Flink|《Flink 官方文档 - 概念透析 - 及时流处理》学习笔记
学习文档:概念透析 - 及时流处理
学习笔记如下:
及时流(timely stream)
及时流处理时有状态流处理的扩展,其中时间在计算中起着一定的作用。
及时流的应用场景:
- 时间序列分析
- 基于特定时间段进行聚合
- 对发生时间很重要的事件进行处理
Event Time 和 Processing Time
处理时间(processing time)
处理时间的即数据到达各个 Operator 的机器时间。
当一个流程序在运行时,所以依赖时间的 Operator(例如窗口)均会使用运行该 Operator 的机器时间。一个小时的窗口将会包含在一个整小时内到达的所有记录。例如,如果一个应用在 9:15 启动,那么第一个时间窗口是从 9:15 - 10:00,下一个事件窗口是从 10:00 - 11:00。
处理时间是一个最简单的时间概念,不要求各个流和机器之间的协调。它提供了最高的性能和最低的延迟。然后,在分布式和异步环境中,处理时间并不提供确定性,它容易受到记录速度、不同 Operator 之间的流动速度以及中断的影响。
事件时间(event time)
各个事件在生产设备上的发生时间。
这个时间通常在记录进入 Flink 之前就已嵌入其中,并且这个事件时间戳(evetn timestamp)可以从每条记录中提取。对于事件时间而言,时间的进度取决于数据,而不是任何时钟。使用事件时间的程序必须指定如何生成事件时间水印(event time watermarks),这是在事件时间中指示进度的机制。
在完美情况下,事件时间将产生完全一致和确定性的结果,无论事件何时到达、如何排序。但是,除非事件(依据时间戳)有序到达,否则在等待乱序事件时,一定会产生一些延迟。又因为只能等待有限的时间,所以也限制了事件时间应用程序的准确性。
假设所有的数据都已经到达,基于事件时间的 operator 将能按预期运行, 即使在处理乱序或延迟事件、或重新处理历史数据时,也能产生正确和一致的结果。例如,每小时的事件时间窗口将包含所有事件时间戳落在该窗口内的记录,无论它们到达的顺序或处理的时间如何,这些记录的时间戳都落在该小时内。
请注意,有时当使用事件时间程序实时处理实时数据时,它们将使用一些基于处理时间(processing time)的 operator,以确保它们及时进行。
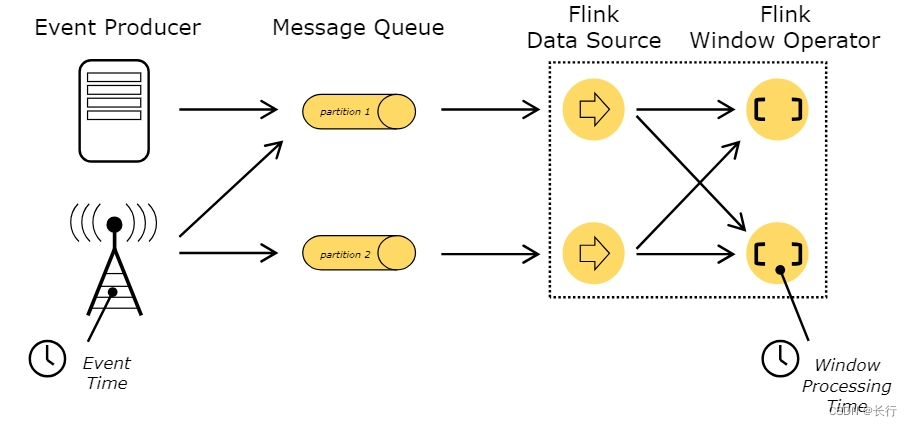
Event Time and Watermarks
一个支持事件时间(event time)的流处理器需要有一个测量事件时间进展的方法。例如,一个按小时创建窗口的 window operator 需要能够及时发现事件时间已经超过了一小时的末尾,从而使该 operator 可以关闭窗口。
事件时间可能独立于处理时间变化。例如,在一个程序中,operator 的当前事件时间可能因为接收事件的延迟而略微落后于处理事件,而两者都以相同的速度进行;又比如,在一个程序可能通过快速处理 Kafka TOPIC 中缓冲的历史数据,来在几秒内处理完数周的数据。
在 Flink 中,用于测量事件时间进展的机制是 watermarks。Watermarks 流作为数据流的一部分,携带了时间戳 t;其中,watermark(t) 表示数据流中的事件时间已经到达了 t,当前数据流中应该不会再有比 t 更早的事件时间了。
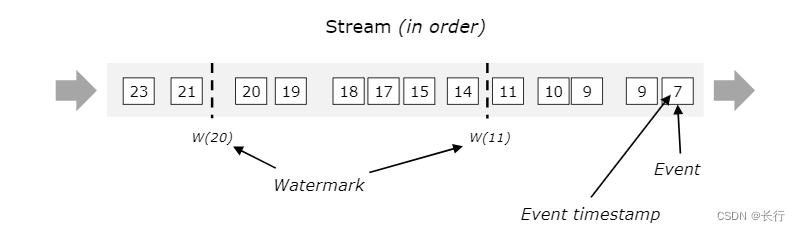
当事件是按事件时间顺序排列时,Watermark 就是一个周期性的标记,样例如下:
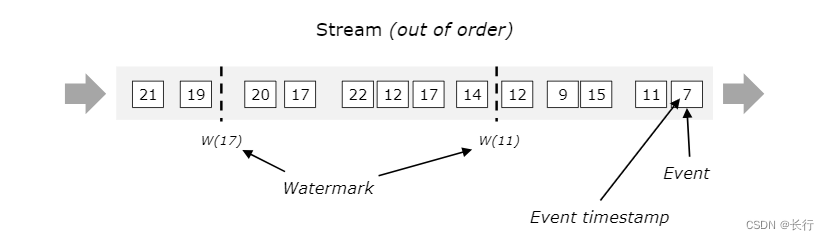
在乱序流中,watermark 至关重要。一般来说,watermark 是声明的数据流中的某个时间点,事件时间在改时间点之前的记录都已经已经到达。一旦 watermark 到达了某个 operator,该 operator 就将其内部的事件时间推进到 watermark 的值。
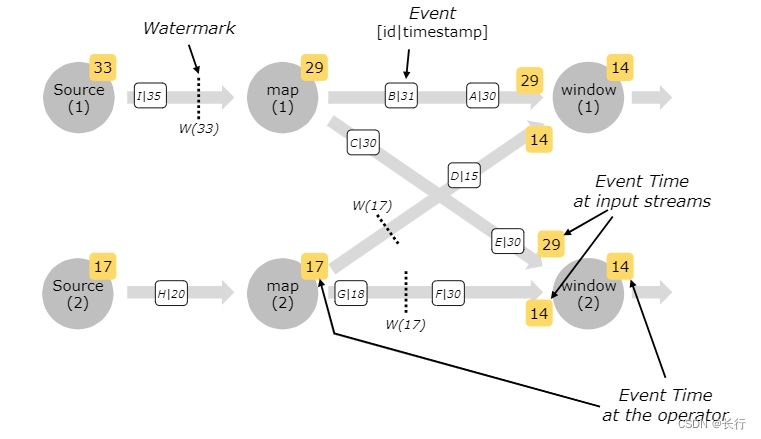
Watermarks in Parallel Streams
watermark 是在 source 或 source 之后生成的。source 的各个并行的 subtask 通常独立地生成 watermark,这些 watermark 定义了特定并行 source 的事件信息。
随着 watermark 在程序流中流动,它们在到达每个 operator 后会推动该 operator 的 event time。每当一个 operator 推动了它的 event time,它就会向每个下游生成一个新的 watermark。
一些 operator 会消费多个输入流(例如 keyBy() 或 partition())。这类 operator 的 event time 是所有输入流的 event time 的最小值。
Lateness 延迟
可能会存在某些元素违反 watermark 条件,即在 watermark(t) 已经发生后,仍然会有出现很多时间戳小于等于 t 的元素。因为某些元素可能被任意延迟,所以不可能指定某一个事件时间前的事件均已到达的时间。此外,即使延迟时间有限,watermark 延迟太长时间也通常是不可取的,因此这会导致在评估事件时间窗口时延迟过多。
延迟元素:在系统的事件时间时钟(通过 watermark 表示)已经超过延迟元素的时间戳之后到达的元素。
Windowing 窗口
在流处理中,聚集操作与批处理是不一样的。因为流式无限生成的,所以在流处理中,不可能统计流中的所有元素;取而代之地,在流处理中,通常在窗口范围内进行聚集操作,例如 “对最近 5 分钟内计数”、“对最近 100 个元素求和” 等。
窗口可以是时间驱动的(例如每 30 秒),也可以是数据驱动的(例如每 100 个元素)。我们通常会区分不同类型的窗口,例如:
- 滚动窗口(没有重叠)
- 滑动的窗口(有重叠)
- 会话窗口(由不活动的间隙打断)

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 简约大气时尚宣传视频模板剪辑素材PR项目工程文件
- node-red:使用node-red-contrib-amqp节点,实现与RabbitMQ服务器(AMQP)的消息传递
- qt 信号和槽的简明使用
- 数模学习day06-主成分分析
- P2257 YY的GCD(莫比乌斯)
- HTTP 301错误:永久重定向,大勇的冒险之旅
- 力扣(leetcode)第521题最长特殊序列I(Python)
- 网络安全(小白)全知识点-学习路线(黑客)
- 在阿里云上测试Web应用防火墙的有效性
- 助力打造清洁环境,基于YOLOv4开发构建公共场景下垃圾堆放垃圾桶溢出检测识别系统