PDF文件中字体乱码的一种简单的处理方法
发布时间:2024年01月16日
要解决问题先得碰到问题,碰到问题就迈出了解决问题的关键一步。
这文件用Acrobat打开,无法搜索文本,复制文本出来也都是乱码。但用sumatra PDF打开就不存在这个问题!
用Acrobat的印前检查解决。preflight即可。
这功能菜单或按钮隐藏着,不妨用搜索的方法,英文版找preflight,中文版找 印前检查。
点击之后在弹出的preflight对话框,不用点Profiles下面的analyze、analyze and fix之类的,
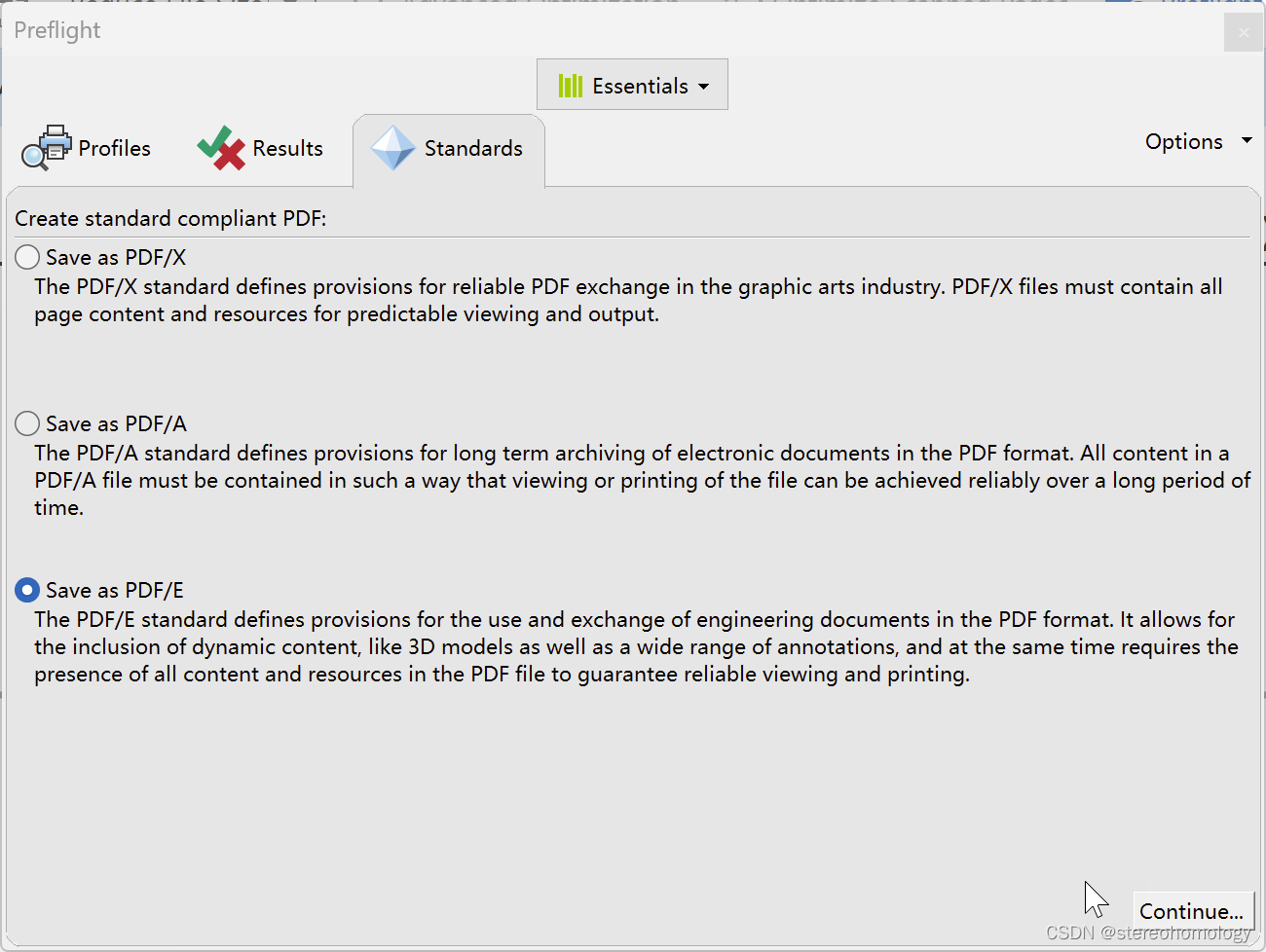
 直接切换到 Standard下面,选择后面两种PDF标准:
直接切换到 Standard下面,选择后面两种PDF标准:
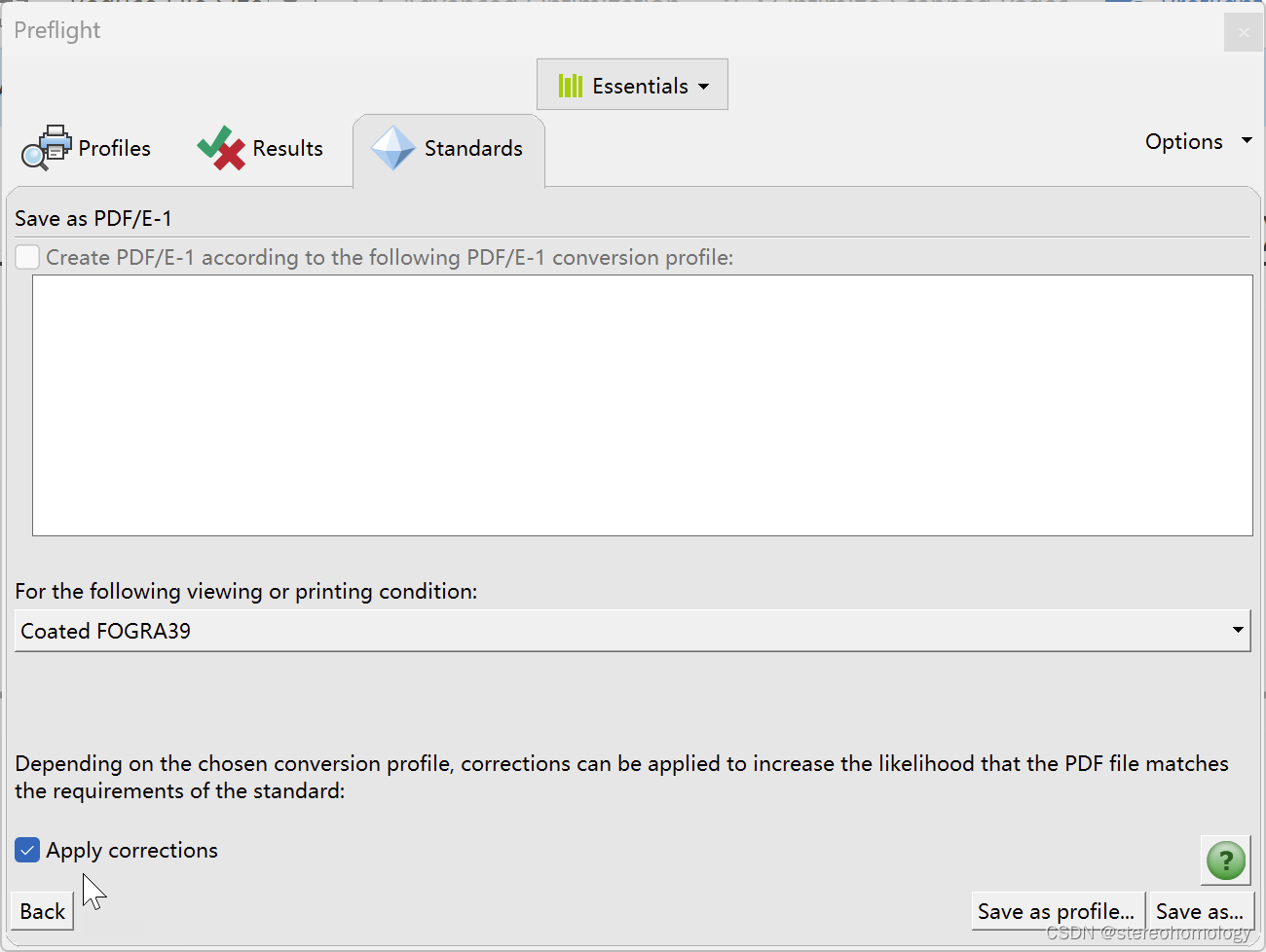
 一路继续,记得勾选apply corrections:
一路继续,记得勾选apply corrections:
 保存好之后问题就解决了。
保存好之后问题就解决了。
碰到不少类似的文件,发现这样解决比较简单。
https://helpx.adobe.com/acrobat/using/analyzing-documents-preflight-tool-acrobat.html
文章来源:https://blog.csdn.net/stereohomology/article/details/135616246
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何防止SQL注入和跨站脚本攻击?
- 黑马程序员——javase基础——day05——面向对象基础
- 走过的2023:在挑战中领悟,在仿徨中成长
- L1-072:刮刮彩票
- 跨平台应用程序开发软件,携RAD Studio 12新版上线
- Hive表加工为知识图谱实体关系表标准化流程
- [学习笔记]刘知远团队大模型技术与交叉应用L3-Transformer_and_PLMs
- 管控品牌价格就是在维护品牌价值
- SpringCloud OpenFegin 传递Date类型的参数时,接收端多出14个小时的问题
- Qml之自定义Button