66.Go从零搭建一个orm框架【简版】
一:前置学习
1、 为什么要用orm
我们在使用各种语言去做需求的时候,不管是Java,Golang还是C++等语言,应该都接触过使用ORM去链接数据库,这些ORM有些是项目组自己整合实现的,也有些是用的开源的组件。特别在1个全新的项目中,我们都会用一个ORM框架去连接数据库,而不是直接用原生代码去写SQL连接,原因有很多,有安全考虑,有性能考虑,但是,更多的我觉得还是开发效率低,因为有时候一些SQL写起来也是很复杂很累的,特别是查询列表的时候,又是分页,又是结果集,还需要自己for next去判断和遍历,是真的有累,开发效率非常低。如果有个ORM,数据库config一配,几个链式函数一调,咔咔咔,结果就出来了。
所以ORM就是我们和数据库交互的中间件,我们通过ORM提供的各种快捷的方法去和数据库产生交互,继而更加方便高效的实现功能。
一句话总结什么是ORM: 提供更加方便快捷的curd方法去和数据库产生交互。
Java用的较多的是Mybatis,Go用的较多的是Gorm。这里我们自己用Go造一个简版的。
2、Golang里面是如何原生连接MySQL的
说完了啥是ORM,以及为啥用ORM之后,我们再看下Golang里面是如何原生连接MySQL的,这对于我们开发一个ORM帮助很大,只有弄清楚了它们之间交互的原理,我们才能更好的开始造。
原生代码连接MySQL,一般是如下步骤。
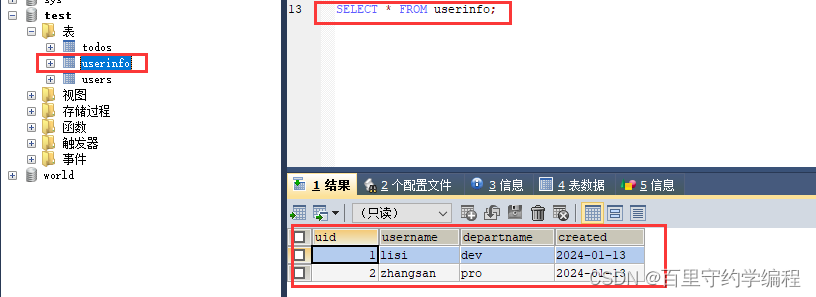
建立数据表:
CREATE TABLE `userinfo` (
`uid` INT(10) NOT NULL AUTO_INCREMENT,
`username` VARCHAR(64) NULL DEFAULT NULL,
`departname` VARCHAR(64) NULL DEFAULT NULL,
`created` DATE NULL DEFAULT NULL,
PRIMARY KEY (`uid`)
)
首先是导入sql引擎和mysql的驱动,然后提供初始化DB和获取DB连接的方法,如下:
package go_raw_sql
import (
"database/sql"
"time"
_ "github.com/go-sql-driver/mysql"
)
var db *sql.DB
func Init() {
//第一个参数是驱动名
res, err := sql.Open("mysql", "root:root@tcp(127.0.0.1:3306)/test?charset=utf8")
if err != nil {
panic(any(err.Error()))
}
db = res
}
func GetDb() *sql.DB {
return db
}
然后,我们快速过一下,如何增删改查:
插入数据:
func Create() {
//方式一:
result, err := db.Exec("INSERT INTO userinfo (username, departname, created) VALUES (?, ?, ?)", "lisi", "dev", "2024-01-13")
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result.LastInsertId())
//方式二:
stmt, err := db.Prepare("INSERT INTO userinfo (username, departname, created) VALUES (?, ?, ?)")
result, err = stmt.Exec("zhangsan", "pro", time.Now().Format("2006-01-02"))
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result.LastInsertId())
}
测试:执行TestCreate
package go_raw_sql
import (
"testing"
)
func TestInit(t *testing.T) {
Init()
}
func TestCreate(t *testing.T) {
// 初始化DB
Init()
// 往userinfo中插入记录
Create()
}
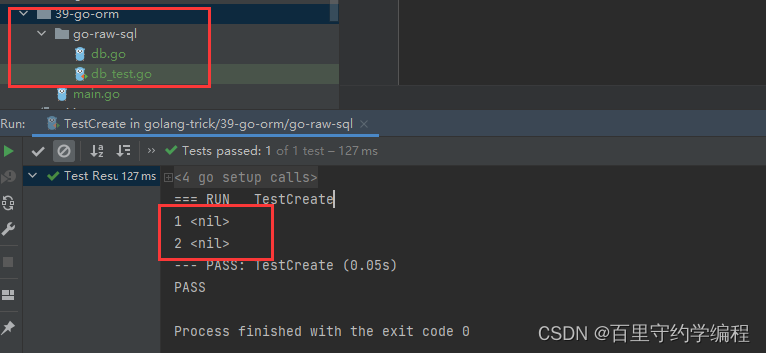
删除数据:
func Delete(){
//方式一:
result, err := db.Exec("delete from userinfo where uid=?", 1)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result.RowsAffected())
//方式二:
stmt, err := db.Prepare("delete from userinfo where uid=?")
_, _ = stmt.Exec("1")
}
更新数据
func Update(){
//方式一:
result, err := db.Exec("update userinfo set username=? where uid=?", "lisi", 2)
if err != nil {
fmt.Println(err)
return
}
fmt.Println(result.RowsAffected())
//方式二:
stmt, err := db.Prepare("update userinfo set username=? where uid=?")
_, _ = stmt.Exec("lisi", 2)
}
查询数据
func Query() {
//单条
var username, departname, created string
err := db.QueryRow("select username, departname, created from userinfo where uid=?", 2).Scan(&username, &departname, &created)
if err != nil {
fmt.Println("QueryRow error :", err.Error())
return
}
fmt.Println("username: ", username, "departname: ", departname, "created: ", created)
//多条:
rows, err := db.Query("select username, departname, created from userinfo where username=?", "li")
if err != nil {
fmt.Println("QueryRow error :", err.Error())
return
}
//定义一个结构体,存放数据模型
type UserInfo struct {
Username string `json:"username"`
Departname string `json:"departname"`
Created string `json:"created"`
}
//初始化
var user []UserInfo
for rows.Next() {
var username1, departname1, created1 string
if err := rows.Scan(&username1, &departname1, &created1); err != nil {
fmt.Println("Query error :", err.Error())
return
}
user = append(user, UserInfo{Username: username1, Departname: departname1, Created: created1})
}
fmt.Println(fmt.Sprintf("%v", user))
}
总结一下,Golang里面原生连接MySQL的方法,非常简单,就是直接写sql嘛,简单粗暴点就直接Exec,复杂点但是效率会高一些就先Prepare再Exec。总体而言,这个学习成本是非常低的,最大的问题就是麻烦和开发效率低。
所以我们是不是可以基于原生代码库的这个优势,自己开发1个ORM呢
- 第一:它能提供了各式各样的方法来提高开发效率
- 第二:底层直接转换拼接成最终的
SQL,去调用这个原生的组件,来和MySQL交互。这样既能提高开发效率,又能保持足够的高效和简单。
3、ORM框架构想
本ORM库原理是简单的SQL拼接。暴露各种CURD方法,并在底层逻辑拼接成Prepare和Eexc占位符部分,继而来调用“github.com/go-sql-driver/mysql”驱动的方法来实现和数据库交互。
首先,先取个厉害的名字吧:smallorm(简版orm)
然后,整个调用过程采用链式的方法,这样比较方便,比如这样子
db.Where().Where().Order().Limit().Select()
其次,暴露的CURD方法,使用起来要简单,名字要清晰,无歧义,不要搞一大堆复杂的间接调用。
OK,我们梳理一下,sql里面常用到的一些curd的方法,把他们整理成ORM的一个个方法,并按照下面这个列表一步一步来实现我们的orm,如下:
-
连接
Connect -
设置表名
Table -
新增/替换
Insert/Replace -
条件
Where -
删除
Delete -
修改
Update -
查询
Select -
执行原生
SQLExec/Query -
设置查询字段
Field -
设置大小
Limit -
聚合查询
Count/Max/Min/Avg/Sum -
排序
Order -
分组
Group -
分组后判断
Having -
获取执行生成的完整
SQLGetLastSql -
事务
Begin/Commit/Rollback
其中Insert/Replace/Delete/Select/Update是整个链式操作的最后一步。是真正的和MySQL交互的方法,后面不能再链式接其他的操作方法。
所以,我们提前可以畅享一下,这个完成后的ORM,是如何调用的:
增:
type User1 struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User1{
Username: "EE",
Departname: "22",
Status: 1,
}
// insert into userinfo (username,departname,status) values ('EE', '22', 1)
id, err := e.Table("userinfo").Insert(user2)
删:
// delete from userinfo where (uid = 10805)
result1, err := e.Table("userinfo").Where("uid", "=", 10805).Delete()
改:
// update userinfo set departname=110 where (uid = 10805)
result1, err := e.Table("userinfo").Where("uid", "=", 10805).Update("departname", 110)
查:
// select uid, status from userinfo where (departname like '%2') or (status=1) order by uid desc limit 1
result, err := e.Table("userinfo").Where("departname", "like", "%2").OrWhere("status", 1).Order("uid", "desc").Limit(1).Field("uid, status").Select()
//select uid, status from userinfo where (uid in (1,2,3,4,5)) or (status=1) order by uid desc limit 1
result, err := e.Table("userinfo").Where("uid", "in", []int{1,2,3,4,5}).OrWhere("status", 1).Order("uid", "desc").Limit(1).Field("uid, status").SelectOne()
type User1 struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User1{
Username: "EE",
Departname: "22",
Status: 1,
}
user3 := User1{
Username: "EE",
Departname: "22",
Status: 2,
}
// select * from userinfo where (Username='EE' and Departname='22' and Status=1) or (Username='EE' and Departname='22' and Status=2) limit 1
id, err := e.Table("userinfo").Where(user2).OrWhere(user3).SelectOne()
二: 开始造
1、连接Connect
连接MySQL比较简单,直接把原生的sql.Open(“mysql”,dsn)方法套一个函数壳即可,但是需要考虑协程和长连接的保持以及ping失败的情况。我们这里第一版本就先不考虑了。
第一步,先构造1个变量引擎SmallormEngine,它是结构体类型的,用来存储各种各样的数据,其他的对外暴露的CURD方法也是基于这个结构体来集成的。
engine/engine.go
package engine
import "database/sql"
type SmallormEngine struct { //orm引擎
Db *sql.DB // 包含原生DB,用于执行底层操作
TableName string // 表名
Prepare string // 预处理SQL语句
AllExec []interface{} // 替代SQL中占位符的实际参数
Sql string // 最后执行的SQL语句,用于日志打印输出
WhereParam string // where and条件拼接
LimitParam string // limit拼接
OrderParam string // order拼接
OrWhereParam string // where or条件拼接
WhereExec []interface{} // 替换where中占位的符实际参数
UpdateParam string // update 拼接
UpdateExec []interface{} // 替换update中占位的符实际参数
FieldParam string // 查询字段拼接
TransStatus int // 事务状态
Tx *sql.Tx // 包含原生事务,用于执行底层事务操作
GroupParam string // group 拼接
HavingParam string // having 拼接
}
因为我们这ORM的底层本质是SQL拼接,所以,我们需要把各种操作方法生成的数据,都保存到这个结构体的各个变量上,方便最后一步生成SQL。其中where和update还提供了占位符方式WhereExec和UpdateExec , select、delete直接用的whereExec,所以不需要额外提供selectExec和deleteExec,update则因为有update tableXXX set XX = ?where yy = ?,所以需要一个updateExec拼接set部分。
另外需要简单说明的是这2个字段:
Db字段的类型是*sql.DB,它用于直接进行CURD操作Tx是*sql.Tx类型的,它是数据库的事务操作,用于回滚和提交。这个后面会详细讲,这里有一个大致的概念即可。
接下来就可以写连接操作了:创建了一个方法NewMysql来创建1个新的连接,参数是(用户名,密码,ip和端口,数据库名)。
engine/engine.go
//新建Mysql连接
func NewMysql(Username string, Password string, Address string, Dbname string) (*SmallormEngine, error) {
dsn := Username + ":" + Password + "@tcp(" + Address + ")/" + Dbname + "?charset=utf8&timeout=5s&readTimeout=6s"
db, err := sql.Open("mysql", dsn)
if err != nil {
return nil, err
}
//最大连接数等配置,先占个位
//db.SetMaxOpenConns(3)
//db.SetMaxIdleConns(3)
return &SmallormEngine{
Db: db,
FieldParam: "*",
}, nil
}
获取到连接后,如何实现链式的方式调用呢?只需要在每个方法返回实例本身即可,类似装饰器模式,不断的改变对象的值,但是返回结果又是该对象,比如:
func (e *SmallormEngine) Where (name string) *SmallormEngine {
// 此处省去了具体逻辑
return e
}
func (e *SmallormEngine) Limit (name string) *SmallormEngine {
// 此处省去了具体逻辑
return e
}
这样我们就可以链式的调用了:
e.Where().Where().Limit()
2、设置/读取表名Table/GetTable
我们需要1个设置和读取数据库表名字的方法,因为我们所有的CURD都是基于某张表的:这样我们每一次调用Table()方法,就给本次的执行设置了一个表名。并且会清空SmallormEngine节点上挂载的所有其他数据,只有Db、TableName以及Tx三个字段不重置。
// Table 设置表名,将表名存于SmallormEngine的TableName字段中,用于后续的SQL拼接
func (e *SmallormEngine) Table(name string) *SmallormEngine {
e.TableName = name
// 重置引擎
e.resetSmallormEngine()
return e
}
func (e *SmallormEngine) GetTable() string {
return e.TableName
}
func (e *SmallormEngine) resetSmallormEngine() {
e.Prepare = ""
e.AllExec = nil
e.Sql = ""
e.WhereParam = ""
e.LimitParam = ""
e.OrderParam = ""
e.OrWhereParam = ""
e.WhereExec = nil
e.UpdateParam = ""
e.UpdateExec = nil
e.FieldParam = ""
e.TransStatus = 0
e.GroupParam = ""
e.HavingParam = ""
}
3、新增/替换Insert/Replace
单个数据插入
下面就是本ORM第一个重头戏和挑战点了,如何往数据库里插入数据?在如何用ORM实现本功能之前,我们先回忆下上面讲的原生的代码是如何插入的:
我们用 先Prepare再Exec 这种方式,高效且安全:
stmt, err := db.Prepare("INSERT INTO userinfo (username, departname, created) VALUES (?, ?, ?)")
result2, err := stmt.Exec("zhangsan", "pro", time.Now().Format("2006-01-02"))
我们分析下它的做法:
先在Prepare里,把要插入的数据的value值用?占位符代替,有几个value就用几个?,然后在Exec里面,把value值给补上,和?的数量一致即可。
ok,整明白了。那我们就按照这2步拆分数据即可。
为了保持方便,我们调用这个Insert方法进行插入数据的时候,参数是要传1个k-v的键值对类型,比如[field1:value1,field2:value2,field3:value3],field表示表的字段,value表示字段的值。在go语言里面,这样的类型可以是Map或者Struct,但是Map必须得都是同一个类型的,显然是不符合数据库表里面,不同的字段可能是不同的类型的这一情况,所以,我们选择了Struct结构体, 它里面是可以有多种数据类型存在,也刚好符合情况。
由于go里面的数据都得是先定义类型,再去初始化1个值,所以,大致的调用过程是这样的:
type User struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User{
Username: "EE",
Departname: "22",
Status: 1, }
id, err := e.Table("userinfo").Insert(user2)
我们注意下,User结构体的每一个元素后面都有一个sql:“xxx”,这个叫Tag标签。这是干啥用的呢?是因为go里面首字母大写表示是可见的变量,所以如果是可见的变量都是大写字母开头,而sql语句表里面的字段首字母名一般是小写,所以,为了照顾这个特殊的关系,进行转换和匹配,才用了这个标签特性。如果你的表的字段类型也是大写字母开头,那就可以不需要这个标签,下面我们会具体说到如何转换匹配的。
所以,接下来的难点就是把user2进行解析,拆分成这2步:
- 第一步:将
sql:“xxx”标签进行解析和匹配,依次替换成全小写的,解析成(username,departname,status),并且依次生成对应数量的?。
stmt, err := db.Prepare("INSERT INTO userinfo (username, departname, status) VALUES (?, ?, ?)")
- 第二步:将
user2的字段的值都拆出来,放入到Exec中。
result2, err := stmt.Exec("EE", "22", 1)
那么,user2里面的3个子元素的field,如何解析成(username,departname,status)呢?由于我们是一个通用的方法,golang是没法直接通过for循环来知道传入的数据结构参数里面包含哪些field和value的,咋办呢?这个时候,大名鼎鼎的反射就可以派上用场了。我们可以通过反射来推导出传入的结构体变量,它的field是多少,value是什么,类型是什么。tag是什么。都可以通过反射来推导出来。
我们现在试一下其中的2个函数reflect.TypeOf和reflect.ValueOf:
type User struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User{
Username: "EE",
Departname: "22",
Status: 1,
}
//反射出这个结构体变量的类型
t := reflect.TypeOf(user2)
//反射出这个结构体变量的值
v := reflect.ValueOf(user2)
fmt.Printf("==== print type ====\n%+v\n", t)
fmt.Printf("==== print value ====\n%+v\n", v)
我们打印看看,结果是啥?
==== print type ====
main.User
==== print value ====
{Username:EE Departname:22 Status:1}
通过上面的打印,我们可以知道了,他的类型是User这个类型,值也是我们想要的值。OK。第一步完成。接下来,我们接下来通过for循环遍历t.NumField()和t.Field(i)来拆分里面的值:
//反射type和value
t := reflect.TypeOf(user2)
v := reflect.ValueOf(user2)
//字段名
var fieldName []string
//问号?占位符
var placeholder []string
//循环判断
for i := 0; i < t.NumField(); i++ {
//小写开头,无法反射,跳过
if !v.Field(i).CanInterface() {
continue
}
//解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
//跳过自增字段
if strings.Contains(strings.ToLower(sqlTag), "auto_increment") {
continue
} else {
fieldName = append(fieldName, strings.Split(sqlTag, ",")[0])
placeholder = append(placeholder, "?")
}
} else { // 没有sql tag的字段用字段名
fieldName = append(fieldName, t.Field(i).Name)
placeholder = append(placeholder, "?")
}
//字段的值
e.AllExec = append(e.AllExec, v.Field(i).Interface())
}
//拼接表,字段名,占位符
e.Prepare = "insert into " + e.GetTable() + " (" + strings.Join(fieldName, ",") + ") values(" + strings.Join(placeholder, ",") + ")"
如上面所示:t.NumField()可以获取到这个结构体有多少个字段用于for循环,t.Field(i).Tag.Get(“sql”)可以获取到包含sql:“xxx”的tag的值,我们用来sql匹配和替换。t.Field(i).Name可以获取到字段的field名字。通过v.Field(i).Interface()可以获取到字段的value值。e.GetTable()来获取我们设置的表的名字。通过上面的这一段稍微有点复杂的反射和拼接,我们就完成了Db.Prepare部分:
e.Prepare = "INSERT INTO userinfo (username, departname, status) VALUES (?, ?, ?)"
接下来,我们来获取stmt.Exec里面的值的部分,上面我们把所有的值都放入到了e.AllExec这个属性里面,之所以它用interface类型,是因为,结构体里面的值的类型是多变的,有可能是int型,也可能是string类型。
//申明stmt类型
var stmt *sql.Stmt
//第一步:Db.prepare
stmt, err = e.Db.Prepare(e.Prepare)
//第二步:执行exec,注意这是stmt.Exec
result, err := stmt.Exec(e.AllExec...)
if err != nil {
//TODO
}
//获取自增ID
id, _ := result.LastInsertId()
单个插入与替换插入完整代码如下:
func (e *SmallormEngine) insertData(data interface{}, insertType string) (int64, error) {
// 反射type和value
t := reflect.TypeOf(data)
v := reflect.ValueOf(data)
if t.Kind() != reflect.Struct {
return 0, errors.New("插入时必须数据必须是结构体类型")
}
// 字段名
var fieldName []string
// 问号?占位符
var placeholder []string
// 循环判断
for i := 0; i < t.NumField(); i++ {
// 小写开头,无法反射,跳过
if !v.Field(i).CanInterface() {
continue
}
// 解析tag,找出真实的SQL字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
// 跳过自增字段
if strings.Contains(strings.ToLower(sqlTag), "auto_increment") {
continue
} else {
fieldName = append(fieldName, strings.Split(sqlTag, ",")[0])
placeholder = append(placeholder, "?")
}
} else { // 结构体当前字段没有sql tag,则用字段名去和db中表的字段名映射
fieldName = append(fieldName, t.Field(i).Name)
placeholder = append(placeholder, "?")
}
// 字段的值
e.AllExec = append(e.AllExec, v.Field(i).Interface())
}
// 遍历完结构体所有的字段后,拼接表名、字段名、占位符等形成SQL
e.Prepare = insertType + " into " + e.GetTable() + " (" + strings.Join(fieldName, ",") + ") values (" + strings.Join(placeholder, ",") + ")"
// 声明stmt类型
var stmt *sql.Stmt
// 第一步:Db.prepare
stmt, err := e.Db.Prepare(e.Prepare)
if err != nil {
return 0, e.setErrorInfo(err)
}
// 第二步:执行exec,注意这里是stmt.Exec
result, err := stmt.Exec(e.AllExec...)
if err != nil {
return 0, e.setErrorInfo(err)
}
// 获取自增ID
id, _ := result.LastInsertId()
return id, nil
}
// 自定义错误格式
func (e *SmallormEngine) setErrorInfo(err error) error {
_, file, line, _ := runtime.Caller(1)
return errors.New("File: " + file + ":" + strconv.Itoa(line) + ", " + err.Error())
}
接下来介绍批量插入、批量替换插入
- 批量插入,传入的数据就是一个切片数组了,即
[]struct这样的数据类型了。- 我们得先用反射算出,这个数组有多少个元素。这样好算出 VALUES 后面有几个
()的占位符。- 搞2个for循环,外面的for循环,得出切片中元素struct的各字段的名字或sql tag中的名字。里面的第二个for循环,就和单个插入的反射操作一样了,就是算出每一个子元素有几个字段,反射出field名字,以及对应
()里面有几个?问号占位符。- 2层for循环把切片里面的每个元素的每个字段的value放入到1个统一的AllExec中。
OK,直接上代码吧:
//批量插入
func (e *SmallormEngine) BatchInsert(data interface{}) (int64, error) {
return e.batchInsertData(data, "insert")
}
//批量替换插入
func (e *SmallormEngine) BatchReplace(data interface{}) (int64, error) {
return e.batchInsertData(data, "replace")
}
//批量插入
func (e *SmallormEngine) batchInsertData(batchData interface{}, insertType string) (int64, error) {
//反射解析
getValue := reflect.ValueOf(batchData)
//切片大小,只有切片类型才能调用反射中的Len,所以先做一下类型判断
if getValue.Kind() != reflect.Slice {
panic("传入的不是切片类型")
}
l := getValue.Len()
//字段名
var fieldName []string
//占位符
var placeholderString []string
//循环判断
for i := 0; i < l; i++ {
value := getValue.Index(i) // Value of item
typed := value.Type() // Type of item
if typed.Kind() != reflect.Struct {
panic("批量插入的子元素必须是结构体类型")
}
num := value.NumField()
//子元素值
var placeholder []string
//循环遍历结构体的每个字段
for j := 0; j < num; j++ {
//小写开头,无法反射,跳过
if !value.Field(j).CanInterface() {
continue
}
//解析tag,找出真实的sql字段名
sqlTag := typed.Field(j).Tag.Get("sql")
if sqlTag != "" {
//跳过自增字段
if strings.Contains(strings.ToLower(sqlTag), "auto_increment") {
continue
} else {
//字段名只记录切片中第一个元素的
if i == 0 {
fieldName = append(fieldName, strings.Split(sqlTag, ",")[0])
}
placeholder = append(placeholder, "?")
}
} else {
//字段名只记录切片中第一个元素的
if i == 0 {
fieldName = append(fieldName, typed.Field(j).Name)
}
placeholder = append(placeholder, "?")
}
//字段值
e.AllExec = append(e.AllExec, value.Field(j).Interface())
}
//子元素拼接成多个()括号后的值
placeholderString = append(placeholderString, "("+strings.Join(placeholder, ",")+")")
}
//拼接表,字段名,占位符
e.Prepare = insertType + " into " + e.GetTable() + " (" + strings.Join(fieldName, ",") + ") values " + strings.Join(placeholderString, ",")
//prepare
var stmt *sql.Stmt
var err error
stmt, err = e.Db.Prepare(e.Prepare)
if err != nil {
return 0, e.setErrorInfo(err)
}
//执行exec,注意这是stmt.Exec
result, err := stmt.Exec(e.AllExec...)
if err != nil {
return 0, e.setErrorInfo(err)
}
//获取自增ID
id, _ := result.LastInsertId()
return id, nil
}
//自定义错误格式
func (e *SmallormEngine) setErrorInfo(err error) error {
_, file, line, _ := runtime.Caller(1)
return errors.New("File: " + file + ":" + strconv.Itoa(line) + ", " + err.Error())
}
开始总结一下上面这一坨关键的地方。首先是获取这个切片的大小,用于第一个for循环。可以通过下面的2行代码获取:
//反射解析
getValue := reflect.ValueOf(batchData)
//切片大小
l := getValue.Len()
其次,在第一个for循环里面,可以通过value:= getValue.Index(i)来获取这个切片里面的第i个元素的值,类似于上面插入单个数据中,反射出结构体的值一样:v:= reflect.ValueOf(data)
然后,通过typed:= value.Type()来获取这第i个元素的类型。类似于上面插入单个数据中,反射出结构体的类型一样:t := reflect.TypeOf(data) 。这个东西被反射出来,主要是为了获取tag标签用。
第二个for循环里面的反射逻辑,基本上是和单个插入是一样的了,唯一需要注意的就是,fieldName的值,因为我们只需要1个,所以我们用i==0判断了一下。加入单次即可。
再一个就是placeholderString这个变量,因为我们为了实现多个()的效果,所以就又搞了1个切片placeholderString拼接多个placeholder。
这样,批量插入,批量替换插入的逻辑就完成了。
单个和批量合二为一
为了使我们的ORM足够的优雅和简单,我们可以把单个插入和批量插入,搞成1个方法暴露出去。那怎么识别出传入的数据是单个结构体,还是切片结构体呢?还是得用反射:
reflect.ValueOf(data).Kind()
它能给出我们答案。如果我们传的是单个结构体,那么它的值就是Struct,如果是切片数组,那么值就是Slice和Array。这样我们就好办了,我们只需要稍做判断即可:
//插入
func (e *SmallormEngine) Insert(data interface{}) (int64, error) {
//判断是批量还是单个插入
getValue := reflect.ValueOf(data).Kind()
if getValue == reflect.Struct {
return e.insertData(data, "insert")
} else if getValue == reflect.Slice || getValue == reflect.Array {
return e.batchInsertData(data, "insert")
} else {
return 0, errors.New("插入的数据格式不正确,单个插入格式为: struct,批量插入格式为: []struct")
}
}
//替换插入
func (e *SmallormEngine) Replace(data interface{}) (int64, error) {
//判断是批量还是单个插入
getValue := reflect.ValueOf(data).Kind()
if getValue == reflect.Struct {
return e.insertData(data, "replace")
} else if getValue == reflect.Slice || getValue == reflect.Array {
return e.batchInsertData(data, "replace")
} else {
return 0, errors.New("插入的数据格式不正确,单个插入格式为: struct,批量插入格式为: []struct")
}
}
OK,完成。
4、条件Where
结构体参数调用
下面,我们开始实现Where方法的逻辑,这个where主要是为了替换sql语句中where后面这部分的逻辑,sql语句中where用的还是非常多的,比如原生sql:
select * from userinfo where status = 1
delete from userinfo where status = 1 or departname != "aa"
update userinfo set departname = "bb" where status = 1 and departname = "aa"
所以,把where后面的数据单独拆出来,搞成1个Where方法是很有必要的。大部分的ORM也是这样做的。
通过观察上面3句sql,我们可以得出基本的where的结构,要么只有1个条件,这个条件的比较复符是丰富的,比如:=, !=, like,<,>等等。要么是多个条件,用and或者or隔开,表示且和或的关系。
通过最上面的原生代码,我们是可以发现的,where部分也是一样的,先用Prepare生成问号占位符,再和Exce替换值的方式来操作。
stmt, err := db.Prepare("delete from userinfo where uid=?")
result3, err := stmt.Exec("1")
stmt, err := db.Prepare("update userinfo set username=? where uid=?")
result, err := stmt.Exec("lisi", 2)
所以,where部分的拆分,其实也是分2步来走。和插入的2步走的逻辑是一样的。大致的调用过程如下:
type User struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User{
Username: "EE",
Departname: "22",
Status: 1,
}
result1, err1 := e.Table("userinfo").Where(user2).Delete()
result2, err2 := e.Table("userinfo").Where(user2).Select()
我们本次实现的是Where部分,where是中间层,它不会具体去执行结果的,它做的仅仅是将数据拆分出来,用2个新的字段WhereParam和WhereExec来暂存数据,给最后的CURD操作方法来使用。
我们开始写代码,和Insert方法的反射逻辑几乎一样。
func (e *SmallormEngine) Where(data interface{}) *SmallormEngine {
//反射type和value
t := reflect.TypeOf(data)
v := reflect.ValueOf(data)
//字段名
var fieldNameArray []string
//循环解析
for i := 0; i < t.NumField(); i++ {
//首字母小写,不可反射
if !v.Field(i).CanInterface() {
continue
}
//解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
fieldNameArray = append(fieldNameArray, strings.Split(sqlTag, ",")[0]+"=?")
} else {
fieldNameArray = append(fieldNameArray, t.Field(i).Name+"=?")
}
//反射出Exec的值。
e.WhereExec = append(e.WhereExec, v.Field(i).Interface())
}
//拼接
e.WhereParam += strings.Join(fieldNameArray, " and ")
return e
}
这样,我们就可以反复调用Where(),转换成2个暂存变量。我们打印下这2个值看看:
WhereParam = "username=? and departname=? and Status=?"
WhereExec = []interface{"EE", "22", 1}
由于Where()是中间态的方法,是可以提供多次调用的,每次调用都是and的关系。比如这样:
e.Table("userinfo").Where(user2).Where(user3).XXX
所以,我们得改造一下e.WhereParam得让他拼接上一次生成的生成的数据。
先判断理一下,是否为空,如果不为空,则说明这是第二次调用了,我们用 “and (”来做隔离。
//多次调用判断
if e.WhereParam != "" {
e.WhereParam += " and ("
} else {
e.WhereParam += "("
}
//结束拼接的时候,加上结束括号“) ”。
e.WhereParam += strings.Join(fieldNameArray, " and ") + ") "
这样,就达到了我们的目的了。我们看下多次调用后的打印结果:
WhereParam = "(username=? and departname=? and status=?) and (username=? and departname=? and status=?)"
WhereExec = []interface{"EE", "22", 1, "FF", "33", 0}
完整代码:
func(e *SmallormEngine) Where(data interface{}) *SmallormEngine {
// 反射type和value
t := reflect.TypeOf(data)
v := reflect.ValueOf(data)
if t.Kind() != reflect.Struct {
panic(any("该Where方法参数必须是结构体类型"))
}
// 字段名
var fieldNameArray []string
// 循环解析
for i:= 0; i < t.NumField();i++ {
// 首字母小写,不可导出,不可反射
if !v.Field(i).CanInterface() {
continue
}
// 解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != ""{
fieldNameArray = append(fieldNameArray,strings.Split(sqlTag,",")[0] + "?")
} else {
fieldNameArray = append(fieldNameArray,t.Field(i).Name)
}
// 反射出Exec的值
e.WhereExec = append(e.WhereExec,v.Field(i).Interface())
}
// 拼接到whereParam中
if e.WhereParam != ""{
e.WhereParam +=" and ("
} else {
e.WhereParam += "("
}
e.WhereParam += strings.Join(fieldNameArray," and ") + ") "
return e
}
需要注意的是,这样方式的调用,我们为了简化调用的结构更清晰更简单,每个条件之间默认都是=的关系。如果有其他的关系判断,可以用下面的方式。
单个字符串参数的调用
上面的Where方法的参数,其实是我们和Insert一样,传入的是1个结构体,但是有时候,如果传入1个结构体,得先定义再实例化,也很麻烦。而且有时候,我们仅仅只需要查询1个字段,如果再去定义1个结构体再实例化就太麻烦了。所以,我们ORM还得提供快捷的方法调用,比如:
Where("uid", "=", 1234)
Where("uid", ">=", 1234)
Where("uid", "in", []int{2, 3, 4})
这样,我们也可以用其他非=的判断表达式,比如:!=,like,not in,in等。
OK,那我们开始写一下,这种方式怎么判断呢?对比传入结构体的方式更简单:方法有3个参数,第一个是需要查询的字段,第2个是比较符,第三个是查询的值。
func (e *SmallormEngine) Where(fieldName string, opt string, fieldValue interface{}) *SmallormEngine {
//区分是操作符in的情况
data2 := strings.Trim(strings.ToLower(opt), " ")
if data2 == "in" || data2 == "not in" {
//判断传入的是切片
reType := reflect.TypeOf(fieldValue).Kind()
if reType != reflect.Slice && reType != reflect.Array {
panic("in/not in 操作传入的数据必须是切片或者数组")
}
//反射值
v := reflect.ValueOf(fieldValue)
//数组/切片长度
dataNum := v.Len()
//占位符
ps := make([]string, dataNum)
for i := 0; i < dataNum; i++ {
ps[i] = "?"
e.WhereExec = append(e.WhereExec, v.Index(i).Interface())
}
//拼接
e.WhereParam += fieldName + " " + opt + " (" + strings.Join(ps, ",") + ")) "
} else {
e.WhereParam += fieldName + " " + opt + " ?) "
e.WhereExec = append(e.WhereExec, fieldValue)
}
return e
}
上面代码唯一需要注意的就是第二参数如果是in/not in操作符的话,后面第三个参数要是切片类型,就得反射出来,用 in (?,?,?)这样的方式。
所以,我们把这2种方式,拼接一下,融合成1种方式,智能的去判断即可,下面是完整的代码:
//传入where条件
func (e *SmallormEngine) Where(data ...interface{}) *SmallormEngine {
//判断是结构体还是多个字符串
var dataType int
if len(data) == 1 {
dataType = 1 // 结构体类型
} else if len(data) == 2 {
dataType = 2 // 两个参数,默认用 = 拼接
} else if len(data) == 3 {
dataType = 3 // 三个参数,指定了操作符
} else {
panic("参数个数错误")
}
//多次调用判断
if e.WhereParam != "" {
e.WhereParam += " and ("
} else {
e.WhereParam += "("
}
//如果是结构体
if dataType == 1 {
t := reflect.TypeOf(data[0])
v := reflect.ValueOf(data[0])
//字段名
var fieldNameArray []string
//循环解析
for i := 0; i < t.NumField(); i++ {
//首字母小写,不可反射
if !v.Field(i).CanInterface() {
continue
}
//解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
fieldNameArray = append(fieldNameArray, strings.Split(sqlTag, ",")[0]+"=?")
} else {
fieldNameArray = append(fieldNameArray, t.Field(i).Name+"=?")
}
e.WhereExec = append(e.WhereExec, v.Field(i).Interface())
}
//拼接
e.WhereParam += strings.Join(fieldNameArray, " and ") + ") "
} else if dataType == 2 {
//直接=的情况
e.WhereParam += data[0].(string) + "=?) "
e.WhereExec = append(e.WhereExec, data[1])
} else if dataType == 3 {
//3个参数的情况
//区分是操作符in的情况
data2 := strings.Trim(strings.ToLower(data[1].(string)), " ")
if data2 == "in" || data2 == "not in" {
//判断传入的是切片
reType := reflect.TypeOf(data[2]).Kind()
if reType != reflect.Slice && reType != reflect.Array {
panic("in/not in 操作传入的数据必须是切片或者数组")
}
//反射值
v := reflect.ValueOf(data[2])
//数组/切片长度
dataNum := v.Len()
//占位符
ps := make([]string, dataNum)
for i := 0; i < dataNum; i++ {
ps[i] = "?"
e.WhereExec = append(e.WhereExec, v.Index(i).Interface())
}
//拼接
e.WhereParam += data[0].(string) + " " + data2 + " (" + strings.Join(ps, ",") + ")) "
} else {
e.WhereParam += data[0].(string) + " " + data[1].(string) + " ?) "
e.WhereExec = append(e.WhereExec, data[2])
}
}
return e
}
上面的写法,参数改成1个了,但是用到了..interface{}这个写法,它表示传入的参数是一个可变参数类型,可以是1个,2个或者3个的情况。用这种方式,方法里获取到的就是1个切片类型了。我们得用len()函数,来判断到底是切片里面有几个元素,然后依次对应上我们的分支逻辑。值得注意的是,当我们传入的是结构体的时候,也是需要用data[0]的方式来获取。
这样,我们就可以用Where方法来快捷的愉快的调用了:
// where uid = 123
e.Table("userinfo").Where("uid", 123)
// where uid not in (2,3,4)
e.Table("userinfo").Where("uid", "not in", []int{2, 3, 4})
// where uid in (2,3,4)
e.Table("userinfo").Where("uid", "in", []int{2, 3, 4})
// where uid like '%2%'
e.Table("userinfo").Where("uid", "like", "%2%")
// where uid >= 123
e.Table("userinfo").Where("uid", ">=", 123)
// where (uid >= 123) and (name = 'vv')
e.Table("userinfo").Where("uid", ">=", 123).Where("name", "vv")
5、条件OrWhere
上面的Where方法生成的数据块之间都是and的关系,其实我们有一些sql是需要or的关系的,比如:
where (uid >= 123) or (name = 'vv')
where (uid = 123 and name = 'vv') or (uid = 456 and name = 'bb')
那么这种情况,其实也是需要考虑进去的,写起来也很简单,只需要新加一个OrWhereParam参数,替换上面Where方法里面的whereParam即可,WhereExec不需要变化。然后把拼接关系改成or,其他代码一摸一样:
func (e *SmallormEngine) OrWhere(data ...interface{}) *SmallormEngine {
...
//判断使用顺序
if e.WhereParam == "" {
panic("WhereOr必须在Where后面调用")
}
//WhereOr条件
e.OrWhereParam += " or ("
...
return e
}
需要注意的是,OrWhere方法是必须得先调用Where后再调用的。因为一般用到了or,前面肯定是有前置的where判断的。
同样,有三种调用方式:
OrWhere("uid", 1234) //默认是等于
OrWhere("uid", ">=", 1234)
OrWhere(uidStruct) //传入1个结构体,结构体之间用and连接
看下使用效果:
// where (uid = 123) or (name = "vv")
e.Table("userinfo").Where("uid", 123).OrWhere("name", "vv")
// where (uid not in (2,3,4)) or (uid not in (5,6,7))
e.Table("userinfo").Where("uid", "not in", []int{2, 3, 4}).OrWhere("uid", "not in", []int{5, 6, 7})
// where (uid like '%2') or (uid like '%5%')
e.Table("userinfo").Where("uid", "like", "%2").OrWhere("uid", "like", "%5%")
// where (uid >= 123) or (uid <= 454)
e.Table("userinfo").Where("uid", ">=", 123).OrWhere("uid", "<=", 454)
// where (username = "EE" and departname = "22" and status = 1) or (name = 'vv') or (status = 1)
type User struct {
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
user2 := User{
Username: "EE",
Departname: "22",
Status: 1,
}
e.Table("userinfo").Where(user2).OrWhere("name", "vv").OrWhere("status", 1)
为了使这个方法更简单的被使用,不搞复杂,这种方式的or关系,实质上是针对于多次调用orWhere的,是不支持同一个结构体里面的数据是or关系的,传入是结构体时,结构体的各字段还是按and拼接的。那如果需要的话,可以这样调用:
// where (username = "EE") or (departname = "22") or (status = 1)
e.Table("userinfo").Where(username, "EE").OrWhere("departname", "22").OrWhere("status", 1)
// where(username = "EE") or(username = "EE" and username = "22" and status = 1)
e.Table("userinfo").Where(username, "EE").OrWhere(uidStruct) //传入1个结构体,结构体之间用and连接
6、删除Delete
删除也是sql逻辑中的最常见的操作了,当我们完成了前面Where和OrWhere的数据逻辑绑定后,其实写Delete方法是最简单的了,为什么呢?因为Delete方法是CURD的最后一步,是直接和数据库进行操交互的了,是不需要我们再去反射各种数据进行绑定了。我们仅仅需要把Where里面绑定的2个值(WhereParam和OrWhereParam),往Prepare和 Exec里面套即可。
我们看下具体是怎么写:
//删除
func (e *SmallormEngine) Delete() (int64, error) {
//拼接delete sql
e.Prepare = "delete from " + e.GetTable()
//如果where不为空
if e.WhereParam != "" || e.OrWhereParam != "" {
e.Prepare += " where " + e.WhereParam + e.OrWhereParam
}
//limit不为空
if e.LimitParam != "" {
e.Prepare += "limit " + e.LimitParam
}
//第一步:Prepare
var stmt *sql.Stmt
var err error
stmt, err = e.Db.Prepare(e.Prepare)
if err != nil {
return 0, e.setErrorInfo(err)
}
e.AllExec = e.WhereExec
//第二步:执行exec,注意这是stmt.Exec
result, err := stmt.Exec(e.AllExec...)
if err != nil {
return 0, e.setErrorInfo(err)
}
//影响的行数
rowsAffected, err := result.RowsAffected()
if err != nil {
return 0, e.setErrorInfo(err)
}
return rowsAffected, nil
}
是不是很熟悉?和Insert方法的逻辑几乎是一样的,只是e.Prepare中的sql语句不一样。
这样看下调用方式和结果:
// delete from userinfo where (uid >= 123) or (uid <=45)
rowsAffected, err := e.Table("userinfo").Where("uid", ">=", 123).OrWhere("uid", "<=", 45).Delete()
7、修改Update
修改数据,也是CURD的最后一步,但是它和Delete不同的是,他是有2个数据需要绑定的,1个通过Where方法绑定的where数据,还有1个,就是需要去更新的数据,这个我们还没做。
update userinfo set status = 1 where (uid >= 123) or (uid <= 454)
其中status=1这部分的数据,我们也是需要提炼出来搞成1个对外暴露的方法。所以,最终的调用方式会是这样的:
e.Table("userinfo").Where("uid", 123).Update("status", 1)
e.Table("userinfo").Where("uid", 123).Update(user2)
和Where的可变参数类似,我们也是提供了2种参数传递方式,既可以传入一个结构体变量,也可以只传入单个更新的变量,用起来会更方便更灵活。
仔细一看,Update中获取数据的方式,和Insert方法插入单个数据的方式不能说特别像吧,可以说简直一模一样啊。
直接上代码吧:
//更新
func (e *SmallormEngine) Update(data ...interface{}) (int64, error) {
//判断是结构体还是多个字符串
var dataType int
if len(data) == 1 {
dataType = 1
} else if len(data) == 2 {
dataType = 2
} else {
return 0, errors.New("参数个数错误")
}
//如果是结构体
if dataType == 1 {
t := reflect.TypeOf(data[0])
v := reflect.ValueOf(data[0])
var fieldNameArray []string
for i := 0; i < t.NumField(); i++ {
//首字母小写,不可反射
if !v.Field(i).CanInterface() {
continue
}
//解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
fieldNameArray = append(fieldNameArray, strings.Split(sqlTag, ",")[0]+"=?")
} else {
fieldNameArray = append(fieldNameArray, t.Field(i).Name+"=?")
}
e.UpdateExec = append(e.UpdateExec, v.Field(i).Interface())
}
e.UpdateParam += strings.Join(fieldNameArray, ",")
} else if dataType == 2 {
//直接=的情况
e.UpdateParam += data[0].(string) + "=?"
e.UpdateExec = append(e.UpdateExec, data[1])
}
//拼接sql
e.Prepare = "update " + e.GetTable() + " set " + e.UpdateParam
//如果where不为空
if e.WhereParam != "" || e.OrWhereParam != "" {
e.Prepare += " where " + e.WhereParam + e.OrWhereParam
}
//limit不为空
if e.LimitParam != "" {
e.Prepare += "limit " + e.LimitParam
}
//prepare
var stmt *sql.Stmt
var err error
stmt, err = e.Db.Prepare(e.Prepare)
if err != nil {
return 0, e.setErrorInfo(err)
}
//合并UpdateExec和WhereExec
if e.WhereExec != nil {
e.AllExec = append(e.UpdateExec, e.WhereExec...)
}
//执行exec,注意这是stmt.Exec
result, err := stmt.Exec(e.AllExec...)
if err != nil {
return 0, e.setErrorInfo(err)
}
//影响的行数
id, _ := result.RowsAffected()
return id, nil
}
其中有一个地方,需要注意的是:合并UpdateExec和WhereExec这一步。需要在e.WhereExec后面加...,这样的目的就是把切片全部展开成1个1个的可变参数,追加到UpdateExec切片的后面。如果不加是会报语法报错的。
cannot use []interface{} literal (type []interface{}) as type interface{} in append
8、查询
查询数据也是平时sql中用到的非常多的方法,通过上面几个方法的实现,我们基本对于增删改很熟悉了,但是,值得注意的是,go原生代码中,查询的写法是不一样的,是没有Prepare和Exec,而是通过QueryRow和Query方法来获取查询数据的,通过看文章最开头的原生golang查询的写法就可以看出。
比如,查询单条数据,我们得先需要把查询的字段定义出来,然后再用Scan()去绑定赋值它们,这个写法感觉太麻烦了
//单条
var username, departname, status string
err := db.QueryRow("select username, departname, status from userinfo where uid=?", 4).Scan(&username, &departname, &status)
if err != nil {
fmt.Println("QueryRow error :", err.Error())
}
fmt.Println("username: ", username, "departname: ", departname, "status: ", status)
再看多条的查询,第一步,得先把查询的数据结构先定义出来,再实例化1个多维的数组,再通过for循环去给这个数组赋值,值得注意的是这个数据结构的字段数得和select出来的字段数保持一致,不然就会丢失。
//多条:
rows, err := db.Query("select username, departname, created from userinfo where username=?", "yang")
if err != nil {
fmt.Println("QueryRow error :", err.Error())
}
//定义一个结构体,存放数据模型
type UserInfo struct {
Username string `json:"username"`
Departname string `json:"departname"`
Created string `json:"created"`
}
//初始化
var user []UserInfo
for rows.Next() {
var username1, departname1, created1 string
if err := rows.Scan(&username1, &departname1, &created1); err != nil {
fmt.Println("Query error :", err.Error())
}
user = append(user, UserInfo{Username: username1, Departname: departname1, Created: created1})
}
麻烦归麻烦,我们还是需要抽丝剥茧,我们还是得找出规律,用我们自定义的方法,去生成符合这样格式的数据。所以,查询又会是另一个难点和挑战点。
为了简化查询逻辑内部实现的复杂度,对于单条的查询,我们舍弃了原生的QueryRow,直接全部用Query+for next替代,这样对于有单条查询,在内部追加1个limit 1来限制数量,继而满足条件。
下面开始吧。
查询多条Select(),返回值为map切片
考虑到要提前定义1个数据结构,再初始化成1个数组,真的是太麻烦了,我想着能不能啥都不传呢?直接按照数据表里的字段名,直接给我输出1个同名字的map切片呢?试一试吧。
比如这样,userinfo表里面有4个字段:“uid, username,departname,status”,我们像下面这样查询,然后就可以返回1个map的数组切片,岂不是美滋滋?
result, err := e.Table("userinfo").Where("status", 1).Select()
返回为:
//type:
[]map[string]string
//value:
[map[departname:v status:1 uid:123 username:yang] map[departname:n status:0 uid:456 username:small]]
那么这种方式实现的前提是,我们可以获取到表的字段有哪些,才能根据这些字段映射成一个map。也好办的,Db.Query给我们返回了一个Columns()方法,它能返回我们本次查询出来的表的字段名是哪些。
比如:
rows, err := db.Query("select uid, username, departname, status from userinfo where username=?", "yang")
if err != nil {
fmt.Println("Query error :", err.Error())
}
column, err := rows.Columns()
if err != nil {
fmt.Println("rows.Columns error :", err.Error())
}
fmt.Println(column)
我们看下返回值:
[uid username departname stauts]
能获取到字段名,那我们就成功了一半,接下来的第二个难题,就是rows.Scan()的数据绑定问题。由于我们是没有预先定义数据类型进行绑定的,所以这个数据,就只能我们动态生成。我们先看下原生Scan()的调用方式。
每次for循环的时候,都是临时生成4个初始值为空的变量,然后把他们的地址传给Scan()方法,通过地址来动态引用赋值。所以,这4个名字其实不重要,你取任何名字都可以,反正最后传的是他们的地址。
for rows.Next() {
var uid1, username1, departname1, status1 string
rows.Scan(&uid1, &username1, &departname1, &status1)
fmt.Println(uid1,username1,departname1,status1)
}
这样我们打印这4个变量,他们就都有值了:
1 yang v 0
12 yi b 1
....
正是利用了这一点,所以我们就可以按照Columns返回的字段个数,动态的生成2个切片,来解决这个映射问题:
//读出查询出的列字段名
column, err := rows.Columns()
if err != nil {
return nil, e.setErrorInfo(err)
}
//values是每个列的值,这里获取到byte里
values := make([][]byte, len(column))
//因为每次查询出来的列是不定长的,用len(column)定住当次查询的长度
scans := make([]interface{}, len(column))
for i := range values {
scans[i] = &values[i]
}
我们新建了2个切片,第一个切片是values,初始值都是空,scans初始值是一个空接口类型的切片,通过一个for循环,把scans每个元素的值,都是values里的每个值的地址。2个进行了深度绑定。
一一对应:
// 打印column的值
[uid username departname stauts]
// 打印values的值
[[] [] [] []]
//打印scans的值
[0xc000056180 0xc000056198 0xc0000561b0 0xc0000561c8]
这样的好处是啥呢?是因为Scan()这个方法,需要传的就是地址符号。接下来。我们就可以这样做了:
for rows.Next() {
rows.Scan(scans[0], scans[1],scans[2], scans[3])
}
这样,scans[0]对应的就是上面例子中的uid1,scans[3]对应的就是上面例子中的status1。scans[0]由于是对values[0]的取地址操作,所以,values[0]的值就变化了,变成了真实的值,所以,这一顿操作下来。values里面的值就变化了:
// 打印column的值
[uid username departname stauts]
// 打印scans的值
[0xc000056180 0xc000056198 0xc0000561b0 0xc0000561c8]
// 打印values的值
[1 yang v 0]
然后,我们再通过这3个切片的下标的映射,就能将表字段和值对应起来,拼接成1个map。
现在碰到1个问题,如果scans里面有十个,甚至几十个参数呢,难道也这样,scans[0],scans[1].....scans[n]展开吗?那和手动写原始代码没啥区别了,有啥办法解决不确定参数的问题吗?当然有,直接看代码:
results := make([]map[string]string, 0)
for rows.Next() {
if err := rows.Scan(scans...); err != nil {
return nil, e.setErrorInfo(err)
}
//每行数据
row := make(map[string]string)
//循环values数据,通过相同的下标,取column里面对应的列名,生成1个新的map
for k, v := range values {
key := column[k]
row[key] = string(v)
}
//添加到map切片中
results = append(results, row)
}
这样,我们就把最关键最核心的数据字段和数据映射问题给解决了,顺便要说的是rows.Scan(scans...)这个最为关键以及巧妙了,可以说是这个方法的最重要的地方,他可以把我们传入的切片全部铺开,当做1个变量1个变量的参数的传入,它解决了我们通用函数里,表字段数不确定的问题。
rows.Scan(scans[0], scans[1],scans[2], scans[3])
↓↓↓
↓↓↓
rows.Scan(scans...)
这样,即使scan里面有100个数据,也没关系,他都会处理好。
好了,我们看下这个方法,完整的代码:
//查询多条,返回值为map切片
func (e *SmallormEngine) Select() ([]map[string]string, error) {
//拼接sql
e.Prepare = "select * from " + e.GetTable()
//如果where不为空
if e.WhereParam != "" || e.OrWhereParam != "" {
e.Prepare += " where " + e.WhereParam + e.OrWhereParam
}
e.AllExec = e.WhereExec
//query
rows, err := e.Db.Query(e.Prepare, e.AllExec...)
if err != nil {
return nil, e.setErrorInfo(err)
}
//读出查询出的列字段名
column, err := rows.Columns()
if err != nil {
return nil, e.setErrorInfo(err)
}
//values是每个列的值,这里获取到byte里
values := make([][]byte, len(column))
//因为每次查询出来的列是不定长的,用len(column)定住当次查询的长度
scans := make([]interface{}, len(column))
for i := range values {
scans[i] = &values[i]
}
results := make([]map[string]string, 0)
for rows.Next() {
if err := rows.Scan(scans...); err != nil {
//query.Scan查询出来的不定长值放到scans[i] = &values[i],也就是每行都放在values里
return nil, e.setErrorInfo(err)
}
//每行数据
row := make(map[string]string)
//循环values数据,通过相同的下标,取column里面对应的列名,生成1个新的map
// 这里的valuesz直接写成scans也行
for k, v := range values {
key := column[k]
row[key] = string(v)
}
//添加到map切片中
results = append(results, row)
}
return results, nil
}
这样,我们就能非常方便的查询数据了,但是这个方法,有2个小的影响的地方:
最后返回的map切片,里面的key名都是数据库的字段名(可能都是小字母头),如果要映射成首字母大写的结构,需要我们自己去写方法。
他会把数据库表的所有字段的类型都会转换成字符串类型的,理论上影响也不大。
查询单条SelectOne(),返回值为map
有了上面查询多条的理论知识基础,查询单条就变得异常简单了,只需要在最后执行sql的部分加个limit 1即可,并且在返回的map切片中,取第0个数据即可。
//查询1条
func (e *SmallormEngine) SelectOne() (map[string]string, error) {
//limit 1 单个查询
results, err := e.Limit(1).Select()
if err != nil {
return nil, e.setErrorInfo(err)
}
//判断是否为空
if len(results) == 0 {
return nil, nil
} else {
return results[0], nil
}
}
Limit()方法的作用就是在sql最后面拼接上limit 1,这个在下面的篇章会详细说。这样,我们就可以通过SelectOne方法获取单条map数据了。
这样,我们就可以很方便的查询单条数据了:
result, err := e.Table("userinfo").Where("status", 1).SelectOne()
返回为:
//type:
map[string]string
//value:
map[departname:v status:1 uid:123 username:yang]
查询多条Find(),返回值为引用结构体切片
这个方法其实是对原生go查询的一个简单包装,毕竟还是有很多人是喜欢先定义好数据结构,然后通过引用赋值的,当然在大分部的go的ORM里面,也是这么实现查询操作的。
//定义好结构体
type User struct {
Uid int `sql:"uid,auto_increment"`
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
//实例化切片
var user1 []User
// select * from userinfo where status=1
err := e.Table("userinfo").Where("status", 2).Find(&user1)
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Printf("%#v", user1)
}
看下打印的数据
[]smallorm.User{smallorm.User2{Uid:131733, Username:"EE2", Departname:"223", Status:2},
smallorm.User{Uid:131734, Username:"EE2", Departname:"223", Status:2},
smallorm.User{Uid:131735, Username:"EE2", Departname:"223", Status:2}}
我们先在脑海中理一下大致的一个调用和逻辑处理过程:
-
先定义一个结构体,里面的字段通过
tag标签和表的字段进行关联 -
初始化
1个空的结构体切片,然后通过&取地址符传给Find()方法 -
Find()方法内部先获取到表的列名,再通过tag关联和各种反射利器,将数据绑定到传入的结构体切片上,给它附上值。
这么看来,第3步是最复杂的,它需要获取传入的结构体切片里面的每一个值,并且还得把查询出来的结果给它全部赋上,天,感觉好难啊!!!这题不会做啊。
后来在我大量翻阅GORM的源码以及查看go反射的文档后,我渐渐的有了头绪,这题也太简单了吧!
首先,还是和Select方法一样,我们需要解析出表的各个字段名,因为这个需要和tag:sql:“xx”一一对应上的。
//读出查询出的列字段名
column, err := rows.Columns()
if err != nil {
return e.setErrorInfo(err)
}
//values是每个列的值,这里获取到byte里
values := make([][]byte, len(column))
//因为每次查询出来的列是不定长的,用len(column)定住当次查询的长度
scans := make([]interface{}, len(column))
for i := range values {
scans[i] = &values[i]
}
上面的这几步是一样的,最后的数据赋值到values里面去了,就不过多赘述了,下面是最关键的一步来了:
//原始struct的切片值
destSlice := reflect.ValueOf(result).Elem()
//原始单个struct的类型
destType := destSlice.Type().Elem()
我们通过这2个神奇(变态)的go反射方法,就可以得出传入的User结构体切片它的类型是什么,它的值是什么。打印下看看:
fmt.Printf("%+v\n", destSlice)
fmt.Printf("%+v", destType)
[]
main.User
ok,我们就成功解析出了传入的结构体是长啥样的了,然后就可以再根据一系列for循环和各种神奇的go反射方法来继续:
destType.NumField(); //获取到User结构体的字段数,这里返回:4
destType.Field(i).Tag.Get("sql") //获取到User结构体的第i个字段的tag值,比如返回:`username`
destType.Field(i).Name // //获取到User结构体的第i个字段的名字,比如返回:`Username`
再通过这几个反射给赋值:
dest := reflect.New(destType).Elem() // 根据类型生成1个新的值,返回:{Uid:0 Username: Departname: Status:0}
dest.Field(i).SetString(value) //给第i个元素,附值,类型是string类型
reflect.Append(destSlice, dest) // 将dest值添加到destSlice切片中。
destSlice.Set(reflect.Append(destSlice, dest)) //将最后得到的切片完全赋值给本身。
或许这一顿反射操作已经把你搞晕了,说实话,我也晕了。现在看下完整的函数:
//查询多条,返回值为struct切片
func (e *SmallormEngine) Find(result interface{}) error {
if reflect.ValueOf(result).Kind() != reflect.Ptr {
return e.setErrorInfo(errors.New("参数请传指针变量!"))
}
if reflect.ValueOf(result).IsNil() {
return e.setErrorInfo(errors.New("参数不能是空指针!"))
}
//拼接sql
e.Prepare = "select * from " + e.GetTable()
e.AllExec = e.WhereExec
//query
rows, err := e.Db.Query(e.Prepare, e.AllExec...)
if err != nil {
return e.setErrorInfo(err)
}
//读出查询出的列字段名
column, err := rows.Columns()
if err != nil {
return e.setErrorInfo(err)
}
//values是每个列的值,这里获取到byte里
values := make([][]byte, len(column))
//因为每次查询出来的列是不定长的,用len(column)定住当次查询的长度
scans := make([]interface{}, len(column))
//原始struct的切片值
destSlice := reflect.ValueOf(result).Elem()
//原始单个struct的类型
destType := destSlice.Type().Elem()
for i := range values {
scans[i] = &values[i]
}
//循环遍历
for rows.Next() {
dest := reflect.New(destType).Elem()
if err := rows.Scan(scans...); err != nil {
//query.Scan查询出来的不定长值放到scans[i] = &values[i],也就是每行都放在values里
return e.setErrorInfo(err)
}
//遍历一行数据的各个字段
for k, v := range values {
//每行数据是放在values里面,现在把它挪到row里
key := column[k]
value := string(v)
//遍历结构体
for i := 0; i < destType.NumField(); i++ {
//看下是否有sql别名
sqlTag := destType.Field(i).Tag.Get("sql")
var fieldName string
if sqlTag != "" {
fieldName = strings.Split(sqlTag, ",")[0]
} else {
fieldName = destType.Field(i).Name
}
//struct里没这个key
if key != fieldName {
continue
}
//反射赋值
if err := e.reflectSet(dest, i, value); err != nil {
return err
}
}
}
//赋值
destSlice.Set(reflect.Append(destSlice, dest))
}
return nil
}
我们在方法前面加了几个参数校验,也是基于反射的,来判断传进来的值是指针类型的才行。在反射赋值里,我搞了个通用的方法reflectSet来进行字段类型的匹配。将查询出来的结果集里面的各个字段的类型枚举遍历出来,去转换成实际结构体里面的类型。是因为go里面是严格区分字段类型的,所以反射赋值的时候,也得根据结构体里面具体字段的类型来分别赋值。
//反射赋值
func (e *SmallormEngine) reflectSet(dest reflect.Value, i int, value string) error {
switch dest.Field(i).Kind() {
case reflect.Int, reflect.Int8, reflect.Int16, reflect.Int32, reflect.Int64:
res, err := strconv.ParseInt(value, 10, 64)
if err != nil {
return e.setErrorInfo(err)
}
dest.Field(i).SetInt(res)
case reflect.String:
dest.Field(i).SetString(value)
case reflect.Uint, reflect.Uint8, reflect.Uint16, reflect.Uint32, reflect.Uint64:
res, err := strconv.ParseUint(value, 10, 64)
if err != nil {
return e.setErrorInfo(err)
}
dest.Field(i).SetUint(res)
case reflect.Float32:
res, err := strconv.ParseFloat(value, 32)
if err != nil {
return e.setErrorInfo(err)
}
dest.Field(i).SetFloat(res)
case reflect.Float64:
res, err := strconv.ParseFloat(value, 64)
if err != nil {
return e.setErrorInfo(err)
}
dest.Field(i).SetFloat(res)
case reflect.Bool:
res, err := strconv.ParseBool(value)
if err != nil {
return e.setErrorInfo(err)
}
dest.Field(i).SetBool(res)
}
return nil
}
通过switch dest.Field(i).Kind() case来一一匹配结构体里的字段是啥类型,再通过strconv.xxx()将数据库查到的数据类型转换好对应的类型,再去SetXXX()。
查询单条FindOne(),返回值为引用结构体
多条的逻辑被解决了,单条就很简单了,2步搞定:第一步设置Limit 1,第二步返回结构体的第0个数据。
//查询单条,返回值为struct切片
func (e *SmallormEngine) FindOne(result interface{}) error {
//取的原始值
dest := reflect.Indirect(reflect.ValueOf(result))
//new一个类型的切片
destSlice := reflect.New(reflect.SliceOf(dest.Type())).Elem()
//调用
if err := e.Limit(1).Find(destSlice.Addr().Interface()); err != nil {
return err
}
//判断返回值长度
if destSlice.Len() == 0 {
return e.setErrorInfo(errors.New("NOT FOUND"))
}
//取切片里的第0个数据,并复制给原始值结构体指针
dest.Set(destSlice.Index(0))
return nil
}
然而实际的过程却比我们预想的多了好几步,而且又是一坨反射逻辑。我们先仔细品一下Find()方法的参数,他是一个指向切片的指针,也就是说原始值是一个切片数组。而我们本次的方法FindOne()传入的是一个结构体指针,是单个数据,并不是数组切片。这就麻烦了,因为数据类型不匹配,是无法传递的。那咋办呢?
万能的反射肯定是办法的,然后我又通过翻阅无数的文档和手册,终于找到了解决之法:我根据传入进来的单个结构体数据,通过反射,动态生成1个切片数组参数传给Find()不就可以了么?
OK,我们调用试一下:
//定义好结构体
type User struct {
Uid int `sql:"uid,auto_increment"`
Username string `sql:"username"`
Departname string `sql:"departname"`
Status int64 `sql:"status"`
}
//实例化数据
var user1 User
// select * from userinfo where status=1
err := e.Table("userinfo").Where("status", 2).FindOne(&user1)
if err != nil {
fmt.Println(err.Error())
} else {
fmt.Printf("%#v", user1)
}
看下打印的数据
smallorm.User{Uid:131733, Username:"EE2", Departname:"223", Status:2}
9、设置查询字段Field
设置查询字段是一个很基础其实也很重要的功能,因为我们平时查询数据的时候,都喜欢用select*,他会把表的所有字段都读出来,有大量数据的场景下,其实是很低效和浪费的。本次ORM也通过了这个方法,来指定本次查询字段,可以这样调用:
e.Table("userinfo").Where("status", 2).Field("uid,status").Select()
由于是采用链式的调用方式,而且它本身也没有数据属性,所以是可以放在中间部分的任何位置的:
e.Table("userinfo").Field("uid,status").Where("status", 2).Select()
实现逻辑也很简单,给SmallormEngine的FieldParam赋值就可以了:
//设置查询字段
func (e *SmallormEngine) Field(field string) *SmallormEngine {
e.FieldParam = field
return e
}
然后,我们就在查询的相关方法Select/Find里,就可以这样拼接sql:
e.Prepare = "select " + e.FieldParam + " from " + e.GetTable()
e.FieldParam的初始值是“*”,这个是在NewMysql里面初始化的。所以即使没调用Field()进行设置,Prepare的值也是select*,也是不影响逻辑的完整性。
值得注意的是,我们是直接裸传的,并没有对传入的字段做检验和判断,这个优化将在第二版本中展开
10、设置大小Limit
设置Limit一般我们用来控制获取的数据量的大小,一般用于查询单条,比如:limit 1。更多的时候是用于分页的,比如,每一页取10个,第一页就是:limit 0,9,第二页就是:limit 10,19,所以limit有2种用法。所以我们ORM设置的参数也得是2个,比如这样:
e.Table("userinfo").Where("status", 2).Limit(1).Select()
e.Table("userinfo").Where("status", 2).Limit(0, 9).Select()
我们来看下怎么实现这2种方式的调用:
//limit分页
func (e *SmallormEngine) Limit(limit ...int64) *SmallormEngine {
if len(limit) == 1 {
e.LimitParam = strconv.Itoa(int(limit[0]))
} else if len(limit) == 2 {
e.LimitParam = strconv.Itoa(int(limit[0])) + "," + strconv.Itoa(int(limit[1]))
} else {
panic("参数个数错误")
}
return e
}
我们在参数上使用了可变的参数方式,这样就可以实现传1个或者2个方式,同时通过判断参数的长度,限制了参数要么是1个,要么是2个,不然就报错。然后将分隔后的参数传给LimitParamb变量,这样我们在Find/Select时候就可以判断这个变量是否为空,来给sql增加limit参数了:
//limit不为空
if e.LimitParam != "" {
e.Prepare += " limit " + e.LimitParam
}
这样我们就往prepare 中增加好了limit的语句。
11、聚合查询Count/Max/Min/Avg/Sum
-
Count()//获取总数 -
Max()//获取最大值 -
Min()//获取最小值 -
Avg()//获取平均值 -
Sum()//获取总和
聚合查询,我们平时用的蛮多的,其实他们实现的方式在SQL拼接上来看是很类似的,都是将原先select*换成select Xxxx(*),其次,他们生成的数据都是只有一条数据。所以我们就可以使用之前在查询时,没用上的db.QueryRow()方法了,因为这个方法就是用来查询一条,不需要各种for循环,刚好符合我们这类方法的结果的查询。
我们来看下怎么写,首先第一步,设置2个参数,分别对应于具体的聚合函数,以及需要聚合的字段名。
name对应于具体的聚合函数,param则对应于具体的字段:
func (e *SmallormEngine) aggregateQuery(name, param string) (interface{}, error) {
e.Prepare = "select " + name + "(" + param + ") as cnt from " + e.GetTable()
}
这样,我们这个通用方法的主体给完成了,我们想实现对应的聚合查询功能,只需要传递2个参数即可。接下来,我们看下查询部分:
//执行绑定
var cnt interface{}
//queryRows
err := e.Db.QueryRow(e.Prepare, e.AllExec...).Scan(&cnt)
if err != nil {
return nil, e.setErrorInfo(err)
}
我们申明了1个接口类型的变量cnt用它来获取到最终的聚合结果值,之所以用接口类型,是因为聚合的结果类型是不确定的,可能有小数,也可能是浮点型的,比如求平均值。下面是完整的代码:
//聚合查询
func (e *SmallormEngine) aggregateQuery(name, param string) (interface{}, error) {
//拼接sql
e.Prepare = "select " + name + "(" + param + ") as cnt from " + e.GetTable()
//如果where不为空
if e.WhereParam != "" || e.OrWhereParam != "" {
e.Prepare += " where " + e.WhereParam + e.OrWhereParam
}
//limit不为空
if e.LimitParam != "" {
e.Prepare += " limit " + e.LimitParam
}
e.AllExec = e.WhereExec
//生成sql
e.generateSql()
//执行绑定
var cnt interface{}
//queryRows
err := e.Db.QueryRow(e.Prepare, e.AllExec...).Scan(&cnt)
if err != nil {
return nil, e.setErrorInfo(err)
}
return cnt, err
}
OK,这样,我们就完成了聚合函数的通用主体部分,接下来就是各自的差异部分了。
获取总数Count
可以用Count()方法来获取总数, 返回总数的类型是Int64,它是链式结构最后一次操作。第一个参数我们传count,因为一般取总数,一般用count()或者count(1),所以第二个参数,这个地方,我们用*。
//总数
func (e *SmallormEngine) Count() (int64, error) {
count, err := e.aggregateQuery("count", "*")
if err != nil {
return 0, e.setErrorInfo(err)
}
return count.(int64), err
}
最后的返回值,我们用到了count.(xxx) 这种断言方法来转换格式。
获取最大值Max
可以用Max()方法来获取某一个字段的最大值, 返回总数的类型是string类型,它是链式结构最后一次操作。第一个参数我们传max,第二个参数传某一个表字段。
//最大值
func (e *SmallormEngine) Max(param string) (string, error) {
max, err := e.aggregateQuery("max", param)
if err != nil {
return "0", e.setErrorInfo(err)
}
return string(max.([]byte)), nil
}
之所以返回值用string类型,是因为取最大值,有时候不限制在int类型的表字段取最大值,有时候也会有时间最大值等,所以返回string是最合适的。
获取最小值Min
可以用Min()方法来获取某一个字段的最小值, 返回总数的类型是string类型, 它是链式结构最后一次操作。第一个参数我们传min,第二个参数传某一个表字段。
//最小值
func (e *SmallormEngine) Min(param string) (string, error) {
min, err := e.aggregateQuery("min", param)
if err != nil {
return "0", e.setErrorInfo(err)
}
return string(min.([]byte)), nil
}
获取平均值Avg
可以用Avg()方法来获取某一个字段的平均值, 返回总数的类型是string类型, 它是链式结构最后一次操作。第一个参数我们传avg,第二个参数传某一个表字段。
//平均值
func (e *SmallormEngine) Avg(param string) (string, error) {
avg, err := e.aggregateQuery("avg", param)
if err != nil {
return "0", e.setErrorInfo(err)
}
return string(avg.([]byte)), nil
}
获取总和Sum
可以用Sum()方法来获取某一个字段的总和, 返回总数的类型是string类型,它是链式结构最后一次操作。第一个参数我们传sum,第二个参数传某一个表字段。
//总和
func (e *SmallormEngine) Sum(param string) (string, error) {
sum, err := e.aggregateQuery("sum", param)
if err != nil {
return "0", e.setErrorInfo(err)
}
return string(sum.([]byte)), nil
}
接下来,来快速的调用看看:
//select count(*) as cnt from userinfo where (uid >= 10805)
cnt, err := e.Table("userinfo").Where("uid", ">=", 10805).Count()
//select max(uid) as cnt from userinfo where (uid >= 10805)
max, err := e.Table("userinfo").Where("uid", ">=", 10805).Max('uid')
//select min(uid) as cnt from userinfo where (uid >= 10805)
min, err := e.Table("userinfo").Where("uid", ">=", 10805).Count()
//select avg(uid) as cnt from userinfo where (uid >= 10805)
avg, err := e.Table("userinfo").Where("uid", ">=", 10805).Avg("uid")
// select sum(uid) as cnt from userinfo where (uid >= 10805)
sum, err := e.Table("userinfo").Where("uid", ">=", 10805).Sum("uid")
12、排序Order
排序也是平常sql语句中用的是最多的,它用于查询结果的展示按照某个字段排序,正序(从小到大)用asc,倒序(从大到小)用desc,写法如下:
//查询结果按照uid倒序
select * from userinfo where (uid >= 10805) order by uid desc
//查询结果按照uid正序
select * from userinfo where (uid >= 10805) order by uid asc
//查询结果,先按照uid正序,再按照status倒序
select * from userinfo where (uid >= 10805) order by uid asc,status desc
所以,我们也把这个操作,用一个单独的方法给暴露出来,方便排序,调用方式如下:
sum, err := e.Table("userinfo").Where("uid", ">=", 10805).Order("uid", "desc").Select()
sum, err := e.Table("userinfo").Where("uid", ">=", 10805).Order("uid","asc", "status", "desc").Select()
看这个参数的个数,我们立马就知道了,这个方法又是一个可变参数的,这个方法写起来思路其实也很清晰,我们只需要把传入的参数,变成order xxx xxx,xx,xx后面的xx数据即可,然后存放到e.OrderParam这个变量中,等Find/Select查询的时候直接判断拼接即可。
看下,具体是怎么实现的:
//order排序
func (e *SmallormEngine) Order(order ...string) *SmallormEngine {
orderLen := len(order)
if orderLen%2 != 0 {
panic("order by参数错误,请保证个数为偶数个")
}
//排序的个数
orderNum := orderLen / 2
//多次调用的情况
if e.OrderParam != "" {
e.OrderParam += ","
}
for i := 0; i < orderNum; i++ {
keyString := strings.ToLower(order[i*2+1])
if keyString != "desc" && keyString != "asc" {
panic("排序关键字为:desc和asc")
}
if i < orderNum-1 {
e.OrderParam += order[i*2] + " " + order[i*2+1] + ","
} else {
e.OrderParam += order[i*2] + " " + order[i*2+1]
}
}
return e
}
唯一复杂的地方,就是判断参数是偶数个数的,然后,按照二分查找法,进行多个排序规则的拼接,这个地方也是有其他的算法进行拼接。
然后,在Find/Select查询的时候就可以判断一下,追加到e.Prepare里:
//order by不为空
if e.OrderParam != "" {
e.Prepare += " order by " + e.OrderParam
}
13、分组Group
分组也是我们平时用的非常多的,它用于我们对某1个或者几个字段进行分组,然后查询这个分组后的数据,写法很简单,直接上代码:
//group分组
func (e *SmallormEngine) Group(group ...string) *SmallormEngine {
if len(group) != 0 {
e.GroupParam = strings.Join(group, ",")
}
return e
}
参数也是可变的,因为我们可以对多个字段进行group的。有时候,可以需要搭配Field(count(*) as c)来实现更加细的分组查询
result,err := e.Table("userinfo").Where("departname", "like", "2%").Field("departname, count(*) as c").Group("departname", "status").Select()
这样,我们就可以在Find/Select查询的时候就可以判断一下,追加到e.Prepare里:
//group 不为空
if e.GroupParam != "" {
e.Prepare += " group by " + e.GroupParam
}
14、分组后判断Having
Having用于在使用Group分组后的过滤查询,它的作用和where其实是一模一样的,都是过滤,只不过Having只能用于group之后,对select后面的参数进行过滤,比如这个sql:
我们想查询出按照status分组后,uid的总数大于5的数据:
select status, count(uid) as c from userinfo where (uid >= 10805) group by status having c >= 5
所以,既然绑定的方式和where是一模一样的,我们可以看下怎么调用的:
result,err := e.Table("userinfo").Where("", "like", "2%").Field("status, count(uid) as c ").Group(status").Having("c",">=", 5).Select()
result,err := e.Table("userinfo").Where("departname", "like", "2%").Field("status, count(uid) as c ").Group(status").Having("c", 5).Select()
type User struct {
Status int64 `sql:"status"`
}
user2 := User1{
Status: 1,
}
result,err := e.Table("userinfo").Where("departname", "like", "2%").Field("status, count(uid) as c ").Group(status").Having(user2).Select()
由于和Where方法实现的方式几乎一样,我们直接快速的看下这个方法的实现过程吧:
//having过滤
func (e *SmallormEngine) Having(having ...interface{}) *SmallormEngine {
//判断是结构体还是多个字符串
var dataType int
if len(having) == 1 {
dataType = 1
} else if len(having) == 2 {
dataType = 2
} else if len(having) == 3 {
dataType = 3
} else {
panic("having个数错误")
}
//多次调用判断
if e.HavingParam != "" {
e.HavingParam += "and ("
} else {
e.HavingParam += "("
}
//如果是结构体
if dataType == 1 {
t := reflect.TypeOf(having[0])
v := reflect.ValueOf(having[0])
var fieldNameArray []string
for i := 0; i < t.NumField(); i++ {
//小写开头,无法反射,跳过
if !v.Field(i).CanInterface() {
continue`在这里插入代码片`
}
//解析tag,找出真实的sql字段名
sqlTag := t.Field(i).Tag.Get("sql")
if sqlTag != "" {
fieldNameArray = append(fieldNameArray, strings.Split(sqlTag, ",")[0]+"=?")
} else {
fieldNameArray = append(fieldNameArray, t.Field(i).Name+"=?")
}
e.WhereExec = append(e.WhereExec, v.Field(i).Interface())
}
e.HavingParam += strings.Join(fieldNameArray, " and ") + ") "
} else if dataType == 2 {
//直接=的情况
e.HavingParam += having[0].(string) + "=?) "
e.WhereExec = append(e.WhereExec, having[1])
} else if dataType == 3 {
//3个参数的情况
e.HavingParam += having[0].(string) + " " + having[1].(string) + " ?) "
e.WhereExec = append(e.WhereExec, having[2])
}
return e
}
专门弄了一个HavingParam来存储占位符,而数值的部分,依然是存放在WhereExec中。
然后,和其他一样,在Find/Select查询的时候就可以判断一下,追加到e.Prepare里:
//having
if e.HavingParam != "" {
e.Prepare += " having " + e.HavingParam
}
OK,我们来试一下怎么调用:
//select uid, status, count(uid) as b from userinfo where (departname like '2%') group by uid,status having (status=1) order by uid desc,status asc
result,err := e.Table("userinfo").Where("departname", "like", "2%").Order("uid", "desc", "status", "asc").Field("uid, status, count(uid) as b").Group("uid", "status").Having("status",1).Select()
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println("result is :", result)
15、获取执行生成的完整SQLGetLastSql
我们上面的所有的方法,其实本质上都是组装成原生sql语法的拼装,有时候,我们其实是想知道最后生成的sql到底是啥,或者查询报错了,想看下最后生成的sql是否有语法错误,我们ORM也提供了这个方法,用于查询本次执行最后生成的sql语句。
实现方式其实很简单,因为我们已经把sql语句的前半部分e.Prepare已经生成好了,我们只需要用具体的数值部分e.AllExec去替换e.Prepare里面的问号占位符即可,因为我们当时数据匹配的时候,也是按照顺序转换成占位符,所以,这次相当于逆向的生成sql。
//生成完成的sql语句
func (e *SmallormEngine) generateSql() {
e.Sql = e.Prepare
for _, i2 := range e.AllExec {
switch i2.(type) {
case int:
e.Sql = strings.Replace(e.Sql, "?", strconv.Itoa(i2.(int)), 1)
case int64:
e.Sql = strings.Replace(e.Sql, "?", strconv.FormatInt(i2.(int64), 10), 1)
case bool:
e.Sql = strings.Replace(e.Sql, "?", strconv.FormatBool(i2.(bool)), 1)
default:
e.Sql = strings.Replace(e.Sql, "?", "'"+i2.(string)+"'", 1)
}
}
}
这个替换做的比较简陋,只对基础的int和bool型做了类型转换,其他类型都当做sql里的字符串处理,需要加单引号。
然后,我们在链式调用的最后一步执行sql的相关方法里,去调用这个方法。就可以将最终的sql语句生成,并存放到e.Sql属性里。调用GetLastSql就可以打印出最后生成的sql语句了。
//获取最后执行生成的sql
func (e *SmallormEngine) GetLastSql() string {
return e.Sql
}
值得注意的是,这个是打印最后一次生成的sql,如果你有多次CURD操作,记得每次去调用:
sum, err := e.Table("userinfo").Where("uid", ">=", 10805).Order("uid", "desc").Select()
fmt.Println(e.GetLastSql()) //select * from userinfo where (uid >= 10805) order by uid asc
sum, err := e.Table("userinfo").Where("uid", ">=", 10805).Order("uid","asc", "status", "desc").Select()
fmt.Println(e.GetLastSql()) //select * from userinfo where (uid >= 10805) order by uid asc,status desc
16、执行原生SQLExec/Query
本次ORM也提供了裸调sql的方法,虽然不是推荐使用,但是有时候确实是有这样的需求的使用场景的。
执行原生sql的增删改操作Exec
go原生的sql代码,提供了Exec方法,用于增删改的操作,也就是本文开头的原生demo中的第一种方式:
result, err := db.Exec("INSERT INTO userinfo (username, departname, created) VALUES (?, ?, ?)","lisi","dev","2020-08-04")
其实,你是可以不传后面的几个参数,不使用问号占位符的,第一个参数直接传完整的sql即可,像这样:
result, err := db.Exec("INSERT INTO userinfo (username, departname, created) VALUES ('lisi', 'dev', '2021-11-04')")
所以,我们本次ORM就利用了这个特性,简单的封装,变成了Exec方法,代码如下:
//直接执行增删改sql
func (e *SmallormEngine) Exec(sql string) (id int64, err error) {
result, err := e.Db.Exec(sql)
e.Sql = sql
if err != nil {
return 0, e.setErrorInfo(err)
}
//区分是insert还是其他(update,delete)
if strings.Contains(sql, "insert") {
lastInsertId, _ := result.LastInsertId()
return lastInsertId, nil
} else {
rowsAffected, _ := result.RowsAffected()
return rowsAffected, nil
}
}
我们通过判断sql是的语句是新增还是其他,因为新增的话一般情况是要返回自增ID的,而其他情况需要返回影响的行数。这样,我们就可以很方便的调用原生的sql语句了:
//result, err:= e.Exec("insert into userinfo(username,departname,created,status) values('dd', '31','2020-10-02',1)");
//result, err := e.Exec("delete from userinfo where username='dd'")
result, err := e.Exec("update userinfo set username='dd' where uid = 132733")
fmt.Println(err)
fmt.Println(result)
fmt.Println(e.GetLastSql())
执行原生sql的查询操作Query
原生go代码里面的Query方法用于查询的操作,他同样也是支持直接传原生的sql语句,而不需要使用占位符的:
result, err := db.Query("SELECT * FROM userinfo limit 1")
所以,我们只需要把ORM里面的Select方法,稍作改造即可,因为后半部分的数据获取是一模一样的:
//直接执行查sql
func (e *SmallormEngine) Query(sql string) ([]map[string]string, error) {
rows, err := e.Db.Query(sql)
e.Sql = sql
if err != nil {
return nil, e.setErrorInfo(err)
}
//读出查询出的列字段名
column, err := rows.Columns()
if err != nil {
return nil, e.setErrorInfo(err)
}
//values是每个列的值,这里获取到byte里
values := make([][]byte, len(column))
//因为每次查询出来的列是不定长的,用len(column)定住当次查询的长度
scans := make([]interface{}, len(column))
for i := range values {
scans[i] = &values[i]
}
//最后得到的map
results := make([]map[string]string, 0)
for rows.Next() {
if err := rows.Scan(scans...); err != nil {
//query.Scan查询出来的不定长值放到scans[i] = &values[i],也就是每行都放在values里
return nil, e.setErrorInfo(err)
}
row := make(map[string]string) //每行数据
for k, v := range values {
//每行数据是放在values里面,现在把它挪到row里
key := column[k]
row[key] = string(v)
}
results = append(results, row)
}
return results, nil
}
OK,我们就可以这样调用了:
result, err := e.Query("SELECT * FROM userinfo limit 1")
fmt.Println(err)
fmt.Println(result)
fmt.Println(e.GetLastSql())
17、事务Begin/Commit/Rollback
sql里的事务操作也是平时业务中用的非常多的,它用于在多次执行增删改的操作的时候,如果其中1个出现问题,可以一起回滚数据,确保了数据的一致性。本ORM也提供了相应的方法。事务也是通过封装来调用原生go代码里面的事务方法。一共有3个方法配合调用:
-
Begin()//开启事物 -
Rollback()//回滚 -
Commit()//确认提交执行
开启事务Begin
开启事务功能相对简单,只是设置一个标志符即可:
//开启事务
func (e *SmallormEngine) Begin() error {
//调用原生的开启事务方法
tx, err := e.Db.Begin()
if err != nil {
return e.setErrorInfo(err)
}
e.TransStatus = 1
e.Tx = tx
return nil
}
在这个方法里,我们调用了原生的Db.Begin()方法,得到了1个tx资源柄,它专门用于执行事务的操作,并且用e.TransStatus=1来标记已经开启了事务操作。
接下来,我们在具体的增删改查的方法里,通过这个标记去判断现在是不是事务状态:
//判断是否是事务
var stmt *sql.Stmt
var err error
if e.TransStatus == 1 {
stmt, err = e.Tx.Prepare(e.Prepare)
} else {
stmt, err = e.Db.Prepare(e.Prepare)
}
...
result, err := stmt.Exec(e.AllExec...)
可以看到,判断非常简单,因为不管是不是事务,最后生成的stmt变量类型是不变的,所以后半段的操作不需要改变。这样我们很方便的开启了事务的功能。
回滚Rollback
回滚操作表示我们执行出现了问题后,向mysql服务器提供回滚指令,它会将这句sql执行的结果给还原。实现原来更简单了,直接调用原生的即可:
//事务回滚
func (e *SmallormEngine) Rollback() error {
e.TransStatus = 0
return e.Tx.Rollback()
}
确认提交Commit
确认提交表示我们所有的执行都是OK的,这个时候我们需要向mysql服务器发出确认提交指令,它才会真正意义上将sql给执行。如果不执行这个指令,实际上数据并不会执行,所以,我们最后一定不要忘记执行确认提交操作。实现原来也很简单了,直接调用原生的即可:
//事务提交
func (e *SmallormEngine) Commit() error {
e.TransStatus = 0
return e.Tx.Commit()
}
我们看下一个完整的事务的调用例子:
err0 := e.Begin()
isCommit := true
if err0 != nil {
fmt.Println(err0.Error())
os.Exit(1)
}
result1, err1 := e.Table("userinfo").Where("uid", "=", 10803).Update("departname", 110)
if err1 != nil {
isCommit = false
fmt.Println(err1.Error())
}
//没找到,删除失败
if result1 <= 0 {
isCommit = false
fmt.Println("update 0")
}
fmt.Println("result1 is :", result1)
fmt.Println("sql is :", e.GetLastSql())
result2, err2 := e.Table("userinfo").Where("uid", "=", 10802).Delete()
if err2 != nil {
isCommit = false
fmt.Println(err2.Error())
}
if result2 <= 0 {
isCommit = false
fmt.Println("delete 0")
}
fmt.Println("result2 is :", result2)
fmt.Println("sql is :", e.GetLastSql())
user1 := User{
Username: "EE",
Departname: "22",
Created: "2012-12-12",
Status: 1,
}
id, err3 := e.Table("userinfo").Insert(user1)
if err3 != nil {
isCommit = false
fmt.Println(err3.Error())
}
fmt.Println("id is :", id)
fmt.Println("sql is :", e.GetLastSql())
if isCommit {
_ = e.Commit()
fmt.Println("ok")
} else {
_ = e.Rollback()
fmt.Println("error")
}
我们通过检查每一步的执行结果,任何一个失败,都将isCommit设置为false,最后通过判断这个值的状态来回滚和确认提交。
到此为止,我们把ORM该有的功能基本上实现了90%以上,也算是一个小而美、优雅且简单的ORM框架了。
三、功能测试和性能测试
功能测试必不可少,而且go也给我们提供了很简单就可以完成的测试功能,这个可以逐步完善,我们先看下性能测试,我们和GORM跑个分测试一下。
数据库的结构如下,表里面有209w数据:
CREATE DATABASE `ApiDB`;
USE ApiDB;
CREATE TABLE `userinfo` (
`uid` int NOT NULL AUTO_INCREMENT,
`username` varchar(64) DEFAULT NULL,
`departname` varchar(64) DEFAULT NULL,
`created` date DEFAULT NULL,
`status` int NOT NULL,
PRIMARY KEY (`uid`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4;
写2个简单的跑分测试,测试下Select和Update:
package smallorm
import (
"gorm.io/driver/mysql"
"gorm.io/gorm"
"testing"
)
func BenchmarkSmallormSelect(b *testing.B) {
e, _ := NewMysql("root", "123456", "127.0.0.1:3306", "ApiDB")
type User struct {
Username string `gorm:"username"`
Departname string `gorm:"departname"`
Created string `gorm:"created"`
Status int64 `gorm:"status"`
}
var users[] User
b.ResetTimer()
for i := 0; i < b.N; i++ {
_ = e.Table("userinfo").Where("uid", ">=", 50).Limit(100).Find(&users)
}
b.StopTimer()
}
func BenchmarkGormSelect(b *testing.B) {
dsn := "root:123456@tcp(127.0.0.1:3306)/ApiDB?charset=utf8mb4&parseTime=True&loc=Local"
db, _ := gorm.Open(mysql.Open(dsn), &gorm.Config{})
type User struct {
Username string `gorm:"username"`
Departname string `gorm:"departname"`
Created string `gorm:"created"`
Status int64 `gorm:"status"`
}
var users[] User
b.ResetTimer()
for i := 0; i < b.N; i++ {
db.Table("userinfo").Where("uid >= ?", "50").Limit(50).Find(&users)
}
b.StopTimer()
}
func BenchmarkSmallormUpdate(b *testing.B) {
e, _ := NewMysql("root", "123456", "127.0.0.1:3306", "ApiDB")
b.ResetTimer()
for i := 0; i < b.N; i++ {
_,_ = e.Table("userinfo").Where("uid", "=", 15).Update("status", 0)
}
b.StopTimer()
}
func BenchmarkGormUpdate(b *testing.B) {
dsn := "root:123456@tcp(127.0.0.1:3306)/ApiDB?charset=utf8mb4&parseTime=True&loc=Local"
db, _ := gorm.Open(mysql.Open(dsn), &gorm.Config{})
b.ResetTimer()
for i := 0; i < b.N; i++ {
db.Table("userinfo").Where("uid = ?", "15").Update("status", 1)
}
b.StopTimer()
}
运行下,看下跑分数据:
go test -bench=. -benchmem
goos: darwin
goarch: amd64
pkg: smallorm
cpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz
BenchmarkSmallormSelect-12 1296 843769 ns/op 911 B/op 25 allocs/op
BenchmarkGormSelect-12 598 1998827 ns/op 29250 B/op 1058 allocs/op
BenchmarkSmallormUpdate-12 1197 864404 ns/op 727 B/op 21 allocs/op
BenchmarkGormUpdate-12 314 4216470 ns/op 6246 B/op 76 allocs/op
PASS
ok smallorm 6.880s
这个跑分,大家可以看一下。
四、待实现功能
-
多表联合查询
-
快捷
hash分表 -
日志、性能、结构、安全的优化
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 12-20
- 动态规划python简单例子-斐波那契数列
- C++中什么情况下使用strncpy、memcpy 和 “=” 赋值符号?
- 数据处理大杀器:Python Collections 模块全攻略
- 代码随想录 Leetcode349. 两个数组的交集
- golang并发编程-channel
- linux RCU机制介绍
- 什么是 DDoS ?如何识别DDoS?怎么应对DDOS攻击
- 丰田金融服务公司被勒索800万美元
- 基于YOLOv7算法的高精度实时二维码目标检测识别系统(PyTorch+Pyside6+YOLOv7)