DLRover 部署指南之5分钟上手分布式模型训练,让你体验别样人生
DLRover

DLRover makes the distributed training of large AI models easy, stable, fast and green. It can automatically train the Deep Learning model on the distributed cluster. It helps model developers to focus on model arichtecture, without taking care of any engineering stuff, say, hardware acceleration, distributed running, etc. Now, it provides automated operation and maintenance for deep learning training jobs on K8s/Ray.
蚂蚁开源的(大模型)分布式训练框架|系统;在k8s上实现模型训练的故障恢复、节点状态检测、弹性调度、Async Flash checkpoint 等功能,“实现PyTorch分布式训练的自动容错和弹性”。
- 出现故障后,快速执行节点健康检测,定位故障机并将其隔离,然后重启 Pod 来替换故障节点
- 健康检测通过后,重启训练子进程来自动恢复模型训练,无需重启作业或者所有 Pod
- 节点故障导致可用机器少于作业配置,自动缩容来继续训练。集群新增机器后,自动扩容来恢复节点数量
- 优化 FSDP 并行训练的模型 save/load,支持根据实际卡数 reshard 模型参数,缩短 checkpoint 保存和加载时间
从这里可以看出,DLRover和蚂蚁内部的ElasticDL 关系甚大,极有可能是ElasticDL的升级、扩展后“改头换面”。
当然具体实现功能如何,经过实测,后文会有补充说明。
本地&GPU 部署
创建K8S集群
准备一个K8S集群,node 全部ready,最好去掉污点。
MAC OS
可以使用minikube ,不过不推荐!
建议本地安装Docker+K8S;这方面文章很多就不赘述了。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker-desktop Ready control-plane - v1.28.2
GPU 节点
一般选择containerd+kubeadm+kubelet;
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
node1 Ready <none> - v1.28.2
node2 Ready <none> - v1.28.2
node3 Ready <none> - v1.28.2
node4 Ready <none> - v1.28.2
安装Elastic JOB
安装Elasticjob 需要非常小心,坑不少。
git clone dlrover 代码
git clone git@github.com:intelligent-machine-learning/dlrover.git
install CRDs
这里有些许不同,注意本地MAC OS与GPU节点的差异;
本地MAC OS由于存储空间有限,训练测试任务比较简单,能使用DLRover即可;而生产环境或者GPU集群中,往往是复杂、大规模的分布式训练,功能作用的不同导致在CRDs的安装、Docker Image 等都有些许区别,请往下看:
本地
仅安装基础CRDs,也是测试DLRover后续需要使用到的elasticjobs.elastic.iml.github.io和scaleplans.elastic.iml.github.io;
cd dlrover
kubectl apply -f dlrover/go/operator/config/crd/bases
kubectl -n dlrover apply -f dlrover/go/operator/config/manifests/bases/default-role.yaml
这里注意目录path,DLRover的文档中的path很多地方都不对,注意矫正。
(多说一句,不知是蚂蚁内部脱敏还是Infra团队太忙,文档中的细节比较差,在部署过程中很多地方需要自己脑补、修正,部分地方已经merge PR不过不保证没有疏漏:-)
前面都是比较简单的无脑执行CMD,接下来的就是较为复杂,往往第一次部署会踩坑。
deploy Elasticjob
如果直接按照github文档执行以下命令大概率会出现这些现象;
make deploy IMG=easydl/elasticjob-controller:master
- 命令长时间阻塞
比如提示一直在等待安装kustomize;几十分钟后提示"Version v3.8.7 does not exist for darwin/arm64, trying darwin/amd64 instead.";又或者提示“make: *** [Makefile:43: manifests] Error 1”。
$ make deploy IMG=easydl/elasticjob-controller:master
test -s /root/dlrover-0.3.1/dlrover/go/operator/bin/kustomize || { [ -s /root/install_kustomize.sh ] && bash /root/install_kustomize.sh || curl -s "https://raw.githubusercontent.com/kubernetes-sigs/kustomize/master/hack/install_kustomize.sh" | bash -s -- 3.8.7 /root/dlrover-0.3.1/dlrover/go/operator/bin; }
- 立即报错"Error: err: exit status 1: stderr: go: updates to go.mod needed; to update it:"
看到以上错误不要慌,按照以下流程走避免这些坑。
install_kustomize.sh打开虽然看着很长,内容很多,其实就是简单的检查kustomize是否已经安装,没有就安装kustomize;当然默认版本是3.8.7,这里的另一个问题是shell指定的3.8.7 版本并不存在,所以需要修改,安装最新版(v5.3)即可。
所以操作步骤变更为手动安装kustomize_v5.3;
前往github release下载对应版本的包,比如本地是MAC M3下载Kustomize_v5.3.0_darwin_arm64.tar.gz即可;
解压到指定目录,这里非常重要;
tar -xf Kustomize_v5.3.0_darwin_arm64.tar.gz -C /dlrover/dlrover/go/operator/bin/
因为install_kustomize.sh检查的路径是/dlrover/dlrover/go/operator/bin/,所以我们必须把kustomize安装到这个路径下!
执行命令检查安装是否成功:
kustomize version
回过头来,继续执行make deploy IMG=easydl/elasticjob-controller:master,会发现很快便成功了;
检查CRD
$ kubectl -n dlrover get crd
NAME CREATED AT
elasticjobs.elastic.iml.github.io -
scaleplans.elastic.iml.github.io -
检查 dlrover deployment
$ kubectl -n dlrover get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
dlrover-controller-manager 1/1 1 1 -
到此DLRover的本地部署工作完成了;接下来就是开始执行训练任务,测试DLRover的功能;未完待续哈。
GPU集群
相较于本地MAC OS,GPU集群上部署往往更为复杂;
准备工作
首先下载kustomize release包(注意操作系统与软件包的对应关系,最新版即可比如v5.3),并上传到master节点;
部署
clone DLRover代码到节点;
git clone git@github.com:intelligent-machine-learning/dlrover.git
进入代码目录(注意目录path);
cd dlrover/dlrover/go/operator/
make deploy IMG=easydl/elasticjob-controller:master
这里会有报错(参考前面本地部署的deploy Elasticjob章节);所以需要手动安装kustomize;解压kustomize安装包到dlrover/dlrover/go/operator/bin并检查安装;
tar -xf kustomize.gz -C /dlrover/dlrover/go/operator/bin
kustomize version
把CRD的权限给到DLRover Master Manager;
kubectl -n dlrover apply -f config/manifests/bases/default-role.yaml
检查CRD
GPU 集群的部署方式与本地存在差异,前往egistry.cn-hangzhou.aliyuncs.com拉取的CRD非常多,耗时非常长,比如统计下来达到97个;核心的其实是2个elasticjobs.elastic.iml.github.io和scaleplans.elastic.iml.github.io。
$ kubectl -n dlrover get crd |wc -l
97
可以通过kubectl 进行针对性检查(非常有必要):
kubectl -n dlrover get crd elasticjobs.elastic.iml.github.io
kubectl -n dlrover get crd scaleplans.elastic.iml.github.io
检查 dlrover deployment
$ kubectl -n dlrover get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
dlrover-controller-manager 1/1 1 1 -
到此DLRover的部署工作完成了;接下来就是开始执行训练任务,测试DLRover的功能;
DLRover Fault-tolerance Experiments
启动chao test job,模拟训练任务;
$ kubectl -n dlrover apply -f examples/pytorch/mnist/chaos_test_job.yaml
$ kubectl -n dlrover get pods
NAME READY STATUS RESTARTS AGE
chaos-test-edljob-worker-0 0/1 ContainerCreating 0 2m32s
chaos-test-edljob-worker-1 0/1 ContainerCreating 0 2m32s
chaos-test-edljob-worker-2 0/1 ContainerCreating 0 2m32s
chaos-test-edljob-worker-3 0/1 ContainerCreating 0 2m32s
dlrover-controller-manager-68c984bdc9-vkwbh 2/2 Running 0 17m
elasticjob-chaos-test-dlrover-master 1/1 Running 0 3m27s
等待几分钟,等全部ready后kubelet -n dlrover delete pod 会发现DLRover会把训练任务重新拉起。
动态组网 tips
需要注意的是在apply chaos_test_job.yaml 后,pod由于长时间没有ready;此时delete ContainerCreating的pod;会发现pod直接进入error;但是DLRover感知到POD Error,随时拉起新的POD,此时集群中POD个数会由4->5;而且error pod会在相当长的时间内存在,直到手动delete。
如果kubectl -n dlrover log 会发现DLRover的动态组网在等待新的POD加入;
[2024-01-16 08:03:46,459] [ERROR] [training.py:842:run] Network check needs at least 4 nodes.
动态组网相关原理参考DLRover Doc,下面的原图:
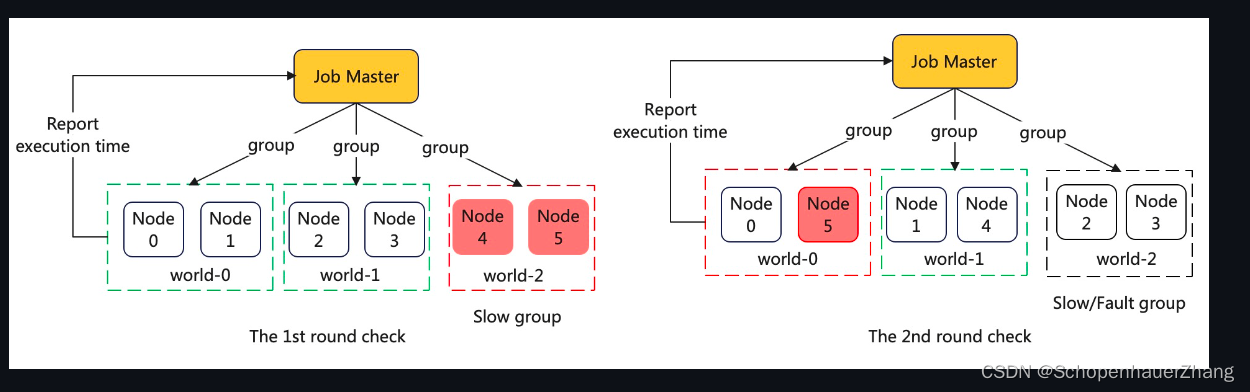
这里逻辑目前看来似乎存在bug,如果旧节点长时间Err status,DLRover并不会主动清理,但是会拉起新的节点(因为组网最小集合不满足),于是发生失败的节点越多,新加入的节点越多,节点越多,失败的概率增大;类似网络拥塞。
夜深了,后续有时间再增加对DLRover的Async Flash checkpoint 等功能的测试吧。
QA
Go version 及Config
虽然DLRover 的developer_guide 中要求Go 1.17 or later;但是在部署过程中发现,至少需要1.18,比如本文部署时选择了Go 1.21;
如果GO version存在问题,在deploy elasticjob的过程中会发现如下问题:
note: module requires Go 1.17
如果go version < 1.17
# sigs.k8s.io/json/internal/golang/encoding/json
/root/go/pkg/mod/sigs.k8s.io/json@v0.0.0-20211208200746-9f7c6b3444d2/internal/golang/encoding/json/encode.go:1249:12: sf.IsExported undefined (type reflect.StructField has no field or method IsExported)
/root/go/pkg/mod/sigs.k8s.io/json@v0.0.0-20211208200746-9f7c6b3444d2/internal/golang/encoding/json/encode.go:1255:18: sf.IsExported undefined (type reflect.StructField has no field or method IsExported)
note: module requires Go 1.17
# golang.org/x/net/http2
/root/go/pkg/mod/golang.org/x/net@v0.0.0-20220722155237-a158d28d115b/http2/transport.go:416:45: undefined: os.ErrDeadlineExceeded
note: module requires Go 1.17
# sigs.k8s.io/controller-tools/pkg/loader
/root/go/pkg/mod/sigs.k8s.io/controller-tools@v0.9.2/pkg/loader/loader.go:487:5: undefined: os.DirEntry
/root/go/pkg/mod/sigs.k8s.io/controller-tools@v0.9.2/pkg/loader/loader.go:545:14: undefined: filepath.WalkDir
note: module requires Go 1.17
手动安装到大于1.17版本,否则如下
$ make deploy IMG=easydl/elasticjob-controller:master
dlrover/dlrover/go/operator/bin/controller-gen rbac:roleName=manager-role crd webhook paths="./..." output:crd:artifacts:config=config/crd/bases
api/v1alpha1/groupversion_info.go:24:2: zip: not a valid zip file
pkg/common/resource.go:29:2: zip: not a valid zip file
pkg/controllers/elasticjob_controller.go:31:2: zip: not a valid zip file
pkg/controllers/elasticjob_controller.go:32:2: zip: not a valid zip file
pkg/controllers/scaleplan_controller.go:33:2: zip: not a valid zip file
pkg/controllers/elasticjob_controller.go:34:2: zip: not a valid zip file
pkg/controllers/scaleplan_controller.go:35:2: zip: not a valid zip file
main.go:29:2: zip: not a valid zip file
main.go:25:2: zip: not a valid zip file
main.go:31:2: zip: not a valid zip file
main.go:32:2: zip: not a valid zip file
Error: not all generators ran successfully
go mod tidy fail
$ make deploy IMG=easydl/elasticjob-controller:master
...
Error: err: exit status 1: stderr: go: updates to go.mod needed; to update it:
go mod tidy
...
$ go mod tidy
go mod tidy: go.mod file indicates go 1.18, but maximum supported version is 1.17
手动安装1.18版本以上的GO,比如Go1.21
install Golang and Config Go
由于大模型相关的从业人员大多是Python好手,对Go了解甚少,所以补充Go 的安装及配置;
安装Go
前往https://golang.google.cn/dl/ 下载对应的版本包;解压到/usr/share/bin下;
tar -xf go.gz -C /usr/share/bin
# 检查go 是否正确安装比如go path 、version等
go env
配置环境变量
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
最好配置到shell 配置文件(如 ~/.bashrc 或 ~/.zshrc)中;
source ~/.bashrc
或者
source ~/.zshrc
使之生效;
配置Go Proxy
安装go之后,需要配置go proxy,以免执行go get等操作时前往外网拉取包导致网络不通|缓慢 timeout甚至fail;
一般使用七牛云即可;
echo 'export GOPROXY=https://goproxy.cn,direct' >> ~/.bashrc
source ~/.bashrc
未完待续

参考文档
https://github.com/intelligent-machine-learning/dlrover
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- C++算法中两夫妻的故事-双指针
- 软件测试之单元测试总结
- electron + selenium报错: Server terminated early with status 1
- 再见卷积神经网络,使用 Transformers 创建计算机视觉模型
- VBA自学日志
- Java基础面试题汇总
- 自编码器及其变体
- 一起学习python类的属性装饰器@property
- 华为防火墙建立IPSEC VPN和NAT穿越问题(大学生易读版)
- VCoder:大语言模型的眼睛