弹性网络优化算法
3.3、Elastic-Net算法使用
这是scikit-learn官网给出的弹性网络回归的,损失函数公式,注意,它用的矩阵表示,里面用到范数运算。
min ? w 1 2 n samples ∣ ∣ X w ? y ∣ ∣ 2 2 + α ρ ∣ ∣ w ∣ ∣ 1 + α ( 1 ? ρ ) 2 ∣ ∣ w ∣ ∣ 2 2 \underset{w}\min { \frac{1}{2n_{\text{samples}}} ||X w - y||_2 ^ 2 + \alpha \rho ||w||_1 + \frac{\alpha(1-\rho)}{2} ||w||_2 ^ 2} wmin?2nsamples?1?∣∣Xw?y∣∣22?+αρ∣∣w∣∣1?+2α(1?ρ)?∣∣w∣∣22?
??Elastic-Net 回归,即岭回归和Lasso技术的混合。弹性网络是一种使用 L1, L2 范数作为先验正则项训练的线性回归模型。 这种组合允许学习到一个只有少量参数是非零稀疏的模型,就像 Lasso 一样,但是它仍然保持一些像 Ridge 的正则性质。我们可利用 l1_ratio 参数控制 L1 和 L2 的凸组合。
??弹性网络在很多特征互相联系(相关性,比如身高和体重就很有关系)的情况下是非常有用的。Lasso 很可能只随机考虑这些特征中的一个,而弹性网络更倾向于选择两个。
??在实践中,Lasso 和 Ridge 之间权衡的一个优势是它允许在迭代过程中继承 Ridge 的稳定性。
弹性网络回归和普通线性回归系数对比:
import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor, LinearRegression
创建数据并获取到原方程的系数
# 1、创建数据集X,y
X = 2 * np.random.rand(100, 20)
w = np.random.randn(20, 1)
b = np.random.randint(1, 10, size=1)
y = X.dot(w) + b + np.random.randn(100,1)
print('原始方程的斜率:',w.ravel())
print('原始方程的截距:',b)

线性回归的系数
linear = LinearRegression()
linear.fit(X, y)
print('普通线性回归系数:',linear.coef_,linear.intercept_)

弹性网络算法
# 获取弹性网络
model = ElasticNet(alpha=1.11,l1_ratio=0.1)
model.fit(X, y)
print("弹性网络系数",model.coef_,model.intercept_)

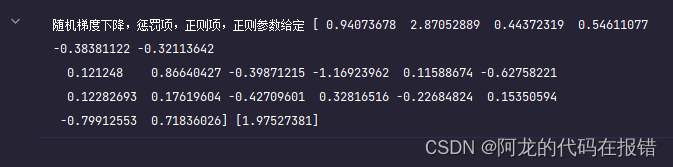
随机梯度下降
# 随机梯度下降 ,可以变化为ridge Lasso elastic
sgd = SGDRegressor(penalty='elasticnet',alpha=0.1)
sgd.fit(X, y.ravel())
print('随机梯度下降,惩罚项,正则项,正则参数给定',sgd.coef_,sgd.intercept_)
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- Android 12.0 SystemUI下拉状态栏定制一 qsPanel快捷模块添加默认背景
- Java的Set集合相关介绍
- 外汇天眼:不仅骗钱还骗感情?小心这类骗子盯上你
- PXE批量高效网络装机
- 远程桌面连接Windows实例,提示“为安全考虑,已锁定该用户账户,原因是登录尝试或密码更改尝试过多”错误解决方案
- uml超市进销存管理系统 实验报告.doc
- oracle中的PIVOT函数
- 登录注册表单路由切换 - 登录注册开发入门(6)
- Java中的内部类
- uniapp 无限级树形结构面包屑、单选-多选、搜索、移除功能插件,基于【虚拟列表】高性能渲染海量数据,加入动态高度、缓冲区