绪分类和回归,我们比较了以下方法:
?传统方法:基于艺术原理的情绪特征(PAEF) (Zhao等人)2014),形容词名词对(ANP)与SentiBank (Borth等人2013),预训练AlexNet (Krizhevsky等人2012),VGG-16 (Simonyan & Zisserman 2015)和ResNet-101 (He 2016)。采用径向基函数核的支持向量机(SVM)或回归(SVR)作为学习模型。
?深度方法:微调(FT) AlexNet、VGG-16和ResNet-101、MldrNet (Rao等人2020)、sentinel - a (Song等人2018)、WSCNet (She等人2020)和PDANet (Zhao等人2019)。
对于情绪检索,我们比较了以下方法的性能:SIFT (Lowe 1999)、HOG (Dalal & Triggs 2005)、SentiBank (Borth et al 2013)、多图学习(MGL) (Zhao et al 2014)、JCDL (Y ang et al 2017)和APSE (Y ao et al 2020)。对于情绪分布学习,比较的方法有:Bayes、SVM、kNN、BP、IIS、BFGS、CPNN (Geng et al . 2013)、BCPNN、ACPNN (Y ang et al . 2013)CNNR (Peng et al . 2015)、DLDL (Gao et al . 2017)和JCDL (Y ang et al . 2017)2017)。
以上几种方法在情绪分类、回归、检索和分布学习方面的对比结果如图8所示。从这些结果,我们可以得出结论:
1. 传统的计算机视觉中手工制作的低级特征,如SIFT和HOG,在IEA任务中表现不佳。例如,在图8c中,SentiBank在IAPSa数据集上的检索性能远远优于SIFT和HOG
2. 预训练的CNN特征,特别是从深度模型中提取的特征(如ResNet-101),与手工制作的特定特征(如PAEF和SentiBank)相比,达到了相当甚至更好的结果,这证明了深度特征对新应用的泛化能力。例如,在图8a中,与PAEF和SentiBank相比,预训练的ResNet-101特征在Twitter I数据集上的情绪分类性能提高了4.63%和5.92%。
3. 一般来说,微调的深度模型比预训练的模型表现得更好。这是合理的,因为预训练的模型没有考虑情绪相关特征的具体特征,而微调的深度模型可以学习适应情绪数据集。
4. 在对比图8a和b中的AlexNet和ResNet-101时,可以清楚地看到,更深的模型通常表现更好。
5. 特别设计的模型表现最好,如图8c中的APSE和图8b中的PDANet;这些方法通过对情绪的特定特征,如极性-情绪层次和注意机制的建模,可以更好地弥合情感差距。

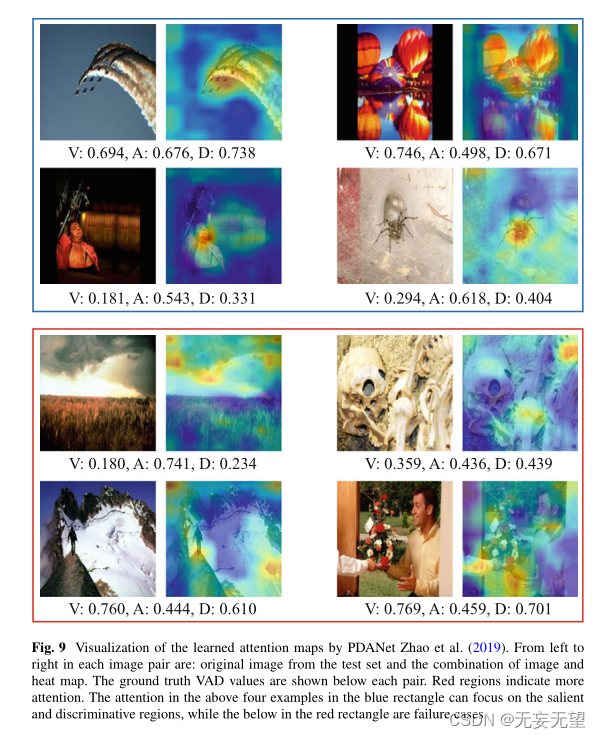
我们将PDANet (Zhao et al . 2019)的学习注意力可视化,并将其与Grad-Cam算法生成的热图(Selvaraju et al . 2017)进行对比,以了解模型的可解释性。结果如图9所示。更多关于其他可视化的结果可以在我们的论文中找到(Y ang等人2017;Zhao et al . 2019;她等人2020;yao et al 2020)。从上面四个蓝色矩形的例子中,我们可以看到PDANet可以成功地关注决定整个图像情绪的显著和判别区域。例如,在右上角,?
PDANet学习到的注意力集中在彩色气球上,这与积极情绪密切相关。我们还在红色矩形中显示了一些失败案例。可以看出,在这些情况下,背景和前景难以区分或者背景比较复杂
8.3 Domain Adaptation Results?
对于IEA的无监督域自适应,我们报告了cycleemotiongan++ (cegan++)与以下基线之间的性能比较:
?仅源:直接将源域上训练的模型转移到目标域;
?色彩风格转移方法:CycleGAN (Zhu et al . 2017);
?UDA方法:ADDA (Tzeng et al . 2017)、SimGAN (Shrivastava et al . 2017)和CyCADA (Hoffman et al . 2018);
?Oracle:在目标域上进行训练和测试,这可以看作是上界。
任务分类器使用在ImageNet上预训练的ResNet-101 (He 2016)架构。更多实现细节请参见(Zhao et al . 2021)。cegan++与上述方法的性能对比如图10所示。从结果可以看出:

1. 由于域漂移的影响,直接将源域训练的模型转移到目标域的效果并不好。例如,从ArtPhoto适配到FI,即在ArtPhoto上进行训练,直接在FI上进行测试,分类准确率仅为23.86%。该模型从一个领域到另一个领域的低可转移性激发了领域适应性研究的必要性
2. 在所有领域适应方法中,cegan++在情绪分类和分布学习方面都取得了最好的效果。cegan++在适应图像情感方面的优势体现在:像素级和特征级对齐,实现源域和目标域的对齐;动态情感语义一致性,实现图像翻译前后情感信息的动态保存。
3. 所有的域自适应方法与在目标域上训练的oracle设置之间仍然存在明显的差距。例如,在FI上的oracle准确率为66.11%,最佳自适应结果为32.01%。未来的努力仍需要进一步弥合不同领域之间的领域转移。
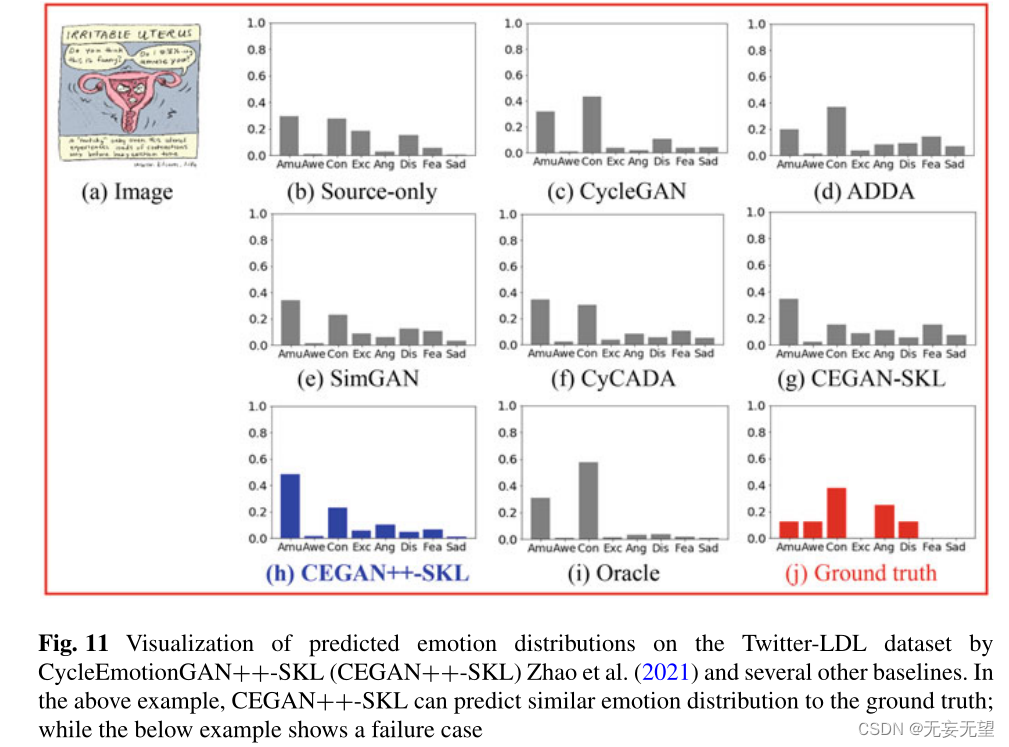
图11显示了在Twitter-LDL数据集上通过不同的领域适应方法预测的情绪分布,包括一个成功的例子和一个失败的案例。更多的可视化结果可以在Zhao等人(2021)中找到。

 ?
?
从上面的例子中,我们可以清楚地看到,CEGAN++预测的情绪分布与地面真实分布非常接近,这说明了CEGAN++对视觉情绪适应的有效性。在下面的失败案例中,我们可以看到,即使是oracle也不能很好地执行,这表明IEA的挑战,需要进一步的研究努力。
9 Conclusions and Future Research Directions?
本文从不同方面介绍了图像情感分析(IEA)的最新进展,重点介绍了我们最近的工作。首先,我们总结了相关的心理学研究,以了解情绪是如何测量的。其次,基于情感表征模型,定义了关键计算问题和广泛使用的监督框架,并介绍了IEA面临的三大挑战。第三,总结并比较了针对不同IEA任务的代表性情绪特征提取方法和学习方法。最后,我们简要地描述了现有的数据集,并提出了一些目前最先进的方法的实验。
虽然国际能源署的研究得到了很大的关注,并提出了很有前景的方法,但总体性能仍然不完善,仍然没有普遍接受的解决方案来解决这些问题。国际能源署的许多问题仍然是开放的,值得我们进一步研究。我们相信,随着心理学、脑科学、机器学习等多学科的进步,IEA将继续成为一个热门的研究课题。最后,我们提出了一些值得思考和研究的课题。
Context-Aware Image Emotion Analysis
除了提取判别性视觉特征外,结合可用的上下文信息也有助于IEA任务(Kosti等2020)。
(1) 图像上下文。不同背景下的相似图像内容可能会在图像内或跨模态引发完全不同的情绪。
例如,如果我们看到一些士兵在鲜花的簇拥下微笑,我们可能会为他们为国家做出的贡献而感动,比如抗击疫情;但如果附近有一个死去的孩子,我们可能会对他们的暴行感到愤怒。如果我们看到一个著名的足球运动员跪着哭泣,观众可能会感到悲伤;但如果这是在赢得一场比赛后,观众尤其是球队的业余爱好者我感到兴奋。
(2)观看者语境。观看者观看图像的情境和观看者的先验知识(如个性、性别和文化背景)也会对情感感知产生很大影响。例如,观众当前的情绪可能与他/她最近的过去情绪密切相关(Zhao et al . 2018)。
(3)图像观看者互动。人类的情绪感知是一个复杂的过程,既涉及刺激,也涉及生理和心理变化。将这种隐式和显式渠道结合起来有助于最终的IEA绩效。
Determining Intrinsic Emotion Features and Localizing Image Emotions to
Image Regions/确定内在情感特征并将图像情感定位到图像区域
如(Zhao et al . 2014)所示,不同类型的图像的情绪是由不同的特征决定的。如果我们能先知道图像的类型,我们就可以选择相应的特征来鉴别IEA。但是我们应该为情绪预测定义什么样的图像类型仍然不清楚。尝试大规模数据驱动的方法值得一试。尽管基于深度学习的方法在IEA中取得了有希望的结果,但这些方法为什么有效的可解释性,即它们关注的特征,尚未得到充分的研究。确定图像的内在特征,以理解是什么让图像有趣、悲伤或可怕,仍然是一个悬而未决的问题。
有时,图像的情感是由图像的整体外观决定的。偶尔,情感会被一些关键的图像区域所反映。
这将有助于我们定位这些关键区域,这些关键区域可以通过改变或替换来改变图像情绪(Peng et al . 2014)。我们可以使用传统的分割方法将图像分割成区域,并识别每个区域的情绪。或者我们可以训练分类器来检测关键区域。例如,ANP分类器通过分层训练来定位对象(Chen et al . 2014)。
最近的情绪区域定位方法是基于注意力(Zhao et al . 2019)和情绪地图(She et al . 2020)。除了情感分类分支,WSCNet还训练了另一个弱监督检测分支,通过跨空间池化策略的全卷积网络学习情感特定软地图(She et al 2020)。PDANet共同考虑空间和通道的注意力,通过它们我们可以获得注意和判别区域(Zhao et al . 2019)。将传统目标检测方法的优点与图像情感的特点相结合,可能会激发出新的解决方案。
Understanding Emotions of 3D Data
现有的关于一般图像情感和情感分析的工作大多是基于二维图像的。但随着体感设备(如Kinect)的广泛普及和公众使用,越来越多的3D数据(如2D图像和深度)被创建和共享,就像个人照片和网络视频一样。与传统的强度和彩色图像相比,3D数据包含更多的信息,并且具有几个优点,例如在低光照水平下有用,并且颜色和纹理不变(Shotton et al . 2011)。一些研究致力于识别3D面部表情。然而,关于广义三维情感分析的研究却很少。据我们所知,目前还没有发布通用3D数据的公共情感数据集。建立一个大规模的三维情感数据集是一个迫切需要和具有重要价值的问题。使用社交网络数据可能有助于减少耗时和繁琐的标签任务。随着3D内容分析的快速发展,理解3D数据的情感将成为一个热门的研究课题。
Image Emotion Analysis in the Wild
现有的IEA方法主要基于特定的设置,例如在具有有限注释者的小数据集上进行训练。
然而,在实际应用中,IEA的问题要复杂和困难得多。例如,给定的数据集可能包含不准确的注释和许多与情感无关的噪声;训练数据增量化,情感分类逐渐细化;标记数据在不同情绪类别之间不平衡;测试集与训练集风格不同;只有有限的计算资源可用。如何设计一种有效、高效的IEA模式,使其在这些实际环境下仍能发挥作用,仍是一个开放的问题。
Novel and Real-world Applications Based on IEA
由于早期的进展相对有限,例如性能较低,情感在实际应用中并没有得到广泛的应用。随着深度学习和大规模数据集的发展,IEA的绩效已经并将继续得到显著提升。因此,我们预见在不久的将来会出现一个情绪智能时代,有许多新颖的和现实世界的基于情绪智能的应用。例如,我们可以了解艺术家如何通过他们的作品表达情感,并将所学到的原理运用到绘画教育中。在时尚广告中,我们可以设计出服装和模特之间的最佳搭配,吸引用户的注意力,提高用户的体验,从而增加销量。
Security, Privacy, and Ethics of IEA
如上所述,观众的先验知识,如身份、年龄和性别,可以对IEA的表现做出贡献。然而,这些信息是保密的,不应该被分享或泄露。
因此,在实际应用中必须考虑到安全性和隐私性的保护。此外,没有关于IEA任务的相关法律,特别是针对个性化场景。人们可能不希望自己的情绪被识别和利用。从伦理学的角度考虑这种影响是很重要的,这需要心理学、认知科学、计算机科学等不同领域的共同努力。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 图神经网络与分子表征:番外——等变术语
- 英文建筑图纸翻译工程图纸翻译
- Red Hat Enterprise Linux 6.10 安装图解
- Linux调试------gdb的使用
- centos 编译安装 cmake
- MySQL之导入、导出
- 高并发场景下,缓存“穿透”了该怎么办?
- 制冷循环热力计算 二
- 在Python中使用列表推导式List Comprehension的8个层次
- Vmware中新安装的镜像 root默认密码