【领域专家系列】简单聊聊设备指纹设计
原创文章,转载请标注。https://blog.csdn.net/leeboyce/article/details/135737231
文章目录
声明
原创文章,转载请标注。https://blog.csdn.net/leeboyce/article/details/135737231
《码头工人的一千零一夜》是一位专注于技术干货分享的博主,追随博主的文章,你将深入了解业界最新的技术趋势,以及在Java开发和安全领域的实用经验分享。无论你是开发人员还是对逆向工程感兴趣的爱好者,都能在《码头工人的一千零一夜》找到有价值的知识和见解。
一、背景
爬虫需要抓取到具有一定规模的数据才能产生价值,抓取设备出于成本考虑,需要控制设备数量。黑产通常会通过伪造设备信息的方式来“创造”出更多的虚假设备。为了能够在较长的一段时间内,追踪并识别出某一台具体的设备,就衍生出了设备指纹。
二、设备指纹需要解决的问题
1、高唯一性
目标是为设备生成一个唯一的设备编码。
(1)碰撞和错误
什么是碰撞?
一个指纹对应多台真实设备,我们就认为该设备指纹发生了碰撞。
什么是错误?
一台设备对应多个设备指纹,我们就认为设备指纹产生了错误。
(3)如何衡量一个设备指纹的好坏?
设备指纹的碰撞率与错误率越趋近于0就认为设备指纹越优秀。
(2)设计原则
在设计设备指纹时,可以适当地允许错误率的错在,但要尽量降低碰撞率。碰撞就意味着对某一设备指纹进行反制时有概率误伤正常用户。
(3)指纹生成设计
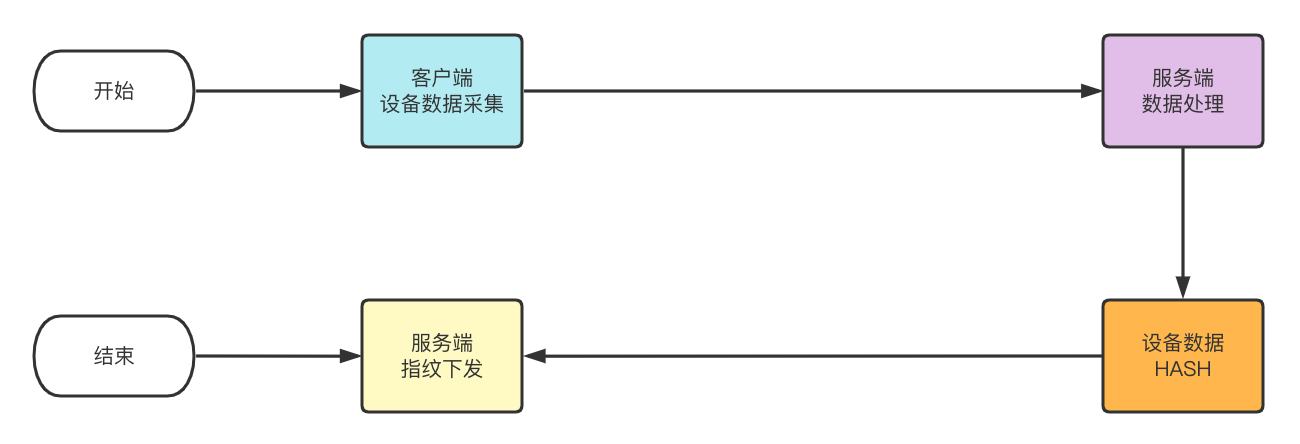
a)方案一
直接使用系统收集数据进行指纹值计算。
优点: 实现方式简单且易维护。接收到数据数据直接计算即可。
缺点: 可拓展性差。删减或新增特征值时就需要重新计算所有设备的指纹值。
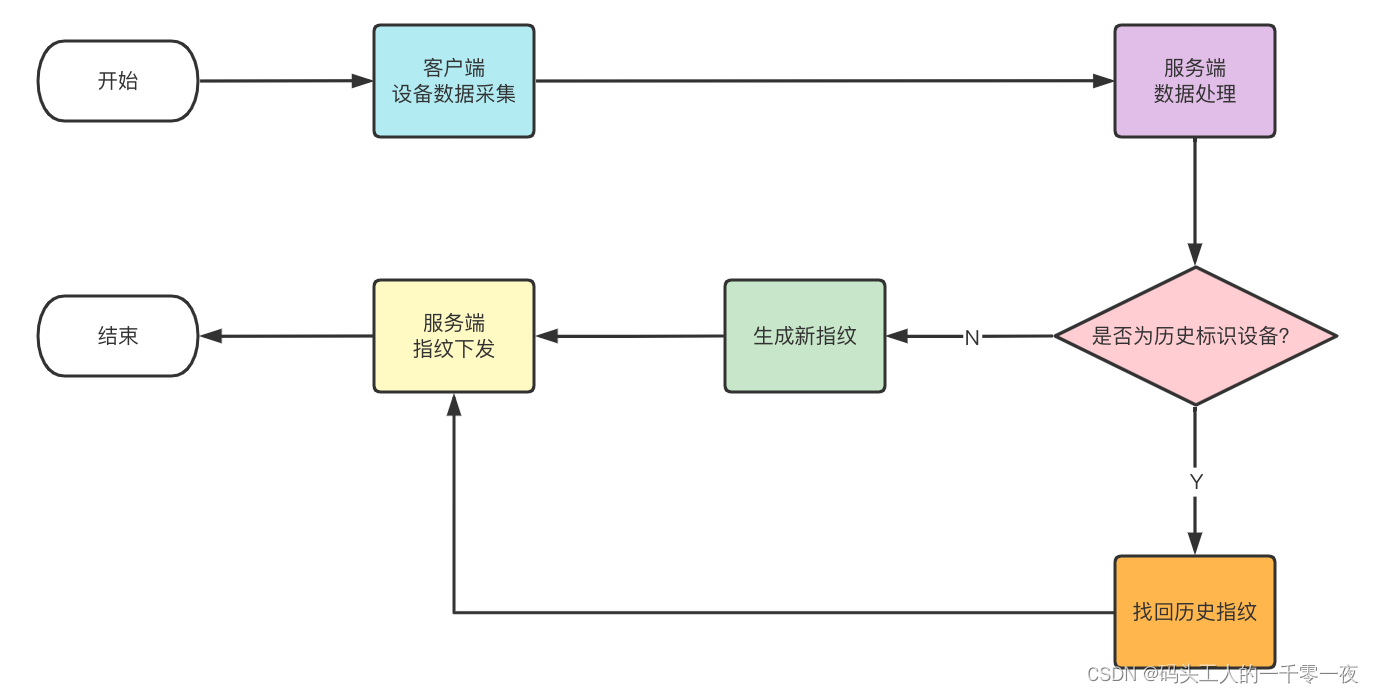
b)方案二
后端生成唯一随机值,指纹值的生成与具体设备数据无关,具体数据值用于描述设备的关联关系。
**优点:**可拓展性强。新增或删减特征值时只需要修改设备之间的关联关系即可。
**缺点:**维护成本高。相较于方案一需要维护特征值与设备之间的关联关系。
c)总结
从系统设计角度,方案二的可拓展性更强,在面对如今安卓、苹果设备因为更加注重用户隐私而不断收缩设备信息获取权限的环境下,显然方案二更适合。
2、高稳定性
(1)传统设备标识
传统设备标识由IMEI、MAC地址、安卓ID 或者系统存储随机值来作为设备指纹,这种设备指纹的问题是依赖单一数据,稳定性太差。

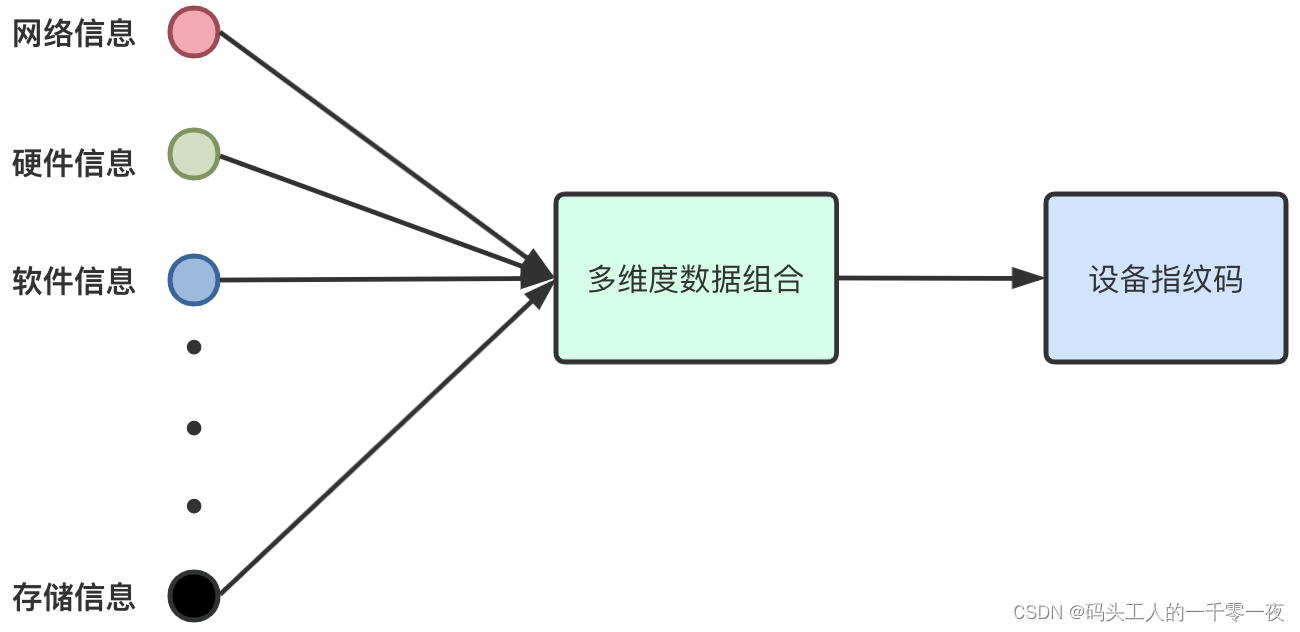
(2)新一代设备标识
通过收集多维度信息进行设备指纹计算,例如网络信息、硬件信息、软件信息、存储信息(多点存储)等,不依赖单一数据源,稳定性有明显提升。
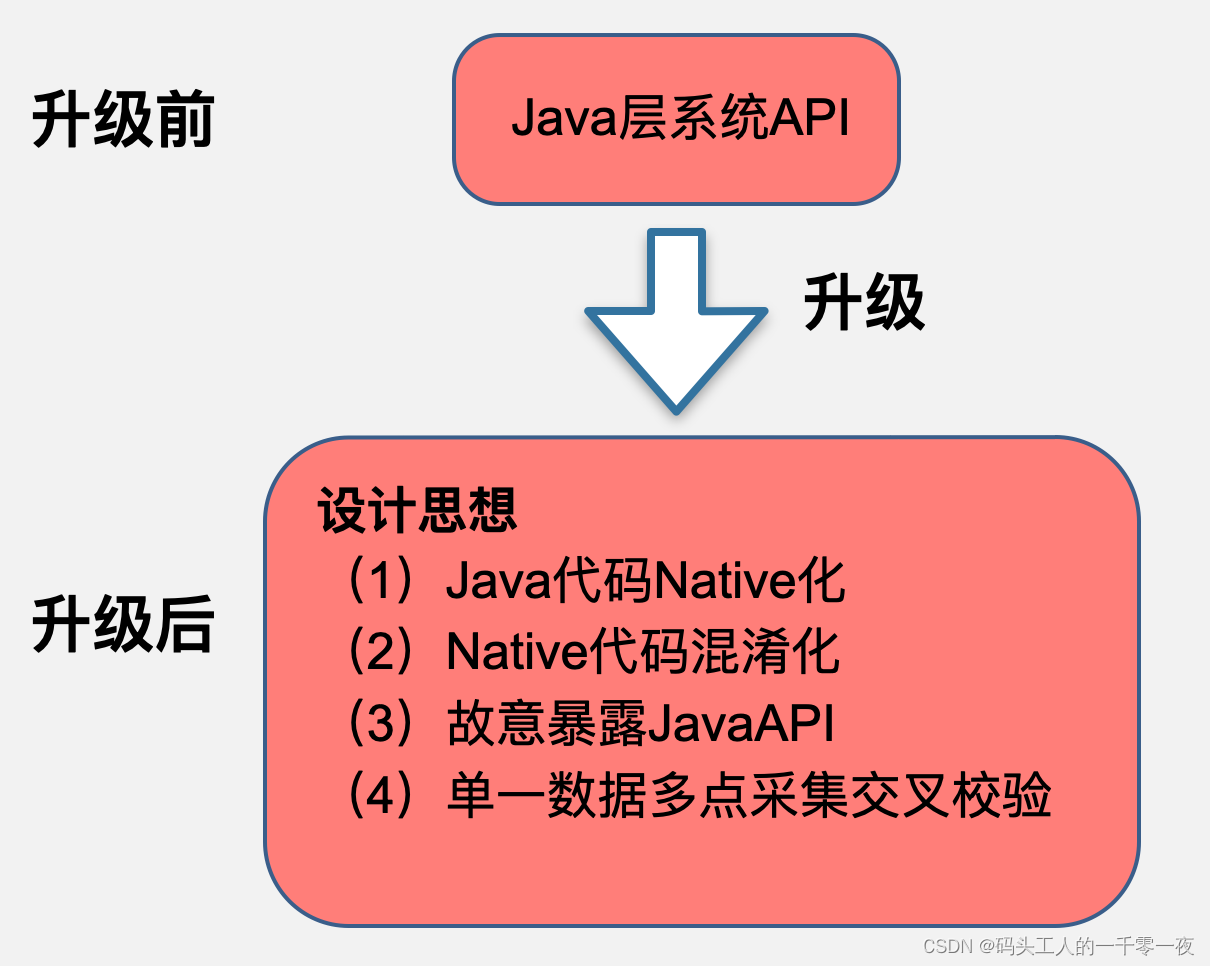
3、防篡改性
大部分逆向选手主要针对Java层进行分析,我们通过核心代码下沉,迫使逆向选手阅读混淆后的汇编代码,提升逆向难度。
三、总结
设备指纹在整个风控体系中的重要性是不言而喻的,一个优秀的设备指纹决定着风控系统的下限。即使风控系统仅有策略,但只要设备指纹未失效,通过频率策略就能够一定程度的防止大规模作弊事件的发生。
四、最后
《码头工人的一千零一夜》是一位专注于技术干货分享的博主,追随博主的文章,你将深入了解业界最新的技术趋势,以及在Java开发和安全领域的实用经验分享。无论你是开发人员还是对逆向工程感兴趣的爱好者,都能在《码头工人的一千零一夜》找到有价值的知识和见解。
懂得不多,做得太少。欢迎批评、指正。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!