条件随机场 (CRF) 的损失函数以及faiss 的原理介绍
1、条件随机场 (CRF) 的损失函数
条件随机场(CRF)是一种统计建模方法,常用于结构化预测问题,如序列标注、分词和命名实体识别等。在CRF模型中,损失函数用于衡量模型预测的标记序列与真实标记序列之间的差异。CRF的目标是最大化正确标记序列的对数似然概率,因此其损失函数通常是负对数似然损失函数。
CRF的损失函数
CRF的损失函数可以表示为以下形式:

其中,N 是训练样本的数量,x(i) 是第i个样本的输入序列,y(i) 是对应的真实标记序列,θ 是模型参数,p(y∣x;θ) 是在给定输入序列x和模型参数θ的条件下,标记序列y的条件概率。
CRF中的条件概率可以通过以下公式计算:
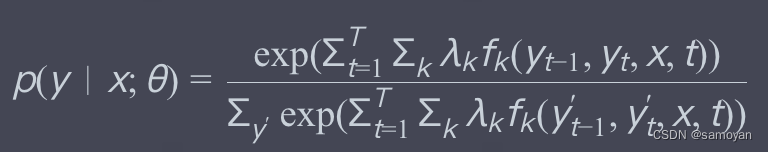
这里,T 是序列的长度,fk? 是特征函数,λk? 是对应的权重,求和是对所有可能的标记序列y′进行。分子是当前标记序列y的得分,而分母是所有可能标记序列的得分之和,也称为配分函数(partition function),用于确保概率之和为1。
在实际应用中,为了避免数值计算问题,通常会使用配分函数的对数形式,并使用动态规划算法(如前向-后向算法)来有效计算这个对数配分函数。
优化CRF损失函数
在训练CRF模型时,目标是最小化损失函数L(θ)。这通常通过梯度下降或其变体(如随机梯度下降、Adam等)来实现。在每次迭代中,计算损失函数关于模型参数θ的梯度,并更新参数以减少损失。
总的来说,CRF的损失函数是负对数似然函数,它衡量的是模型输出与真实标记序列的匹配程度。通过最小化这个损失函数,可以使模型更好地拟合训练数据,从而在实际应用中提高预测的准确性。
2、Faiss原理与核心算法
Faiss是由Facebook AI Research(FAIR)团队开发的一种高效相似性搜索和密集向量聚类库。它主要用于大规模向量检索以及向量集的聚类操作,尤其适用于高维空间中的向量。Faiss的核心在于其能够处理海量数据集,并且能够在CPU和GPU上提供高效的搜索操作。
Faiss的核心组件
-
Indexing(索引): Faiss使用索引结构来存储向量,以便进行快速检索。索引负责维护数据集的结构,并提供查询接口。
-
Search(搜索): Faiss提供了不同的搜索算法,用于在索引中找到与查询向量最相似的向量。搜索可以是精确的,也可以是基于近似算法的。
-
Quantization(量化): 为了提高搜索效率,Faiss使用量化技术来压缩向量。这可以通过减少存储需求和计算距离的时间来加速搜索。
Faiss的核心算法
-
Exact Search(精确搜索): 对于小规模数据集,Faiss可以进行精确的k-nearest neighbor (k-NN) 搜索。这种搜索保证返回最接近查询向量的k个邻居。
-
Approximate Nearest Neighbor (ANN) Search(近似最近邻搜索): 对于大规模数据集,精确搜索变得不切实际。Faiss实现了多种ANN算法,如Product Quantization (PQ), Inverted File System (IVF), 和Hierarchical Navigable Small World (HNSW) 等。
-
Product Quantization (PQ): PQ是一种将高维空间划分为若干低维子空间的技术,每个子空间被量化为有限个质心。这可以大幅减少存储需求,并加速距离计算。
-
Inverted File System (IVF): IVF是一种基于倒排索引的方法,它首先将数据集划分为几个聚类(使用k-means),然后只在与查询向量最相关的聚类中搜索。
-
Hierarchical Navigable Small World (HNSW): HNSW是一种基于图的搜索算法,它构建了一个分层的图结构,通过跳跃连接来加速搜索过程。
-
-
Clustering(聚类): Faiss还提供了k-means聚类算法,可以对大规模数据集进行有效的聚类操作。
Faiss的优化技术
-
使用BLAS/LAPACK库: Faiss利用了基础线性代数子程序库(BLAS)和线性代数程序包(LAPACK)来加速矩阵和向量运算。
-
支持GPU加速: Faiss提供了GPU版本的索引,可以利用GPU的并行计算能力来进一步提高搜索速度。
-
Batching(批处理): 通过批量处理查询,Faiss可以更高效地利用资源,减少查询时间。
总结来说,Faiss的核心在于其高效的索引结构和搜索算法,以及对大规模数据集的处理能力。通过量化技术和多种优化,Faiss能够在保持相对较高精度的同时,提供快速的搜索性能。这使得Faiss在工业界和学术界广泛应用于相似性搜索和聚类任务中。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 工智能基础知识总结--线性回归
- Feign自定义打印请求响应log
- 【蓝桥杯选拔赛真题75】Scratch行走的螃蟹 第十五届蓝桥杯scratch图形化编程 少儿编程创意编程选拔赛真题解析
- 基于生成模板的动态前缀微调事件抽取(ACL2022)
- Go源码学习:bytes包 - 1.1 - buffer.go -(4)
- leetcode中的状态机类型的题目
- Transformer简略了解
- C语言算术操作符相关题目
- 2024年阿里云服务器优惠活动汇总,最新
- GitHub Copilot 的使用方法和快捷键