leetcode 每日一题 2024年01月14日 删除排序链表中的重复元素
发布时间:2024年01月14日
题目
给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:

输入:head = [1,1,2]
输出:[1,2]
示例 2:
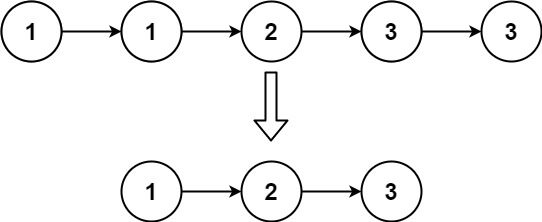
输入:head = [1,1,2,3,3]
输出:[1,2,3]
提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
分析
链表的删除一般需要两个指针,一个指针cur指向当前节点,一个指针next指向下一个节点。
删除下一个节点:cur.next = next.next
-
链表是有序的,我们需要删除,相邻的相同的节点。
-
所以cur.val == next.val时删除一节点。并且pre(cur)是不用移动的,新的
next指针指向原本的next.next,现在的pre(cur).next。
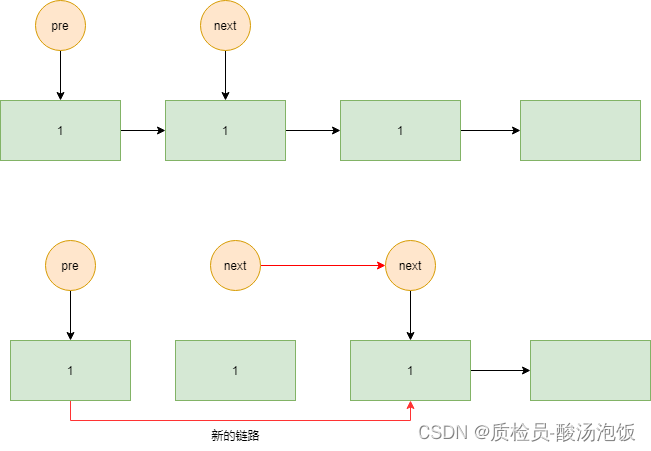
if(cur.val==next.val){ cur.next = next.next; next = cur.next; } -
当
cur.val != next.val,相邻两个节点是不同的,直接遍历下两个相邻的节点。即:if(cur.val != next.val){ cur = next.next; next = cur.next; } -
将上述过程整合成为代码如下。
代码
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode() {}
* ListNode(int val) { this.val = val; }
* ListNode(int val, ListNode next) { this.val = val; this.next = next; }
* }
*/
class Solution {
public ListNode deleteDuplicates(ListNode head) {
if (head == null) return head;
ListNode cur = head;
ListNode next = head.next;
while (next != null) {
if (cur.val == next.val) {
cur.next = next.next;
} else {
cur = next;
}
next = cur.next;
}
return head;
}
}
复杂度
时间复杂度:O(n)
空间复杂度:O(1)
交流
qq群:
文章来源:https://blog.csdn.net/h88888888888/article/details/135578860
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 传统文本短信无缝升级,什么是AIM短信?
- Web网页开发-CSS层叠样式表1-笔记
- Python:爬虫获取微信公众号里面的表格内容+整理数据导出表格
- Postman基本使用、测试环境(Environment)配置
- C11新特性
- 华为OD机试 - 堆内存申请(Java & JS & Python & C)
- ai训练总结
- 前端开发学习与发展建议,错过很可惜
- 验证回文串(aa)
- ????—游戏-01_2D-开发—????