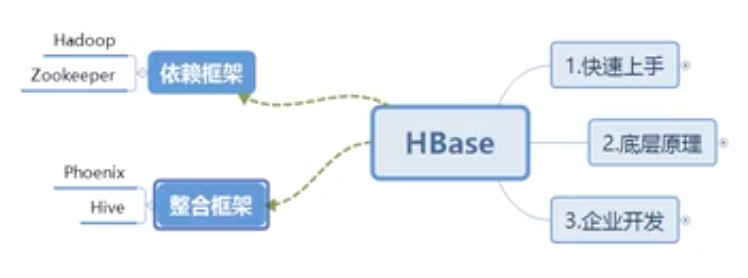
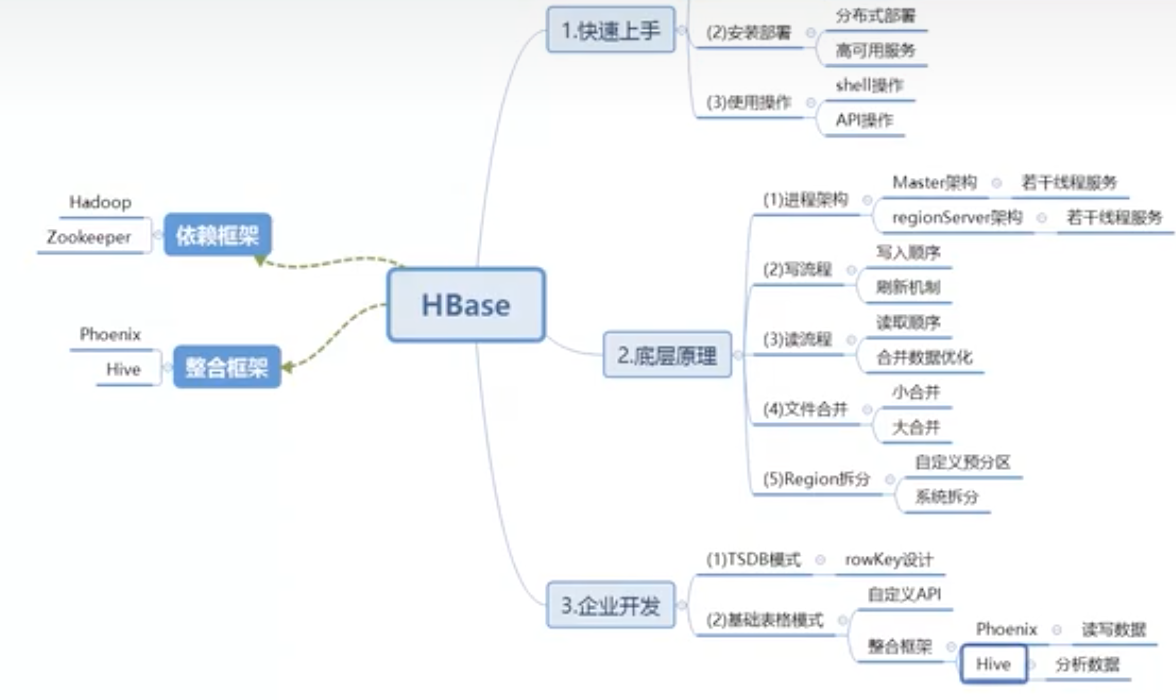
【大数据精讲】HBase基本概念与读写流程
目录
基本概念
Apache HBase – Apache HBase? Home
" This project's goal is the hosting of very large tables -- billions of rows X millions of columns --"
概念
- 海量数据:10亿行、100万列
- 非关系型数据库:kv结构
- 稀疏的:不像关系型数据库表,即使没有数据也要留空
- 分布式的
- 持久的
- 多维的:hashmap是单维度的
- 排序的:排序后可以使用比如二分查找
- map映射:k:v
-
- key:行键、列键和时间戳索引作为key
- value:未解释的字节数组,未解释指即经过序列化的
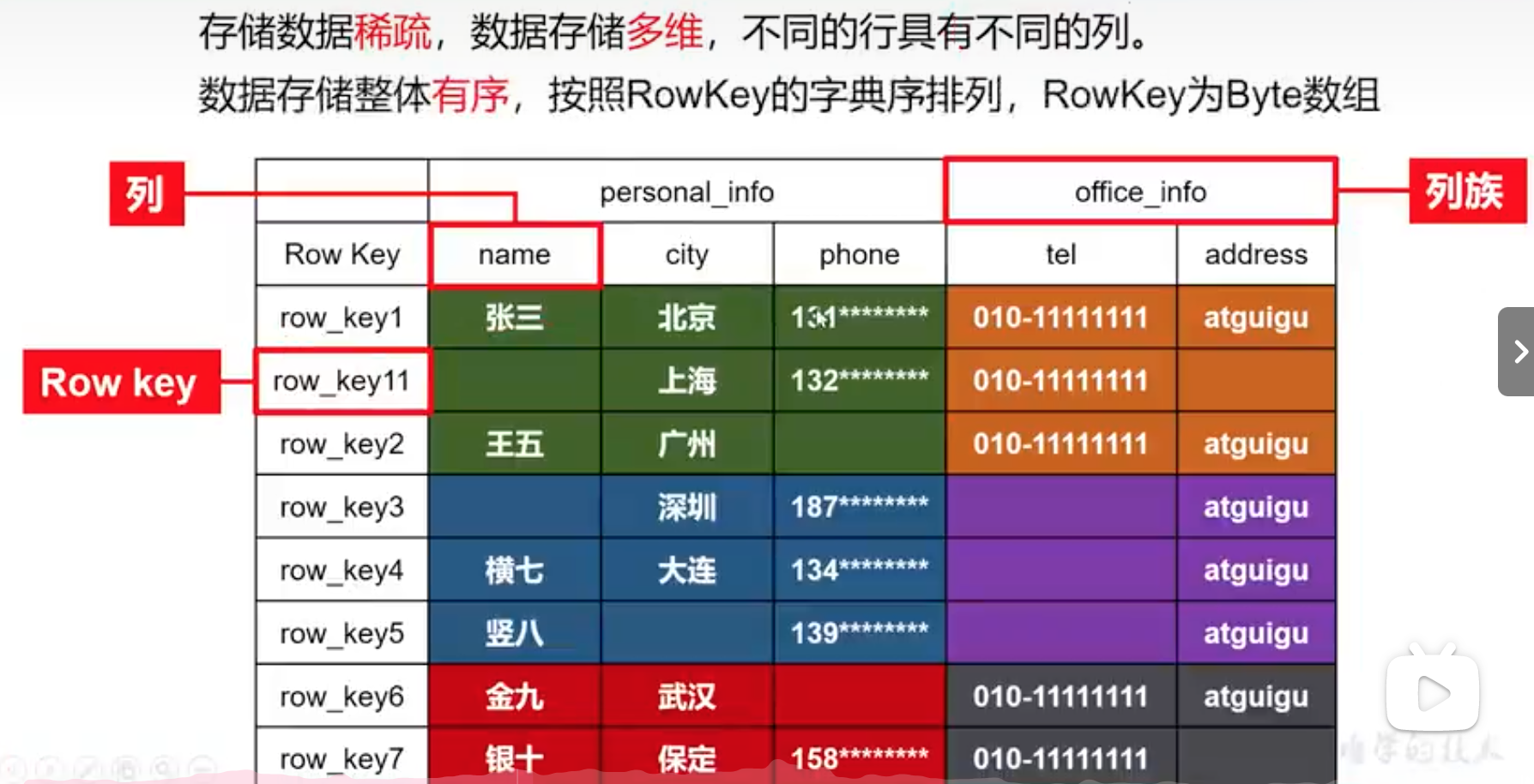
HBase使用与BigTable非常相似的数据模型,用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
数据模型
Name Space命名空间
类似数据库概念,其下有多个表,自带两个:hbase和default
- hbase:系统使用,存放内置表,不要操作
- default:用户默认使用的
Table
hbase在定义表时只需要声明列族即可,不需要声明具体的列。数据存储是稀疏的,可以动态、按需指定,可以轻松应对字段变更
Row
行由RowKey和多个Column组成的,数据是按照RowKey字典顺序存储的,查询时只能按照RowKey进行检索,所以RowKey的设计十分重要。
hbase不能写sql,比如where name=xx不行,没这个功能,只能按rowkey读取,这也是hbase不太好用的原因。
Column
ColumnFamily列族+ColumnQualifier列名组成。
如info:name,info:age
建表时只需要指明列族,而列名无需预先定义。
Time Stamp
用来标记版本
Cell
即k:v模型,key由{rowkey,column family: column qualifier, timestamp}组成来,唯一确定的单元。cell中的数据全部是字节码形式存储。
cell针对的是底层存储StoreFile而言的,指的是底层存储的一行数据,其他是针对表而言的
逻辑结构
json
- 列族:column family
- 列:column
- row key:行号,用来排序和整理数据,特点:一定是按照字典序排序好的,字典序:row_key11在row_key2前面
横向拆分:按行拆分region
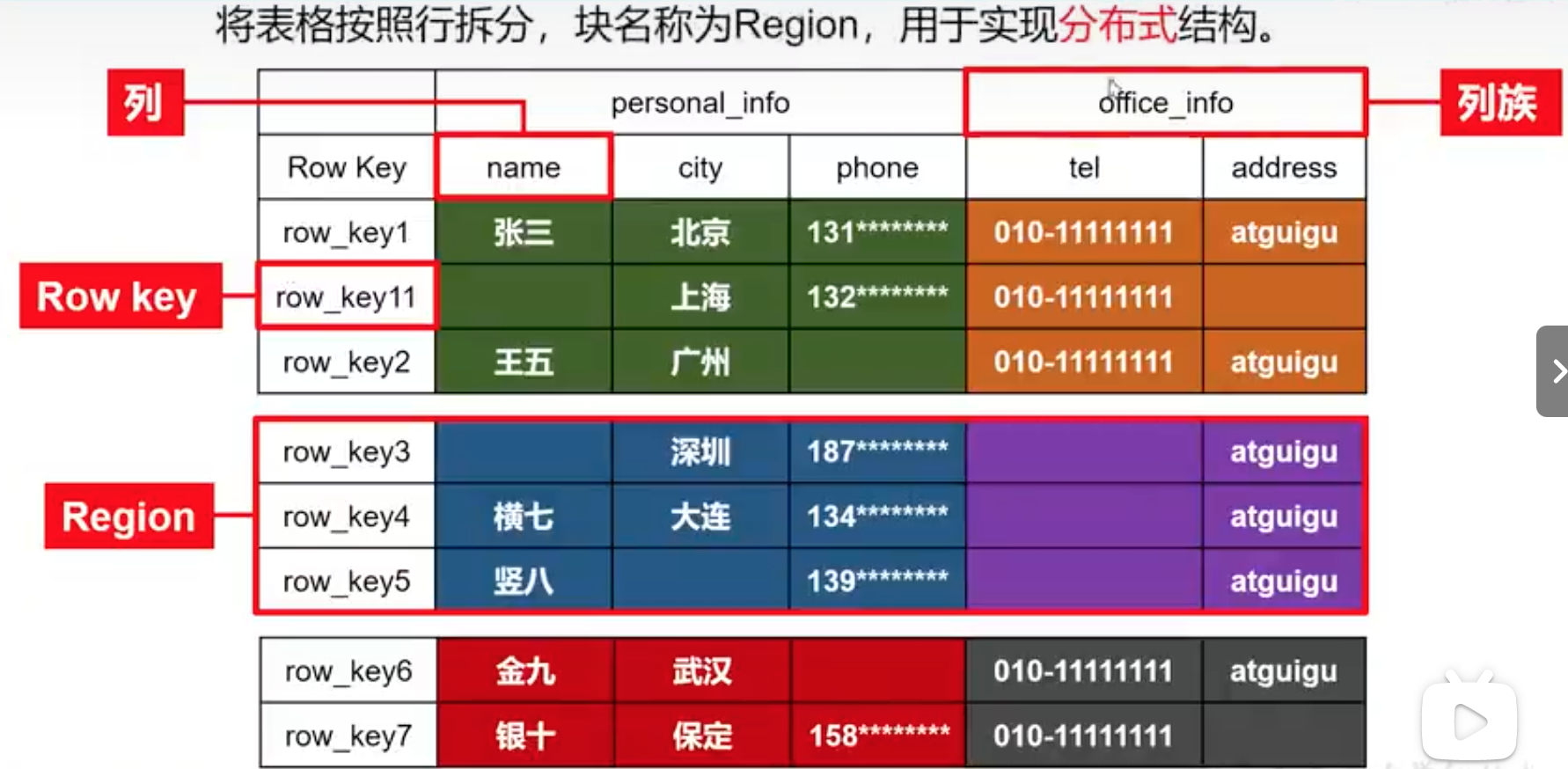
竖向拆分:按列族拆分为store
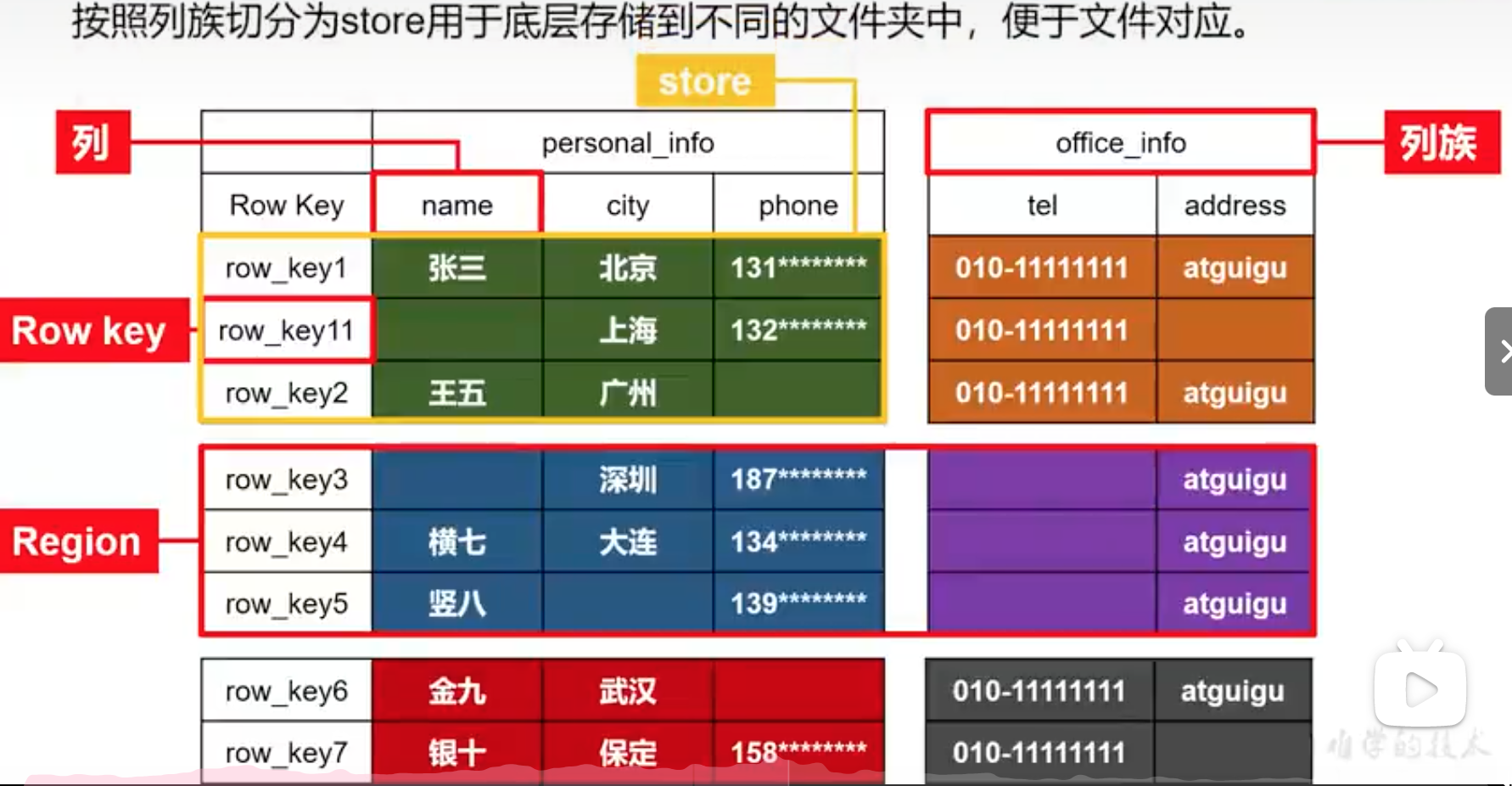
物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储。
- Timestamp
-
- 时间戳用于标记版本
- 不同版本version的数据根据timestamp进行区分,读取数据默认读取最新的版本
- HDFS存储有一个标志性的特点:不能够修改数据
- 在不能改数据的基础上怎么实现改,以时间戳作为版本
- Type:标记,写入Put 删除Delete
-
- 对于删除操作,其类型为DeleteColumn

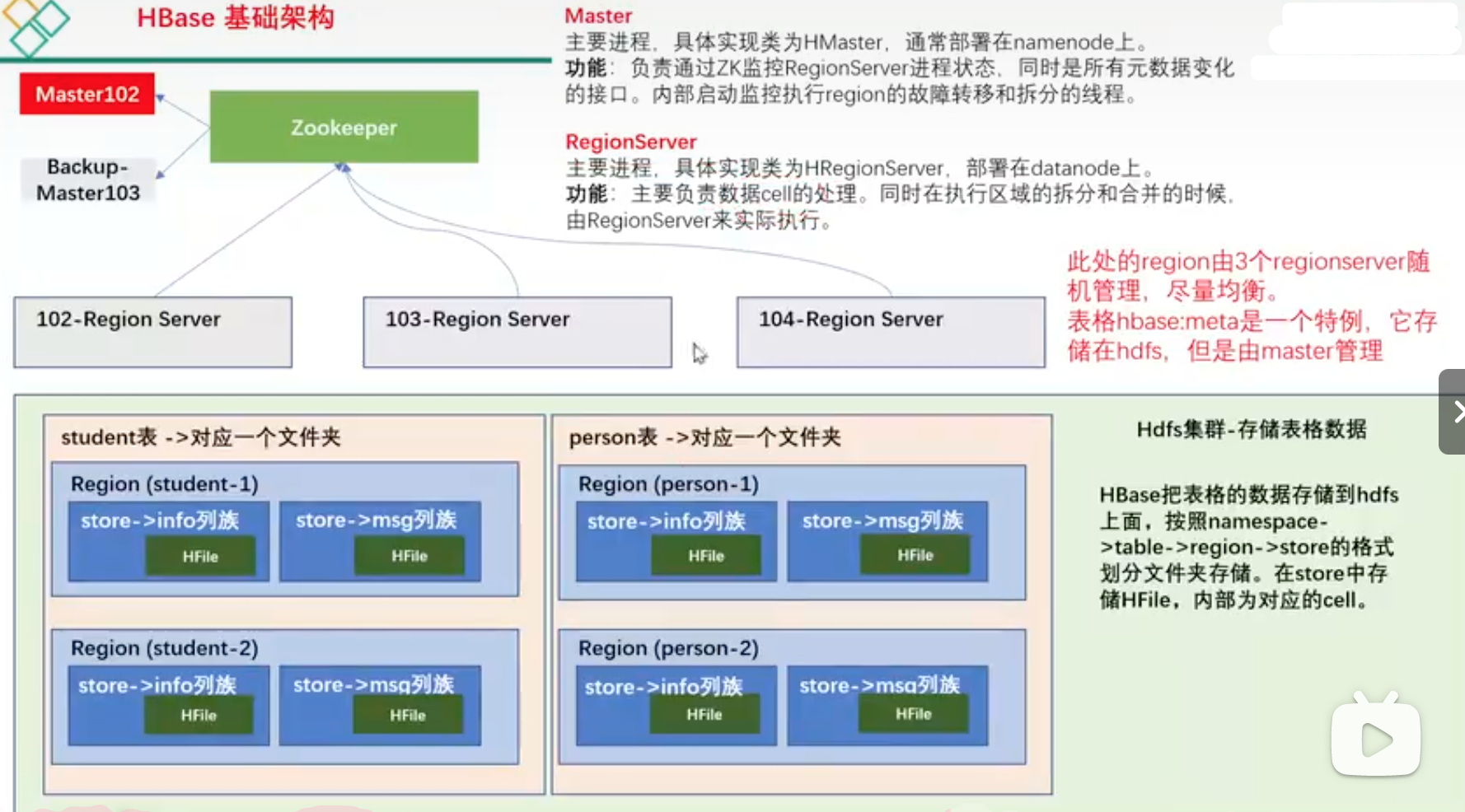
基础架构
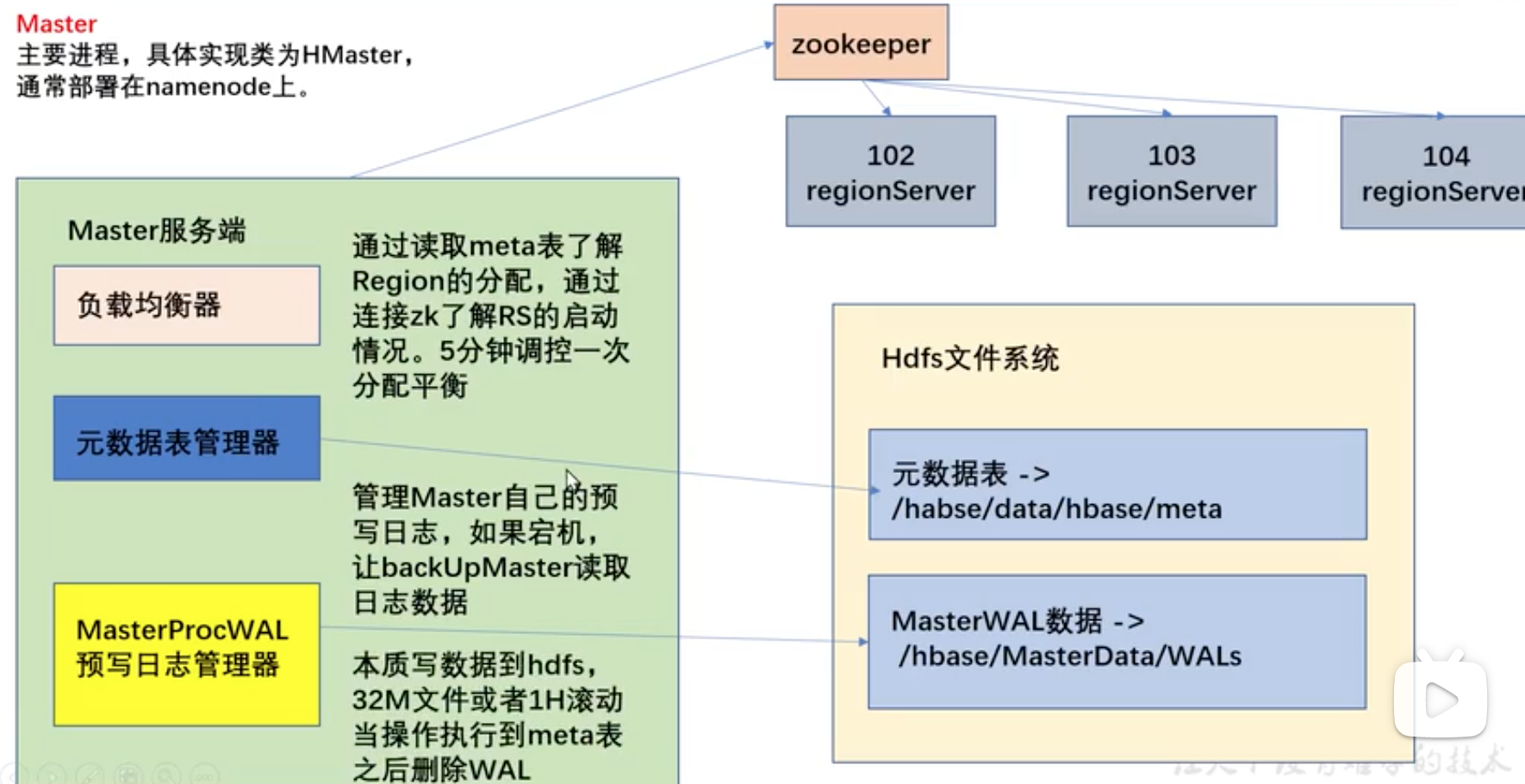
Meta表架构
警告:不要修改
System Table:hbase:meta
表名:[table],[region start key],[region id]
第一列:info:regioninfo 为region信息,存储一个HRegionInfo对象
第二列:info:server 当前region所处的RegionServer信息,包含端口号
第三列:info:serverstartcode 当前region被分到RegionServer的起始时间
如果一个表处于切分的过程中,即region切分,还会多出两列info:splitA和info:splitB,存储值也是HRegionInfo对象,拆分结束后,删除这两列

RegionServer架构

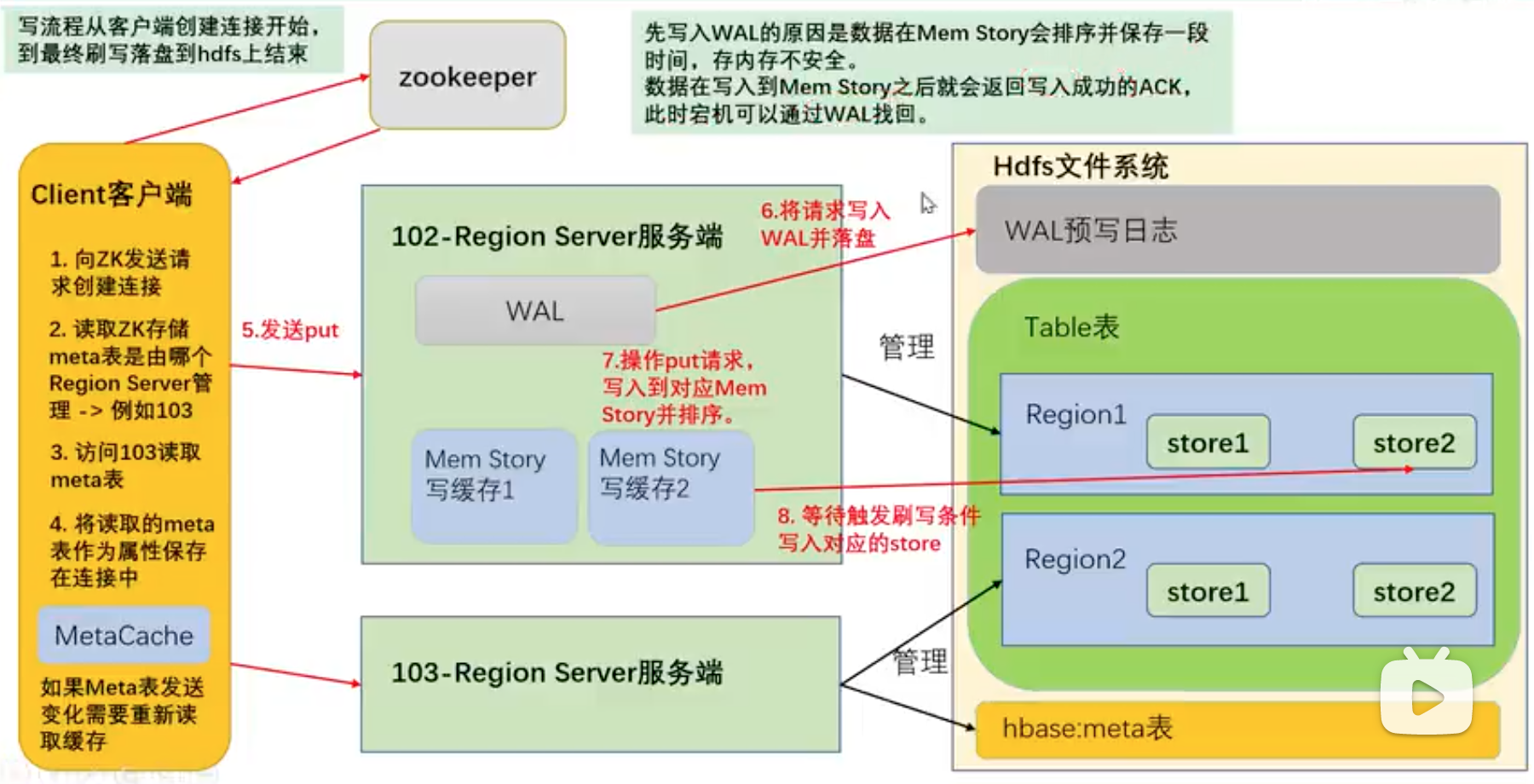
??写流程
master只负责修改和写hbase/meta表,读找zk就可以了,zk会告诉你表在哪
仅能保证单文件HFile/storeFile有序


??读流程
hash有个特点:说没有一定没有,说有不一定有


本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- halcon字符识别结果为“\x1A”
- 深入解析Python装饰器及*args, **kwargs的妙用
- 【激活函数】GELU 激活函数
- c++类中属性私有设置
- Class path contains multiple SLF4J bindings. 用log4j2的sl4j实现,跟springboot默认的logback冲突
- 算法和算法分析
- k8s service的使用
- SpringBoot日志
- 世界排名第一的开源电商系统 -Magento 2
- 书生·浦语大模型全链路开源体系(笔记)