LLaVA-Plus:多模态大模型的新突破
前言
随着AIGC技术的不断进步,各类多模态大模型(MLM)开始蓬勃发展。在这一领域中,LLaVA-Plus的推出无疑是一次重大突破。作为LLaVA团队的最新工作,LLaVA-Plus不仅继承了LLaVA的优秀特性,还在此基础上进行了显著改进和升级。
-
Huggingface模型下载:https://huggingface.co/LLaVA-VL/llava_plus_v0_7b
-
AI快站模型免费加速下载:https://aifasthub.com/models/LLaVA-VL

丰富的多模态处理能力
LLaVA-Plus拥有多样化的功能。除了能够处理基本的图像编辑任务,如物体检测、分割、打标签等,它还支持进行复杂的OCR处理和图像美化。此外,LLaVA-Plus能够与外部知识进行交互,支持用户与模型的实时交互,如对点击区域进行实例分割等。

创新的技能库概念
LLaVA-Plus的一大创新在于引入了“技能库(Skill Repository)”的概念。这一库集成了众多AI子任务能力及相应的模型,使得LLaVA-Plus能够根据用户的需求调用适当的子任务模型,进而完成各种复杂的任务。这种模式类似于“Visual ChatGPT”,但与之不同的是,LLaVA-Plus将LLM部分融合进了统一的网络结构中,使得图像特征在整个对话过程中都是有感知的。
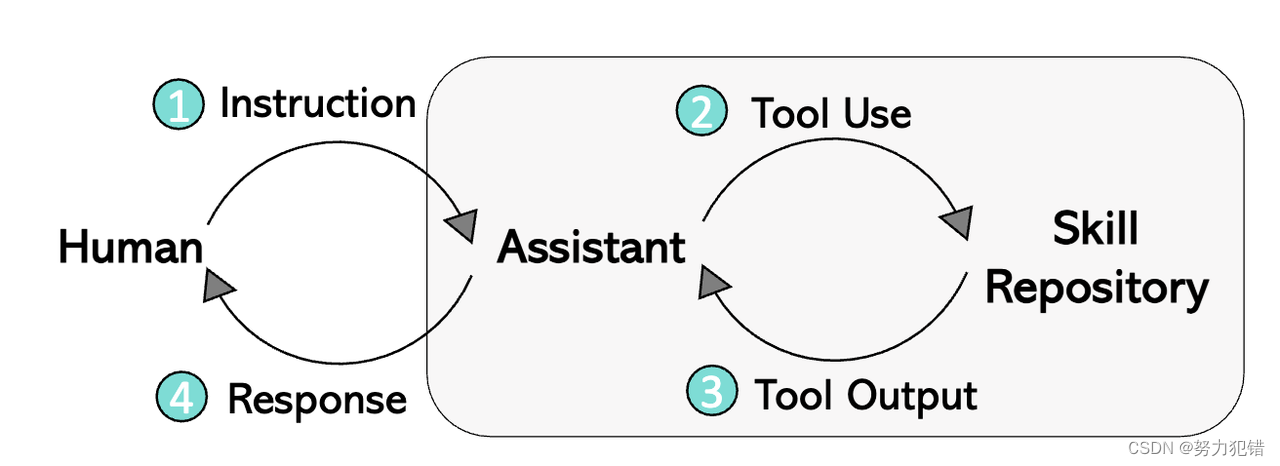
模块化与灵活性
通过将子任务模型与LMM模型解耦,LLaVA-Plus能够根据增加的子任务模型来扩展其功能。这种模块化设计不仅使得每个子任务模型可以专注于解决特定的任务,从而达到最佳效果,而且还利用了现有的开源模型,降低了整个系统学习的难度,避免了重复工作。
LLM与多模态任务的融合
LLaVA-Plus的核心优势在于将语言模型和子任务模型的结合。语言模型部分负责理解用户的要求,确定需要调用的子任务列表,然后调用相应的多模态模型,并将这些模型的输出进行汇总,以自然语言的形式返回给用户。这种整合使得LMM不仅能够理解和处理文字信息,还能够感知和响应图像、视频等多模态输入,显著扩展了模型的应用范围和能力。
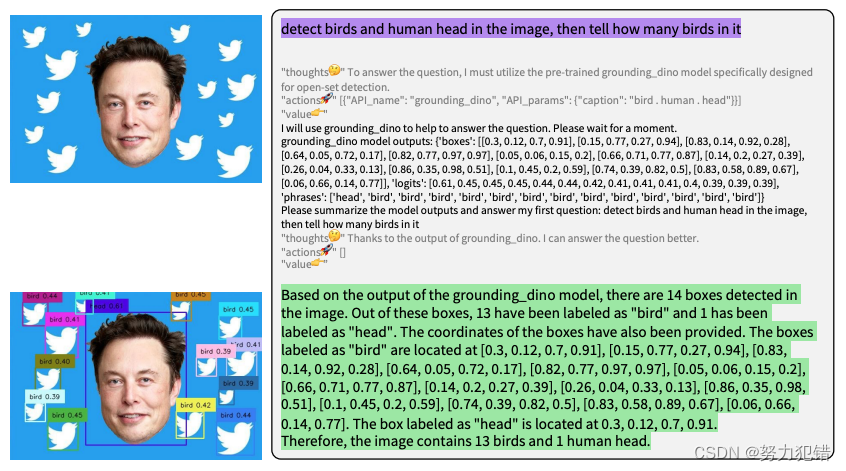
实际应用前景
LLaVA-Plus的这种设计思路对AI应用的普及和发展具有重要的促进作用。例如,可以开发自动发朋友圈/微博/Ins/Twitter的Bot,将用户的照片进行美化后,自动生成文案并发布。更进一步地,LLaVA-Plus可以改进图像生成过程,例如,通过优化用户输入的提示词,为Stable Diffusion等图像生成模型提供更适合的指令。这不仅增强了图像生成的质量,也为用户创造了更为丰富和个性化的图像内容。
未来展望
展望未来,LLaVA-Plus这样的多模态大模型可能会成为人工智能领域的一种常态。这种模型不仅使得计算机视觉和人工智能技术更加亲近普通用户,还可能引领一种全新的交互方式。用户将不再需要了解复杂的计算机指令或专业的图像处理技术,而是通过自然语言即可实现复杂的多模态任务,极大地降低了使用门槛,推动AI技术的普及和应用。
LLaVA-Plus的推出无疑是多模态大模型领域的一次重要进展,其创新性的设计和强大的功能为未来的AI发展提供了新的可能性和方向。
模型下载
Huggingface模型下载
https://huggingface.co/LLaVA-VL/llava_plus_v0_7b
AI快站模型免费加速下载
https://aifasthub.com/models/LLaVA-VL
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Baumer工业相机堡盟工业相机如何使用OpenCV实现相机图像的显示(C++)
- 【程序员的自我修养—编译和链接】
- NEAU_Python程序设计结课作业
- C++轮子·STL 简介
- MATLAB神经网络训练工具箱,自动建立神经网络求解(数学建模国赛美赛必备)
- vue的computed中的getter和setter
- 计算机Java项目|java游戏账号交易系统
- ubuntu系统下nginx警告可疑符号 [warn] server name “*“ has suspicious symbols in /etc/nginx/nginx.conf:40
- 第七章实验案例
- 封神榜大模型