PEGASUS模型介绍
PEGASUS介绍
概述
模型论文为Pre-training with Extracted Gap-sentences for Abstractive Summarization,简称为PEGASUS。面向的情况主要是因为目前预训练语言任务主要为MLM和NSP任务,即为掩码预测任务和下一句预测任务,没有面向生成式文本摘要的预训练任务。因此PEGASUS提出在预训练阶段的时候,将重要的句子作为MASK1,掩盖后,通过encoder-decoder的结构运用MASK1覆盖后的句子预测MASK1的句子,在一定程度上模拟摘要生成。
PEGASUS假设前提为在预训练过程中,约接近下游任务的预训练任务可以获取更好的下游任务性能。
PEGASUS模型的预训练任务主要有两个,分别为gap句子生成和掩码预测任务。Gap句子生成主要模拟抽取式摘要文本生成。
-
GSS(Gap Sentence Generation)
-
MLM(Mask Language Model)
模型框架图示
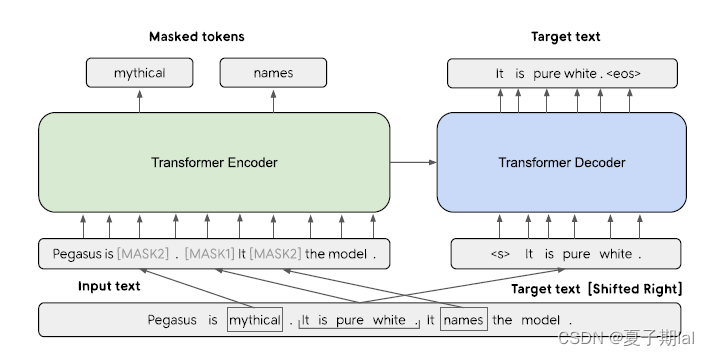
- MASK1为我们所模拟生成式摘要的句子,MASK2主要为MLM任务
Gap Sentence Generation(GSG)
前提为预训练目标与下游任务约接近,finetune效果会更好。通过运用span mask的思想,将整个句子运用MSAK1遮盖预测,除此之外,将MASK1拼接为起来,形成一个伪摘要。Gap sentence ration(GSR)用于描述MASK1在文档中的总比例。
- G S R = 输入句子中 M A S K 1 总个数 ) 输入句子中 t o k e n 总个数 GSR = \frac{输入句子中MASK1总个数)}{输入句子中token总个数} GSR=输入句子中token总个数输入句子中MASK1总个数)?
但是选择不同的句子会有不一样的结果,因此提出了下列集中选择句子的方式。定义n个句子文档集 D = x i n D = {x_i}n D=xi?n,n为句子个数, x i x_i xi?为第i个句子。D为文档。
- Random,随机选取m个句子
- Lead,选取文章中前m个句子
- Principal, 根据特定指标,选取得分高的top-m个句子
Principle 选择方式
- 独立性选择(independently,ind),根据选中句子和其他句子集合的ROUGE1-F1来计算,具体公式如下,最终选取前m个
s
i
s_i
si?句子。
- s i = r o u g e ( x i , D ? { x i } ) s_i=rouge(x_i,D\setminus\{x_i\}) si?=rouge(xi?,D?{xi?})
- 连续性选择(Sequential Sentence Selection,seq),通过贪婪最大化选择句子集合和其他句子子集的ROUGE1-F1值选取,具体算法描述如下所示。
- 
- 
R o u g e ? N = ∑ S ∈ R e f e r e n c e S u n m a r i e s C o u n t m a t c h ( g r a m n ) ∑ S ∈ R e f e r e n c e S u m a r i e s ∑ g r a m n ∈ S C o u n t ( g r a m n ) Rouge{-}N=\frac{\sum_{S\in ReferenceSunmaries}Count_{match}(gram_n)}{\sum_{S\in ReferenceSumaries}\sum_{gram_n\in S}Count(gram_n)} Rouge?N=∑S∈ReferenceSumaries?∑gramn?∈S?Count(gramn?)∑S∈ReferenceSunmaries?Countmatch?(gramn?)?
结论
最终得到一共有四种,结合之前的Random以及Lead,最终有Ind-Uniq,Ind-Orig,Seq-Uniq,Seq-Orig,Random,Lead共六种选择。
最终确定了将文档的SGR(选取30%)的句子作为Gap sentence句子,而且在选择MASK1的时候,运用Ind-Orig对方式,结果最好。
MLM掩码预测任务选择
在文中共有三种方法。
- 类似于BERT做法,输入文本的15%的tokens, 80%的被替换为[MASK2], 10%的被随机的token替换 10%未发生变化,在finetune的时候共享encoder参数
- 只用CSG,不运用常见MLM
- 在运用CSG的基础上,在没有被选中的句子中选取15%作为常见MLM任务。
结论
只用MLM的效果最差,但是在100K-200K的参数中,用MLM+GSG效果较好,但是在200K之后,运用MLM效果反而下降,因此在训练大规模参数PEGASUS-large中只运用了GSG,在PERASUS-base中只运用了GSG+MLM。
参考
此在训练大规模参数PEGASUS-large中只运用了GSG,在PERASUS-base中只运用了GSG+MLM。
参考
PEGASUS模型:一个专为摘要提取定制的模型
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- osgearth瓦片渲染
- winform实现窗体设计器,什么?我也能用visual studio做一个visual studio,彻底解决鸡生蛋、蛋生鸡问题!
- 最大流—EK算法,流网络,残留网络,定理证明,详细代码
- “轻松粘贴,高效办公:自动粘贴文本技术让您事半功倍
- flutter学习-day21-使用permission_handler进行系统权限的申请和操作
- 【Materials Studio】入门基础篇
- 上海亚商投顾:创业板指放量涨近2% 全市场超4400只个股上涨
- [自动化分布式] Zabbix自动发现与自动注册
- 电霸虾皮版:为Shopee卖家提供的数据支持服务的选品工具
- 【Python 零基础入门】 Numpy