【Hadoop】ZooKeeper数据模型Znode
ZooKeeper 数据模型Znode
前面提过,Zookeeper相当于文件系统+通知机制。既然是文件系统,那就涉及数据模型。
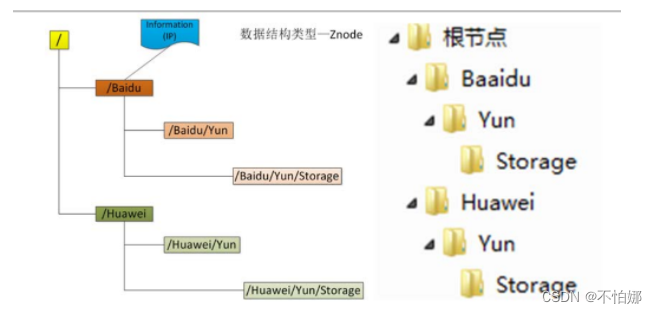
ZooKeeper 的数据模型在结构上和Unix标准文件系统非常相似,都是采用树形层次结构,ZooKeeper 树中的每个节点被称为 Znode。
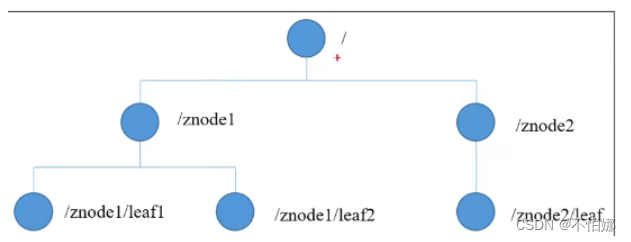
和文件系统的目录树一样,ZooKeeper 树中的每个节点可以拥有子节点。但和标准文件系统也有不同之处,体现在:
-
引用方式:Znode 通过路径引用,如同 Linux 中的文件路径,但路径必须由斜杠字符来开头
-
Znode 结构:每个 Znode 由 3 部分组成:
- stat:描述该 Znode 的版本, 权限等信息
- data:与该 Znode 关联的数据
- children:该 Znode 下的子节点
-
Znode 大小:ZooKeeper 虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反,它被用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都很小,通常以 KB 为单位。ZooKeeper 的服务器和客户端都被设计为严格检查并限制每个 Znode 的数据大小至多 1M, 但实际使用中要远小于此值
-
数据访问:ZooKeeper 中的每个节点存储的数据要被原子性的操作,也就是说读操作将获取与节点相关的所有数据,写操作将替换掉节点的所有数据。另外,每一个节点都拥有自己的 ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作
-
节点类型:ZooKeeper 中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话结束,临时节点将被自动删除,或者也可以手动删除
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显式地执行了删除操作的时候,这些节点才能被删除
-
监视器:客户端可以在节点上设置 watch, 称为监视器。当节点状态发生改变时(Znode 的增、删、改)将会触发 watch 所对应的操作。当 watch 被触发时,ZooKeeper 将会向客户端发送且仅发送一条通知,因为 watch 只能被触发一次,这样可以减少网络流量。这就对应前面说的,当有用户关注的主播上线的时候,就会给用户发送通知消息,这个动作就是由监视器来完成的
ZooKeeper 中的时间
-
Zxid:Zxid 是一个 64 位的数字,它的高 32 位是 epoch 用来标识 leader 关系是否改变,每次一个Leader 被选出来,它都会有一个新的 epoch, 低 32 位是个递增计数。
使得 ZooKeeper 节点状态改变的每一个操作都将使节点接收到一个 Zxid 格式的时间戳,并且这个时间戳全局有序。也就是说,每个对节点的改变都将产生一个唯一的 Zxid, 如果 Zxid1的值小于 Zxid2 的值,那么 Zxid1 所对应的事件发生在 Zxid2 所对应的事件之前。
实际上,ZooKeeper 的每个节点维护者三个 Zxid 值,为别为:cZxid、mZxid、pZxid。
cZxid 是节点的创建时间所对应的 Zxid 格式时间戳。
mZxid 是节点的修改时间所对应的 Zxid 格式时间戳
-
版本号:
对节点的每一个操作都将致使这个节点的版本号增加。每个节点维护着三个版本号,它们分别为:
version:节点数据版本号
cversion:子节点版本
aversion:节点所拥有的 ACL 版本号
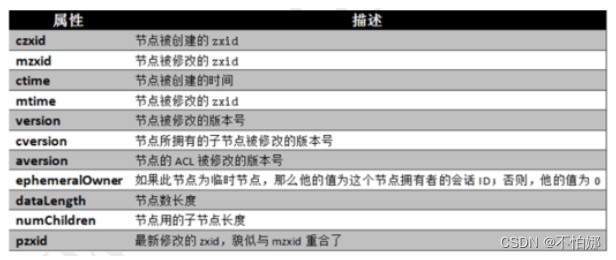
ZooKeeper 节点属性
一个 ZooKeeper 节点自身拥有表示其状态的许多重要属性,如下图所示。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- python测试工具: 实现数据源自动核对
- 普中STM32-PZ6806L开发板(HAL库函数实现-按键扫描)
- RuntimeError: Inference tensors do not track version counter.
- Promise
- 使用 exec*库函数、编程练习动态链接库的两种使用方式
- shell编程-重定向与打印命令详解(超详细)
- 【漏洞复现】Hikvision SPON IP网络对讲广播系统命令执行漏洞(CVE-2023-6895)
- 借助文档控件Aspose.Words,在 Word 文档中创建和修改 VBA 宏
- 在 The Sandbox 见证元宇宙新地标:Playboy 推出 MetaMansion 特别预览
- fastadmin自定义添加、修改弹窗大小