json.loads和eval 速度对比
发布时间:2023年12月18日
代码1
import json
import time
import pandas as pd
data_sets = pd.read_pickle("val_token_id.pandas_pickle")
data_sets=[str(i) for i in data_sets]
start=time.time()
[json.loads(i) for i in data_sets]
print(time.time()-start)
start=time.time()
[eval(i) for i in data_sets]
print(time.time()-start)
结果图
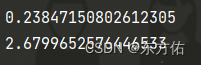
代码2
import json
import time
from multiprocessing import Process, Manager, freeze_support
import pandas as pd
from tqdm import tqdm
def json_loads_data(return_list,one_data):
return_list+=[json.loads(i) for i in tqdm(one_data)]
if __name__ == '__main__':
freeze_support()
data_sets = pd.read_pickle("val_token_id.pandas_pickle")
data_sets = [str(i) for i in data_sets]
start = time.time()
data = Manager().list()
num = 5
p_list = []
for i in range(0, len(data_sets), len(data_sets)//num):
j = i + len(data_sets)//num
p = Process(target=json_loads_data, args=(data, data_sets[i:j]))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print("multi_json_loads", time.time() - start)
start = time.time()
[json.loads(i) for i in data_sets]
print("json_loads", time.time() - start)
start = time.time()
pd.DataFrame(data_sets)[0].apply(lambda x: json.loads(x)).values.tolist()
print("dataFrame_apply", time.time() - start)
start = time.time()
json.loads(str(data_sets).replace("'", ""))
print("json_loads_str", time.time() - start)
start = time.time()
[eval(i) for i in data_sets]
print("eval", time.time() - start)
参考地址
https://blog.csdn.net/qq_35869630/article/details/105919104
Python 在大数据处理下的优化(一)用json.loads比eval快10倍!
文章来源:https://blog.csdn.net/weixin_32759777/article/details/134928535
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。 如若内容造成侵权/违法违规/事实不符,请联系我的编程经验分享网邮箱:chenni525@qq.com进行投诉反馈,一经查实,立即删除!
最新文章
- Python教程
- 深入理解 MySQL 中的 HAVING 关键字和聚合函数
- Qt之QChar编码(1)
- MyBatis入门基础篇
- 用Python脚本实现FFmpeg批量转换
- 如何修复DLL错误或丢失的问题,这里提供几种方法
- nginx 下载文件限速
- 软件测试BUG分析以及BUG定位
- 【UML】第14篇 协作图
- 计算机毕业设计 基于SpringBoot的民宿租赁系统的设计与实现 Java实战项目 附源码+文档+视频讲解
- 【Diagnosis基础】Dcm模块详细介绍
- 【加锁 】
- Mybatis之properties和自定义别名
- GLES学习笔记--glReadpixels 读取数据全是0
- C++类调用另一个类的成员函数