BOSS直聘上算法岗位的薪资分析
????????
目录
????????元旦抽空爬取了一下BOSS直聘上base北京的算法岗位的相关数据,本文简单分析拿给大家做参考,看完才发现算法薪资原来这么高啊、轻松秒掉数据分析。
????????在PC端上打开BOSS直聘网页搜索算法,只会显示10页岗位(每页30条),所以我按照工作经验要求对应届生、 1年以内、 1-3年、 3-5年、 5-10年、 10年以上分别爬了10页数据,总共1770条(漏了30条也不是算法岗位,就不补了)。
一、数据介绍及预处理
1、数据介绍
????????数据包括职位名称、base地点、薪资水平、经验及学历要求、招聘公司、行业、融资阶段、员工规模等?文末获取数据集
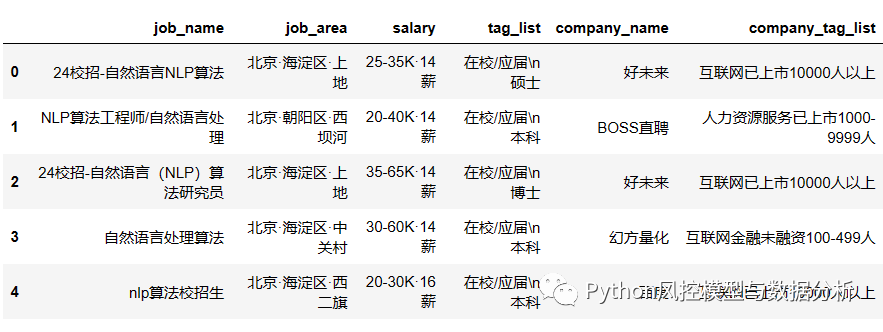
2、数据预处理
(1)数据筛选
????????由于BOSS直聘上搜索算法岗位的结果中,包含一些数据开发、AI产品等其他岗位,因此按照岗位名称是否包含算法/机器学习等来做筛选,剩余1411条
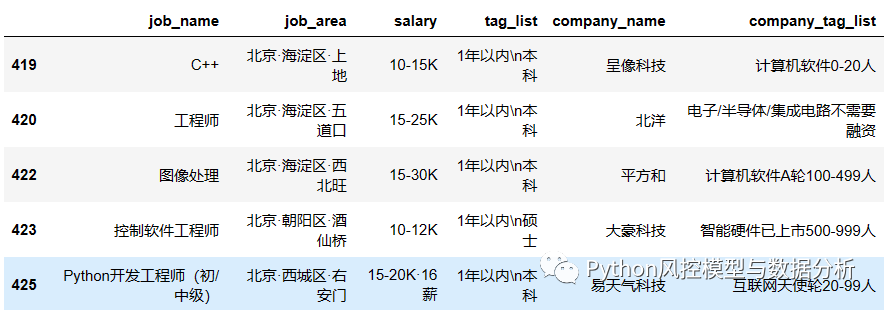
(2)数据分割提取
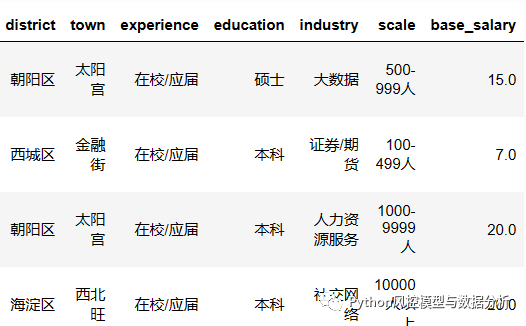
????????在job_area中包括市、行政区、乡镇三级地址,tag_list中包含经验要求、学历要求,company_tag_list中包含行业、融资阶段、员工规模,所以结合split方法、正则表达式分别进行数据提取。
import re
def get_industry(string):
try:
result=re.findall('(.*?)[0-9].*[0-9].*',string)[0]
l=['已上市','不需要融资','未融资','天使轮','A轮','B轮','C轮','D轮及以上']
for s in l:
result=result.replace(s,'')
return result
except:
return None
def get_scale(string):
try:
result=re.findall('([0-9].*[0-9].*)',string)[0]
l=['已上市','不需要融资','未融资','天使轮','A轮','B轮','C轮','D轮及以上']
for s in l:
if s in result:
result=result.split(s)[1]
return result
except:
return None
def dat_pred(data):
df=data[data.job_name.str.contains('算法')|data.job_name.str.contains('机器学习')|data.job_name.str.contains('深度学习')|data.job_name.str.contains('自然语言')|data.job_name.str.contains('NLP')|data.job_name.str.contains('图像识别')].reset_index(drop=True).copy()
df['district']=df.job_area.str.split('·').str[1]
df['town']=df.job_area.str.split('·').str[2]
df['experience']=df.tag_list.str.split('\\n').str[0]
df['education']=df.tag_list.str.split('\\n').str[1]
df['industry']=df.company_tag_list.apply(get_industry)
# df['scale']=df.company_tag_list.apply(lambda x:re.findall('([0-9].*[0-9].*)',x)).str[0]
df['scale']=df.company_tag_list.apply(get_scale)
df['base_salary']=df.salary.str.split('-').str[0]
df.base_salary=df.base_salary.astype(float)
return df
df_all_copy=df_all.pipe(dat_pred)
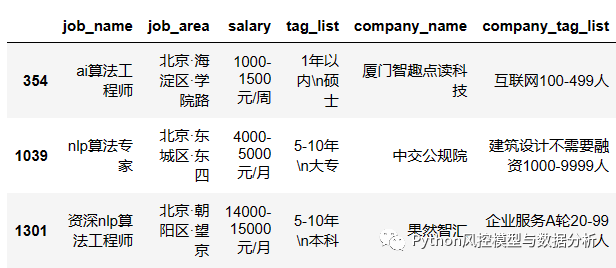
df_all_copy(3)薪资数据处理
????????考虑到薪资待遇下限更贴近实际,因此提取左边界作为base_salary用于分析,此外发现大部分salary单位是k、但是还有部分为元,所以进行标准化处理、统一为k。
二、数据分析
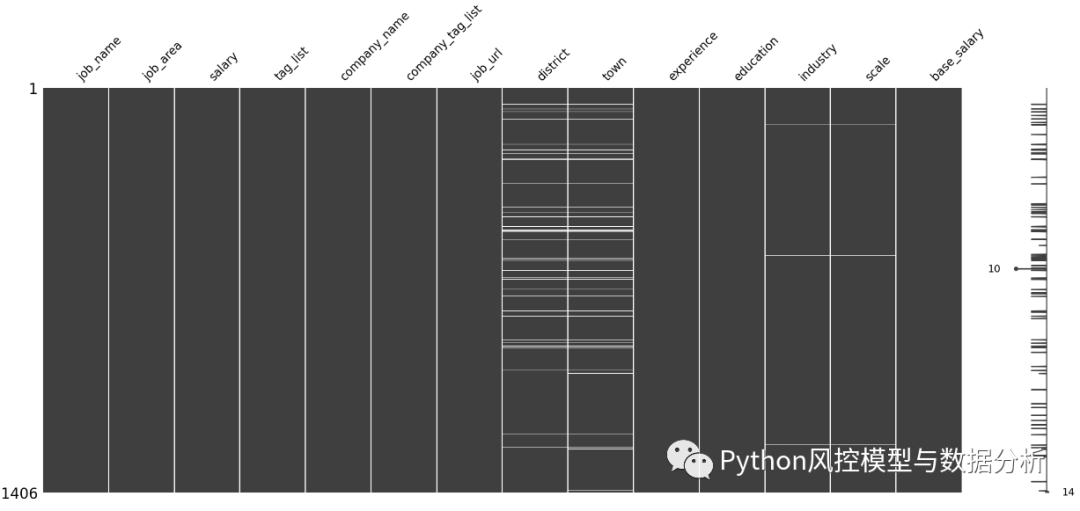
1、缺失值统计
????????由于BOSS直聘上的数据格式规范,所以爬取的数据质量尚可,整体缺失率低
2、岗位数量、薪资水平统计
????????对地域、学历、经验、员工规模等进行分组统计岗位数量、薪资水平
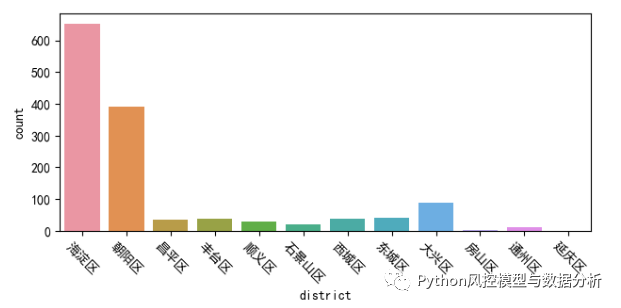
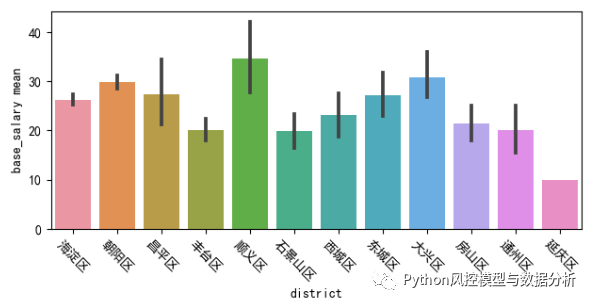
(1)行政区分组统计
????????不出所料,海淀和朝阳的算法岗位数量远超其他地区,在海淀确实有很多互联网大厂的职场,在这个数据集中直接按行政区分组统计base_salary平均水平最高的反而是顺义(同数据分析),而顺义的数据量少、所以结果仅供参考
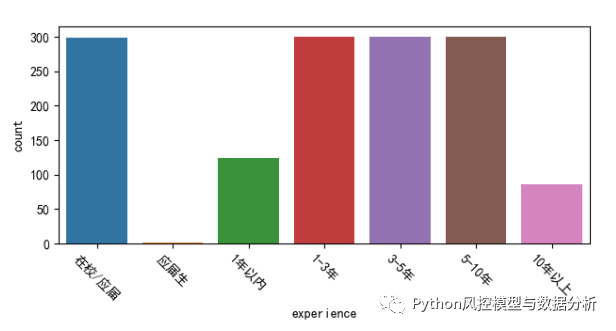
(2)经验要求分组统计
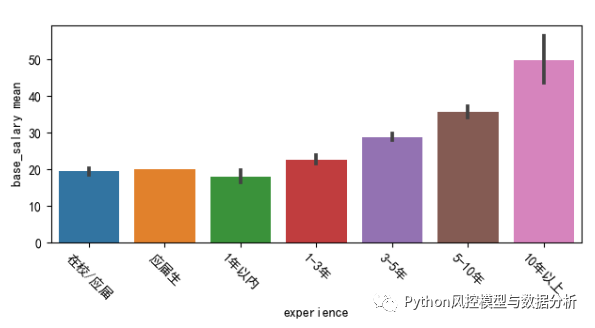
????????从数据结果来看,相对于数据分析岗位而言、企业对应届生的算法岗位招聘量比较可观,当然应届生的面试难度可能更大;算法岗位基本起薪都在20k了,而且随着工作经验增加,算法岗位的薪资待遇增长也很稳定,3年基本就能拿到30k了
(3)学历要求分组统计
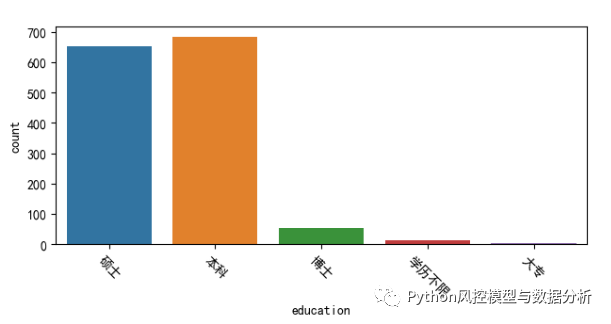
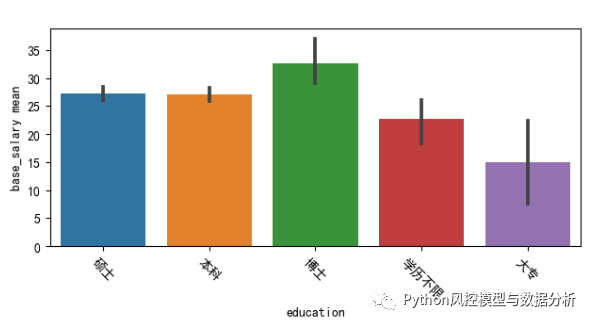
????????从数据结果来看,企业对学历还是有一定要求的,大多本科起步;随着学历提高,薪资差异虽然没有那么大、但也还是明显的单调关系
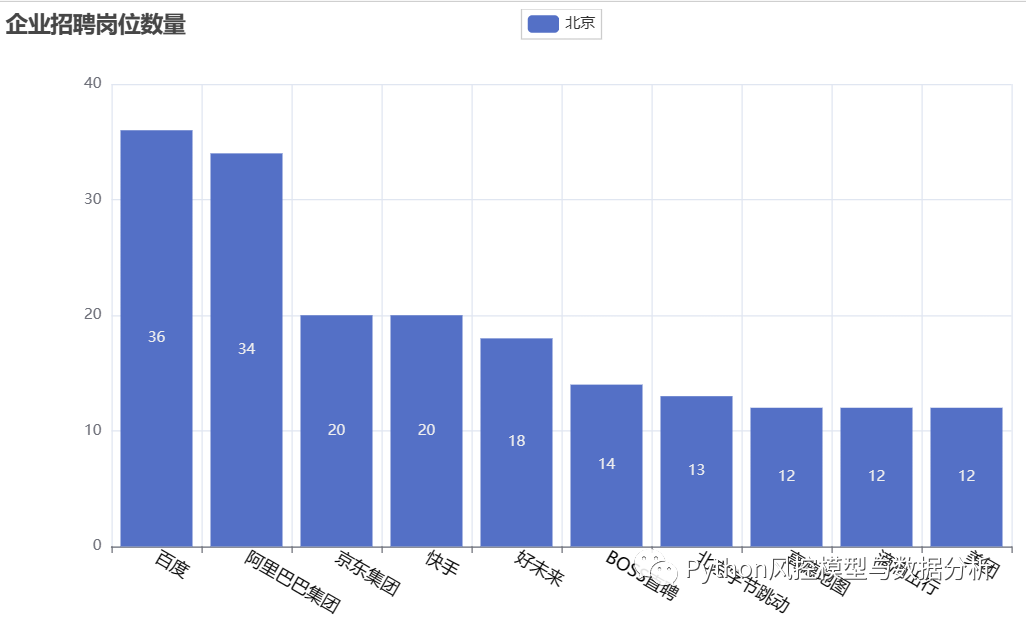
3、企业维度岗位数量
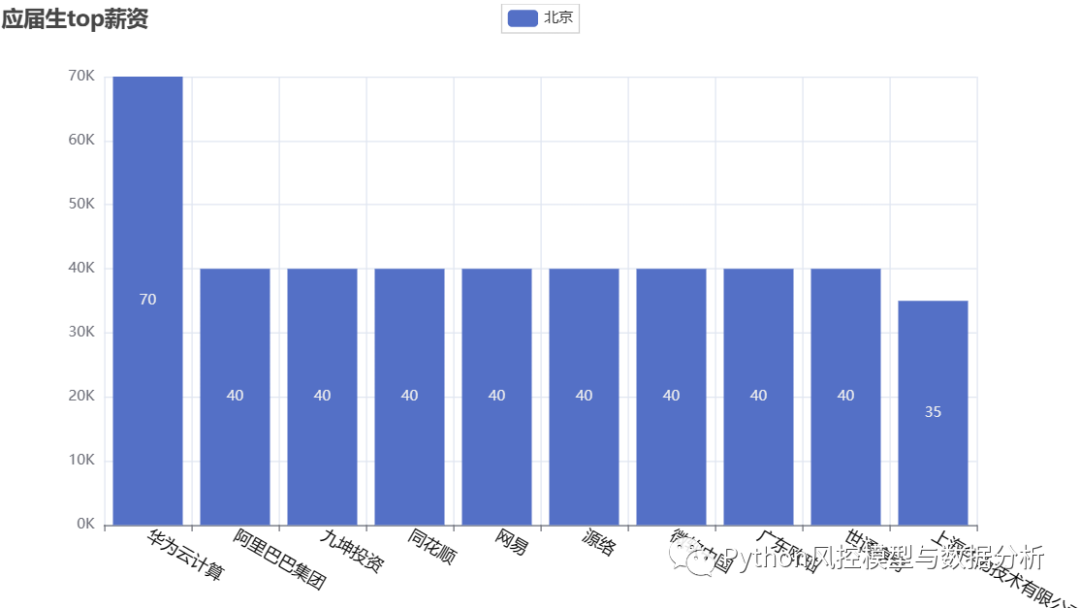
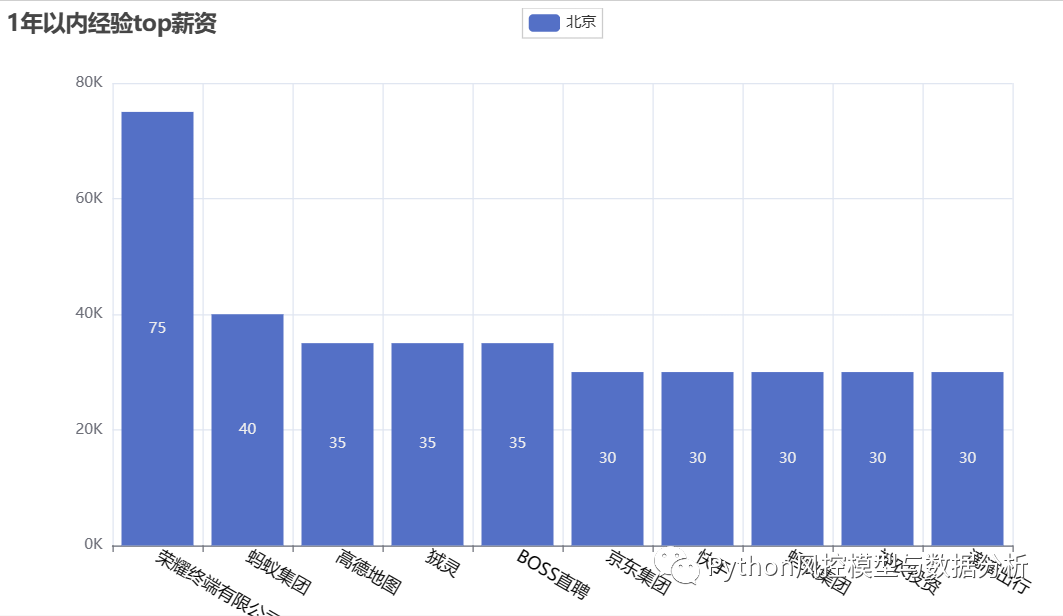
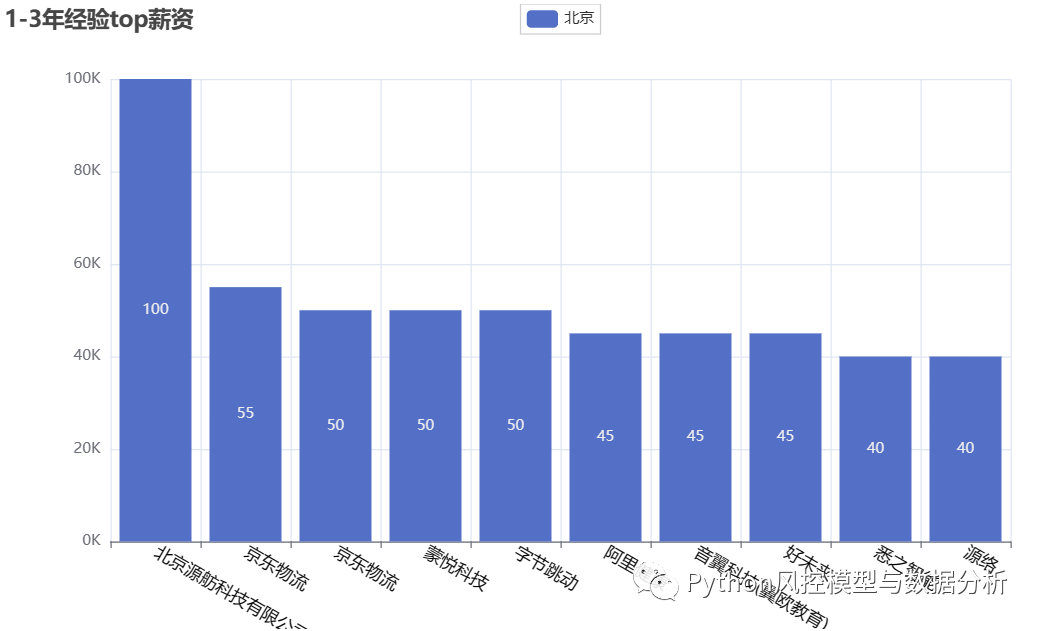
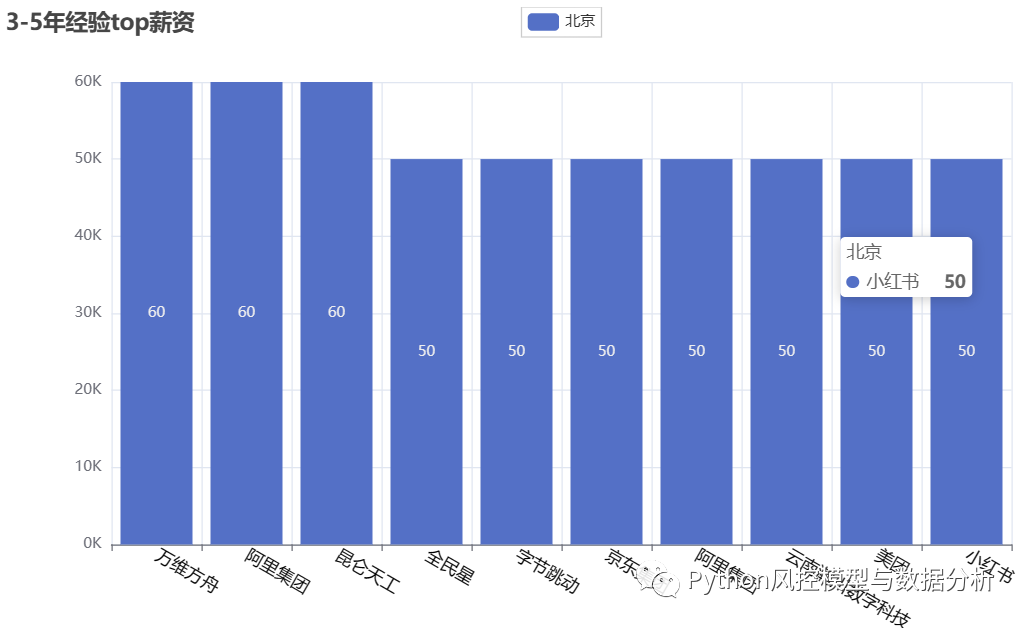
4、top薪资岗位
????????分别对不同经验要求的算法岗位排序的到最高的top10薪资,可以看到在不同经验要求下最高的一批薪资都是很可观的、尤其是top岗位薪资是超乎想象的高,所以加油吧朋友们,钱途可期啊
三、划重点
少走10年弯路
? ? ? ??关注威信公众号?Python风控模型与数据分析,回复?BOSS直聘算法 获取本篇数据及代码
? ? ? ? 还有更多理论、代码分享等你来拿
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- ... * Images are published to: /custom_ns/custom_camera/custo ...
- tp5.1如何修改浏览器标签栏图标
- 大学物理-实验篇——用拉伸法测定金属丝的杨氏(弹性)模量(胡克定律、杨氏模量、平面反射镜、三角函数、螺旋测微器)
- Java Hutool入门教程
- vue和react的区别是什么
- 371、仿真-基于51单片机的交通灯数码管显示(左拐,人行道)(程序+Proteus仿真+原理图+程序流程图+元器件清单+配套资料等)
- 学点心理学做一个灵魂有趣的人,为你讲解生动好玩的心理学话题
- 【Databend】merge 的用法
- AI 魔法画笔、挥洒无限创意 | 开源日报 No.129
- vue实现验证码倒计时功能