Java学习苦旅(二十二)——Map&Set
本篇博客将详细讲解Map和Set。
搜索
概念
Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。以前常见的搜索方式有:
-
直接遍历,时间复杂度为O(N),元素如果比较多效率会非常慢
-
二分查找,时间复杂度为O(log(N)),但搜索前必须要求序列是有序的
上述排序比较适合静态类型的查找,即一般不会对区间进行插入和删除操作了,而现实中的查找比如:
-
根据姓名查询考试成绩
-
通讯录,即根据姓名查询联系方式
-
不重复集合,即需要先搜索关键字是否已经在集合中
可能在查找时进行一些插入和删除的操作,即动态查找,那上述两种方式就不太适合了,本节介绍的Map和Set是一种适合动态查找的集合容器。
模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称之为Key-value的键值对,所以模型会有两种:
- 纯key模型,例如:
-
有一个英文词典,快速查找一个单词是否在词典中
-
快速查找某个名字在不在通讯录中
- Key-Value模型,比如:
-
统计文件中每个单词出现的次数,统计结果是每个单词都有与其对应的次数:<单词,单词出现的次数>
-
梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
而Map中存储的就是key-value的键值对,Set中只存储了Key。
Map
Map是一个接口类,该类没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复。
Map.Entry<K, V>
Map.Entry<K, V>是Map内部实现的用来存放<key, value>键值对映射关系的内部类,该内部类中主要提供了<key, value>的获取,value的设置以及Key的比较方式。
| 方法 | 解释 |
|---|---|
| K getKey() | 返回entry中的key |
| V getValue() | 返回entry中的value |
| V setValue(V value) | 将键值对中的value替换为指定value |
Map的常用方法说明
| 方法 | 解释 |
|---|---|
| V get(Object key) | 返回key对应的value |
| V getOrDefault(Object key, V defaultValue) | 返回key对应的value,key不存在,返回默认值 |
| V put(K key, V value) | 设置key对应的value |
| V remove(Object key) | 删除key对应的映射关系 |
| Set<K> keySet() | 返回所有key的不重复集合 |
| Collection<V> values() | 返回所以value的可重复集合 |
| Set<Map.Entry<K,V>> entrySet() | 返回所有的key-value映射关系 |
| boolean containsKey(Object key) | 判断是否包含key |
| boolean containsValue(Object value) | 判断是否包含value |
示例代码
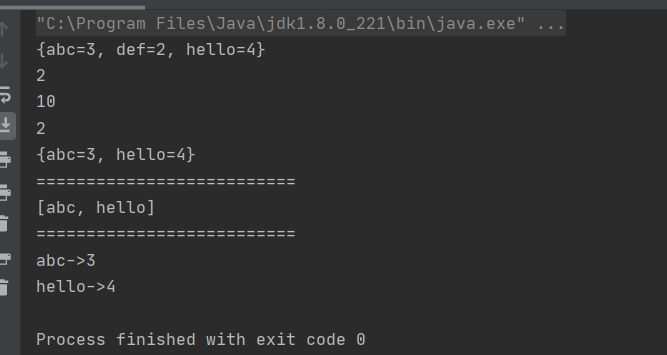
public static void main(String[] args) {
Map<String,Integer> map = new HashMap<>();
map.put("abc",3);
map.put("def",2);
map.put("hello",4);//存储元素的时候,要注意key如果相同,value的值会被覆盖
System.out.println(map);
int ret = map.get("def");
System.out.println(ret);
System.out.println(map.getOrDefault("lmn",10));
Integer ret2 = map.remove("def");
System.out.println(ret2);
System.out.println(map); System.out.println("==========================");
Set<String> set = map.keySet();//通过key获取对应的value值
System.out.println(set);
System.out.println("==========================");
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for (Map.Entry<String,Integer> entry : entrySet) {
System.out.println(entry.getKey()+"->"+entry.getValue());
}
}
执行结果为
注意:
-
Map是一个接口,不能直接实例化对象,如果要实例化对象只能实例化其实现类TreeMap或者HashMap。
-
Map中存放键值对的Key是唯一的,value是可以重复的。
-
在Map中插入键值对时,key不能为空,否则就会抛NullPointerException异常,但是value可以为空。
-
Map中的Key可以全部分离出来,存储到Set中来进行访问(因为Key不能重复)。
-
Map中的value可以全部分离出来,存储在Collection的任何一个子集合中(value可能有重复)。
-
Map中键值对的Key不能直接修改,value可以修改,如果要修改key,只能先将该key删除掉,然后再来进行重新插入。
TreeMap和HashMap的区别
| Map底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找的时间复杂度 | O(log(N)) | O(1) |
| 是否有序 | 关于Key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找的区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
Set
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key。
常用方法说明
| 方法 | 解释 |
|---|---|
| boolean add(E e) | 添加元素,但重复元素不会被添加成功 |
| void clear() | 清空集合 |
| boolean contains(Object o) | 判断o是否在集合中 |
| Iterator<E> interator() | 返回迭代器 |
| boolean remove(Object o) | 删除集合中的o |
| int size() | 返回set中元素的个数 |
| boolean isEmpty() | 检测set是否为空,空返回true,否则返回false |
| Object[] toArray() | 将set中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合c中的元素是否在set中全部存在,是返回true,否则返回false |
| boolean addAll(Collection<? extends E> c) | 将集合c中的元素添加到set中,可以达到去重的效果 |
示例代码
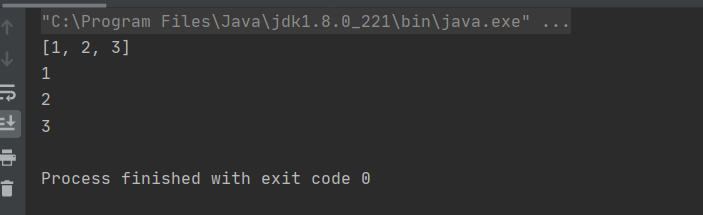
public static void main(String[] args) {
Set<Integer> set = new HashSet<>();
set.add(1);
set.add(2);
set.add(3);
System.out.println(set);
Iterator<Integer> iterator = set.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
执行结果为
注意:
-
Set是继承自Collection的一个接口类。
-
Set中只存储了key,并且要求key一定要唯一。
-
Set的底层是使用Map来实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的。
-
Set最大的功能就是对集合中的元素进行去重。
-
实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet是在HashSet的基础上维护了一个双向链表来记录元素的插入次序。
-
Set中的Key不能修改,如果要修改,先将原来的删除掉,然后再重新插入。
-
Set中不能插入null的key。
TreeSet和HashSet的区别
| Set底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log(N)) | O(1) |
| 是否有序 | 关于Key有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1.先计算Key哈希地址。2.然后进行插入和删除 |
| 比较与覆写 | Key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key是否有序不关心,需要更高的时间性能 |
结尾
本篇博客到此结束。
上一篇博客:Java学习苦旅(二十一)——泛型
下一篇博客预告:Java学习苦旅(二十三)——二叉搜索树
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- React与Vue:前端框架的比较
- 爬虫引流(简单实现这个功能)
- 欧美电商平台Depop如何入驻?
- Android 车联网——PowerHalService介绍(九)
- JavaWeb-HTTP
- 仓储|仓库管理水墨屏RFID电子标签2.4G基站CK-RTLS0501G功能说明与安装方式
- zeppelin记录2
- 大数据毕业设计:python高校微博舆情分析可视化系统 NLP情感分析 可视化 Flask框架 爬虫(源码)?
- 面试宝典之微服务框架面试题
- 理论U4 集成学习