CUDA:执行模型
SM
?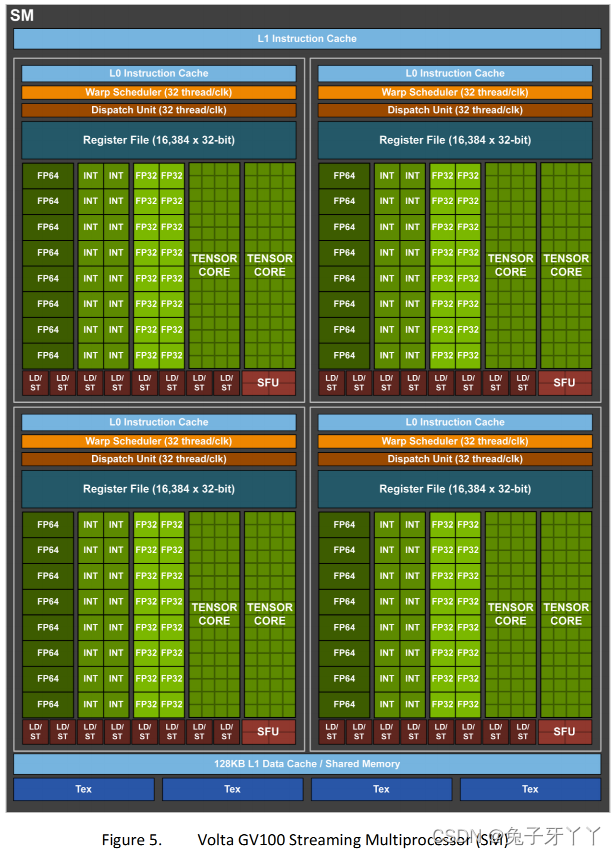
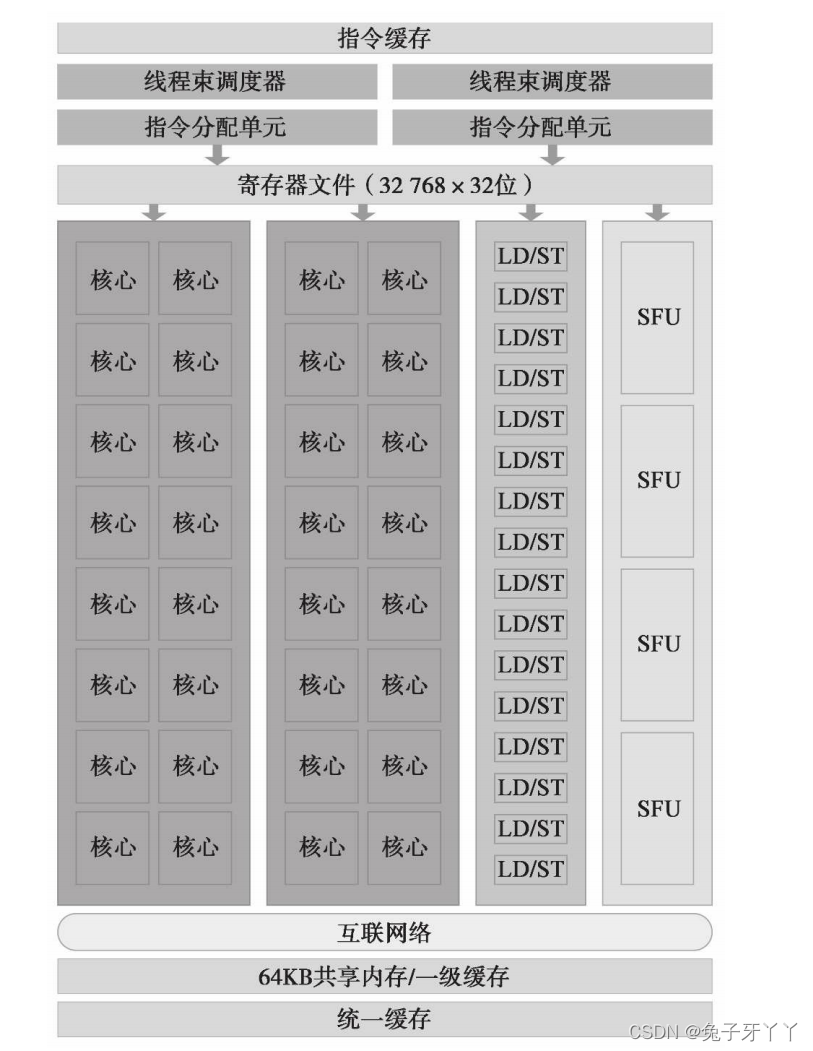
在SM中,共享内存和寄存器是非常重要的资源。共享内存被分配在SM上的常驻线程
块中,寄存器在线程中被分配。线程块中的线程通过这些资源可以进行相互的合作和通
信。
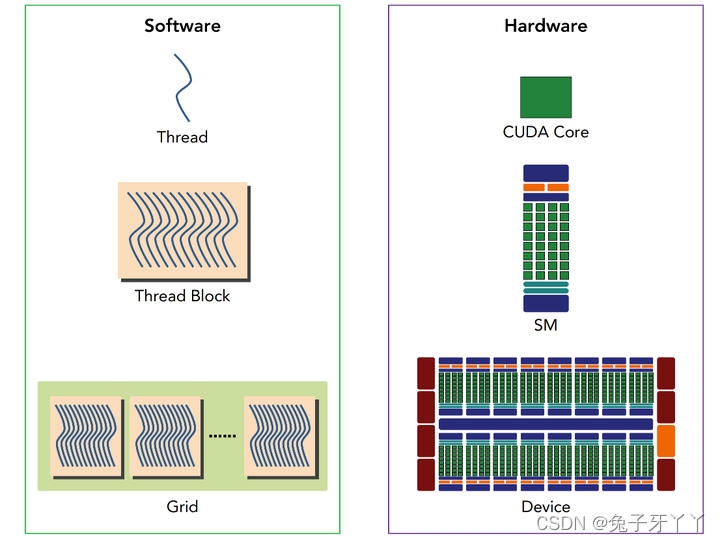
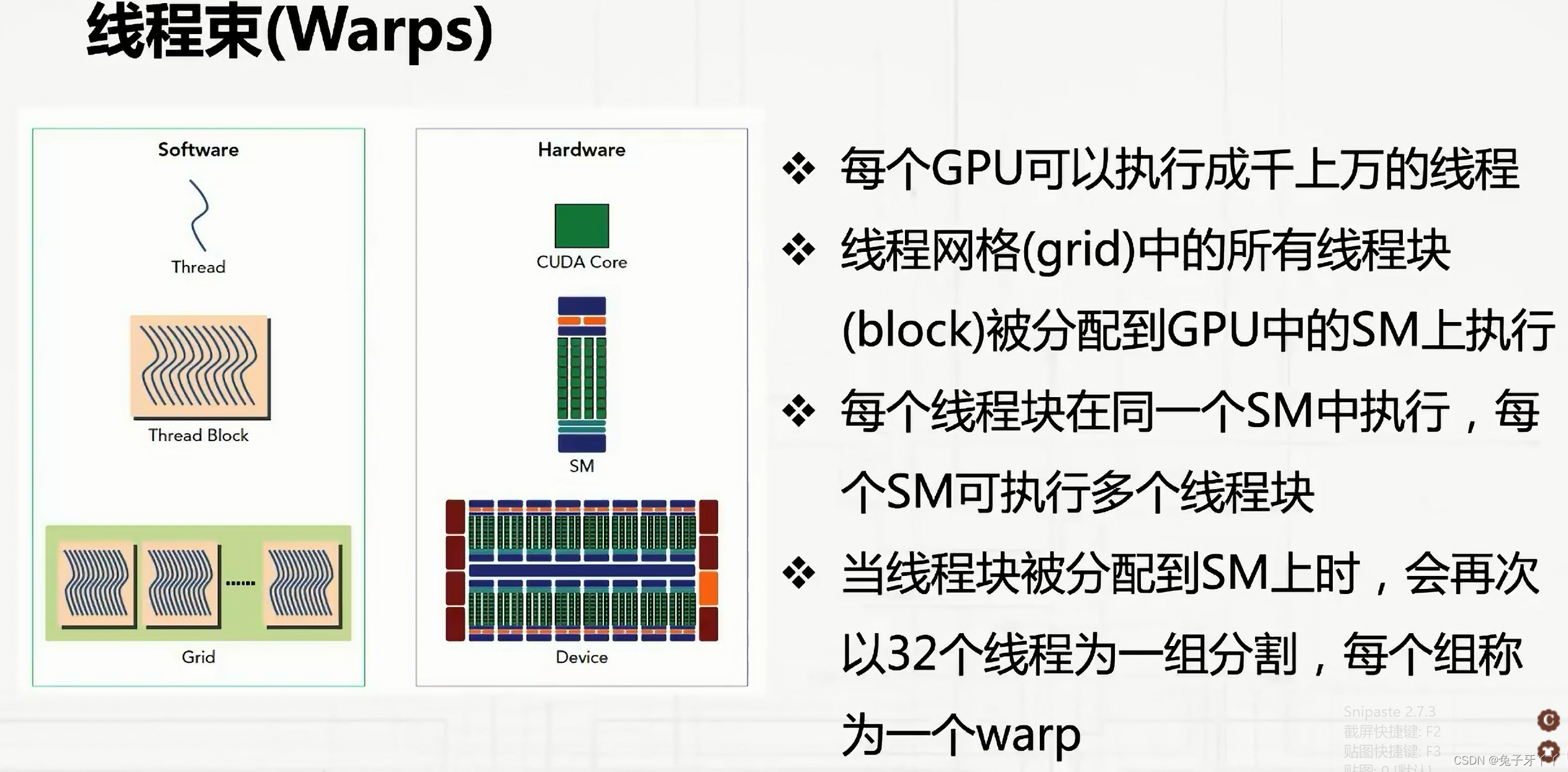
warp
CUDA采用单指令多线程(SIMT)架构来管理和执行线程,每32个线程为一组,被称
为线程束(warp)。线程束中的所有线程同时执行相同的指令。每个线程都有自己的指
令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个SM都将分配给它的
线程块划分到包含32个线程的线程束中,然后在可用的硬件资源上调度执行。
一个线程块只能在一个SM上被调度。一旦线程块在一个SM上被调度,就会保存在该
SM上直到执行完成。在同一时间,一个SM可以容纳多个线程块
CUDA程序编写优化步骤
如何完成一个优秀的CUDA程序呢?这里有一份步骤给大家参考:
-
确定任务中的串行和并行的部分,选择合适的算法(首先将问题分解为几个步骤,确定哪些步骤可以用并行实现,并确定合适的算法);
-
按照算法确定数据和任务的划分方式,将每个需要实现的步骤映射为一个满足CUDA两层并行模型的内核函数,让每个SM上至少有6个活动warp和至少2个活动block;
-
编写一个能正确运行的程序作为优化的起点,要确保程序能稳定运行以及其正确性,在精度不足或者发生溢出时必须使用双精度浮点或者更长的整数类型;
-
优化显存访问,避免显存带宽成为瓶颈。在显存带宽得到完全优化前,其他优化不会产生明显效果。
-
优化指令流,在误差可接受的情况下,使用CUDA算术指令集中的快速指令;避免多余的同步;在只需要少量线程进行操作的情况下,使用类似
“if threaded<N”的方式,避免多个线程同时运行占用更长时间或者产生错误结果; -
资源均衡,调整每个线程处理的数据量,shared memory和register和使用量;通过调整block大小,修改算法和指令以及动态分配shared memory,都可以提高shared的使用效率;register的多少是由内核程序中使用寄存器最多的时刻的用量决定的,因此减小register的使用相对困难;节约register方法是使用shared memory存储变量;使用括号明确地表示每个变量的生存周期;使用占用寄存器较小的等效指令代替原有指令;
-
与主机通信优化,尽量减少CPU与GPU间的传输,使用cudaMallocHost分配主机端存储器,可以获得更大带宽;一次缓存较多的数据后再一次传输,可以获得较高的带宽;需要将结果显示到屏幕的时候,直接使用与图形学API互操作的功能;使用流和异步处理隐藏与主机的通信时间;使用zero-memory技术和Write-Combined memory提高可用带宽;
由此我们可以看到我们的优化之路还很漫长,这个优化步骤中的每一步都对应了大量可以去做的优化,上面这个只是个概述,不过我们可以看到有一句非常重要的话:
在显存带宽得到完全优化前,其他优化不会产生明显效果。
所以我们就先不要想其他的了,先完成最基本的优化,去尽可能的使用显卡的内存带宽~
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 什么是抖店?不用直播带货,0粉丝可以做吗?
- 纯html写个个人简历!模版分享啦!!!
- 逆向获取某音乐软件的加密(js逆向)
- MessageBox:HubSpot x Facebook全方位对接!
- 【深度学习每日小知识】Object Detection 目标检测
- 在PyCharm中创建Flask项目
- web前端开发网页制作html/css结课作业
- spring AOP详解
- 鸿蒙OS应用开发之文本显示
- 0基础学java-day26(满汉楼实战)