【所有方法一览】大模型推理优化:在更小的设备运行、推理增速
发布时间:2023年12月21日
?
知识蒸馏(优先)
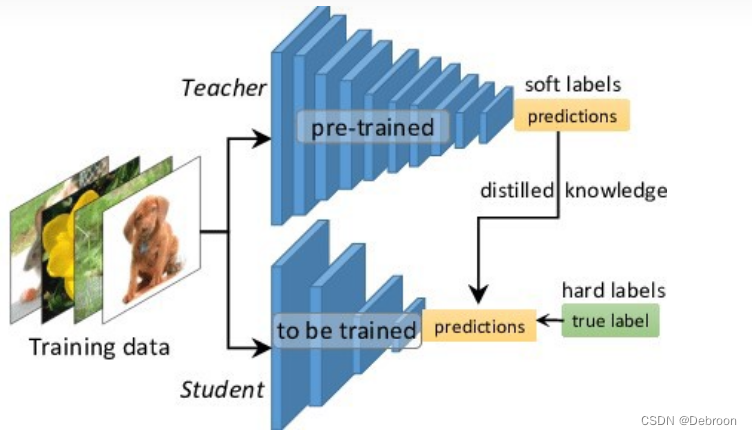
知识蒸馏:
- 知识:模型参数、一堆矩阵
- 蒸馏:把大模型参数迁移到小模型,用更小的矩阵代替更大的矩阵
让大、小模型最后一层输出尽可能接近。
- 判别指标:KL 散度、L2 距离
学习的是最后一层的概率分布,但大模型不止最后一层,还有很多中间层。
- 所以,不仅要最后一层接近,还有俩者的中间层、输入层、注意力层也要接近
- 判别指标:MSE loss
主流是知识蒸馏,但需要多训练一个模型,成本更高。
模型剪枝
把其中一些参数(矩阵)去掉,接近 0 的参数。
- 去掉 30% 的参数,对下游任务性能不影响
对于注意力层,定义重要性指标,去掉不重要的层。
模型量化(优先)
把浮点数变成定点数。
主流框架都支持。
参数共享
相邻矩阵共享同一套参数,原先相邻矩阵参数都不同。
- 只使用一个层,效果也不会差
低秩分解
用一小维代替整个参数矩阵。
参数搜索
找更好的神经网络配置,比如加卷积层、找更好的非线性函数、注意力机制优化等。
文章来源:https://blog.csdn.net/qq_41739364/article/details/135134492
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!