深入HashMap底层理解阿里手册的遍历守则
写在文章开头
你好,我叫sharkchili,目前还是在一线奋斗的Java开发,经历过很多有意思的项目,也写过很多有意思的文章,是CSDN Java领域的博客专家,也是Java Guide的维护者之一,非常欢迎你关注我的公众号:写代码的SharkChili,这里面会有笔者精心挑选的并发、JVM、MySQL数据库专栏,也有笔者日常分享的硬核技术小文。

HashMap算是我们日常开发中比较常用的一个集合工具,在阿里开发手册中也有提及关于HashMap的使用守则:
??【推荐】使用entrySet遍历Map类集合KV,而不是keySet方式进行遍历。
????
??说明:keySet其实是遍历了2次,一次是转为Iterator对象,另一次是从hashMap中取出key所对应的value。而entrySet只是遍历了一次就把key和value都放到了entry中,效率更高。如果是JDK8,使用Map.foreach方法。
??
??正例:values()返回的是V值集合,是一个list集合对象;keySet()返回的是K值集合,是一个Set集合对象;entrySet()返回的是K-V值组合集合。
对于这一守则,笔者会通过代码实验和HashMap底层实现进行一次深入剖析,希望能够让读者对该守则有更深刻的理解和掌握。

实验论证守则
在论证为什么之前,我们必须先印证是不是,所以笔者针对这一守则给出两段示例代码,先来看看基于keySet 遍历的代码示例,可以看到笔者为了让增加散列的随机性,key使用工具类进行随机生成20长度的字符串:
public static void main(String[] args) {
//生成2000w的数据
Map<String, Integer> map = new HashMap<>();
for (int i = 0; i < 2000_0000; i++) {
map.put(RandomUtil.randomString(20), i);
}
//使用keySet取值
long begin = System.currentTimeMillis();
Set<String> keySet = map.keySet();
for (String key : keySet) {
map.get(key);
}
long end = System.currentTimeMillis();
log.info("使用keySet 总耗时:{}ms", end - begin);
}
对应输出结果如下,可以看到总耗时为816ms:
23:55:57.159 [main] INFO com.sharkChili.webTemplate.test.Test - 使用keySet 总耗时:816ms
同样的我们给出entrySet的示例:
public static void main(String[] args) {
//生成2000w的数据
Map<String, Integer> map = new HashMap<>();
for (int i = 0; i < 2000_0000; i++) {
map.put(RandomUtil.randomString(20), i);
}
//使用 entrySet 取值
long begin = System.currentTimeMillis();
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String, Integer> entry : entrySet) {
entry.getValue();
}
long end = System.currentTimeMillis();
log.info("使用entrySet 总耗时:{}ms", end - begin);
}
对应输出结果如下,可以看到耗时为keySet一半左右,不难看出同样时遍历前者遍历时比后者多做了一倍的工作:
23:57:26.593 [main] INFO com.sharkChili.webTemplate.test.Test - 使用entrySet 总耗时:482ms
源码剖析
当我们调用keySet()获取keySe集合时,底层实际上是为当前这个HashMap生成一个keySet对象,这一点我们从注释中也能看到这一点,自此我们可知这个视图并不是调用时遍历生成的:
Returns a {@link Set} view of the keys contained in this map.
其次我们查看源码,发现进行keySet初始化创建时,会将其赋值给成员变量ks ,这也就意味着后续在使用keySet进行遍历时,HashMap就不会再创建一个全新的keySet:
public Set<K> keySet() {
Set<K> ks = keySet;
//初始化时创建一个key的视图,后续使用这个视图时都是复用本次初始化得来的
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
随后我们在使用增强for进行遍历时,代码会来到内部迭代器HashIterator 的内部类KeyIterator ,为当前遍历创建一个KeyIterator :
abstract class HashIterator {
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
}
而这个迭代器是继承自HashIterator,所以进行初始化时,实际上还是调用HashIterator的构造方法。
我们都知道HashMap底层的实现是数组+链表/红黑树,所以在进行key的迭代器生成时,它会通过遍历找到数组中第一个不为空的位置,并让next指针指向这个元素:
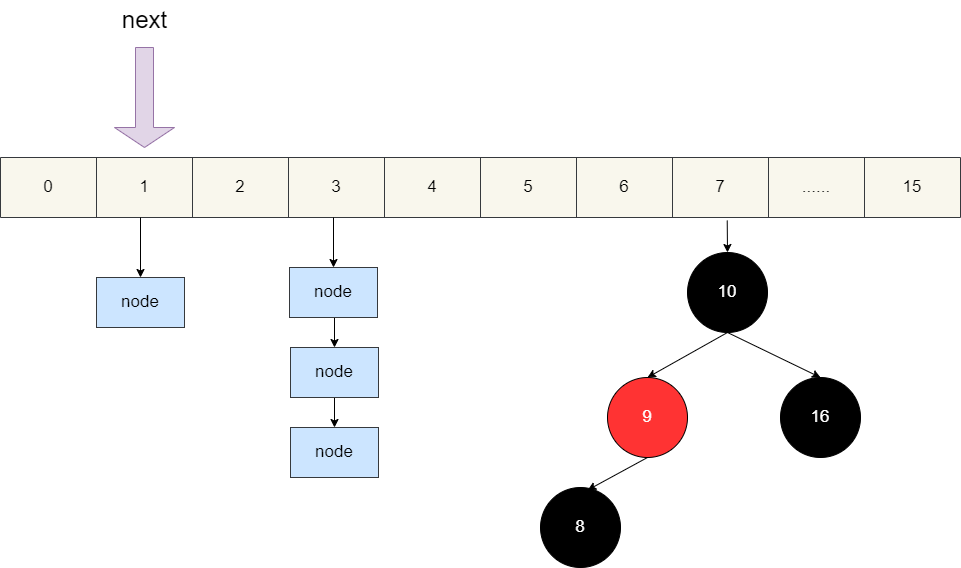
对应的源码如下图所示,HashIterator在do-while循环中不断步进直到next指向的索引位置不为空为止:
HashIterator() {
expectedModCount = modCount;
Node<K,V>[] t = table;
current = next = null;
index = 0;
//不断步进这个底层数组table,直到找到第一个不为空的元素为止
if (t != null && size > 0) { // advance to first entry
do {} while (index < t.length && (next = t[index++]) == null);
}
}
完成迭代器的初始化工作后,增强for取值逻辑就是基于这个KeyIterator的hasNext(实际调用的是其父类HashIterator的hasNext):
public final boolean hasNext() {
return next != null;
}
只要上述方法不为空,迭代器则直接将这个key对应的节点Node的key返回出去:
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
随后我们又回过头用这个key到HashMap使用get方法获取value,可以看到如果当前节这个key是链表或者红黑树的话,又需要进行一次**O(n)或者O(log n)**的查询:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//红黑树的遍历定位
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//链表的循环定位
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
以下图为例,假设我们要获取key为b的value,这就意味着,我们迭代keySet时经过了a,b,在获取value时要需要根据key定位到索引1的位置,再经过一次a节点找到key为b的节点,自此我们也就直到了为什么使用keySet定位k-v效率低下的原因了。
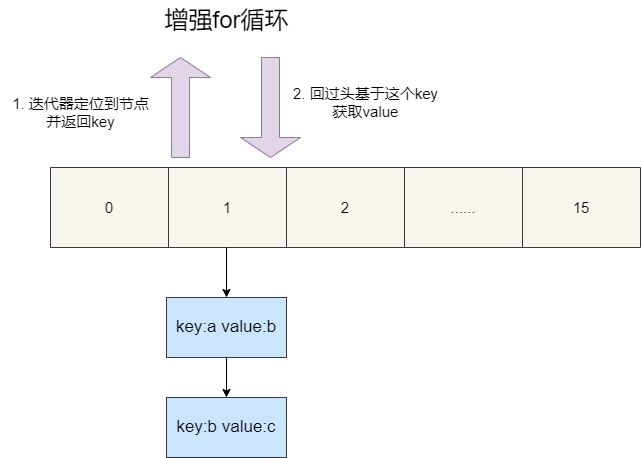
了解了keySet的低效,我们自然也需要直到为什么entrySet是高效的,和keySet一样,entrySet进行初始化时也是创建一个EntrySet对象并赋值给成员变量es 。它同样也是HashIterator的子类,所以初始化next定位第一个元素的步骤和keySet是一样的,这里就不多赘述了。
唯一区别就是我们的使用entrySet进行遍历时,返回的就是HashMap的节点entry,所以我们在获取value时无需再回过头到数组中定位元素,避免了一次扫描,这也是为什么是使用entrySet进行k-v遍历高效的原因所在。
final class EntryIterator extends HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}
小结
相信通过笔者的解读,你对于HashMap的底层实现和遍历技巧有着更进一步的理解和掌握,基于此文笔者也顺便总结一下HashMap的一些遍历守则:
- 只需要遍历key时用keySet方法。
- 只要values用values方法。
- 若需要遍历k-v则建议是使用entrySet或者JDK8提供的forEach方法。
我是sharkchili,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号:
写代码的SharkChili,同时我的公众号也有我精心整理的并发编程、JVM、MySQL数据库个人专栏导航。

参考
为什么阿里巴巴为什么不推荐使用keySet()进行遍历HashMap?:https://juejin.cn/post/7295353579002396726
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!